案例介绍
MC2通算融合算子的性能收益主要来自于通信、计算的并行执行,即对Matmul计算的矩阵进行切分,通过下一块数据的Matmul计算与当前数据块的通信任务并行执行,从而达到隐藏计算/通信时间的目的。简单示意图如下,进行Matmul计算的矩阵沿M轴被切分为两块,则第二块数据的Matmul计算和第一块数据的通信可以并行执行,从而通过隐藏计算时间提高算子性能。本节的所有图示中MM代表Matmul计算,hcom代表通信任务。
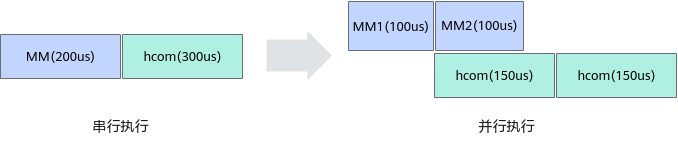
以MC2通算融合算子Matmul+hcom_allReduce,算子shape为M = 4096,N = 8192,K = 4096,数据类型half为例,介绍MC2算子的主要性能优化手段。
获取性能数据
通过msProf算子调优工具获取算子性能数据:
- 获取真实环境执行的性能数据(指令的cycle占比数据ArithmeticUtilization.csv),包含各个流水的占比情况;
- 获取仿真性能数据(指令流水图),包含各个流水的占用区间,可观察流水间依赖情况,从而优化并行效率。
分析主要瓶颈点
由上述图示可知MC2算子性能收益来自任务的并行执行,存在如下场景无法获得较大性能收益。
- 场景一:数据未切分

- 场景二:通算时间差异大
Matmul计算和通信任务的执行时间差异较大时,并行计算能够隐藏的时间很少,算子整体执行时间与未切分时的算子执行时间接近,此时无法获得性能收益。

- 场景三:线性度不好
线性度是衡量输出与输入之间关系的一个指标,用于描述在一定范围内输出是否能够以线性的方式响应输入的变化。在性能分析中,线性度即体现为输入数据切分后,每块数据的执行时间与原来切分前数据的执行时间是否为线性关系。这里,线性度不好分为两个方面,Matmul线性度不好或者hcom通信线性度不好。以Matmul线性度的各种情况为例,简单说明如下。
- 好的线性度:
数据切分前,Matmul执行时间为200us,将Matmul的输入均匀切分为两块,假设切分后,每块数据的Matmul执行时间都是100us,通过计算的并行执行,下图实际性能收益为100us。

- 不好的线性度:
数据切分前,Matmul执行时间为200us,将Matmul的输入均匀切分为两块,假设切分后,每块数据的Matmul执行时间都是150us,通过计算的并行执行,下图实际性能收益为50us。

- 劣化的线性度:
数据切分前,Matmul执行时间为200us,将Matmul的输入均匀切分为两块,假设切分后,每块数据的Matmul执行时间都是200us,通过计算的并行执行,下图实际性能收益为劣化50us。

上述内容以Matmul的线性度进行分析,实际场景中Matmul或者通信的线性度都有可能存在上述情况。
- 好的线性度:
综合上述分析,在MC2算子中总的优化原则为,计算不劣化的情况下,数据切分尽量切成小块数据。

当前案例优化前的算子指令流水图如上图所示,Matmul执行时间888us,hcom_allReduce通信时间1025us,总时间1913us。
设计优化方案
由上述通算融合算子的特性可知,性能优化主要优化数据切分策略。
验证优化方案性能收益
- 数据切分阶段一
Matmul的左矩阵(4096, 4096)沿M轴切分为两块(如下代码中的tileNum+tailNum),则每块数据的矩阵为(2048, 4096)。此时单算子执行时间为1419us。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
MatmulAllReduceCustomTilingData *tiling = context->GetTilingData<MatmulAllReduceCustomTilingData>(); tiling->param.rankDim = 8; tiling->param.tileM = 2048; tiling->param.tileNum = 2; tiling->param.tailM = 0; tiling->param.tailNum = 0; tiling->param.rankM = 4096; tiling->param.rankN = 8192; tiling->param.rankK = 4096; tiling->param.isTransposeA = 0; tiling->param.isTransposeB = 0; tiling->param.cToFloatLen = 0; tiling->param.nd2NzWorkLen = true; tiling->param.dataType = static_cast<uint8_t>(HCCL_DATA_TYPE_MAP.at(aType));
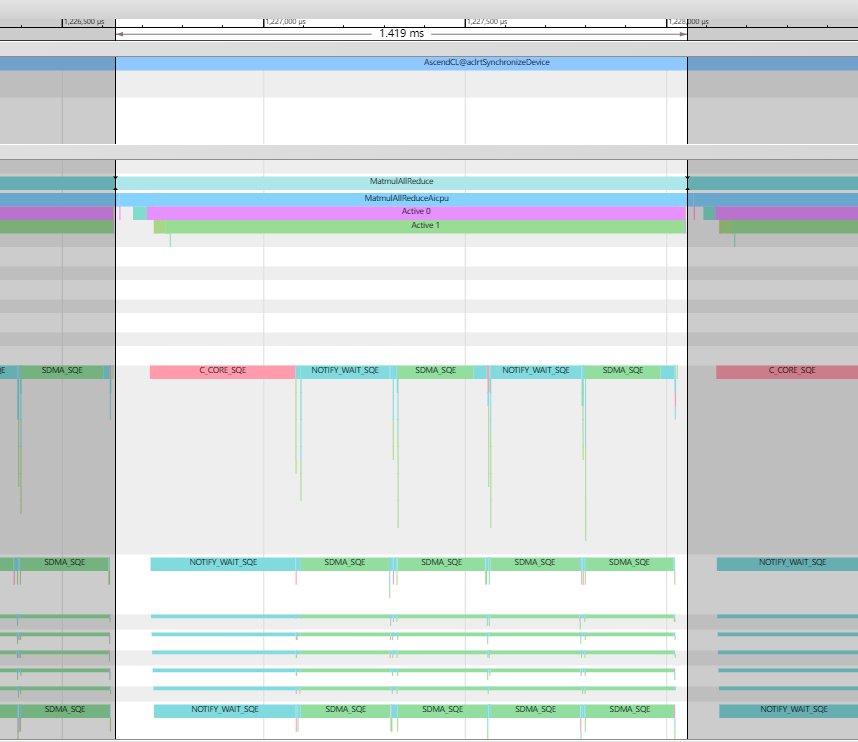
- 数据切分阶段二
为获得更好的线性度,Matmul做更细粒度的切分,在M轴方向切分为5块(如下代码中的tileNum+tailNum),此时单算子执行时间为1262us。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
MatmulAllReduceCustomTilingData *tiling = context->GetTilingData<MatmulAllReduceCustomTilingData>(); tiling->param.rankDim = 8; tiling->param.tileM = 512; // 优化前tileM为2048 tiling->param.tileNum = 1; // 优化前tileNum为2 tiling->param.tailM = 896; // 优化前tailM为0 tiling->param.tailNum = 4; // 优化前tailNum为0 tiling->param.rankM = 4096; tiling->param.rankN = 8192; tiling->param.rankK = 4096; tiling->param.isTransposeA = 0; tiling->param.isTransposeB = 0; tiling->param.cToFloatLen = 0; tiling->param.nd2NzWorkLen = true; tiling->param.dataType = static_cast<uint8_t>(HCCL_DATA_TYPE_MAP.at(aType));
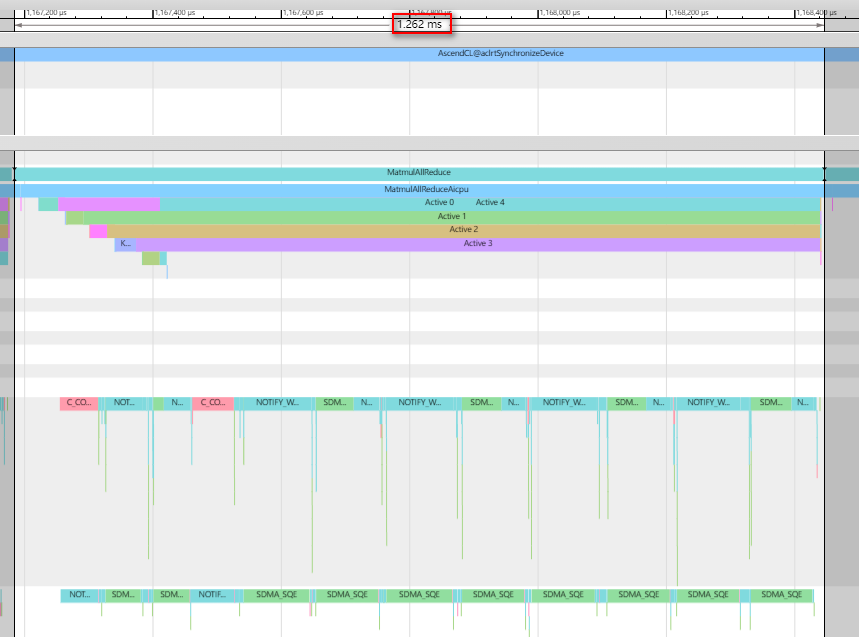
上述两种数据切分方式的性能收益如下,数据切分阶段一,单算子性能收益26%,数据切分阶段二,单算子性能收益34%。

总结
MC2算子的性能优化主要关注计算性能、通信性能以及合理的切分策略。