各功能共存情况
Y表示两功能不冲突,N表示两功能冲突。
控制可计算batch |
多头自适应压缩 (alibi场景) |
多头自适应压缩 (rope场景) |
并行解码 |
MLA |
反量化融合 |
qkv全量化 |
logN缩放 |
BNSD维度输入 |
|
|---|---|---|---|---|---|---|---|---|---|
控制可计算batch |
- |
Y |
Y |
N |
Y |
Y |
Y |
Y |
Y |
多头自适应压缩 (alibi场景) |
- |
- |
N |
N |
N |
Y |
N |
Y |
N |
多头自适应压缩 (rope场景) |
- |
- |
- |
N |
N |
Y |
N |
Y |
N |
并行解码 |
- |
- |
- |
- |
N |
N |
N |
Y |
N |
MLA |
- |
- |
- |
- |
- |
N |
N |
N |
N |
反量化融合 |
- |
- |
- |
- |
- |
- |
N |
Y |
N |
qkv全量化 |
- |
- |
- |
- |
- |
- |
- |
N |
N |
logN缩放 |
- |
- |
- |
- |
- |
- |
- |
- |
N |
BNSD维度输入 |
- |
- |
- |
- |
- |
- |
- |
- |
- |
mask类型

mask类型不是独立特性,因paged attention算子的mask较为复杂,为便于理解,此处单独针对mask类型进行说明。
maskType |
硬件类型 |
维度 |
备注 |
|---|---|---|---|
UNDEFINED |
不传mask |
不传mask |
相当于一个全零的mask。 |
MASK_TYPE_NORM |
[batch, 1, max_seq_len] 或 [1, max_seq_len] 或 [max_seq_len, max_seq_len] |
倒三角mask。 |
|
[batch, max_seq_len / 16, 16, 16] 或 [1, max_seq_len / 16, 16, 16] |
|||
MASK_TYPE_ALIBI |
[batch, num_head, 1, max_seq_len] 或 [num_head, 1, max_seq_len] |
alibi mask。 |
|
[batch * num_head, max_seq_len / 16, 16, 16] 或 [num_head, max_seq_len / 16, 16, 16] |
|||
MASK_TYPE_SPEC |
[num_tokens, max_seq_len] |
并行解码mask。 |
|
[1, max_seq_len / 16, num_tokens, 16] |
上表中
基础功能
当参数maskType、batchRunStatusEnable、quantType、calcType、compressType、scaleType均为默认值时,使用PagedAttention的基础功能,此时输入输出参数如下:
参数 |
维度 |
数据类型 |
格式 |
cpu or npu |
描述 |
|---|---|---|---|---|---|
query |
[num_tokens, num_head, head_size] |
float16/bf16 |
ND |
npu |
各batch的query在num_tokens轴合并。 |
keyCache |
|
float16/bf16 |
|
npu |
cache好的key。 |
valueCache |
|
float16/bf16 |
|
npu |
cache好的value。 |
blockTables |
[num_tokens, max_num_blocks_per_query] |
int32 |
ND |
npu |
每个query的kvcache的block table,第一维是token索引,第二维表示block索引。 |
contextLens |
[batch] |
int32 |
ND |
cpu |
每个query对应的key/value的token数量。 |
attnOut |
[num_tokens, num_head, head_size_v] |
float16/bf16 |
ND |
npu |
经过计算输出的query。 |
控制可计算batch
- 功能
指定某几个batch参与attention计算。
- 开启方式
参数“batchRunStatusEnable”置为true,并传入batchRunStatus作为输入tensor。
batchRunStatus为0,1组成的tensor。0代表该位置的batch不参与计算,1代表参与计算。
- 特殊约束
不支持
Atlas 推理系列产品
多头自适应压缩(alibi场景)
- 功能
alibi mask场景下,对kv的 head_num维度进行压缩,提高内存利用率,精度不变。
又名Razor Attention。
- 开启方式
参数“compressType”置为COMPRESS_TYPE_KVHEAD。
若干输入tensor需要传入指定的维度,如下:
参数
维度
数据类型
格式
cpu or npu
query
[num_tokens * kv_head_num, num_head / kv_head_num, head_size]
float16/bf16
ND
npu
keyCache
[num_blocks, block_size, 1, head_size]
float16/bf16/int8
ND
npu
valueCache
[num_blocks, block_size, 1, head_size]
float16/bf16/int8
ND
npu
blockTables
[num_tokens * kv_head_num, max_num_blocks_per_query]
int32
ND
npu
contextLens
[batch * num_head]
int32
ND
cpu
attnOut
[n_tokens, num_head, head_size]
float16/bf16
ND
npu
- 特殊约束
不支持
Atlas 推理系列产品 。需与ReshapeAndCache算子的相应功能配合使用。
多头自适应压缩(rope场景)
- 功能
rope mask场景下,对kv的 head_num维度进行压缩,提高内存利用率,精度不变。
又名Razor Attention。
- 开启方式
参数“compressType”置为COMPRESS_TYPE_KVHEAD_ROPE。
额外传入razorOffset作为输入tensor。
若干输入tensor需要传入指定的维度,如下:
参数
维度
数据类型
格式
cpu or npu
query
[num_tokens * kv_head_num, num_head / kv_head_num, head_size]
float16/bf16
ND
npu
keyCache
[num_blocks, block_size, 1, head_size]
float16/bf16/int8
ND
npu
valueCache
[num_blocks, block_size, 1, head_size]
float16/bf16/int8
ND
npu
blockTables
[num_tokens * kv_head_num, max_num_blocks_per_query]
int32
ND
npu
contextLens
[batch * num_head]
int32
ND
cpu
razorOffset
[num_tokens * kv_head_num, block_size]
float
ND
cpu
attnOut
[n_tokens, num_head, head_size]
float16/bf16
ND
npu
- 特殊约束
不支持
Atlas 推理系列产品 。需与ReshapeAndCache算子的相应功能配合使用。
并行解码
- 功能
在传统的推理过程中,需要逐个token的进行串行解码,导致时间消耗与生成的token数量成正比,这个缺点在实施逐步解码的情况下尤为明显,为了增强这个过程,引入了lookahead。在decode阶段从n-gram中获取多个候选Token,进行并行解码,提升模型的推理速度。
- 开启方式
参数“calcType”置为CALC_TYPE_SPEC。
参数“maskType”置为MASK_TYPE_NORM或MASK_TYPE_SPEC。
额外传入qSeqLens作为输入tensor。
- 特殊约束
无。
MLA
- 功能
DeepSeek V2提出Multi-Head Latent Attention,通过对hiddenstates进行down-projection处理,压缩hiddensize,减少KVCache显存的占用。通过up-projection恢复KV,进行PA计算。通过算力换显存,来提升吞吐。
- 开启方式
keyCache的维度[num_blocks, block_size, kv_head_num, head_size_k]与valueCache的维度[num_blocks, block_size, kv_head_num, head_size_v]中head_size_k与head_size_v不相等。
- 特殊约束
不支持
Atlas 推理系列产品 。
反量化融合
- 功能
支持量化好的k,v传入,降低显存占用。由于传入的q不是量化的,故又名伪量化。
- 开启方式
参数“quantType”置为TYPE_DEQUANT_FUSION。
当以上参数开启时,通过参数hasQuantOffset指明传入的量化后的kv是否需要相应的偏移量。
- 特殊约束
不支持
Atlas 推理系列产品 。
qkv全量化
- 功能
支持量化好的q, k, v传入,降低显存占用。
- 开启方式
参数“quantType”置为TYPE_QUANT_QKV_OFFLINE或TYPE_QUANT_QKV_ONLINE, 分别为离线量化与在线量化。
复用kDescale和vDescale,当采用离线量化时,额外传入pScale作为输入tensor。
若干输入tensor需要传入指定的维度,如下:
参数
维度
数据类型
格式
cpu or npu
query
[num_tokens, num_head, head_size]
int8
ND
npu
keyCache
[num_blocks, block_size, kv_head_num, head_size]
int8
ND
npu
valueCache
[num_blocks, block_size, kv_head_num, head_size]
int8
ND
npu
blockTables
[num_tokens, max_num_blocks_per_query]
int32
ND
npu
contextLens
[batch]
int32
ND
cpu
kDescale
[head_num]
float
ND
npu
vDescale
[head_num]
float
ND
npu
pScale
[head_num]
float
ND
npu
attnOut
[n_tokens, num_head, head_size]
float16/bf16
ND
npu
其中pScale仅在离线量化场景传入,在线量化场景则不传此输入tensor。
- 特殊约束
使用全量化时需要指定输出tensor的数据类型,具体为使用参数outDataType,该参数只能是ACL_FLOAT16或ACL_BF16。
不支持
Atlas 推理系列产品 。
logN缩放
- 功能
针对Qwen长序列场景,使用LogN缩放注意力。
其公式为:
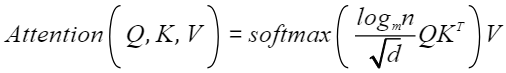
其中:m为训练长度,n为预测长度。
- 开启方式
将参数“scaleType置”为infer::PagedAttentionParam::SCALE_TYPE_LOGN时即可使用LogN缩放。
使用LogN缩放时,PagedAttentionOperation 新增一个 输入tensor 名为 logN,其具体规格如下:
名字
维度
数据类型
格式
cpu or npu
logN
增量阶段: [batch size]
Atlas 800I A2 推理产品 /Atlas A2 训练系列产品 :float32;Atlas 推理系列产品 :float16ND
NPU
其它输入tensor没有变化。
- 特殊约束
无。
BNSD维度输入
- 功能
使PA Op支持BNSD数据排布(原有的数据排布格式为BSND)。
- 开启方式
将参数“inputLayout”置为infer::inputLayout::TYPE_BNSD时开启BNSD功能。该参数默认值为infer::inputLayout::TYPE_BSND,表示默认数据排布格式为BSND。
若干tensor的规格发生了改变,改变的tensor如下表所示:
参数
维度
数据类型
格式
cpu or npu
q
[batch * maxSeq, headNum, head_size]
fp16/bf16
ND
npu
kCache
[layer,batch,headNum,maxSeq,head_size]
fp16/bf16
ND
npu
vCache
[layer,batch,headNum,maxSeq,head_size]
fp16/bf16
ND
npu
out
[batch * maxSeq, headNum, head_size]
fp16/bf16
ND
npu
其余tensor未发生改变。
- 特殊约束
无。