功能说明
Iterate后,获取一块C矩阵片,可以直接输出到GM tensor中,也可以输出到VECCALC tensor中。
该接口和Iterate接口配合使用,用于在调用Iterate完成迭代计算后,获取一片baseM * baseN大小的矩阵分片。
函数原型
- 同步模式
- 获取C矩阵,输出至VECCALC
- 针对Atlas A2训练系列产品:
template <bool sync = true, bool doPad = false>
__aicore__ inline void GetTensorC(const LocalTensor<DstT>& c, uint8_t enAtomic = 0, bool enSequentialWrite = false, uint32_t height = 0, uint32_t width = 0, uint32_t srcGap = 0, uint32_t dstGap = 0) {};
- 针对Atlas推理系列产品AI Core
template <bool sync = true>
__aicore__ inline void GetTensorC(const LocalTensor<DstT>& co2Local, uint8_t enAtomic = 0, bool enSequentialWrite = false);
- 针对Atlas A2训练系列产品:
- 获取C矩阵,输出至GM
__aicore__ inline void GetTensorC(const GlobalTensor<DstT>& gm, uint8_t enAtomic = 0, bool enSequentialWrite = false){};
- 获取C矩阵,同时输出至GM和VECCALC
__aicore__ inline void GetTensorC(const GlobalTensor<DstT> &c, const LocalTensor<DstT> &cLocal, uint8_t enAtomic = 0, bool enSequentialWrite = false) {};
- 获取C矩阵,输出至VECCALC
参数说明
参数名 |
描述 |
|---|---|
sync |
设置同步或者异步模式:同步模式设置为true;异步模式设置为false。 |
doPad |
该参数预留,开发者无需关注。 |
参数名 |
输入/输出 |
描述 |
|---|---|---|
c/co2Local |
输出 |
取出C矩阵到VECCALC,数据格式只能为NZ 针对Atlas A2训练系列产品:数据类型T可以为half、float、bfloat16_t 针对Atlas推理系列产品AI Core:数据类型T可以为half、float |
Gm |
输出 |
取出C矩阵到GM,数据格式可以为ND或NZ 针对Atlas A2训练系列产品:数据类型T可以为half、float、bfloat16_t 针对Atlas推理系列产品AI Core:数据类型T可以为half、float |
enAtomic |
输入 |
是否开启Atomic操作,默认值为0,注意:只有输出位置是GM才支持开启Atomic操作。 参数取值: 0:不开启Atomic操作 1:开启AtomicAdd累加操作 2:开启AtomicMax求最大值操作 3:开启AtomicMin求最小值操作 |
enSequentialWrite |
输入 |
是否开启连续写模式到GM(不跳写,写入[baseM,baseN];跳写,写入[singleCoreM、singleCoreN]中对应的位置),默认值false(跳写模式) |
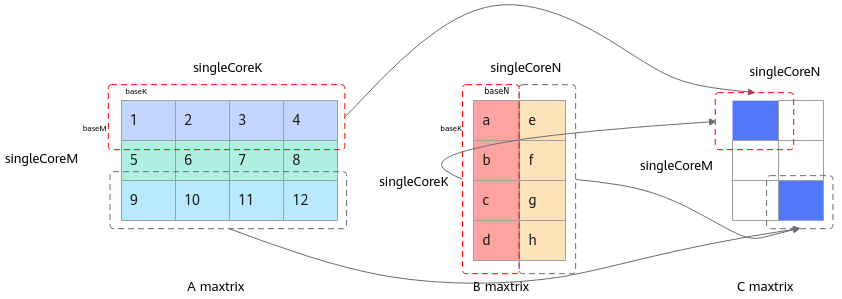

返回值
无
支持的型号
Atlas A2训练系列产品
Atlas推理系列产品AI Core
注意事项
传入的C矩阵地址空间大小需要保证不小于baseM * baseN。
调用示例
- 获取C矩阵,输出至VECCALC
// 同步模式样例 while (mm. Iterate ()) { mm. GetTensorC (ubCmatrix); } - 获取C矩阵,输出至GM,同步模式样例
while (mm.Iterate()) { mm.GetTensorC(gm); } - 获取C矩阵,同时输出至GM和VECCALC,同步模式样例
while (mm.Iterate()) { mm.GetTensorC(gm, ubCmatrix); }