当前大模型推理加速库的并行方案主要是Tensor Parallelism(张量并行),核心是将模型中的部分计算切分到不同Device上运行,最终通过通信算子合并计算结果。
一个带有两层Linear Layer(o = W*x + B)的MLP层的张量并行优化示例如图1所示。
第一个Linear的Weight和Bias在dim=1轴切分,第二个Linear的Weight在dim = 0 轴切分,Bias除以2,得到的两个结果z1和z2,最后通过AllReduce算子相加得到最终输出z。

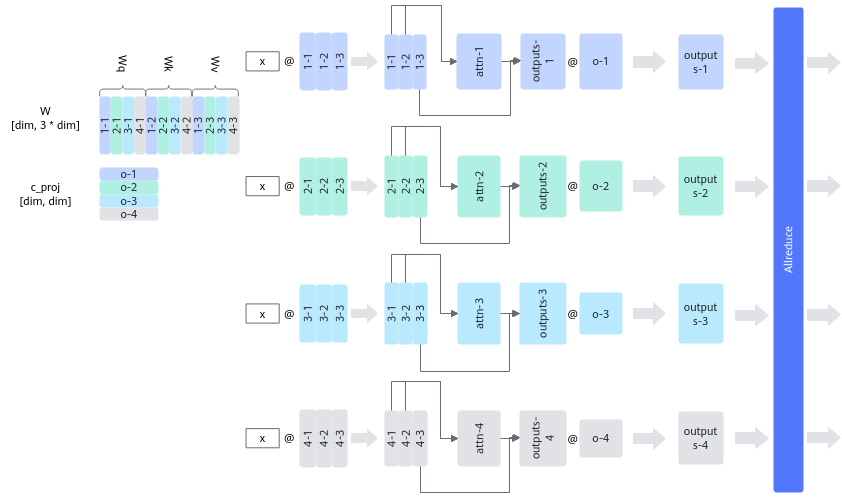
对于Attention Block,整体逻辑一致,需要对Q/K/V矩阵对应权重在dim = 1切分,然后将最后一个Linear的Weight在dim = 0轴切分,最后通过AllReduce算子相加得到最终输出结果,如图2所示。
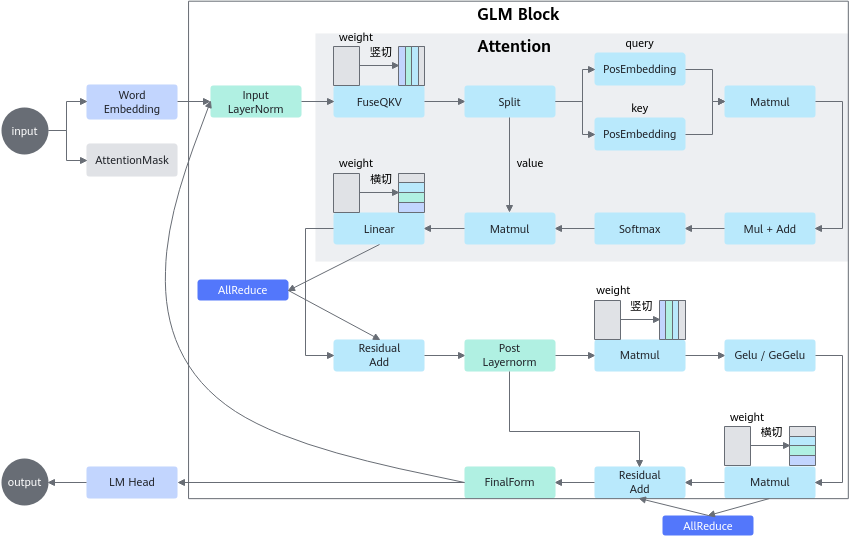
对于Transformer Block而言,其包含Attention Block和MLP层,整体切分思路是上述两个结构的组合,具体策略如下:
- Attention Block内:Attention中Q、K、V的权重在head轴竖切,最后一个linear的权重横切。
- MLP中gate_proj和up_proj的权重在 head 轴竖切,down_proj(最后一个)的权重横切。
- 插入通信算子:单层一共两个AllReduce,分别在Attention和Linear后,Add(残差)之前。
图3 Transformer Block张量并行