功能说明
对输入tensor做grad反向计算,当前仅支持传入shape为ND格式,内部的reduce过程都是按last轴进行。
SoftmaxGrad其公式如下:
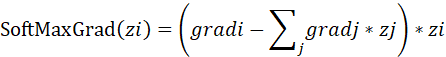
函数原型
template <typename T, bool isReuseSource = false>
void SoftmaxGrad(const LocalTensor<T>& dstTensor, const LocalTensor<T>& gradTensor,
const LocalTensor<T>& srcTensor, bool isFront = false)
参数说明
参数名 |
输入/输出 |
描述 |
|---|---|---|
dstTensor |
输出 |
目的操作数,类型为LocalTensor,last轴长度需要32B对齐 |
gradTensor |
输入 |
源操作数,类型为LocalTensor,last轴长度需要32B对齐 |
srcTensor |
输入 |
源操作数,类型为LocalTensor,last轴长度需要32B对齐 |
isFront |
输入 |
取值为True时,直接返回 |
isReuseSource |
输入 |
是否复用src的空间 |
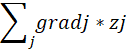
返回值
无
支持的型号
Atlas A2训练系列产品
调用示例
本样例输入src的Shape大小为[128,64],输入gradtensor的Shape大小为[128,64],isFront为false时,输出Shape大小dst=[128,64],isFront为true时,输出sumTempLocal=[128,16],数据类型均为half。
#include "kernel_operator.h"
namespace AscendC {
template <typename T> class KernelSoftmaxGrad {
public:
__aicore__ inline KernelSoftmaxGrad() {}
__aicore__ inline void Init(__gm__ uint8_t* src1Gm,__gm__ uint8_t* src2Gm, __gm__ uint8_t* dstGm)
{
elementNumPerBlk = 32 / sizeof(T); // half=16 float=8
src1Global.SetGlobalBuffer((__gm__ T*)src1Gm);
src2Global.SetGlobalBuffer((__gm__ T*)src2Gm);
dstGlobal.SetGlobalBuffer((__gm__ T*)dstGm);
pipe.InitBuffer(inQueueSrc1, 1, height*width * sizeof(T));
pipe.InitBuffer(inQueueSrc2, 1, height*width * sizeof(T));
pipe.InitBuffer(maxQueue, 1, height*elementNumPerBlk * sizeof(T));
pipe.InitBuffer(sumQueue, 1, height*elementNumPerBlk * sizeof(T));
pipe.InitBuffer(outQueueDst, 1, height*width * sizeof(T));
}
__aicore__ inline void Process()
{
CopyIn();
Compute();
CopyOut();
}
private:
__aicore__ inline void CopyIn()
{
LocalTensor<T> srcLocal1 = inQueueSrc1.AllocTensor<T>();
LocalTensor<T> srcLocal2 = inQueueSrc2.AllocTensor<T>();
DataCopy(srcLocal1, src1Global, height*width);
DataCopy(srcLocal2, src2Global, height*width);
inQueueSrc1.EnQue(srcLocal1);
inQueueSrc2.EnQue(srcLocal2);
}
__aicore__ inline void Compute()
{
LocalTensor<T> srcLocal1 = inQueueSrc1.DeQue<T>();
LocalTensor<T> srcLocal2 = inQueueSrc2.DeQue<T>();
LocalTensor<T> sumTempLocal = sumQueue.AllocTensor<T>();
LocalTensor<T> maxTempLocal = maxQueue.AllocTensor<T>();
LocalTensor<T> dstLocal = outQueueDst.AllocTensor<T>();
const uint32_t shapeDim = 2;
uint32_t array[2] = {height, width};
srcLocal1.SetShapeInfo(ShapeInfo(shapeDim, array)); // default ND
srcLocal2.SetShapeInfo(ShapeInfo(shapeDim, array)); // default ND
dstLocal.SetShapeInfo(ShapeInfo(shapeDim, array));
array[0] = height;
array[1] = elementNumPerBlk;
sumTempLocal.SetShapeInfo(ShapeInfo(shapeDim, array));
maxTempLocal.SetShapeInfo(ShapeInfo(shapeDim, array));
SoftmaxGrad<T,false>(sumTempLocal, srcLocal2, srcLocal1, true);
SoftmaxGrad<T,false>(srcLocal1, srcLocal2, srcLocal1, false);
DataCopy(dstLocal, srcLocal1, height*width);
outQueueDst.EnQue<T>(dstLocal);
maxQueue.FreeTensor(maxTempLocal);
sumQueue.FreeTensor(sumTempLocal);
inQueueSrc1.FreeTensor(srcLocal1);
inQueueSrc2.FreeTensor(srcLocal2);
}
__aicore__ inline void CopyOut()
{
LocalTensor<T> dstLocal = outQueueDst.DeQue<T>();
DataCopy(dstGlobal, dstLocal, height*width);
outQueueDst.FreeTensor(dstLocal);
}
private:
TPipe pipe;
TQue<QuePosition::VECIN, 1> inQueueSrc1;
TQue<QuePosition::VECIN, 1> inQueueSrc2;
TQue<QuePosition::VECIN, 1> maxQueue;
TQue<QuePosition::VECIN, 1> sumQueue;
TQue<QuePosition::VECOUT, 1> outQueueDst;
GlobalTensor<T> src1Global,src2Global, dstGlobal;
uint32_t elementNumPerBlk = 0;
uint32_t width = 64;
uint32_t height = 128;
};
} // namespace AscendC
extern "C" __global__ __aicore__ void softmax_grad_kernel_half(__gm__ uint8_t *src1Gm, __gm__ uint8_t *src2Gm, __gm__ uint8_t *dstGm)
{
AscendC::KernelSoftmaxGrad<half> op;
op.Init(src1Gm,src2Gm, dstGm);
op.Process();
}