常规matmul与叠加偏置
- 功能概述
常规矩阵乘matmul的功能,且可通过hasBias参数控制是否叠加偏置。
- 计算公式
矩阵乘输入两个张量A(x)和B(weight),输出张量为C:
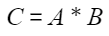
叠加偏置,偏置矩阵为bias:
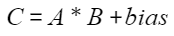
- 硬件支持情况
硬件型号
支持情况
特殊说明
Atlas A2 训练系列产品 /Atlas A2 推理系列产品 支持
-
Atlas 推理系列产品 支持
不支持输入输出tensor数据类型为bf16的场景。
- 参数配置
成员名称
取值范围
特殊说明
transposeA
false/true
取值为true时,不支持部分场景,详见规格说明。
transposeB
false/true
-
hasBias
false/true
-
outDataType
ACL_DT_UNDEFINED
-
enAccum
false
-
- 输入
参数
维度
数据类型
格式
描述
x
[m, k]/[batch, m, k]
float16/bf16
ND
矩阵乘的A矩阵。
weight
[k, n]/[batch, k, n]/[1, n / 16, k, 16]/[batch, n / 16, k, 16]
float16/bf16
ND/NZ
矩阵乘的B矩阵,权重。
bias
[1, n]/[n]/[batch, n]
float16/bf16
ND
叠加的偏置矩阵。当hasBias取值为true时输入。
- 输出
参数
维度
数据类型
格式
描述
output
[m, n]/[batch, m, n]
float16/bf16
ND
矩阵乘计算结果。
- 规格说明
由于输入输出的排列组合约束较复杂,下图列举了所有输入输出属性的组合,图中没有的组合即不支持:
图1 输入输出属性排列组合
Atlas 推理系列产品 不支持组合7-12。- “transposeA”取值为true时,不支持组合2、5、8、11。
Atlas 训练系列产品 支持组合4-6。- 所有输入输出tensor的数据类型均相同。
- 当weight维度为4维时,k和n的值均为16的整数倍。
- OP使用与典型场景
OP使用时,可参考算子使用指导中的使用流程部分,其中,单算子(OpsOperation)构造Operation参数的构造方法参考下列各场景的参数构造部分。
- 场景一
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = false; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = false;
# 计算示例 >>> x tensor([[1, 2], [3, 4]]) >>> weight tensor([[1, 2, 3], [4, 5, 6]]) >>> output tensor([[9, 12, 15], [19, 26, 33]]) # 9 = 1 * 1 + 2 * 4 # 12 = 1 * 2 + 2 * 5 # 15 = 1 * 3 + 2 * 6 # 19 = 3 * 1 + 4 * 4 # 26 = 3 * 2 + 4 * 5 # 33 = 3 * 3 + 4 * 6 - 场景二
// 参数构造 atb::infer::LinearParam param; param.transposeA = true; param.transposeB = true; param.hasBias = false; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = false;
# 根据行列转置情况,该示例和前一示例计算相同。 >>> x tensor([[1, 3], [2, 4]]) >>> weight tensor([[1, 4], [2, 5], [3, 6]]) >>> output tensor([[9, 12, 15], [19, 26, 33]]) - 场景三
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = true; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = false;
# 计算示例 >>> x tensor([[1, 2], [3, 4]]) >>> weight tensor([[1, 2, 3], [4, 5, 6]]) >>> bias tensor([1, 2, 3]) >>> output tensor([[10, 14, 18], [20, 28, 36]]) # 10 = 1 * 1 + 2 * 4 + 1 # 14 = 1 * 2 + 2 * 5 + 2 # 18 = 1 * 3 + 2 * 6 + 3 # 20 = 3 * 1 + 4 * 4 + 1 # 28 = 3 * 2 + 4 * 5 + 2 # 36 = 3 * 3 + 4 * 6 + 3
- 场景一
- 功能约束
- 硬件约束
Atlas 推理系列产品 不支持输入输出tensor数据类型为bf16的场景。 - 参数约束
transposeA为true时不支持部分场景。
outDataType为ACL_DT_UNDEFINED。
enAccum为false。
- 硬件约束
matmul与add融合
- 功能概述
矩阵乘matmul与add融合,该功能类似功能1中的叠加偏置,性能较优。
- 计算公式
矩阵乘输入两个张量A(x)和B(weight),偏置矩阵为bias,输出张量为C:
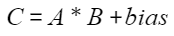
- 硬件支持情况
硬件型号
支持情况
Atlas A2 训练系列产品 /Atlas A2 推理系列产品 支持
Atlas 推理系列产品 不支持
- 参数配置
成员名称
取值范围
特殊说明
transposeA
false/true
取值为true时,不支持部分场景,详见规格说明。
transposeB
false/true
-
hasBias
true
-
outDataType
ACL_DT_UNDEFINED
-
enAccum
false
-
- 输入
参数
维度
数据类型
格式
描述
x
[m, k]/[batch, m, k]
float16/bf16
ND
矩阵乘的A矩阵。
weight
[k, n]/[batch, k, n]
float16/bf16
ND
矩阵乘的B矩阵,权重。
bias
[1, n]/[n]/[batch, n]
float
ND
叠加的偏置矩阵。
- 输出
参数
维度
数据类型
格式
描述
output
[m, n]/[batch, m, n]
float16/bf16
ND
矩阵乘计算结果。
- 规格说明
图2 输入输出属性排列组合

“transposeA”取值为true时,不支持组合2、5。
- OP使用与典型场景
OP使用时,可参考算子使用指导中的使用流程部分,其中,单算子(OpsOperation)构造Operation参数的构造方法参考以下参数构造部分。
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = true; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = false;
# 计算示例 >>> x tensor([[1, 2], [3, 4]]) >>> weight tensor([[1, 2, 3], [4, 5, 6]]) >>> bias tensor([1, 2, 3]) >>> output tensor([[10, 14, 18], [20, 28, 36]]) # 10 = 1 * 1 + 2 * 4 + 1 # 14 = 1 * 2 + 2 * 5 + 2 # 18 = 1 * 3 + 2 * 6 + 3 # 20 = 3 * 1 + 4 * 4 + 1 # 28 = 3 * 2 + 4 * 5 + 2 # 36 = 3 * 3 + 4 * 6 + 3 - 功能约束
- 硬件约束
Atlas 推理系列产品 不支持该功能。 - 参数约束
transposeA为true时不支持部分场景。
hasBias为true。
outDataType为ACL_DT_UNDEFINED。
enAccum为false。
- 硬件约束
matmul与inplaceAdd融合
- 功能概述
矩阵乘matmul与inplaceAdd融合,将矩阵乘结果累加到累加矩阵上,相较于算子拼接的方案,性能较优。
- 计算公式
矩阵乘输入两个张量A(x)和B(weight),累加张量为C(accum),同时也是输出张量:
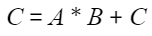
- 硬件支持情况
硬件型号
支持情况
Atlas A2 训练系列产品 /Atlas A2 推理系列产品 支持
Atlas 推理系列产品 不支持
- 参数配置
成员名称
取值范围
特殊说明
transposeA
false/true
取值为true时,不支持部分场景,详见规格说明。
transposeB
false/true
-
hasBias
false
-
outDataType
ACL_DT_UNDEFINED
-
enAccum
true
-
- 输入
参数
维度
数据类型
格式
描述
x
[m, k]/[batch, m, k]
float16/bf16
ND
矩阵乘的A矩阵。
weight
[k, n]/[batch, k, n]
float16/bf16
ND
矩阵乘的B矩阵,权重。
bias
[m, n]/[batch, m, n]
float
ND
累加矩阵。
- 输出
参数
维度
数据类型
格式
描述
output
[m, n]/[batch, m, n]
float
ND
累加矩阵,与accum为同一个Tensor,即计算结果原地写。
- 规格说明
由于输入输出的排列组合约束较复杂,下表列举了所有输入输出属性的组合,表格中没有的组合即不支持:
图3 输入输出属性排列组合
“transposeA”取值为true时,不支持组合2、5、8、11。
- OP使用与典型场景
OP使用时,可参考算子使用指导中的使用流程部分,其中,单算子(OpsOperation)构造Operation参数的构造方法参考以下参数构造部分。
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = false; param.outDataType = ACL_DT_UNDEFINED; param.enAccum = true;
# 计算示例 >>> x tensor([[1, 2], [3, 4]]) >>> weight tensor([[1, 2, 3], [4, 5, 6]]) >>> accum tensor([[1, 2, 3], [4, 5, 6]) >>> output tensor([[10, 14, 18], [23, 31, 39]]) # 10 = 1 * 1 + 2 * 4 + 1 # 14 = 1 * 2 + 2 * 5 + 2 # 18 = 1 * 3 + 2 * 6 + 3 # 23 = 3 * 1 + 4 * 4 + 4 # 31 = 3 * 2 + 4 * 5 + 5 # 39 = 3 * 3 + 4 * 6 + 6 - 功能约束
- 硬件约束
Atlas 推理系列产品 不支持该功能。 - 参数约束
transposeA为true时不支持部分场景。
hasBias为false。
outDataType为ACL_DT_UNDEFINED。
enAccum为true。
- 硬件约束
matmul反量化与叠加偏置
- 功能概述
矩阵乘matmul加反量化处理,通过hasBias参数控制是否叠加偏置。
- 计算公式
矩阵乘输入两个张量A(x)和B(weight),反量化步长为deqScale,输出张量为C,dequant为反量化处理函数:
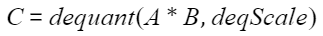
叠加偏置的场景下,偏置矩阵为bias:
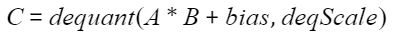
- 硬件支持情况
硬件型号
支持情况
特殊说明
Atlas A2 训练系列产品 /Atlas A2 推理系列产品 支持
-
Atlas 推理系列产品 支持
- 不支持transposeA配置为true。
- 不支持transposeB配置为false。
- 不支持hasBias为false。
- 不支持outDataType为ACL_BF16。
- 参数配置
成员名称
取值范围
特殊说明
transposeA
false/true
取值为true时,不支持部分场景,详见规格说明。
transposeB
false/true
受硬件约束。
hasBias
false/true
受硬件约束。
outDataType
ACL_FLOAT16/ACL_BF16
受硬件约束。该参数对应输出tensor的数据类型。
enAccum
false
-
- 输入
参数
维度
数据类型
格式
描述
x
[m, k]/[batch, m, k]
int8
ND
矩阵乘的A矩阵。
weight
[k, n]/[batch, k, n]/[1, n / 16, k, 16]/[batch, n / 16, k, 16]
int8
ND/NZ
矩阵乘的B矩阵,权重。
bias
[1, n]/[n]/[batch, n]
int32
ND
叠加的偏置矩阵。当hasBias取值为true时输入。
deqScale
[1, n]/[n]/[batch, n]
int64/uint64/float
ND
反量化步长。
- 输出
参数
维度
数据类型
格式
描述
output
[m, n]/[batch, m, n]
float16/bf16
ND
矩阵乘反量化计算结果。
- 规格说明
由于输入输出的排列组合约束较复杂,下表列举了所有输入输出属性的组合,表格中没有的组合即不支持:
图4 输入输出属性排列组合
Atlas 推理系列产品 不支持组合7-9。Atlas A2 训练系列产品 /Atlas A2 推理系列产品 不支持组合4-6。- transposeA取值为true时,不支持组合2、5、8。
- 输出tensor的数据类型与参数outDataType的值相同。
- 当weight维度为4维时,若“transposeB”为false,n为32的整数倍,k为16的整数倍;若“transposeB”为true,k为32的整数倍,n为16的整数倍。
- OP使用与典型场景
OP使用时,可参考算子使用指导中的使用流程部分,其中,单算子(OpsOperation)构造Operation参数的构造方法参考以下参数构造部分。
// 参数构造 atb::infer::LinearParam param; param.transposeA = false; param.transposeB = false; param.hasBias = true; param.outDataType = ACL_FLOAT16; param.enAccum = false;
# 计算示例 >>> x tensor([[1, 2], [3, 4]]) >>> weight tensor([[1, 2, 3], [4, 5, 6]]) >>> bias tensor([1, 2, 3]) >>> deqScale tensor([1, 2, 3]) >>> output tensor([[10, 28, 54], [20, 56, 108]]) # 10 = (1 * 1 + 2 * 4 + 1) * 1 # 28 = (1 * 2 + 2 * 5 + 2) * 2 # 54 = (1 * 3 + 2 * 6 + 3) * 3 # 20 = (3 * 1 + 4 * 4 + 1) * 1 # 56 = (3 * 2 + 4 * 5 + 2) * 2 # 108 = (3 * 3 + 4 * 6 + 3) * 3 - 功能约束
- 硬件约束
Atlas 推理系列产品 不支持输入输出tensor数据类型为bf16的场景。
- 硬件约束