在算子实现章节已经介绍了kernel侧算子核心的实现方法,本章节侧重于介绍接入CANN框架时编程模式和API的使用。
自动生成kernel侧算子实现模板
在算子工程目录下的“op_kernel/xxx.cpp”文件中实现算子的核函数。核函数的定义模板已通过msOpGen工具自动生成,样例如下所示。注意这里参数的顺序按照“输入、输出、workspace、tiling”的顺序排布,开发者不要调整其顺序。
#include "kernel_operator.h"
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) {
GET_TILING_DATA(tiling_data, tiling);// 获取Tiling参数,详见下文介绍
// TODO: user kernel impl
}

算子原型定义中的输入和输出同名的情况下,自动生成的核函数中,输出参数增加ref后缀予以区分。示例如下:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR x_ref, GM_ADDR workspace, GM_ADDR tiling) {
...
}
GET_TILING_DATA获取Tiling参数
提供GET_TILING_DATA,用于获取算子kernel入口函数传入的tiling信息,并填入注册的Tiling结构体中,此函数会以宏展开的方式进行编译。注意,对应的算子host实现中需要定义TilingData结构体,实现并注册计算TilingData的Tiling函数。具体请参考Host侧tiling实现。
核函数中调用GET_TILING_DATA获取TilingData的样例如下:
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling)
{
GET_TILING_DATA(tilingData, tiling);
KernelAdd op;
op.Init(x, y, z, tilingData.totalLength, tilingData.tileNum);
if (TILING_KEY_IS(1)) {
op.Process();
}
}
核函数内推导输入数据类型和格式
算子工程在核函数内提供了DTYPE_<Arg>、ORIG_DTYPE_<Arg>、FORMAT_<Arg>三种宏用于推导核函数入参的数据类型、原始数据类型和数据格式。其中<Arg>会自动大写。样例如下:
template<class T> func() {}
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling)
{
DTYPE_X temp;
func<DTYPE_Z>();
if (FORMAT_Y == FORMAT_ND) {
...
}
}
输出shape依赖计算的算子kernel侧实现
某些算子,比如NonZero(统计tensor中非零值的个数),计算完成前无法得知算子输出的shape信息,算子计算完成后才能获取。该类算子在原型定义时,需要使用OutputShapeDependOnCompute接口进行标识,同时在算子核函数中将实际输出shape写入到出参中,便于框架侧基于该信息进行输出内存的管理。
在核函数所有输出的最后增加一个GM_ADDR类型的输出参数,并在核函数计算完成后,将输出shape信息写入到该出参中。shape信息的排布格式如下,大小为n * (8 + 1),每个元素的数据类型为uint64_t。其中n表示待刷新shape信息的输出个数,每个输出的shape信息都通过第1个元素来保存实际的shape维度(dim),后续的8个元素来保存具体每个维度的shape信息。
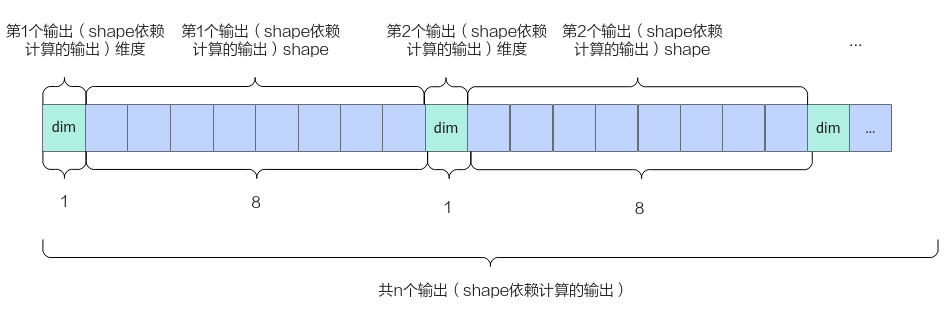
- 输出的顺序和原型定义中输出的顺序保持一致。
- 对于uint64_t的输出数据类型(对于tensor而言),需要将dim的uint32_t的高位设置为1,表示以uint64_t类型解析该tensor。
- 如下示例中,算子中有一个输出依赖计算得出,输出tensor的数据类型为uint32_t,计算完成后,得到输出的shape为(32, 64),出参shape_out用于存放该shape信息,值为(2, 32, 64)。代码示例如下:
extern "C" __global__ __aicore__ void xxx_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR shape_out, GM_ADDR workspace, GM_ADDR tiling) { ... constexpr uint32_t SHAPEOUT_SIZE = 9; // 输出数据为2维([32, 64]),tensor类型为uint32_t GlobalTensor<uint64_t> shapeoutGlobal_uint32; shapeoutGlobal_uint32.SetGlobalBuffer((__gm__ uint64_t*)shape_out, SHAPEOUT_SIZE); shapeoutGlobal_uint32.SetValue(0, 2); shapeoutGlobal_uint32.SetValue(1, 32); shapeoutGlobal_uint32.SetValue(2, 64); ... } - 如下示例中,算子中有一个输出依赖计算得出,输出tensor的数据类型为uint64_t,计算完成后,得到输出的shape为(32, 64),出参shape_out用于存放该shape信息,值为(0x0000000010000000 | 2, 32, 64)。代码示例如下:
extern "C" __global__ __aicore__ void xxx_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR shape_out, GM_ADDR workspace, GM_ADDR tiling) { ... constexpr uint32_t SHAPEOUT_SIZE = 9; // 输出数据为4维([1, 64, 128, 128]),tensor类型为uint64_t GlobalTensor<uint64_t> shapeoutGlobal_uint64; shapeoutGlobal_uint64.SetGlobalBuffer((__gm__ uint64_t*)shape_out, SHAPEOUT_SIZE); shapeoutGlobal_uint64.SetValue(0, 0x0000000010000000 | 4); shapeoutGlobal_uint64.SetValue(1, 1); shapeoutGlobal_uint64.SetValue(2, 64); shapeoutGlobal_uint64.SetValue(3, 128); shapeoutGlobal_uint64.SetValue(4, 128); ... }
- 如下示例中,算子中有两个输出依赖计算得出,输出tensor的数据类型为uint64_t,计算完成后,得到输出的shape为(16, 32)和 (1, 16, 16, 32),出参shape_out用于存放该shape信息。示例如下:
extern "C" __global__ __aicore__ void xxx_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR shape_out, GM_ADDR workspace, GM_ADDR tiling) { ... // 有两个输出需要刷新shape,一个维度为2维[16, 32],一个维度为4维[1, 16, 16, 32] // tensor类型为uint64_t constexpr uint32_t SHAPEOUT_SIZE_2 = 18; GlobalTensor<uint64_t> shapeoutGlobal_uint64_2; shapeoutGlobal_uint64_2.SetGlobalBuffer((__gm__ uint64_t*)shape_out, SHAPEOUT_SIZE_2 ); shapeoutGlobal_uint64_2.SetValue(0, 0x0000000010000000 | 2); shapeoutGlobal_uint64_2.SetValue(1, 16); shapeoutGlobal_uint64_2.SetValue(2, 32); // index[3]~index[8]数据为占位 shapeoutGlobal_uint64_2.SetValue(9, 0x0000000010000000 | 4); shapeoutGlobal_uint64_2.SetValue(10, 1); shapeoutGlobal_uint64_2.SetValue(11, 16); shapeoutGlobal_uint64_2.SetValue(12, 16); shapeoutGlobal_uint64_2.SetValue(13, 32); ... }