功能说明
该接口提供数据非对齐搬运的功能,支持的数据传输通路如下:
GM->VECIN/VECOUT
VECIN/VECOUT->GM
其中从GM->VECIN/VECOUT进行数据搬运时,可以根据开发者的需要自行填充数据。
函数原型
通路:GM->VECIN/VECOUT
template<typename T> __aicore__ inline void DataCopyPad(const LocalTensor<T>& dstLocal, const GlobalTensor<T>& srcGlobal, const DataCopyParams& dataCopyParams, const DataCopyPadParams& padParams)
通路:VECIN/VECOUT->GM
template<typename T> __aicore__ inline void DataCopyPad(const GlobalTensor<T>& dstGlobal, const LocalTensor<T>& srcLocal,const DataCopyParams& dataCopyParams)
参数说明
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstLocal, dstGlobal |
输出 |
目的操作数,类型为LocalTensor或GlobalTensor。 Atlas A2训练系列产品,支持的数据类型为:half/int16_t/uint16_t/float/int32_t/uint32_t/int8_t/uint8_t |
srcLocal, srcGlobal |
输入 |
源操作数,类型为LocalTensor或GlobalTensor。 Atlas A2训练系列产品,支持的数据类型为:half/int16_t/uint16_t/float/int32_t/uint32_t/int8_t/uint8_t |
dataCopyParams |
输入 |
搬运参数。DataCopyParams类型,DataCopyParams结构定义请参考表2。 |
padParams |
输入 |
从GM->VECIN/VECOUT进行数据搬运时,可以根据开发者需要,在搬运数据左边或右边填充数据。padParams是用于控制数据填充过程的参数,DataCopyPadParams类型,DataCopyPadParams结构定义请参考表3。 |
参数名称 |
含义 |
|---|---|
blockCount |
指定该指令包含的连续传输数据块个数,取值范围:blockCount∈[1, 4095]。 |
blockLen |
指定该指令每个连续传输数据块长度,该指令支持非对齐搬运,每个连续传输数据块长度单位为Byte。取值范围:blockLen∈[1, 65535]。 |
srcStride |
源操作数,相邻连续数据块的间隔(前面一个数据块的尾与后面数据块的头的间隔),如果源操作数的逻辑位置为VECIN/VECOUT,则单位为dataBlock(32Bytes), 如果源操作数的逻辑位置为GM,则单位为Byte。 |
dstStride |
目的操作数,相邻连续数据块间的间隔(前面一个数据块的尾与后面数据块的头的间隔),如果目的操作数的逻辑位置为VECIN/VECOUT,则单位为dataBlock(32Bytes),如果目的操作数的逻辑位置为GM,则单位为Byte。 |
参数名称 |
含义 |
|---|---|
isPad |
是否需要填充数据,取值范围:true,false。 |
leftPadding |
连续搬运数据块左侧需要补充的数据范围,单位为元素个数。leftPadding+rightPadding的字节数之和不能超过32Bytes。 |
rightPadding |
连续搬运数据块右侧需要补充的数据范围,单位为元素个数。leftPadding+rightPadding的字节数之和不能超过32Bytes。 |
paddingValue |
左右两侧需要填充的数据值,需要保证在数据占用字节范围内。 |
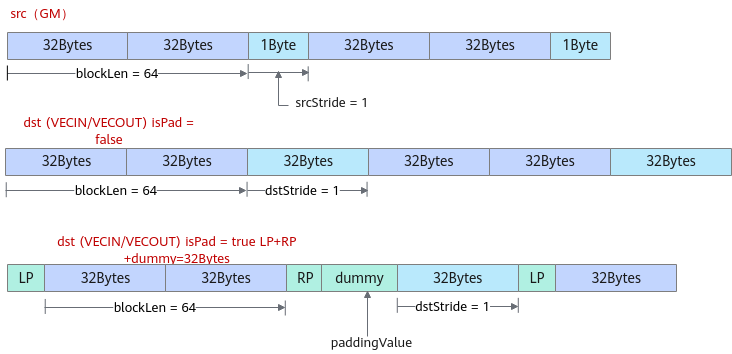
- GM->VECIN/VECOUT, 当每个连续传输数据块长度blockLen为32字节对齐时,下图呈现了需要传入的DataCopyParams和PadParams示例。
- isPad设置为false,表示不进行数据填充,DataCopyParams参数解释如下:blockLen为64,每个连续传输数据块包含64Bytes;srcStride为1,因为源操作数的逻辑位置为GM,srcStride的单位为Byte,也就是说源操作数相邻数据块之间间隔1Byte;dstStride为1,因为目的操作数的逻辑位置为VECIN/VECOUT,dstStride的单位为dataBlock(32Bytes),也就是说目的操作数相邻数据块之间间隔1个dataBlock。
- isPad设置为true时,表示需要进行数据填充,除了需要传入DataCopyParams参数(blockLen=64、srcStride=1、dstStride=1),还需要传入PadParams参数,LP为连续传输数据块左侧填充的数据长度,RP为数据块右侧填充的数据长度,paddingValue为填充值。由于Unified Buffer要求32字节对齐,左右填充的数据不满足32字节对齐时,框架会填充一些假数据dummy,保证左右填充的数据和假数据为32字节对齐(本示例中LP+RP+dummy=32Bytes),假数据的值和左右填充的数据值paddingValue相同。
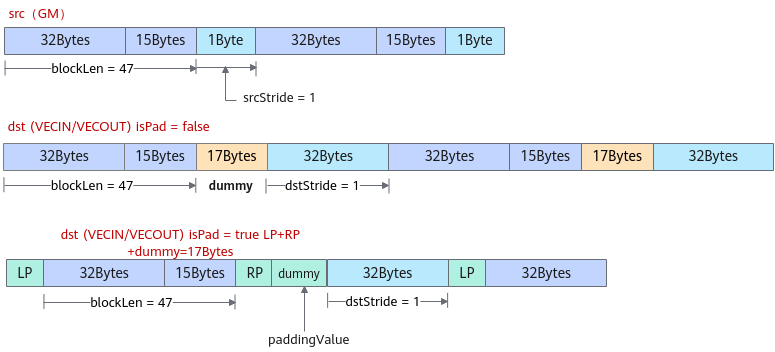
- GM->VECIN/VECOUT, 当每个连续传输数据块长度blockLen为非32字节对齐时,下图呈现了需要传入的DataCopyParams和PadParams示例。
- isPad设置为false,表示不进行数据填充,DataCopyParams参数解释如下:blockLen为47,每个连续传输数据块包含47Bytes;srcStride为1,表示源操作数相邻数据块之间间隔1Byte;dstStride为1,表示目的操作数相邻数据块之间间隔1个dataBlock。由于Unified Buffer要求32字节对齐,框架会填充一些假数据dummy,保证左32字节对齐,假数据的值和连续传输数据块中的第一个元素数值相同。
- isPad设置为true时,表示需要进行数据填充,除了需要传入DataCopyParams参数(blockLen=47、srcStride=1、dstStride=1),还需要传入PadParams参数,LP为连续传输数据块左侧填充的数据长度,RP为数据块右侧填充的数据长度,paddingValue为填充值。由于Unified Buffer要求32字节对齐,左右填充的数据和blockLen不满足32字节时,框架会填充一些假数据dummy,保证需要左右填充数据、假数据和blockLen32字节对齐,对齐至32字节的最小倍数。此时的假数据和左右填充的数据值paddingValue相同。
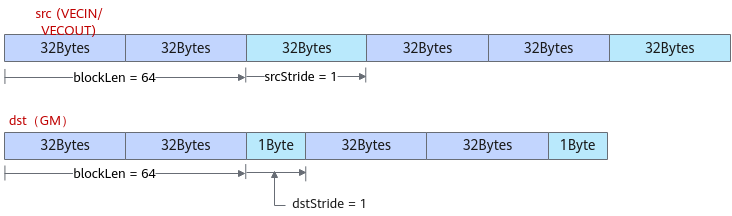
- VECIN/VECOUT->GM, 当每个连续传输数据块长度blockLen为32字节对齐时,下图呈现了需要传入的DataCopyParams示例,blockLen为64,每个连续传输数据块包含64Bytes;srcStride为1,因为源操作数的逻辑位置为VECIN/VECOUT,srcStride的单位为dataBlock(32Bytes),也就是说源操作数相邻数据块之间间隔1个dataBlock;dstStride为1,因为目的操作数的逻辑位置为GM,dstStride的单位为Byte,也就是说目的操作数相邻数据块之间间隔1Byte。
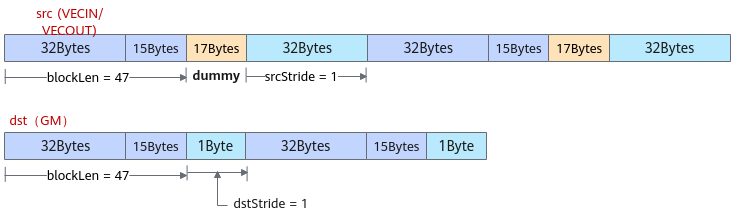
- VECIN/VECOUT->GM, 当每个连续传输数据块长度blockLen不满足32字节对齐,由于Unified Buffer要求32字节对齐,框架在搬出时会自动补充一些假数据来保证对齐,但在当搬到GM时会自动将填充的假数据丢弃掉。下图呈现了该场景下需要传入的DataCopyParams示例和假数据补齐的原理。blockLen为47,每个连续传输数据块包含47Bytes,不满足32字节对齐;srcStride为1,表示源操作数相邻数据块之间间隔1个dataBlock;dstStride为1,表示目的操作数相邻数据块之间间隔1Byte。框架在搬出时会自动补充17Bytes的假数据来保证对齐,搬到GM时再自动将填充的假数据丢弃掉。
返回值
无
支持的型号
Atlas A2训练系列产品
约束说明
leftPadding+rightPadding的字节数之和不能超过32Bytes。
调用示例
#include "kernel_operator.h"
namespace AscendC {
class TestDataCopyPad {
public:
__aicore__ inline TestDataCopyPad()() {}
__aicore__ inline void Init(__gm__ uint8_t* srcGm, __gm__ uint8_t* dstGm)
{
srcGlobal.SetGlobalBuffer((__gm__ half *)srcGm);
dstGlobal.SetGlobalBuffer((__gm__ half *)dstGm);
pipe.InitBuffer(inQueueSrcVecIn, 1, 64 * sizeof(half));
}
__aicore__ inline void Process()
{
CopyIn();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<half> srcLocal = inQueueSrcVecIn.AllocTensor<half>();
DataCopyParams copyParams{1, 20 * sizeof(half), 0, 0};
DataCopyPadParams padParams{true, 0, 2, 0};
DataCopyPad(srcLocal, srcGlobal, copyParams, padParams); // 从GM->VECIN搬运20Bytes
inQueueSrcVecIn.EnQue<half>(srcLocal);
}
__aicore__ inline void CopyOut()
{
LocalTensor<half> ubLocal = inQueueSrcVecIn.DeQue<half>();
DataCopyParams copyParams{1, 20 * sizeof(half), 0, 0};
DataCopyPad(dstGlobal, ubLocal, copyParams); // 从VECIN->GM搬运20Bytes
inQueueSrcVecIn.FreeTensor(ubLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueSrcVecIn;
GlobalTensor<T> srcGlobal;
GlobalTensor<T> dstGlobal;
};
}
extern "C" __global__ __aicore__ void kernel_data_copy_pad_kernel(__gm__ uint8_t* src_gm, __gm__ uint8_t* dst_gm)
{
AscendC::TestDataCopyPad op;
op.Init(src_gm, dst_gm);
op.Process();
}
输入数据(src0Global): [1 2 3 ... 64] 输出数据(dstGlobal):[1 2 3 ... 20]