函数功能
根据接口输出的不同,本节介绍如下两种LayerNorm接口。
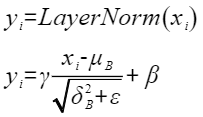
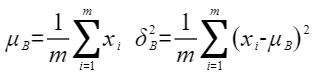
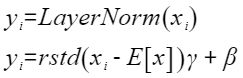
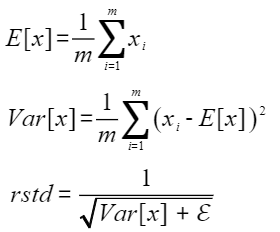
实现原理
- 输出归一化结果、均值和方差
以float类型,ND格式,输入为inputX[B, S, H],gamma[H]和beta[H]为例,描述LayerNorm高阶API内部算法框图,如下图所示。
图1 LayerNorm算法框图
计算过程分为如下几步,均在Vector上进行:
- 计算均值:Muls计算x*1/m的值,再计算累加值ReduceSum,得到均值outputMean;
- 计算方差:Sub计算出输入x与均值的差值,再用Mul进行平方计算,最后用Muls乘上1/m并计算累加值,得到方差outputVariance;
- 处理gamma和beta:通过broadcast得到BSH维度的gamma和beta;
- 计算输出:方差通过broadcast得到BSH维度的tensor,再依次经过Adds(outputVariance, eps), Ln, Muls, Exp,最后与(x-均值)相乘,得到的结果乘上gamma,加上beta,得到输出结果。
- 输出归一化结果、均值和标准差的倒数
以float类型,ND格式,输入为inputX[A, R],gamma[R] 和beta[R]为例,描述LayerNorm高阶API内部算法框架,如下图所示。
图2 LayerNorm-Rstd版本算法框图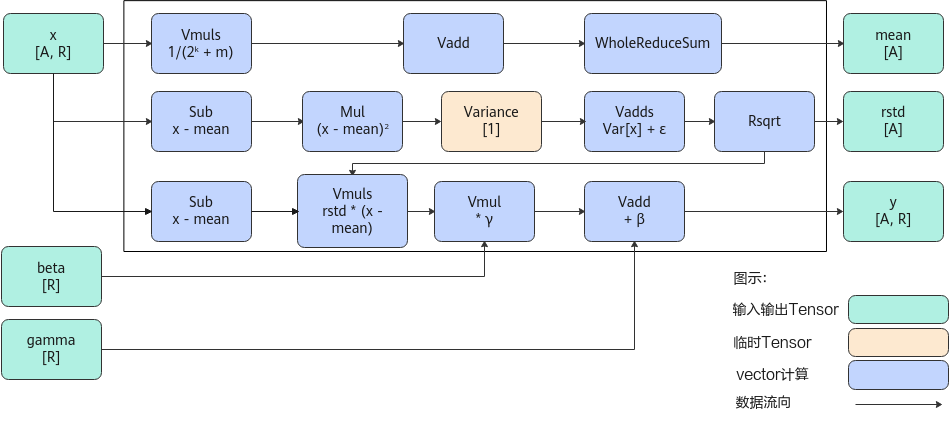
计算过程分为如下几步,均在Vector上进行,整体按照以A轴为最外层循环进行计算:
- 计算均值:首先对x的每个元素乘以1/(2^k+m),防止后续累加溢出。然后使用二分累加方式对数据进行求和:将数据拆分成一个整块和一个尾块,其中整块为2^k个元素,尾块为m个元素,将尾块数据叠加到整块数据。为方便描述,定义Vnum为参与单次计算的元素个数。对整块中,以Vnum长度为单位,奇偶位数据进行Vadd,得到一个Vnum长度的结果,对该结果做WholeReduceSum计算,得到输出均值mean;
- 计算rstd:用Sub计算出输入x与均值的差值,再用Mul计算,计算该差值的平方,为防止溢出,按照同样的二分累加方式,计算出该平方结果的方差Variance;方差与防除零系数ε相加,通过Rsqrt计算,得到输出rstd;
- 计算输出:用Sub计算出输入x与均值的差值,再与rstd相乘,得到的结果与gamma相乘,与beta相加,得到输出结果。
函数原型
由于该接口的内部实现中涉及复杂的计算,需要额外的临时空间来存储计算过程中的中间变量。临时空间大小BufferSize的获取方法:通过LayerNorm Tiling中提供的GetLayerNormMaxMinTmpSize接口获取所需最大和最小临时空间大小,最小空间可以保证功能正确,最大空间用于提升性能。
临时空间支持接口框架申请和开发者通过sharedTmpBuffer入参传入两种方式,因此LayerNorm接口的函数原型有两种:
- 输出归一化结果、均值和方差
- 通过sharedTmpBuffer入参传入临时空间
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void LayerNorm(const LocalTensor<T>& output, const LocalTensor<T>& outputMean, const LocalTensor<T>& outputVariance, const LocalTensor<T>& inputX, const LocalTensor<T>& gamma, const LocalTensor<T>& beta, const LocalTensor<uint8_t>& sharedTmpBuffer, const T epsilon, LayerNormTiling& tiling)
该方式下开发者需自行申请并管理临时内存空间并管理,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
- 接口框架申请临时空间
1 2
template <typename T, bool isReuseSource = false> __aicore__ inline void LayerNorm(const LocalTensor<T>& output, const LocalTensor<T>& outputMean, const LocalTensor<T>& outputVariance, const LocalTensor<T>& inputX, const LocalTensor<T>& gamma, const LocalTensor<T>& beta, const T epsilon, LayerNormTiling& tiling)
该方式下开发者无需申请,但是需要预留临时空间的大小。
- 通过sharedTmpBuffer入参传入临时空间
- 输出归一化结果、均值和标准差的倒数
- 通过sharedTmpBuffer入参传入临时空间
1 2
template <typename U, typename T, bool isReuseSource = false, const LayerNormConfig& config = LNCFG_NORM> __aicore__ inline void LayerNorm(const LocalTensor<T>& output, const LocalTensor<float>& outputMean, const LocalTensor<float>& outputRstd, const LocalTensor<T>& inputX, const LocalTensor<U>& gamma, const LocalTensor<U>& beta, const float epsilon, const LocalTensor<uint8_t>& sharedTmpBuffer, const LayerNormPara& para, const LayerNormSeparateTiling& tiling)
该方式下开发者需自行申请并管理临时内存空间并管理,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
- 接口框架申请临时空间
1 2
template <typename U, typename T, bool isReuseSource = false, const LayerNormConfig& config = LNCFG_NORM> __aicore__ inline void LayerNorm(const LocalTensor<T>& output, const LocalTensor<float>& outputMean, const LocalTensor<float>& outputRstd, const LocalTensor<T>& inputX, const LocalTensor<U>& gamma, const LocalTensor<U>& beta, const float epsilon, const LayerNormPara& para, const LayerNormSeparateTiling& tiling)
该方式下开发者无需申请,但是需要预留临时空间的大小。
- 通过sharedTmpBuffer入参传入临时空间
参数说明
- 输出归一化结果、均值和方差的接口
表1 模板参数说明 参数名
描述
T
操作数的数据类型。
isReuseSource
是否允许修改源操作数,默认值为false。如果开发者允许源操作数被改写,可以使能该参数,使能后能够节省部分内存空间。
设置为true,则本接口内部计算时复用inputX的内存空间,节省内存空间;设置为false,则本接口内部计算时不复用inputX的内存空间。
对于float数据类型输入支持开启该参数,half数据类型输入不支持开启该参数。
isReuseSource的使用样例请参考更多样例。
表2 接口参数说明 参数名称
输入/输出
含义
output
输出
目的操作数,类型为LocalTensor,shape为[B, S, H],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatoutputMean
输出
均值,类型为LocalTensor,shape为[B, S],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatoutputVariance
输出
方差,类型为LocalTensor,shape为[B, S],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatinputX
输入
源操作数,类型为LocalTensor,shape为[B, S, H],LocalTensor数据结构的定义请参考LocalTensor。inputX的数据类型需要与目的操作数保持一致,尾轴长度需要32B对齐。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatgamma
输入
缩放系数,类型为LocalTensor,shape为[H],LocalTensor数据结构的定义请参考LocalTensor。gamma的数据类型需要与目的操作数保持一致,尾轴长度需要32B对齐。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatbeta
输入
平移系数,类型为LocalTensor,shape为[H],LocalTensor数据结构的定义请参考LocalTensor。beta的数据类型需要与目的操作数保持一致,尾轴长度需要32B对齐。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:half/floatAtlas 推理系列产品AI Core ,支持的数据类型为:half/floatsharedTmpBuffer
输入
共享缓冲区,用于存放API内部计算产生的临时数据。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。共享缓冲区大小的获取方式请参考LayerNorm Tiling。
类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为:uint8_tAtlas 推理系列产品AI Core ,支持的数据类型为:uint8_tepsilon
输入
防除零的权重系数。
tiling
输入
LayerNorm计算所需Tiling信息,Tiling信息的获取请参考LayerNorm Tiling。
- 输出归一化结果、均值和标准差的倒数的接口
表3 模板参数说明 参数名
描述
U
beta,gamma操作数的数据类型。
T
inputX操作数的数据类型。
isReuseSource
当前该参数为预留参数,默认值为false。
config
配置LayerNorm接口中输入输出相关信息。LayerNormConfig类型,定义如下。
1 2 3 4 5
struct LayerNormConfig { bool isNoBeta = false; bool isNoGamma = false; bool isOnlyOutput = false; };
- isNoBeta:计算时,输入beta是否使用。
- false:默认值,LayerNorm计算中使用输入beta。
- true:LayerNorm计算中不使用输入beta。此时,公式中与beta相关的计算被省略。
- isNoGamma:可选输入gamma是否使用。
- false:默认值,LayerNorm计算中使用可选输入gamma。
- true:LayerNorm计算中不使用输入gamma。此时,公式中与gamma相关的计算被省略。
- isOnlyOutput:是否只输出y,不输出均值mean与标准差的倒数rstd。当前该参数仅支持取值为false,表示y、mean和rstd的结果全部输出。
表4 接口参数说明 参数名称
输入/输出
含义
output
输出
目的操作数,类型为LocalTensor,shape为[A, R],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: half/floatAtlas 推理系列产品AI Core ,支持的数据类型为: half/floatoutputMean
输出
均值,类型为LocalTensor,shape为[A],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: floatAtlas 推理系列产品AI Core ,支持的数据类型为: floatoutputRstd
输出
标准差的倒数,类型为LocalTensor,shape为[A],LocalTensor数据结构的定义请参考LocalTensor。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: floatAtlas 推理系列产品AI Core ,支持的数据类型为: floatinputX
输入
源操作数,类型为LocalTensor,shape为[A, R],LocalTensor数据结构的定义请参考LocalTensor。inputX的数据类型需要与目的操作数保持一致,尾轴长度需要32B对齐。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: half/floatAtlas 推理系列产品AI Core ,支持的数据类型为: half/floatgamma
输入
缩放系数,类型为LocalTensor,shape为[R],LocalTensor数据结构的定义请参考LocalTensor。gamma的数据类型精度不低于源操作数的数据类型精度。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: half/floatAtlas 推理系列产品AI Core ,支持的数据类型为: half/floatbeta
输入
平移系数,类型为LocalTensor,shape为[R],LocalTensor数据结构的定义请参考LocalTensor。beta的数据类型精度不低于源操作数的数据类型精度。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: half/floatAtlas 推理系列产品AI Core ,支持的数据类型为: half/floatepsilon
输入
防除零的权重系数。
sharedTmpBuffer
输入
共享缓冲区,用于存放API内部计算产生的临时数据。该方式开发者可以自行管理sharedTmpBuffer内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。共享缓冲区大小的获取方式请参考LayerNorm Tiling。
类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品 ,支持的数据类型为: uint8_tAtlas 推理系列产品AI Core ,支持的数据类型为: uint8_tpara
输入
LayerNorm计算所需的参数信息。LayerNormPara类型,定义如下。
1 2 3 4 5
struct LayerNormPara { uint32_t aLength; uint32_t rLength; uint32_t rLengthWithPadding; };
- aLength:指定输入inputX的A轴长度。
- rLength: 指定输入inputX的R轴实际需要处理的数据长度。
- rLengthWithPadding:指定输入inputX的R轴对齐后的长度,该值是32B对齐的。
tiling
输入
LayerNorm计算所需的Tiling信息,Tiling信息的获取请参考LayerNorm Tiling。
- isNoBeta:计算时,输入beta是否使用。
返回值
无
支持的型号
约束说明
- 操作数地址偏移对齐要求请参见通用约束。
- 对于输出归一化结果、均值和方差的接口:
- src和dst的Tensor空间可以复用。
- 输入仅支持ND格式。
- 输入数据不满足对齐要求时,开发者需要进行补齐,补齐的数据应设置为0,防止出现异常值从而影响网络计算。
- 不支持对尾轴H轴的切分。
- 对于输出归一化结果、均值和标准差的倒数的接口:
- 参数gamma和beta的数据类型精度不低于源操作数的数据类型精度。
- src和dst的Tensor空间不可以复用。
- 输入仅支持ND格式。
- 不支持对R轴进行切分。
调用示例
- 输出归一化结果、均值和方差的接口调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126
#include "kernel_operator.h" template <typename dataType, bool isReuseSource = false> class KernelLayernorm { public: __aicore__ inline KernelLayernorm() {} __aicore__ inline void Init(GM_ADDR inputXGm, GM_ADDR gammGm, GM_ADDR betaGm, GM_ADDR outputGm, GM_ADDR outputMeanGm, GM_ADDR outputVarianceGm, const LayerNormTiling &tiling) { this->bLength = tiling.bLength; this->sLength = tiling.sLength; this->hLength = tiling.hLength; this->tiling = tiling; bshLength = bLength * sLength * hLength; bsLength = bLength * sLength; inputXGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(inputXGm), bshLength); gammGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(gammGm), hLength); betaGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(betaGm), hLength); outputGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(outputGm), bshLength); outputMeanGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(outputMeanGm), bsLength); outputVarianceGlobal.SetGlobalBuffer(reinterpret_cast<__gm__ dataType *>(outputVarianceGm), bsLength); pipe.InitBuffer(inQueueX, 1, sizeof(dataType) * bshLength); pipe.InitBuffer(inQueueGamma, 1, sizeof(dataType) * hLength); pipe.InitBuffer(inQueueBeta, 1, sizeof(dataType) * hLength); pipe.InitBuffer(outQueue, 1, sizeof(dataType) * bshLength); pipe.InitBuffer(outQueueMean, 1, sizeof(dataType) * bsLength); pipe.InitBuffer(outQueueVariance, 1, sizeof(dataType) * bsLength); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { AscendC::LocalTensor<dataType> inputXLocal = inQueueX.AllocTensor<dataType>(); AscendC::LocalTensor<dataType> gammaLocal = inQueueGamma.AllocTensor<dataType>(); AscendC::LocalTensor<dataType> betaLocal = inQueueBeta.AllocTensor<dataType>(); AscendC::DataCopy(inputXLocal, inputXGlobal, bshLength); AscendC::DataCopy(gammaLocal, gammGlobal, hLength); AscendC::DataCopy(betaLocal, betaGlobal, hLength); inQueueX.EnQue(inputXLocal); inQueueGamma.EnQue(gammaLocal); inQueueBeta.EnQue(betaLocal); } __aicore__ inline void Compute() { AscendC::LocalTensor<dataType> inputXLocal = inQueueX.DeQue<dataType>(); AscendC::LocalTensor<dataType> gammaLocal = inQueueGamma.DeQue<dataType>(); AscendC::LocalTensor<dataType> betaLocal = inQueueBeta.DeQue<dataType>(); AscendC::LocalTensor<dataType> outputLocal = outQueue.AllocTensor<dataType>(); AscendC::LocalTensor<dataType> meanLocal = outQueueMean.AllocTensor<dataType>(); AscendC::LocalTensor<dataType> varianceLocal = outQueueVariance.AllocTensor<dataType>(); AscendC::LayerNorm<dataType, isReuseSource>( outputLocal, meanLocal, varianceLocal, inputXLocal, gammaLocal, betaLocal, (dataType)epsilon, tiling); outQueue.EnQue<dataType>(outputLocal); outQueueMean.EnQue<dataType>(meanLocal); outQueueVariance.EnQue<dataType>(varianceLocal); inQueueX.FreeTensor(inputXLocal); inQueueGamma.FreeTensor(gammaLocal); inQueueBeta.FreeTensor(betaLocal); } __aicore__ inline void CopyOut() { AscendC::LocalTensor<dataType> outputLocal = outQueue.DeQue<dataType>(); AscendC::LocalTensor<dataType> meanLocal = outQueueMean.DeQue<dataType>(); AscendC::LocalTensor<dataType> varianceLocal = outQueueVariance.DeQue<dataType>(); AscendC::DataCopy(outputGlobal, outputLocal, bshLength); AscendC::DataCopy(outputMeanGlobal, meanLocal, bsLength); AscendC::DataCopy(outputVarianceGlobal, varianceLocal, bsLength); outQueue.FreeTensor(outputLocal); outQueueMean.FreeTensor(meanLocal); outQueueVariance.FreeTensor(varianceLocal); } private: AscendC::GlobalTensor<dataType> inputXGlobal; AscendC::GlobalTensor<dataType> gammGlobal; AscendC::GlobalTensor<dataType> betaGlobal; AscendC::GlobalTensor<dataType> outputGlobal; AscendC::GlobalTensor<dataType> outputMeanGlobal; AscendC::GlobalTensor<dataType> outputVarianceGlobal; AscendC::TPipe pipe; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueX; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueGamma; AscendC::TQue<AscendC::QuePosition::VECIN, 1> inQueueBeta; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueue; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueMean; AscendC::TQue<AscendC::QuePosition::VECOUT, 1> outQueueVariance; uint32_t bLength; uint32_t sLength; uint32_t hLength; dataType epsilon = 0.001; uint32_t bshLength; uint32_t bsLength; LayerNormTiling tiling; }; extern "C" __global__ __aicore__ void kernel_layernorm_operator(GM_ADDR inputXGm, GM_ADDR gammGm, GM_ADDR betaGm, GM_ADDR outputGm, GM_ADDR outputMeanGm, GM_ADDR outputVarianceGm, GM_ADDR tiling) { GET_TILING_DATA(tilingData, tiling); KernelLayernorm<half, false> op; op.Init(inputXGm, gammGm, betaGm, outputGm, outputMeanGm, outputVarianceGm, tilingData.layernormTilingData); op.Process(); }
- 输出归一化结果、均值和标准差的倒数的接口调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137
#include "kernel_operator.h" constexpr int32_t BUFFER_NUM = 1; // tensor num for each queue template <const AscendC::LayerNormConfig& CONFIG> class KernelLayerNorm { public: __aicore__ inline KernelLayerNorm() {} __aicore__ inline void Init(GM_ADDR x, GM_ADDR gamma, GM_ADDR beta, GM_ADDR mean, GM_ADDR rstd, GM_ADDR y, const float epsilon, const AscendC::LayerNormPara& para, const AscendC::LayerNormSeparateTiling& tiling) { this->meanRstdSize = (para.aLength + 7) / 8 * 8; // 此时进行32B对齐处理 // get start index for current core, core parallel xGm.SetGlobalBuffer((__gm__ DTYPE_X*)x, para.aLength * para.rLengthWithPadding); gammaGm.SetGlobalBuffer((__gm__ DTYPE_Y*)gamma, para.rLengthWithPadding); betaGm.SetGlobalBuffer((__gm__ DTYPE_Y*)beta, para.rLengthWithPadding); meanGm.SetGlobalBuffer((__gm__ float*)mean, this->meanRstdSize); rstdGm.SetGlobalBuffer((__gm__ float*)rstd, this->meanRstdSize); yGm.SetGlobalBuffer((__gm__ DTYPE_X*)y, para.aLength * para.rLengthWithPadding); // pipe alloc memory to queue, the unit is Bytes pipe.InitBuffer(inQueueX, BUFFER_NUM, para.aLength * para.rLengthWithPadding * sizeof(DTYPE_X)); pipe.InitBuffer(inQueueGamma, BUFFER_NUM, para.rLengthWithPadding * sizeof(DTYPE_Y)); pipe.InitBuffer(inQueueBeta, BUFFER_NUM, para.rLengthWithPadding * sizeof(DTYPE_Y)); pipe.InitBuffer(outQueueMean, BUFFER_NUM, this->meanRstdSize * sizeof(float)); pipe.InitBuffer(outQueueRstd, BUFFER_NUM, this->meanRstdSize * sizeof(float)); pipe.InitBuffer(outQueueY, BUFFER_NUM, para.aLength * para.rLengthWithPadding * sizeof(DTYPE_X)); this->epsilon = epsilon; this->para = para; this->tiling = tiling; } __aicore__ inline void Compute() { AscendC::LocalTensor<DTYPE_X> xLocal = inQueueX.DeQue<DTYPE_X>(); AscendC::LocalTensor<DTYPE_Y> gammaLocal = inQueueGamma.DeQue<DTYPE_Y>(); AscendC::LocalTensor<DTYPE_Y> betaLocal = inQueueBeta.DeQue<DTYPE_Y>(); AscendC::LocalTensor<float> meanLocal = outQueueMean.AllocTensor<float>(); AscendC::LocalTensor<float> rstdLocal = outQueueRstd.AllocTensor<float>(); AscendC::LocalTensor<DTYPE_X> yLocal = outQueueY.AllocTensor<DTYPE_X>(); AscendC::Duplicate(meanLocal, (float)0, this->meanRstdSize); AscendC::Duplicate(rstdLocal, (float)0, this->meanRstdSize); AscendC::Duplicate(yLocal, (DTYPE_X)0, para.aLength * para.rLengthWithPadding); AscendC::LayerNorm<DTYPE_Y, DTYPE_X, false, CONFIG>(yLocal, meanLocal, rstdLocal, xLocal, gammaLocal, betaLocal, epsilon, para, tiling); outQueueMean.EnQue<float>(meanLocal); outQueueRstd.EnQue<float>(rstdLocal); outQueueY.EnQue<DTYPE_X>(yLocal); inQueueX.FreeTensor(xLocal); inQueueGamma.FreeTensor(gammaLocal); inQueueBeta.FreeTensor(betaLocal); } __aicore__ inline void Process() { CopyIn(); Compute(); CopyOut(); } private: __aicore__ inline void CopyIn() { // alloc tensor from queue memory AscendC::LocalTensor<DTYPE_X> xLocal = inQueueX.AllocTensor<DTYPE_X>(); AscendC::LocalTensor<DTYPE_Y> gammaLocal = inQueueGamma.AllocTensor<DTYPE_Y>(); AscendC::LocalTensor<DTYPE_Y> betaLocal = inQueueBeta.AllocTensor<DTYPE_Y>(); // copy progress_th tile from global tensor to local tensor AscendC::DataCopy(xLocal, xGm, para.aLength * para.rLengthWithPadding); AscendC::DataCopy(gammaLocal, gammaGm, para.rLengthWithPadding); AscendC::DataCopy(betaLocal, betaGm, para.rLengthWithPadding); // enque input tensors to VECIN queue inQueueX.EnQue(xLocal); inQueueGamma.EnQue(gammaLocal); inQueueBeta.EnQue(betaLocal); } __aicore__ inline void CopyOut() { // deque output tensor from VECOUT queue AscendC::LocalTensor<float> meanLocal = outQueueMean.DeQue<float>(); AscendC::LocalTensor<float> rstdLocal = outQueueRstd.DeQue<float>(); AscendC::LocalTensor<DTYPE_X> yLocal = outQueueY.DeQue<DTYPE_X>(); // copy progress_th tile from local tensor to global tensor AscendC::DataCopy(meanGm, meanLocal, this->meanRstdSize); AscendC::DataCopy(rstdGm, rstdLocal, this->meanRstdSize); AscendC::DataCopy(yGm, yLocal, para.aLength * para.rLengthWithPadding); // free output tensor for reuse outQueueMean.FreeTensor(meanLocal); outQueueRstd.FreeTensor(rstdLocal); outQueueY.FreeTensor(yLocal); } private: AscendC::TPipe pipe; // create queues for input, in this case depth is equal to buffer num AscendC::TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX; AscendC::TQue<QuePosition::VECIN, BUFFER_NUM> inQueueGamma; AscendC::TQue<QuePosition::VECIN, BUFFER_NUM> inQueueBeta; // create queue for output, in this case depth is equal to buffer num AscendC::TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueMean; AscendC::TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueRstd; AscendC::TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueY; AscendC::GlobalTensor<DTYPE_X> xGm; AscendC::GlobalTensor<DTYPE_Y> gammaGm; AscendC::GlobalTensor<DTYPE_Y> betaGm; AscendC::GlobalTensor<float> meanGm; AscendC::GlobalTensor<float> rstdGm; AscendC::GlobalTensor<DTYPE_X> yGm; float epsilon; uint32_t meanRstdSize; AscendC::LayerNormPara para; AscendC::LayerNormSeparateTiling tiling; }; __aicore__ constexpr AscendC::LayerNormConfig GetLayerNormConfig(bool isNoBeta, bool isNoGamma) { return {.isNoBeta = isNoBeta, .isNoGamma = isNoGamma, .isOnlyOutput = false}; } // with beta and gamma constexpr AscendC::LayerNormConfig LNCFG_NORM1 = GetLayerNormConfig(false, false); constexpr AscendC::LayerNormConfig LNCFG_NOBETA = GetLayerNormConfig(true, false); constexpr AscendC::LayerNormConfig LNCFG_NOGAMMA = GetLayerNormConfig(false, true); constexpr AscendC::LayerNormConfig LNCFG_NOOPT = GetLayerNormConfig(true, true); extern "C" __global__ __aicore__ void layernorm_custom(GM_ADDR x, GM_ADDR gamma, GM_ADDR beta, GM_ADDR mean, GM_ADDR rstd, GM_ADDR y, GM_ADDR workspace, GM_ADDR tiling) { GET_TILING_DATA(tilingData, tiling); float epsilon = tilingData.espilon; AscendC::LayerNormPara para(tilingData.aLength, tilingData.rLengthWithPadding); if (TILING_KEY_IS(1)) { if (!tilingData.isNoBeta && !tilingData.isNoGamma) { KernelLayerNorm<LNCFG_NORM1> op; op.Init(x, gamma, beta, mean, rstd, y, epsilon, para, tilingData.tilingData); op.Process(); } else if (!tilingData.isNoBeta && tilingData.isNoGamma) { KernelLayerNorm<LNCFG_NOGAMMA> op; op.Init(x, gamma, beta, mean, rstd, y, epsilon, para, tilingData.tilingData); op.Process(); } else if (tilingData.isNoBeta && !tilingData.isNoGamma) { KernelLayerNorm<LNCFG_NOBETA> op; op.Init(x, gamma, beta, mean, rstd, y, epsilon, para, tilingData.tilingData); op.Process(); } else if (tilingData.isNoBeta && tilingData.isNoGamma) { KernelLayerNorm<LNCFG_NOOPT> op; op.Init(x, gamma, beta, mean, rstd, y, epsilon, para, tilingData.tilingData); op.Process(); } } }