在开发算子代码之前需要分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend C接口。
- 明确算子的数学表达式及计算逻辑。Matmul算子完成矩阵乘操作,其数学表达式如下,形状为[m, k]的矩阵a和形状为[k, n]的矩阵b相乘,得到形状为[m, n]的矩阵c。为了方便,令m=k=n=32。
c = a * b
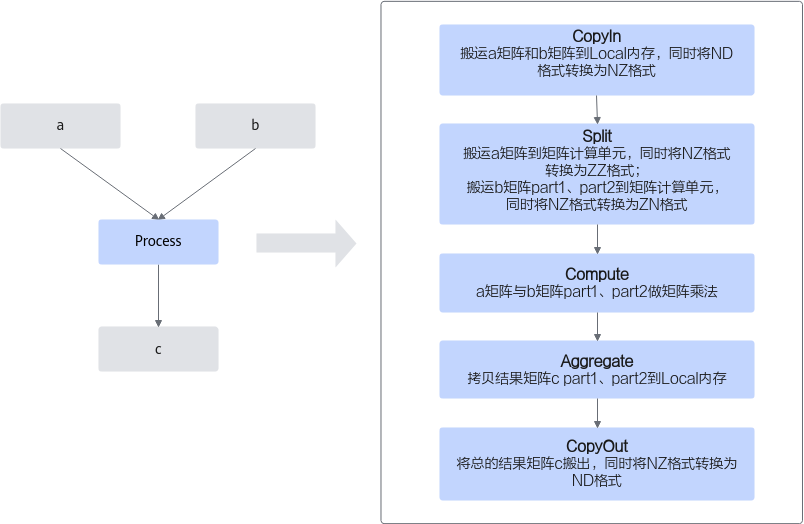
注意需要处理的数据过大时,需要对数据进行切分并分块搬运到A2、B2,分别计算后再进行汇聚。下文的计算逻辑为了展示Split和Aggregate阶段的样例,请您根据实际需要处理的数据大小决定是否需要切分和汇聚。
计算逻辑如下:- 分别搬运输入数据矩阵a、b至Local Memory A1、B1。
- 将a矩阵从A1搬运至A2。将b矩阵切分为part1和part2,形状均为[k, n / 2],切分后再分块搬运至B2。
- a矩阵和b矩阵part1、part2分别做矩阵乘运算,获得矩阵c的part1和part2,形状均为[m, n / 2]。计算结果在CO1存储。
- 将矩阵c的part1和part2分别拷贝到CO2进行合并。
- 将合并后的输出数据从CO2搬出。
- 明确输入和输出。
- Matmul算子有两个输入:a与b,输出为c。
- 本样例中算子输入支持的数据类型为half(float16),算子输出的数据类型为float32。
- 矩阵a、b、c的形状均为[32, 32]。
- 算子输入输出支持的数据格式为:ND。
- 确定核函数名称和参数。
- 您可以自定义核函数名称,本样例中核函数命名为matmul_custom。
- 根据对算子输入输出的分析,确定核函数有3个参数a,b,c;a,b为输入在Global Memory上的内存地址,c为输出在Global Memory上的内存地址。
- 约束分析。
由于硬件架构对矩阵乘计算的输入输出有格式约束,需要在算子实现中增加格式转换的流程。
- 搬运矩阵a、b至A1、B1时,将ND格式的矩阵a、b转换为NZ格式。
- 从A1搬运矩阵a至A2时,将NZ格式的a矩阵转换为ZZ格式;从B1搬运矩阵b到B2时将NZ格式的b矩阵转换为ZN格式。
- 将计算结果从CO2搬出时,将NZ格式的c矩阵转换为ND格式。
- 确定算子实现所需接口。
通过以上分析,得到Ascend C Matmul算子的计算流程图和设计规格如下:
图1 Matmul算子的计算流程图
算子类型(OpType) |
Matmul |
|||
|---|---|---|---|---|
算子输入 |
name |
shape |
data type |
format |
a |
(m, k) = (32, 32) |
half |
ND |
|
b |
(k, n) = (32, 32) |
half |
ND |
|
算子输出 |
c |
(m, n) = (32, 32) |
float32 |
ND |
核函数名称 |
matmul_custom |
|||
使用的主要接口 |
DataCopy:数据搬移接口 |
|||
LoadData:矩阵数据格式转换接口 |
||||
Mmad:矩阵乘计算接口 |
||||
EnQue、DeQue等接口:Queue队列管理接口 |
||||
算子实现文件名称 |
matmul_custom.cpp |
|||