功能说明
按元素以e、2、10为底做对数运算,计算公式如下,其中PAR表示矢量计算单元一个迭代能够处理的元素个数 :
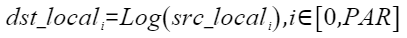
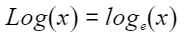
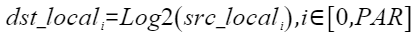
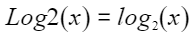
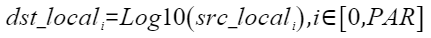
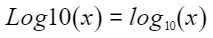
定义原型
- 以e为底:
template <typename T> __aicore__ inline void Log(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor)
- 以10为底:
template <typename T> __aicore__ inline void Log10(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor)
- 以2为底:
- 接口框架申请临时空间
template<typename T, bool isReplace = false, bool isBasicBlock = false> __aicore__ inline void Log2(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor)
- 通过tmpTensor入参传入临时空间
template<typename T, bool isReplace = false, bool isBasicBlock = false> __aicore__ inline void Log2(const LocalTensor<T> &dstTensor, const LocalTensor<T> &srcTensor, const LocalTensor<T> &tmpTensor)
由于Log2接口的内部实现中涉及复杂的数学计算,需要额外的临时空间来存储计算过程中的中间变量,仅输入为half类型时需要。临时空间支持接口框架申请和开发者通过tmpTensor入参传入两种方式。
- 接口框架申请临时空间,开发者无需申请,但是需要预留临时空间的大小。
- 通过tmpTensor入参传入,使用该tensor作为临时空间进行处理,接口框架不再申请。该方式开发者可以自行管理tmpTensor内存空间,并在接口调用完成后,复用该部分内存,内存不会反复申请释放,灵活性较高,内存利用率也较高。
接口支持开启基本块功能,基本块计算是一种分块计算的方式。当输入的数据量较大,当前环境可提供的临时空间不充足时,可以开启基本块功能,分块进行计算。请根据如下公式判断是否需要开启基本块:
开发者当前环境可提供的临时空间大于n * InputSize * sizeof(datatype)时,可以不使用基本块,否则建议使用基本块。针对half数据类型,n=4。
接口框架申请的方式,开发者需要预留临时空间;通过tmpTensor传入的情况,开发者需要为tensor申请空间。临时空间大小BufferSize的获取方式如下:
- 开启基本块功能,通过Log Tiling中提供的GetLog2MinTmpSize接口获取需要预留空间的大小。
- 不开启基本块功能,对于half数据类型,BufferSize = 4 * InputSize * Sizeof(half)。其中InputSize为输入元素个数。
- 接口框架申请临时空间
参数说明
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstLocal |
输出 |
目的操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 Atlas A2训练系列产品,支持的数据类型为:half/float |
srcLocal |
输入 |
源操作数。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 源操作数的数据类型需要与目的操作数保持一致。 Atlas A2训练系列产品,支持的数据类型为:half/float |
tmpTensor |
输入 |
中间操作数,Log2指令执行期间,需要一块临时空间用于存储中间结果。 类型为LocalTensor,支持的TPosition为VECIN/VECCALC/VECOUT。 若输入为half类型,临时空间的大小请参考定义原型。 若输入为float类型,不需要临时空间。 Atlas A2训练系列产品,支持的数据类型为:half/float |
isReuseSource |
输入 |
是否允许修改源操作数。该参数预留,传入默认值false即可。 |
isBasicBlock |
输入 |
是否使用基本块进行计算。 True: 若输入源数据数量大于基本块大小(1024),则会对输入数据进行分块,以块为单位进行处理。 False: 根据输入源数据量,分配相应的额外临时空间进行处理。 |
返回值
无
支持的型号
Atlas A2训练系列产品
约束说明
- 本指令函数由于只使用二级接口实现,运算量为目的LocalTensor的总长度。源操作数与目的操作数不允许同时使用(即地址不重叠)。
- 操作数地址偏移对齐要求请参见通用约束。
调用示例
本样例中只展示Compute流程中的部分代码。如果您需要运行样例代码,请将该代码段拷贝并替换样例模板中Compute函数的部分代码即可。
- Log接口样例
Log(dstLocal, srcLocal);
结果示例如下:输入数据(srcLocal): [144.22607 9634.764 ... 1835.1245 3145.5125] 输出数据(dstLocal): [4.971382 9.173133 ... 7.514868 8.053732]
- Log2接口样例
Log2(dstLocal, srcLocal);
结果示例如下:输入数据(srcLocal): [6299.54 338.45963 ... 2.853525 5752.1323] 输出数据(dstLocal): [12.621031 8.40284 ... 1.5127451 12.4898815]
- Log10接口样例
Log10(dstLocal, srcLocal);
结果示例如下:输入数据(srcLocal): [712.7535 78.36265 ... 3099.0571 9313.082] 输出数据(dstLocal): [2.8529394 1.8941091 ... 3.4912295 3.9690933]
样例模板
#include "kernel_operator.h"
namespace AscendC {
template <typename srcType>
class KernelLog {
public:
__aicore__ inline KernelLog()
{}
__aicore__ inline void Init(GM_ADDR src_gm, GM_ADDR dst_gm, uint32_t srcSize)
{
src_global.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(src_gm), srcSize);
dst_global.SetGlobalBuffer(reinterpret_cast<__gm__ srcType *>(dst_gm), srcSize);
pipe.InitBuffer(inQueueX, 1, srcSize * sizeof(srcType));
pipe.InitBuffer(outQueue, 1, srcSize * sizeof(srcType));
bufferSize = srcSize;
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<srcType> srcLocal = inQueueX.AllocTensor<srcType>();
DataCopy(srcLocal, src_global, bufferSize);
inQueueX.EnQue(srcLocal);
}
__aicore__ inline void Compute()
{
LocalTensor<srcType> dstLocal = outQueue.AllocTensor<srcType>();
LocalTensor<srcType> srcLocal = inQueueX.DeQue<srcType>();
Log(dstLocal, srcLocal);
//Log10(dstLocal, srcLocal);
//Log2<srcType, false, false>(dstLocal, srcLocal);
outQueue.EnQue<srcType>(dstLocal);
inQueueX.FreeTensor(srcLocal);
}
__aicore__ inline void CopyOut()
{
LocalTensor<srcType> dstLocal = outQueue.DeQue<srcType>();
DataCopy(dst_global, dstLocal, bufferSize);
outQueue.FreeTensor(dstLocal);
}
private:
GlobalTensor<srcType> src_global;
GlobalTensor<srcType> dst_global;
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueX;
TQue<QuePosition::VECOUT, 1> outQueue;
uint32_t bufferSize = 0;
};
template <typename dataType>
__aicore__ void kernel_log_operator(GM_ADDR src_gm, GM_ADDR dst_gm, uint32_t srcSize)
{
KernelLog<dataType> op;
op.Init(src_gm, dst_gm, srcSize);
op.Process();
}
} // namespace AscendC
extern "C" __global__ __aicore__ void kernel_log_operator(GM_ADDR src_gm, GM_ADDR dst_gm, uint32_t srcSize)
{
AscendC::kernel_log_operator<half>(src_gm, dst_gm, srcSize); //传入类型和大小
}