使用场景
因为在同一模型或算子调试过程中,用户定位算子相关的计算精度问题时费时费力,所以推出了精度比对工具。精度比对工具通过在PyTorch模型中注入hook,跟踪计算图中算子的前向传播与反向传播时的输入与输出,排查存在的计算精度误差,进行问题的精准定位。
主要的使用场景包括:
- 同一模型从GPU(或CPU)移植到NPU中存在精度下降问题,对比NPU芯片中的算子计算数值与GPU(CPU)芯片中的算子计算数值,进行问题定位。
- 同一模型进行迭代(模型、算子或设备迭代)时存在精度下降问题,对比相同模型在迭代前后版本的算子计算数值,进行问题定位。
精度比对基本原理
普遍适用的比对方法是以模型为单位,采用hook机制挂在模型上。当模型在CPU(或GPU)上进行正向传播时跟踪并dump每一层的数值输入与输出,在反向传播时跟踪并dump每一层的梯度输入值与输出值;同样的当模型在NPU中进行计算时采用相同的方式记录下相应的数据,通过对比dump出的数值,计算余弦相似度和均方根误差的方式,定位和排查NPU算子存在的计算精度问题。

图1即为精度对比的基本逻辑,需注意以下问题:
- 需要对大量的变量进行控制,要确保模型结构参数等相同。
- 相同的模型在不同的硬件设备上进行运算时,可能会出现相同的计算会调用不同的底层算子,造成NPU算子可能出现不匹配情形。
- NPU与CPU/GPU的计算结果误差可能会随着模型的执行不断累积,最终会出现同一个算子因为输入的数据差异较大而无法匹配对比计算精度的情况。
其中问题2表现如下图2。

由于可能会出现融合算子,所以在算子的逐一匹配时可能会出现错误匹配或无法匹配的问题,例如图2中NPU算子npu_op_1与npu_op_2无法和cpu_op_k进行匹配,会跳过当前算子的匹配,直到到npu_op_3和cpu_op_3才重新对齐开始匹配。
算子匹配条件
判断运行在CPU和NPU上的两个算子是否相同的条件如下:
- 两个算子的名字是否相同。
- 两个算子的输入输出tensor数量和各个tensor的shape是否相同。
通常满足以上的两个条件,就认为是同一个算子,可以成功进行算子的匹配。后续进行相应的计算精度比对。
计算精度评价指标
在进行计算精度匹配时,基本共识为默认CPU或GPU的算子计算结果是准确的,最终比对生成的csv文件中主要包括以下的几个属性:Name、Npu Tensor Dtype、Bench Tensor Dtype、Npu Tensor Shape、Bench Tensor Shape、Cosine(余弦相似)、RMSE(均方根误差)、MAPE(绝对百分比误差)。
其中主要使用算子Name、Dtype、Shape用于描述算子的基本特征,Cosine、RMSE、MAPE作为评价计算精度的主要评估指标。
- 余弦相似度(通过计算两个向量的余弦值来判断其相似度):
当余弦夹角数值越接近于1说明计算出的两个张量越相似。在计算中可能会存在nan,主要由于可能会出现其中一个向量为0。
- 均方根误差(RMSE):
当均方根误差越接近0表示其计算的平均误差越小。
- 平均绝对百分比误差(MAPE):
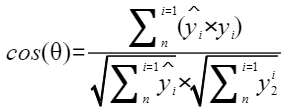
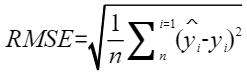
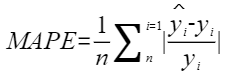
绝对百分比误差衡量计算误差的百分比,越接近0越好,但当其中的实际计算结果中存在0时是无法进行计算的。
使用方法

- 导入相关函数和库代码。
import os import torch import torch.nn as nn ... from torch_npu.hooks import set_dump_path, register_acc_cmp_hook
表1 相关函数说明 函数名称
功能
参数
用法举例
set_dump_path(fpath=None)
设置生成dump数据文件的路径。
- fpath: dump数据文件的路径。
set_dump_path("./cpu_module_op.pkl")register_acc_cmp_hook(model)
对模型注入hooks, 开启dump数据功能。
- model: 需要dump数据的网络模型。
register_acc_cmp_hook(model)
- 设置hook。
- 在CPU模型脚本设置hook。
#在模型或网络定义处增加hook module = ModuleOP() # 对模型注入forwar和backward的hooks register_acc_cmp_hook(module) #模型输入 images = images.to(cpu)
- 在NPU模型脚本设置hook。
#在模型或网络定义处增加hook module = ModuleOP() # 对模型注入forwar和backward的hooks register_acc_cmp_hook(module) #模型输入 images = images.to(npu)
- 在CPU模型脚本设置hook。
- 设置dump。
- 模型在CPU计算输出位置设置dump。
set_dump_path("./cpu_module_op.pkl") out = module(images) loss = out.sum() loss.backward() - 模型在NPU计算输出位置设置dump。
set_dump_path("./npu_module_op.pkl") module.npu() images = images.npu() out = module(images) loss = out.sum() loss.backward()
- 模型在CPU计算输出位置设置dump。
- 新建脚本compare.py,导入函数compare,将需要对比的.pkl文件移动到脚本的同级目录下,对比dump数据文件,完成后会在当前目录生成module_result.csv精度比对结果文件。
表2 compare函数说明 函数名称
功能
参数
用法举例
compare(pkl_path1, pkl_path2, output_path, shape_flag=False)
对比不同device上dump数据生成的.pkl文件,生成评估计算精度的.csv文件。
- pkl_path1: 模型dump数据文件1。
- pkl_path2: 模型dump数据文件2。
- output_path: 精度比对结果文件输出路径。
- shape_flag: False时只使用算子名字进行匹配,True时使用算子名称和输入输出大小进行匹配。
compare("./npu_module_op.pkl","./cpu_module_op.pkl", "./module_result.csv")以CPU和NPU对比为例,脚本代码如下:from torch_npu.hooks.tools import compare compare("./npu_module_op.pkl", "./cpu_module_op.pkl", "./module_result.csv") #可根据实际文件名称修改
快速上手样例参考
import os
import copy
import torch
import torch.nn as nn
from torchvision import models, datasets, transforms
from torch_npu.hooks import set_dump_path, seed_all, register_acc_cmp_hook
from torch_npu.hooks.tools import compare
torch_npu._C._npu_setDevice(0) # 用户可根据实际情况指定运行脚本的device
# 选取需要的模型
model_cpu = models.resnet50()
model_cpu.eval()
model_npu = copy.deepcopy(model_cpu)
model_npu.eval()
# 对该计算进行hook注入和数据dump
register_acc_cmp_hook(model_cpu)
register_acc_cmp_hook(model_npu)
seed_all()
# 需要根据不同的模型输入和标签生成相应的tensor(或读取实际数据),损失函数等,如果是随机生成的标签需要保证数据的有效性
inputs = torch.randn(1, 3, 244, 244)
labels = torch.randn(1).long()
criterion = nn.CrossEntropyLoss()
# 在cpu上计算,在计算输出位置设置dump
set_dump_path("./cpu_resnet50_op.pkl")
output = model_cpu(inputs)
loss = criterion(output, labels)
loss.backward()
# 在npu上计算,在计算输出位置设置dump
set_dump_path("./npu_resnet50_op.pkl")
model_npu.npu()
inputs = inputs.npu()
labels = labels.npu()
output = model_npu(inputs)
loss = criterion(output, labels)
loss.backward()
# 对比dump出的数据精度,生成csv文件
compare("./npu_resnet50_op.pkl", "./cpu_resnet50_op.pkl", "./resnet50_result.csv")
如需对生成的.pkl文件解析读取数据,参考样例代码如下:
import json
pkl_file=open("./cpu_resnet50_op.pkl",'r')
tensor_line=pkl_file.readline() # 读取行数据
tensor_data=json.loads(tensor_line)
print(tensor_data[0]) # 算子名称
print(tensor_data[1]) # 对应数据
print(tensor_data[2]) # 数据类型
print(tensor_data[3]) # 数据尺寸