功能
将多个通信卡上的数据按所属rank号的顺序在第一维进行聚合,然后发送到每张卡上。
该算子涉及多卡相关操作,可根据实际需求配置HCCL相关环境变量,具体请参见《CANN 环境变量参考》中的“集合通信”章节。
使用场景
多对多。收集所有的数据到所有的节点上。把多个节点的数据收集到一个主节点上(Gather),再把这个收集到的数据分发到其他节点上(broadcast)。
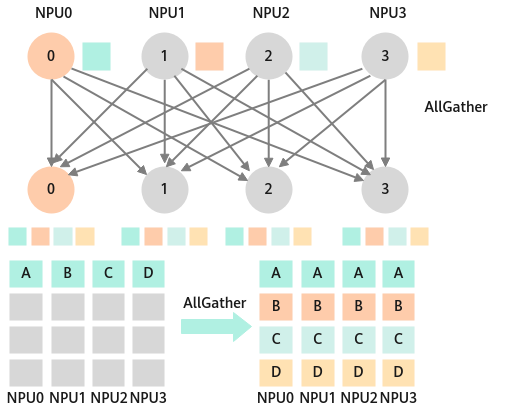
应用场景:
- All-Gather可应用于模型并行。
- 模型并行里前向计算里的参数全同步,需要用all-gather把模型并行里将切分到不同的NPU上的参数全同步到一张NPU上才能进行前向计算。
使用示例
定义
struct AllGatherParam {
int rank = 0;
int rankSize = 0;
int rankRoot = 0;
std::string backend = "hccl";
HcclComm hcclComm = nullptr;
CommMode commMode = COMM_MULTI_PROCESS;
std::string rankTableFile;
std::string commDomain;
};
参数列表
|
成员名称 |
类型 |
默认值 |
描述 |
|---|---|---|---|
|
rank |
int |
0 |
当前卡所属通信编号。 |
|
rankSize |
int |
0 |
通信的卡的数量。 |
|
rankRoot |
int |
0 |
主通信编号。 |
|
backend |
string |
“hccl” |
通信后端指示,仅支持“hccl”和“lccl”。 当“backend”为“lccl”且机器为 |
|
hcclComm |
HcclComm |
nullptr |
HCCL通信域指针。 默认为空,加速库为用户创建;若用户想要自己管理通信域,则需要传入该通信域指针,加速库使用传入的通信域指针来执行通信算子。 |
|
commMode |
CommMode |
COMM_MULTI_PROCESS |
通信模式,CommMode类型枚举值。hccl多线程只支持外部传入通信域方式。 |
|
rankTableFile |
string |
- |
集群信息的配置文件路径,适用单机以及多机通信场景,当前仅支持hccl后端场景。 若单机配置了ranktable,则以ranktable来初始化通信域。 配置请参见《TensorFlow 1.15模型迁移指南》的“准备ranktable资源配置文件”。 |
|
commDomain |
string |
- |
通信Device组用通信域名标识,多通信域时使用,当前仅支持“hccl”。 |
输入
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
x |
[dim_0,dim_1,... ,dim_n] |
|
ND |
输入tensor,维度小于8。 |
输出
|
参数 |
维度 |
数据类型 |
格式 |
描述 |
|---|---|---|---|---|
|
output |
[rankSize, dim_0,dim_1,... ,dim_n] |
|
ND |
输出tensor,维度小于或等于8。 输出output的维数比输入x的维数多一维。 |
规格约束
- rank、rankSize、rankRoot需满足以下条件。
- 0 ≤ rank < rankSize
- 0 ≤ rankRoot < rankSize

- 多用户使用时需要使用ATB_SHARE_MEMORY_NAME_SUFFIX环境变量(请参见Transformer加速库环境变量说明)进行共享内存的区分,以进行初始化信息同步。
- 当使用加速库的通信算子异常退出时,需要清空残留数据,避免影响之后的使用,命令参考如下:
rm -rf /dev/shm/sem.lccl* rm -rf /dev/shm/sem.hccl* ipcrm -a
- 当前不支持单device上跑多个HCCP进程实例,不能单卡同时跑多个通信算子。比如运行通信算子场景下,不支持同一张卡上跑多个模型。