简介
torch_npu_run是torchrun在大集群场景的改进版,提升集群建链性能。
torch_npu_run相对torchrun有以下改进:
- torch_npu_run采用epoll实现多线程TCP server,可以高效地处理大量并发连接,快速响应客户端请求,从而显著提高系统的整体性能和吞吐量。
- torch_npu_run支持分层建链,通过配置enable_tiered_parallel_tcpstore为true,可以开启分层建链。
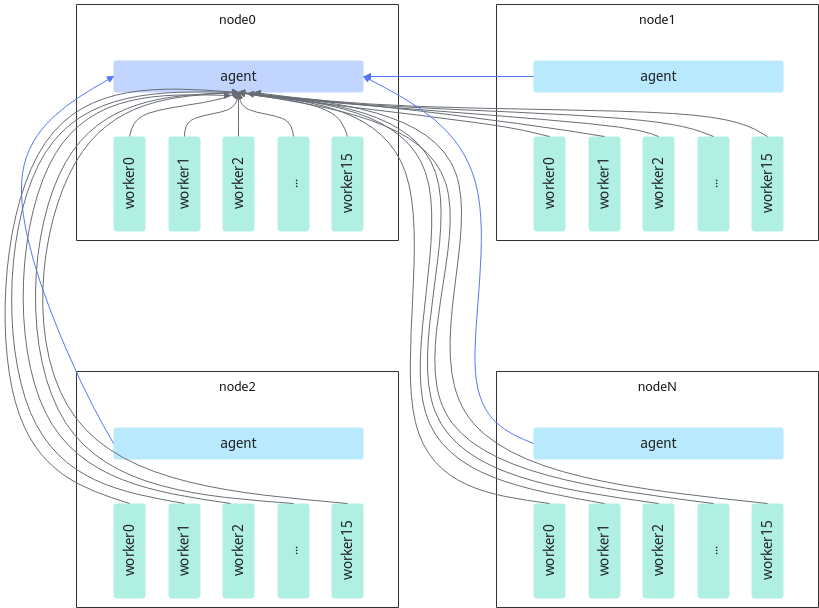
在分布式训练中,一般每个节点会开启一个torch_run进程,也被称为agent进程。agent负责管理本节点上多个训练进程的启动和结束等状态,训练进程也被称为worker。原生torchrun是让所有的agent和worker与0号节点(node0)上的agent建立TCP连接,如图1所示。torchrun的方式下建链时间会随着训练进程数的增多呈线性增长,导致性能瓶颈。
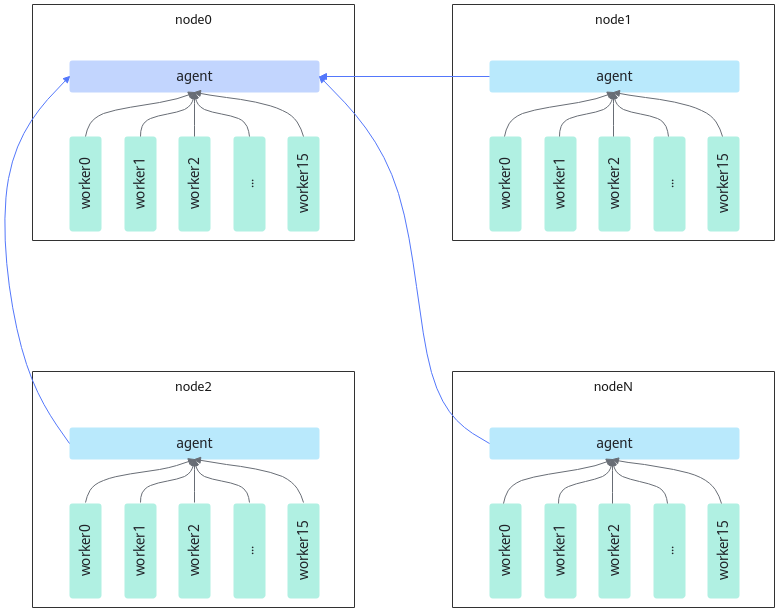
torch_npu_run是在torch_run的基础上引入了tcpStore分层架构方案,即在每一个节点上由agent启动一个新角色proxy,管理worker的通信。节点上的worker与proxy建立UnixSocket连接,所有的proxy与node0的proxy建立TCP连接。实现通信的分层,打破建链时间线性瓶颈,使得建链时间复杂度从O(n)降低到
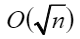 ,如图2所示。
,如图2所示。
使用场景
启动分布式训练任务时,推荐使用该特性。
使用指导
torch_npu_run和torchrun的使用方式类似。torch_npu_run的部分可选配置参数如下:
- nnodes:节点数量,或节点数量范围,格式为 <最小节点数>:<最大节点数>。
- nproc_per_node:每个节点的工作进程数,支持的值有auto、cpu、gpu或整数。
- node_rank:多节点分布式训练中节点的排名。
- rdzv_backend:建立集合通信连接的后端机制。
- rdzv_endpoint:用于集合的后端服务地址,格式为 <主机名>:<端口号>。
- rdzv_id:用户定义的ID,用于唯一标识作业的工作组。每个节点都使用此ID加入特定工作组。
- standalone:表示在单机上运行分布式训练任务,适用于单节点多进程作业。
- master_addr:主节点(排名为0)的网络地址,仅用于静态集合点。
- master_port:主节点(排名为0)的端口,仅用于静态集合点。
- local_addr:当前节点的IP地址。
- enable_tiered_parallel_tcpstore:是否开启分层建链进一步提升建链性能,即是否分节点内和节点间建链。推荐在大规模集群场景下使用。支持的值有true和false,默认为false(不开启)。
使用样例
拉起单机8卡训练任务示例:
export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR --master_port=$MASTER_PORT --nnodes=1 --nproc_per_node=8 ddp_test.py
拉起双机16卡训练任务示例:
- 不开启分层建链
# 第一台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR --master_port=$MASTER_PORT --nnodes=2 --node_rank 0 --nproc_per_node=8 ddp_test.py # 第二台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR --master_port=$MASTER_PORT --nnodes=2 --node_rank 1 --nproc_per_node=8 ddp_test.py
- 开启分层建链
# 第一台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR --master_port=$MASTER_PORT --nnodes=2 --node_rank 0 --nproc_per_node=8 --enable_tiered_parallel_tcpstore=true ddp_test.py # 第二台机器 export MASTER_IP_ADDR=** # 将**填写node_rank0的IP地址 export MASTER_PORT=** # 将**填写为一个空闲的tcp端口号 torch_npu_run --rdzv_backend=parallel --master_addr=$MASTER_IP_ADDR --master_port=$MASTER_PORT --nnodes=2 --node_rank 1 --nproc_per_node=8 --enable_tiered_parallel_tcpstore=true ddp_test.py

ddp_test.py为模型训练脚本,ddp_test.py仅为示例,用户可根据实际脚本名称进行修改。
约束说明
无