Atlas 训练系列产品不支持该算子。
Atlas A2训练系列产品支持该算子。
该接口为试验版本,当前不支持应用于商用产品中,后续版本会作为正式功能更新发布。
接口原型
每个算子分为两段式接口,必须先调用“aclnnMoeGatingTopKSoftmaxGetWorkspaceSize”接口获取入参并根据计算流程计算所需workspace大小,再调用“aclnnMoeGatingTopKSoftmax”接口执行计算。
- aclnnStatus aclnnMoeGatingTopKSoftmaxGetWorkspaceSize(const aclTensor *x, const aclTensor *finishedOptional, int64_t k, const aclTensor *yOut, const aclTensor *expertIdxOut, const aclTensor *rowIdxOut, uint64_t *workspaceSize, aclOpExecutor **executor)
- aclnnStatus aclnnMoeGatingTopKSoftmax(void* workspace, uint64_t workspaceSize, aclOpExecutor* executor, const aclrtStream stream)
功能描述
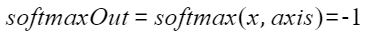
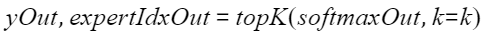
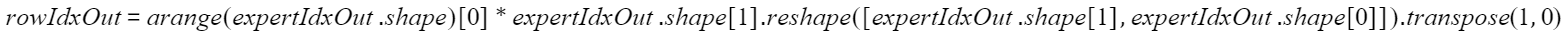
aclnnMoeGatingTopKSoftmaxGetWorkspaceSize
- 参数说明:
- x(aclTensor*,计算输入):待计算的输入,要求是一个2D/3D的Tensor,数据类型支持FLOAT16、BFLOAT16、FLOAT32,数据格式要求为ND。
- finishedOptional(aclTensor*,可选计算输入):要求是一个1D/2D的Tensor,数据类型支持bool,shape为x_shape[:-1],数据格式要求为ND。
- k(int64_t,计算输入):topk的k值,大小为0 <= k <= gating的-1轴大小。
- yOut(aclTensor*, 计算输出):对x做softmax后取的topk值,要求是一个2D/3D的Tensor,数据类型与x需要保持一致,其非-1轴要求与x的对应轴大小一致,其-1轴要求其大小同k值。数据格式要求为ND。
- expertIdxOut(aclTensor*, 计算输出):对x做softmax后取topk值的索引,即专家的序号。shape要求与yOut一致。数据类型支持int32,数据格式要求为ND。
- rowIdxOut(aclTensor*, 计算输出):指示每个位置对应的原始行位置(见示例),shape要求与yOut一致。数据类型支持int32,数据格式要求为ND。
- workspaceSize(uint64_t*,出参):Device侧的整型,返回需要在Device侧申请的workspace大小。
- executor(aclOpExecutor**,出参):Device侧的aclOpExecutor,返回op执行器,包含了算子计算流程。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
aclnnMoeGatingTopKSoftmax
- 参数说明:
- workspace(void*,入参):在Device侧申请的workspace内存起址。
- workspaceSize(uint64_t,入参):在Device侧申请的workspace大小,由aclnnMoeGatingTopKSoftmaxGetWorkspaceSize获取。
- executor(aclOpExecutor*,入参):op执行器,包含了算子计算流程。
- stream(aclrtStream,入参):指定执行任务的AscendCL stream流。
- 返回值:
返回aclnnStatus状态码,具体参见aclnn返回码。
约束与限制
专家个数不超过1024个。
调用示例
constexpr int opt_case_id = 1000;
constexpr int opt_op_type = 1001;
//通用参数
constexpr int op_gating_dim0 = 1011;
constexpr int op_gating_dim1 = 1012;
constexpr int op_finished_dim0 = 1013;
constexpr int op_device_id = 1014;
constexpr int op_tensor_format = 1050;
constexpr int op_tensor_type = 1051;
constexpr int op_thread_num = 1052;
constexpr int op_input_path = 1053;
constexpr int op_output_path = 1054;
constexpr int op_top_k = 1055;
constexpr int op_num_experts=1056;
constexpr int op_device_num = 1057;
constexpr int op_sat_mode = 1058;
const char * tmp_err_msg = NULL;
//其他参数
constexpr int op_loop_times = 10;
constexpr int DEVICE_NUM_MAX = 8;
//全局变量定义
int64_t gCaseId;
std::string gOpType;
int64_t g_gating_dim0 = 1;
int64_t g_gating_dim1 = 1;
int64_t g_finished_dim0 = 1024;
int64_t g_poolSize = 1;
int64_t g_loop_times = 1;
int64_t g_device_num = 1;
int64_t g_device_id = 0;
int64_t g_thread_num = 1;
int64_t g_topk = 2;
int64_t g_num_experts =16;
uint64_t g_fisrt = 0;
uint64_t g_last =0;
int g_sat_mode = 0;
std::string g_str_input_format;
std::string g_str_output_format;
std::string g_input_path;
std::string g_output_path;
aclDataType g_tensor_type[16]={aclDataType::ACL_DT_UNDEFINED};
aclFormat g_tensor_format[16] ={ACL_FORMAT_ND};
std::map<std::string,aclDataType>g_data_type_map =
{
{"FLOAT" , ACL_FLOAT},
{"FP16" , ACL_FLOAT16},
{"INT8" , ACL_INT8},
{"INT16" , ACL_INT16},
{"UINT16" , ACL_UINT16},
{"UINT8" , ACL_UINT8},
{"INT32" , ACL_INT32},
{"INT64" , ACL_INT64},
{"UINT32" , ACL_UINT32},
{"BOOL" , ACL_BOOL},
{"DOUBLE" , ACL_DOUBLE},
{"BF16" , ACL_BF16},
{"UNDEFINED", ACL_DT_UNDEFINED}
};
int Init(int32_t deviceId, aclrtContext* context, aclrtStream* stream) {
// 固定写法,acl初始化
auto ret = aclInit(nullptr); // profiling需要aclint,如果不需要profiling则不需要此步骤
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclInit failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetDevice(deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateContext(context, deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtSetCurrentContext(*context);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetCurrentContext failed. ERROR: %d\n", ret); return ret);
ret = aclrtCreateStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateStream failed. ERROR: %d\n", ret); return ret);
return 0;
}
template <typename T>
int CreateAclTensor(const std::vector<T>& hostData, const std::vector<int64_t>& shape, void** deviceAddr,
aclDataType dataType, aclTensor** tensor, aclFormat tensorFormat) {
auto size = GetShapeSize(shape) * sizeof(T);
printf("Alloc size [%zu] for tensor\n", size);
// 调用aclrtMalloc申请device侧内存
auto ret = aclrtMalloc(deviceAddr, size, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ret);
// 调用aclrtMemcpy将host侧数据拷贝到device侧内存上
ret = aclrtMemcpy(*deviceAddr, size, hostData.data(), size, ACL_MEMCPY_HOST_TO_DEVICE);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMemcpy failed. ERROR: %d\n", ret); return ret);
// 计算连续tensor的strides
std::vector<int64_t> strides(shape.size(), 1);
for (int64_t i = shape.size() - 2; i >= 0; i--)
{
strides[i] = shape[i + 1] * strides[i + 1];
}
// 调用aclCreateTensor接口创建aclTensor
*tensor = aclCreateTensor(shape.data(), shape.size(), dataType, strides.data(), 0, tensorFormat,
shape.data(), shape.size(), *deviceAddr);
return 0;
}
void FreeDeviceMem(void* addr)
{
if (addr != nullptr)
{
aclrtFree(addr);
}
}
void DestroyAclTensor(aclTensor* tensor, void* addr)
{
FreeDeviceMem(addr);
aclDestroyTensor(tensor);
tensor = nullptr;
}
void MoEGatingTopKSoftmax(void *args)
{
ThreadData *threadData;
threadData = (ThreadData *) args;
int threadId = threadData->threadId;
int device_id = threadData->device_id;
auto tensors = threadData->tensors;
auto out_size = threadData->tensor_size[2];
auto indicesOut_size = threadData->tensor_size[3];
auto sourceRowOut_size = threadData->tensor_size[4];
auto dev_mem = threadData->dev_mem;
auto expert_tokens = threadData->expert_tokens;
aclrtContext context = threadData->context;
aclrtStream stream;
auto ret = aclrtSetCurrentContext(context);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("threadId %d aclrtSetCurrentContext failed. ERROR: %d\n",threadId, ret); return ;);
ret= aclrtSetDeviceSatMode((aclrtFloatOverflowMode)g_sat_mode);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("threadId %d aclrtSetDeviceSatMode failed. ERROR: %d\n",threadId, ret); return ;);
ret = aclrtCreateStream(&stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("threadId %d aclrtCreateStream failed. ERROR: %d\n",threadId, ret); return ;);
aclOpExecutor *executor;
uint64_t workspaceSize;
aclrtMemAttr attr = ACL_HBM_MEM;
size_t mem_free;
size_t mem_total;
size_t aa = 1024;
for(int i = 0;i < g_loop_times; i++)
{
ret = aclnnMoeGatingTopKSoftmaxGetWorkspaceSize(tensors[0], tensors[1], g_topk, tensors[2], tensors[3], tensors[4], &workspaceSize, &executor);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnMoeGatingTopKSoftmaxGetWorkspaceSize failed. ERROR: %d\n", ret); return ;);
printf("aclnnMoeGatingTopKSoftmaxGetWorkspaceSize workspace size is %ld \n",workspaceSize);
void *workspace = NULL;
if (workspaceSize != 0)
{
ret = aclrtMalloc(&workspace, workspaceSize, ACL_MEM_MALLOC_HUGE_FIRST);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtMalloc failed. ERROR: %d\n", ret); return ;);
}
ret = aclnnMoeGatingTopKSoftmax(&workspace, workspaceSize, executor, stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclnnMoEGatingTopKSoftmax failed. ERROR: %d\n", ret); return ;);
ret = aclrtSynchronizeStream(stream);
if( i == g_loop_times -1 )
{
ret = aclrtGetMemInfo(attr, &mem_free, &mem_total);
size_t mem_used_after = (mem_total-mem_free)/aa/aa;
printf(" after run : free :%ld M, total:%ld M, used :%ld M, ret :%d \n", mem_free/aa/aa, mem_total/aa/aa, mem_used_after, ret);
g_last = mem_free/aa/aa;
printf(" op cost memory :%ld M \n", g_fisrt-g_last);
}
tmp_err_msg = aclGetRecentErrMsg();
if(tmp_err_msg !=NULL)
{ printf(" ERROR Message : %s \n " ,tmp_err_msg);}
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSynchronizeStream failed. ERROR: %d\n", ret); return ;);
if(workspaceSize != 0)
{
aclrtFree(workspace);
}
}
tmp_err_msg = aclGetRecentErrMsg();
if(tmp_err_msg != NULL)
{
printf(" ERROR Message : %s \n " ,tmp_err_msg);
}
void *host_data1 = malloc(out_size);
aclrtMemcpy(host_data1, out_size, dev_mem[2], out_size, ACL_MEMCPY_DEVICE_TO_HOST);
WriteFile(g_output_path +"_"+ std::to_string(device_id) + "_"+std::to_string(threadId) + "out.bin", host_data1, out_size);
free(host_data1);
void *host_data2 = malloc(indicesOut_size);
aclrtMemcpy(host_data2, indicesOut_size, dev_mem[3], indicesOut_size, ACL_MEMCPY_DEVICE_TO_HOST);
WriteFile(g_output_path +"_"+ std::to_string(device_id) + "_"+std::to_string(threadId) + "indices_out.bin", host_data2, indicesOut_size);
free(host_data2);
void *host_data3 = malloc(sourceRowOut_size);
aclrtMemcpy(host_data3, sourceRowOut_size, dev_mem[4], sourceRowOut_size, ACL_MEMCPY_DEVICE_TO_HOST);
WriteFile(g_output_path +"_"+ std::to_string(device_id) + "_"+std::to_string(threadId) + "source_row_out.bin", host_data3, sourceRowOut_size);
free(host_data3);
ret = aclrtDestroyStream(stream);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("threadId %d aclrtDestroyStream failed. ERROR: %d\n",threadId, ret); return ;);
}
struct option long_options[] =
{
// 图像类参数
{"case_id", 1, nullptr, opt_case_id},
{"op_type", 1, nullptr, opt_op_type},
{"gating_dim0", 1, nullptr, op_gating_dim0},
{"gating_dim1", 1, nullptr, op_gating_dim1},
{"finished_dim0", 1, nullptr, op_finished_dim0},
{"num_experts",1, nullptr, op_num_experts},
{"thread_num", 1, nullptr, op_thread_num},
{"device_num", 1, nullptr, op_device_num},
{"device_id", 1, nullptr, op_device_id},
{"tensor_type", 1, nullptr, op_tensor_type},
{"loop", 1, nullptr, op_loop_times},
{"tensor_format",1, nullptr, op_tensor_format},
{"topK", 1, nullptr, op_top_k},
{"input_path", 1, nullptr, op_input_path},
{"output_path", 1, nullptr, op_output_path},
{"sat_mode", 1, nullptr, op_sat_mode},
};
bool is_argv_in_options(std::string &argv_str)
{
for (int option_index = 0; option_index < sizeof(long_options) / sizeof(struct option); option_index++) {
std::string option_str = std::string("--") + std::string(long_options[option_index].name);
if (argv_str == option_str) {
return true;
}
}
return false;
}
int32_t check_argv(int argc, char *argv[])
{
for (int argc_index = 0; argc_index < argc; argc_index++)
{
std::string argv_str(argv[argc_index]);
if (argv_str.find(std::string("--")) != std::string::npos)
{
bool find_flag = is_argv_in_options(argv_str);
if (find_flag == false) {
printf("argv:%s not support.\n", argv_str.c_str());
return -1;
}
}
}
return 0;
}
int32_t get_option(int argc, char **argv) {
if (check_argv(argc, argv) != 0) {
return -1;
}
while (1) {
int32_t option_index = 0;
int32_t option_value = getopt_long(argc, argv, "", long_options, &option_index);
if (option_value == -1)
{
break;
}
switch (option_value) {
case opt_case_id:
gCaseId = atoi(optarg);
break;
case opt_op_type:
gOpType = optarg;
break;
case op_gating_dim0:
g_gating_dim0 = atoi(optarg);
break;
case op_gating_dim1:
g_gating_dim1 = atoi(optarg);
break;
case op_finished_dim0:
g_finished_dim0 = atoi(optarg);
break;
case op_thread_num:
g_thread_num = atoi(optarg);
break;
case op_loop_times:
g_loop_times = atoi(optarg);
break;
case op_device_num:
g_device_num = atoi(optarg);
break;
case op_input_path:
g_input_path = optarg;
break;
case op_output_path:
g_output_path = optarg;
break;
case op_device_id:
g_device_id = atoi(optarg);
break;
case op_top_k:
g_topk = atoi(optarg);
break;
case op_tensor_type:
{
std::vector<std::string> tokens;
split(optarg,tokens,':');
for(int i = 0;i<tokens.size();i++)
{
g_tensor_type[i] = g_data_type_map[tokens[i]];
printf(" token is %s, tensor_type is %d \n ",tokens[i].c_str(),g_tensor_type[i]);
}
}
break;
case op_tensor_format:
{
std::vector<std::string> tokens;
split(optarg,tokens,':');
for(int i = 0;i<tokens.size();i++)
{
g_tensor_format[i] =(aclFormat)atoi(tokens[i].c_str());
}
}
break;
case op_num_experts:
g_num_experts = atoi(optarg);
break;
case op_sat_mode:
g_sat_mode = atoi(optarg);
break;
default:
printf("invalid para %d", option_value);
break;
}
}
return 0;
}
int main(int argc, char **argv)
{
get_option(argc,&(*argv));
aclError ret;
ret = aclInit(NULL);
std::vector<std::thread>vec_thread;
aclTensor *v_tensors[DEVICE_NUM_MAX][g_thread_num][15];
void *v_dev_mem[DEVICE_NUM_MAX][g_thread_num][15];
size_t v_tensors_size[DEVICE_NUM_MAX][g_thread_num][15]={0};
ThreadData threadData[DEVICE_NUM_MAX][g_thread_num];
std::vector<aclrtContext> vec_context;
int64_t shape1[] = {g_gating_dim0,g_gating_dim1}; //gating
int64_t shape2[] = {g_finished_dim0};//finishedOptional
int64_t shape3[] = {g_gating_dim0,g_topk};//out
int64_t shape4[] = {g_gating_dim0,g_topk};//indicesOut
int64_t shape5[] = {g_gating_dim0,g_topk};//sourceRowOut
tensor_info tensor_desc[]=
{
{shape1,2,g_tensor_type[0],g_tensor_format[0]},
{shape2,1,g_tensor_type[1],g_tensor_format[1]},
{shape3,2,g_tensor_type[2],g_tensor_format[2]},
{shape4,2,g_tensor_type[3],g_tensor_format[3]},
{shape5,2,g_tensor_type[4],g_tensor_format[4]},
};
std::string bin_path[] = {"gating.bin", "finished.bin"};
if(g_device_num == 1)//指定某一个device上运行
{
ret = aclrtSetDevice(g_device_id);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
aclrtMemAttr attr = ACL_HBM_MEM;
size_t mem_free;
size_t mem_total;
size_t aa = 1024;
ret = aclrtGetMemInfo(attr, &mem_free, &mem_total);
size_t mem_used_after = (mem_total-mem_free)/aa/aa;
printf(" after run : free :%ld M, total:%ld M, used :%ld M, ret :%d \n", mem_free/aa/aa, mem_total/aa/aa, mem_used_after, ret);
g_fisrt = mem_free/aa/aa;
aclrtContext context;
ret = (aclrtCreateContext(&context, g_device_id) != ACL_SUCCESS);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret);
for(int threadId = 0;threadId< g_thread_num; threadId++)
{
int len = sizeof(tensor_desc)/sizeof(tensor_info);
printf("len is %d \n",len);
for(auto i = 0; i < len ;i++)
{
uint8_t *host;
void *data;
struct tensor_info *info = &(tensor_desc[i]);
size_t size = get_data_size(info);
std::cout<<"size :"<<size<<std::endl;
if (size == 0)
{
v_tensors[g_device_id][threadId][i] = NULL;
v_dev_mem[g_device_id][threadId][i] = NULL;
continue;
}
if(aclrtMallocHost((void**)(&host), size)!= ACL_SUCCESS)
{
printf("Malloc host memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
if (aclrtMalloc(&data, size, ACL_MEM_MALLOC_HUGE_FIRST) != ACL_SUCCESS)
{
printf("Malloc device memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
v_tensors_size[g_device_id][threadId][i] = size;
if(i<2)
{
ReadFile(g_input_path +"/"+ bin_path[i], size, host, size);
if(aclrtMemcpy(data, size, host, size, ACL_MEMCPY_HOST_TO_DEVICE) !=ACL_SUCCESS)
{
printf("Malloc device memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
}
v_dev_mem[g_device_id][threadId][i] = data;
v_tensors[g_device_id][threadId][i] = aclCreateTensor(info->dims, info->dim_cnt, info->dtype, NULL, 0, info->fmt, info->dims, info->dim_cnt, data);
}
threadData[g_device_id][threadId].threadId = threadId;
threadData[g_device_id][threadId].device_id = g_device_id;
for(int num= 0 ;num < len; num ++)
{
threadData[g_device_id][threadId].tensors[num] = v_tensors[g_device_id][threadId][num];
threadData[g_device_id][threadId].tensor_size[num] = v_tensors_size[g_device_id][threadId][num];
threadData[g_device_id][threadId].dev_mem[num] = v_dev_mem[g_device_id][threadId][num];
}
threadData[g_device_id][threadId].context = context;
vec_thread.emplace_back(MoEGatingTopKSoftmax, &threadData[g_device_id][threadId]);
}
}
else
{
for(int deviceId = 0;deviceId < g_device_num; deviceId++ )
{
auto ret = aclrtSetDevice(deviceId);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtSetDevice failed. ERROR: %d\n", ret); return ret);
aclrtContext context;
ret = ( aclrtCreateContext(&context, deviceId) != ACL_SUCCESS);
CHECK_RET(ret == ACL_SUCCESS, LOG_PRINT("aclrtCreateContext failed. ERROR: %d\n", ret); return ret);
for(int threadId = 0;threadId< g_thread_num; threadId++)
{
int len = sizeof(tensor_desc)/sizeof(tensor_info);
printf("len is %d \n",len);
for(auto i = 0; i < len ;i++)
{
uint8_t *host;
void *data;
struct tensor_info *info = &(tensor_desc[i]);
size_t size = get_data_size(info);
std::cout<<"size :"<<size<<std::endl;
if (size == 0)
{
v_tensors[deviceId][threadId][i] = NULL;
v_dev_mem[deviceId][threadId][i] = NULL;
continue;
}
if(aclrtMallocHost((void**)(&host), size)!= ACL_SUCCESS)
{
printf("Malloc host memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
if (aclrtMalloc(&data, size, ACL_MEM_MALLOC_HUGE_FIRST) != ACL_SUCCESS)
{
printf("Malloc device memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
v_tensors_size[deviceId][threadId][i] = size;
if(i<2)
{
ReadFile(g_input_path +"/"+ bin_path[i], size, host, size);
if(aclrtMemcpy(data, size, host, size, ACL_MEMCPY_HOST_TO_DEVICE) !=ACL_SUCCESS)
{
printf("Malloc device memory failed, error message is:\n%s\n", aclGetRecentErrMsg());
return -1;
}
}
v_dev_mem[deviceId][threadId][i] = data;
v_tensors[deviceId][threadId][i] = aclCreateTensor(info->dims, info->dim_cnt, info->dtype, NULL, 0, info->fmt, info->dims, info->dim_cnt, data);
}
threadData[deviceId][threadId].threadId = threadId;
threadData[deviceId][threadId].device_id = deviceId;
for(int num = 0;num<len;num++)
{
threadData[deviceId][threadId].tensors[num] = v_tensors[deviceId][threadId][num];
threadData[deviceId][threadId].tensor_size[num] = v_tensors_size[deviceId][threadId][num];
threadData[deviceId][threadId].dev_mem[num] = v_dev_mem[deviceId][threadId][num];
}
threadData[deviceId][threadId].context = context;
vec_thread.emplace_back(MoEGatingTopKSoftmax, &threadData[deviceId][threadId]);
}
}
}
//资源初始化
for (auto &tmp:vec_thread)
{
if (tmp.joinable())
{
tmp.join();
}
}
if(g_device_num == 1)
{
ret = aclrtResetDevice(g_device_id);
}
else
{
for(int i = 0;i < g_device_num;i++ )
{
ret = aclrtResetDevice(i);
}
}
(void) aclFinalize();
}