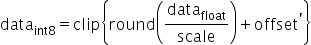量化因子记录文件格式说明
量化因子record文件格式,为基于protobuf协议的序列化数据结构文件,通过该文件、量化配置文件以及原始网络模型文件,生成量化后的模型文件。
- convert_model接口量化场景下对应的protobuf原型定义为(或查看昇腾模型压缩工具安装目录/amct_tensorflow/proto/scale_offset_record_tf.proto文件):
syntax = "proto2"; package AMCTTensorflow; // this proto is designed for convert_model API message SingleLayerRecord { optional float scale_d = 1; optional int32 offset_d = 2; repeated float scale_w = 3; repeated int32 offset_w = 4; // convert_model does not support this field [shift_bit] yet repeated uint32 shift_bit = 5; optional bool skip_fusion = 9 [default = false]; } message MapFiledEntry { optional string key = 1; optional SingleLayerRecord value = 2; } message ScaleOffsetRecord { repeated MapFiledEntry record = 1; }该场景下对应参数说明如下:
消息
是否必填
类型
字段
说明
SingleLayerRecord
-
-
-
包含了量化层所需要的所有量化因子记录信息。
optional
float
scale_d
数据量化scale因子,仅支持对数据进行统一量化。
optional
int32
offset_d
数据量化offset因子,仅支持对数据进行统一量化。
repeated
float
scale_w
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持卷积层(Conv2D)、Depthwise卷积层(DepthwiseConv2dNative)、反卷积层(Conv2DBackpropInput)类型进行channel_wise量化模式。
repeated
int32
offset_w
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。
repeated
uint32
shift_bit
移位因子。convert_model接口场景下预留字段,当前不支持,不需要配置。
optional
bool
skip_fusion
配置当前层是否要跳过Conv+BN融合、Depthwise_Conv+BN融合、Group_conv+BN融合、BatchNorm融合,默认为false,即当前层要做上述融合。
ScaleOffsetRecord
-
-
-
map结构,为保证兼容性,采用离散的map结构。
repeated
MapFiledEntry
record
每个record对应一个量化层的量化因子记录;record包括两个成员:
- key为所记录量化层的layer name。
- value对应SingleLayerRecord定义的具体量化因子。
MapFiledEntry
optional
string
key
层名。
optional
SingleLayerRecord
value
量化因子配置。
- 量化感知训练或稀疏场景下由昇腾模型压缩工具生成的量化因子对应的protobuf原型定义为(或查看昇腾模型压缩工具安装目录/amct_tensorflow/proto/inner_scale_offset_record.proto文件):
syntax = "proto2"; package AMCTTensorflow; // this proto is designed for amct tools message InnerSingleLayerRecord { optional float scale_d = 1; optional int32 offset_d = 2; repeated float scale_w = 3; repeated int32 offset_w = 4; repeated uint32 shift_bit = 5; // the cluster of nuq, only nuq layer has this field; repeated int32 cluster = 6; optional bool skip_fusion = 9 [default = false]; optional string dst_type = 10 [default = 'INT8']; repeated string prune_producer = 11; repeated string prune_consumer = 12; } message InnerMapFiledEntry { optional string key = 1; optional InnerSingleLayerRecord value = 2; } message InnerScaleOffsetRecord { repeated InnerMapFiledEntry record = 1; } message PruneRecord { repeated PruneNode producer = 1; repeated PruneNode consumer = 2; } message PruneNode { required string name = 1; repeated AMCTProto.AttrProto attr = 2; }该场景下对应参数说明如下:
消息
是否必填
类型
字段
说明
InnerSingleLayerRecord
-
-
-
包含了量化层所需要的所有量化因子记录信息。
optional
float
scale_d
数据量化scale因子,仅支持对数据进行统一量化。
optional
int32
offset_d
数据量化offset因子,仅支持对数据进行统一量化。
repeated
float
scale_w
权重量化scale因子,支持标量(对当前层的权重进行统一量化),向量(对当前层的权重按channel_wise方式进行量化)两种模式,仅支持卷积层(Conv2D)、Depthwise卷积层(DepthwiseConv2dNative)、反卷积层(Conv2DBackpropInput)类型进行channel_wise量化模式。
repeated
int32
offset_w
权重量化offset因子,同scale_w一样支持标量和向量两种模式,且需要同scale_w维度一致,当前不支持权重带offset量化模式,offset_w仅支持0。
repeated
uint32
shift_bit
移位因子。
repeated
int32
cluster
聚类中心。只有非均匀量化场景下需要使能该字段,该版本不支持该字段。
optional
bool
skip_fusion
配置当前层是否要跳过Conv+BN融合、Depthwise_Conv+BN融合、Group_conv+BN融合、BatchNorm融合,默认为false,即当前层要做上述融合。
optional
string
dst_type
量化位宽,包括INT8和INT4两种量化类型。当前版本仅支持INT8量化。
InnerScaleOffsetRecord
-
-
-
map结构,为保证兼容性,采用离散的map结构。
repeated
InnerMapFiledEntry
record
每个record对应一个量化层的量化因子记录;record包括两个成员:
- key为所记录量化层的layer name。
- value对应SingleLayerRecord定义的具体量化因子。
InnerMapFiledEntry
optional
string
key
层名。
optional
InnerSingleLayerRecord
value
量化因子配置。
PruneRecord
-
-
-
稀疏信息的记录。
repeated
PruneNode
producer
稀疏的producer,可稀疏结点间级联关系的根节点。
例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consume;conv1是bn、relu、conv2的producer。
repeated
PruneNode
consumer
稀疏的consumer,可稀疏结点间级联关系的下游节点。
例如conv1>bn>relu>conv2都可以稀疏,且bn、relu、conv2都会受到conv1稀疏的影响,则bn、relu、conv2是conv1的consume;conv1是bn、relu、conv2的producer。
PruneNode
-
-
-
稀疏的节点。
required
string
name
节点名称。
repeated
AMCTProto.AttrProto
attr
节点属性。
对于optional字段,由于protobuf协议未对重复出现的值报错,而是采用覆盖处理,因此出现重复配置的optional字段内容时会默认保留最后一次配置的值,需要用户自己保证文件的正确性。
对于一般量化层需要配置包含scale_d、offset_d、scale_w、offset_w、shift_bit参数,对于AvgPool因为没有权重,因此不能够配置scale_w、offset_w参数,量化因子record文件格式参考示例如下(如下示例以inner_scale_offset_record.proto原型文件对应的量化因子为例进行说明):
record {
key: "fc4/Tensordot/MatMul"
value {
scale_d: 0.0798481479
offset_d: 1
scale_w: 0.00297622895
offset_w: 0
shift_bit: 1
dst_type: "INT8"
}
}
record {
key: "depthwise"
value {
scale_d: 0.00962011795
offset_d: 1
scale_w: 0.00787108205
scale_w: 0.00787108205
scale_w: 0.00787108205
offset_w: 0
offset_w: 0
offset_w: 0
shift_bit: 1
shift_bit: 1
shift_bit: 1
skip_fusion: true
dst_type: "INT8"
}
}
record {
key: "conv2d/Conv2D"
value {
scale_d: 0.00392156886
offset_d: -128
scale_w: 0.00106807391
scale_w: 0.00104224426
scale_w: 0.0010603976
offset_w: 0
offset_w: 0
offset_w: 0
shift_bit: 1
shift_bit: 1
shift_bit: 1
dst_type: "INT8"
}
}
通道稀疏record文件记录各稀疏层间的级联关系,其格式参考示例如下:
prune_record {
producer {
name: "conv_1"
attr {
name: "type"
type: STRING
s: "Conv2D"
}
attr {
name: "begin"
type: INT
i: 0
}
attr {
name: "end"
type: INT
i: 64
}
}
consumer {
name: "BN_1"
attr {
name: "type"
type: STRING
s: "FusedBatchNormV3"
}
attr {
name: "begin"
type: INT
i: 0
}
attr {
name: "end"
type: INT
i: 64
}
}
}
量化因子说明
对于量化层数据和权重分别需要提供量化因子scale(浮点数的缩放因子),offset(偏移量)两项,昇腾模型压缩工具采用的是统一的量化数据格式,其应用表达式为:
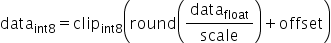
支持的取值范围为:

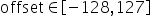
下面介绍上述表达式的由来,量化通常分为对称量化算法、非对称量化算法两类。如下所示:
- 对称量化算法原理:
原始高精度数据和量化后INT8数据的转换为:
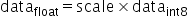 ,其中scale是float32的浮点数,为了能够表示正负数,
,其中scale是float32的浮点数,为了能够表示正负数,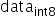 采用signed int8的数据类型,通过原始高精度数据转换到int8数据的操作如下,其中round为取整函数,量化算法需要确定的数值即为常数scale:
采用signed int8的数据类型,通过原始高精度数据转换到int8数据的操作如下,其中round为取整函数,量化算法需要确定的数值即为常数scale: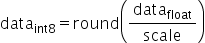
对权值和数据的量化可以归结为寻找scale的过程,由于
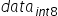 为有符号数,要保证正负数值表示范围的对称性,因此对所有数据首先进行取绝对值的操作,使待量化数据的范围变换为
为有符号数,要保证正负数值表示范围的对称性,因此对所有数据首先进行取绝对值的操作,使待量化数据的范围变换为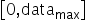 ,再来确定scale。由于INT8在正数范围内能表示的数值范围为[0,127],因此scale可以通过如下方式计算得到:
,再来确定scale。由于INT8在正数范围内能表示的数值范围为[0,127],因此scale可以通过如下方式计算得到: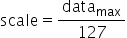
确定了scale之后,INT8数据对应的表示范围为
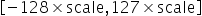 ,量化操作即为对量化数据以
,量化操作即为对量化数据以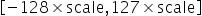 进行饱和,即超过范围的数据饱和到边界值,然后进行公式所示量化操作即可。
进行饱和,即超过范围的数据饱和到边界值,然后进行公式所示量化操作即可。 - 非对称量化算法原理:
与对称量化算法主要区别在于数据转换的方式不同,如下,同样需要确定scale与offset这两个常数。
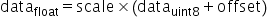
确定后通过原始高精度数据计算得到UINT8数据的转换,即为如下公式所示:
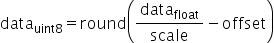
其中,scale是FP32浮点数,
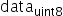 为unsigned INT8定点数,offset是INT8定点数。其表示的数据范围为
为unsigned INT8定点数,offset是INT8定点数。其表示的数据范围为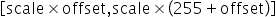 。若待量化数据的取值范围为
。若待量化数据的取值范围为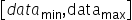 ,则scale和offset的计算方式如下:
,则scale和offset的计算方式如下: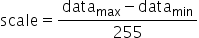 ,
,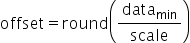
而昇腾模型压缩工具采用的是统一的量化数据格式,即量化数据格式统一:
通过将非对称量化公式通过简单的数据变换,可以使得量化后的数据与对称量化算法在数据格式上保持一致,均为int格式。具体变换过程如下:
以int8量化为例进行说明,公式符号与之前保持一致,输入原始高精度浮点数据为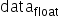 ,原始量化后的定点数为
,原始量化后的定点数为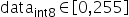 ,量化scale,原始量化
,量化scale,原始量化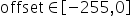 (算法要求强制过零点,否则可能会出现精度问题),原始量化的计算原理公式如下:
(算法要求强制过零点,否则可能会出现精度问题),原始量化的计算原理公式如下:

其中 。通过上述变换,可以将量化数据也转成int8格式。确定scale和变换后的offset'后,通过原始高精度浮点数据计算得到INT8数据的转换既为如下公式所示:
。通过上述变换,可以将量化数据也转成int8格式。确定scale和变换后的offset'后,通过原始高精度浮点数据计算得到INT8数据的转换既为如下公式所示: