功能简介
torch.compile是一种即时编译器(just-in-time compiler),其成图的首次编译时间通常较长,而大模型推理场景对时延敏感,因此有必要优化首次编译时长。在推理服务弹性扩容等业务场景,使用编译缓存可有效缩短服务启动后首次推理时延。
成图编译通常包括两段耗时,一段是Dynamo的编译耗时,一段是Ascend IR计算图的编译耗时。TorchAir提供了一种模型编译缓存方案(通过cache_compile接口),可将首次编译结果落盘,以加速torch.compile图模式的启动时间。
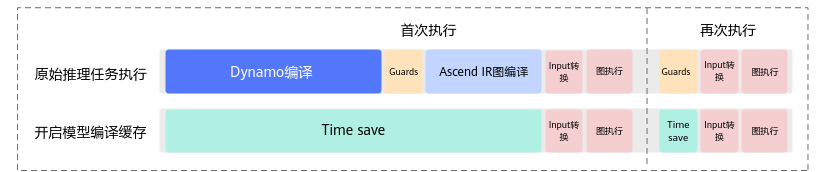
以LLaMA 2-70B(Large Language Model Meta AI 2)为例,图1呈现了启动与未开启模型编译缓存的耗时分布。注意,该图屏蔽了与本功能无关的耗时细节。
- 原始推理任务执行,分为5个阶段:
- 开启模型编译缓存:
使用约束
- 如果图中包含依赖随机数生成器(RNG)的算子(例如randn、bernoulli、dropout等),不支持使用本功能。
- 该功能不支持同时配置Dynamo导图功能、使能RefData类型转换功能。
- 该功能跳过了Dynamo的JIT编译环节、Guards、Ascend IR图编译环节,与torch.compile原始方案相比多了如下限制:
- 缓存要与执行计算图一一对应,若重编译则缓存失效。
- Guards阶段被跳过且不会触发JIT编译,要求生成模型的脚本和加载缓存的脚本一致。
- CANN包跨版本缓存无法保证兼容性,如果版本升级,需要清理缓存目录并重新进行Ascend IR计算图编译生成缓存。
Dynamo编译缓存
本节提供一个简化版的模型编译缓存使用示例,同时展示了缓存对特殊类型输入的处理能力(如Python Class类型、List类型等)。
- 准备PyTorch模型脚本。
假设在/home/workspace目录下定义了test.py模型脚本,代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import torch # InputMeta为仿照VLLM(Versatile Large Language Model)框架的入参结构 @dataclasses.dataclass class InputMeta: data: torch.Tensor is_prompt: bool class Model(torch.nn.Module): def __init__(self): super().__init__() self.linear1 = torch.nn.Linear(2, 1) self.linear2 = torch.nn.Linear(2, 1) for param in self.parameters(): torch.nn.init.ones_(param) @torch.inference_mode() def forward(self, x: InputMeta, kv: List[torch.Tensor]): return self.linear2(x.data) + self.linear2(kv[0])
- 改造PyTorch模型脚本。
- 先处理forward函数。
- 通过cache_compile接口实现编译缓存。
“_forward”函数是可以缓存编译的函数,但由于其会触发多次重新编译,所以要为每个场景封装一个新的func函数,然后func直接调用_forward函数。同时,forward函数中添加调用新函数的判断逻辑。如何封装新的func函数,取决于原始模型逻辑,请用户根据实际场景自行定义。

- func函数只能被触发一次Dynamo trace,换言之如果func发生重编译,则会放弃缓存。
- 对于发生多次trace(Guards失效)的函数,需要进行一次函数封装来使缓存生效。
- func必须是method,即module实例对象的方法,且该方法未被其他装饰器修饰。
- func必须能形成整图,即必须支持full graph。
test.py中只展示了prompt和decode的func函数封装,具体代码示例如下:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
import dataclasses import logging from typing import List import torch import torch_npu import torchair from torchair import logger logger.setLevel(logging.INFO) # InputMeta为仿照VLLM(Versatile Large Language Model)框架的入参结构 @dataclasses.dataclass class InputMeta: data: torch.Tensor is_prompt: bool class Model(torch.nn.Module): def __init__(self): super().__init__() self.linear1 = torch.nn.Linear(2, 1) self.linear2 = torch.nn.Linear(2, 1) for param in self.parameters(): torch.nn.init.ones_(param) # 通过torchair.inference.cache_compile实现编译缓存 self.cached_prompt = torchair.inference.cache_compile(self.prompt) self.cached_decode = torchair.inference.cache_compile(self.decode) def forward(self, x: InputMeta, kv: List[torch.Tensor]): # 添加调用新函数的判断逻辑 if x.is_prompt: return self.cached_prompt(x, kv) return self.cached_decode(x, kv) def _forward(self, x, kv): return self.linear2(x.data) + self.linear2(kv[0]) # 重新封装为prompt函数 def prompt(self, x, y): return self._forward(x, y) # 重新封装为decode函数 def decode(self, x, y): return self._forward(x, y) x = InputMeta(data=torch.randn(2, 2).npu(), is_prompt=True) kv = [torch.randn(2, 2).npu()] model = Model().npu() # 执行prompt res_prompt = model(x, kv) x.is_prompt = False # 执行decode res_decode = model(x, kv)
- 模型脚本改造后,运行并生成封装func函数的缓存文件。
- 进入test.py所在目录,执行如下命令:
cd /home/workspace python3 test.py
- 参考TorchAir Python层日志开启INFO日志,首次执行可以看到如下打印日志:
1 2
[INFO] TORCHAIR 2024-04-30 14:48:18 Cache ModelCacheMeta(name='CacheCompileSt.test_cache_hint.<locals>.Model.prompt(x, y)', date='2024-04-30 14:48:16.736731', version='1.0.0', fx=None) saved to /home/workspace/.torchair_cache/Model_dynamic_f2df0818d06118d4a83a6cacf8dc6d28/prompt/compiled_module [INFO] TORCHAIR 2024-04-30 14:48:20 Cache ModelCacheMeta(name='CacheCompileSt.test_cache_hint.<locals>.Model.decode(x, y)', date='2024-04-30 14:48:19.654573', version='1.0.0', fx=None) saved to /home/workspace/.torchair_cache/Model_dynamic_f2df0818d06118d4a83a6cacf8dc6d28/decode/compiled_module
生成的各个func函数缓存文件路径由cache_compile中cache_dir参数指定,缺省值是当前工作路径下“.torchair_cache”文件夹(若无会新建)。
比如${work_dir}/.torchair_cache/${model_info}/${func}/compiled_module文件,${work_dir}为当前工作目录,${model_info}为模型信息,${func}为封装的func函数。
- 进入test.py所在目录,执行如下命令:
- 再次执行脚本,验证模型启动时间。
重新执行test.py脚本,开启Python侧INFO日志,可以看到缓存命中的日志:
1 2
[INFO] TORCHAIR 2024-04-30 14:52:08 Cache ModelCacheMeta(name='CacheCompileSt.test_cache_hint.<locals>.Model.prompt(x, y)', date='2024-04-30 14:48:16.736731', version='1.0.0', fx=None) loaded from /home/workspace/.torchair_cache/Model_dynamic_f2df0818d06118d4a83a6cacf8dc6d28/prompt/compiled_module [INFO] TORCHAIR 2024-04-30 14:52:08 Cache ModelCacheMeta(name='CacheCompileSt.test_cache_hint.<locals>.Model.decode(x, y)', date='2024-04-30 14:48:19.654573', version='1.0.0', fx=None) loaded from /home/workspace/.torchair_cache/Model_dynamic_f2df0818d06118d4a83a6cacf8dc6d28/decode/compiled_module
- (可选)如需查看封装的func函数缓存文件compiled_module,通过readable_cache接口读取。
compiled_module主要存储了torch.compile成图过程中模型脚本、模型结构、执行流程等相关信息,可用于问题定位分析。
接口调用示例如下:1 2
import torch_npu, torchair torchair.inference.readable_cache("/home/workspace/.torchair_cache/Model_dynamic_f2df0818d06118d4a83a6cacf8dc6d28/prompt/compiled_module", file="prompt.py")
compiled_module内容最终解析到可读文件prompt.py(格式不限,如py、txt等)中。
Ascend IR编译缓存
除了优化Dynamo编译耗时,还支持优化Ascend IR图编译耗时,主要通过cache_compile中ge_cache参数实现,以进一步加速图模式启动时间。
缺省情况下,ge_cache=False(功能不开启),因受CANN包版本变更影响,用户需根据实际情况手动开启该功能。
功能开启操作示例如下(以步骤2中脚本为例):
1 2 3 | # 开启ge_cache后的调用示例 self.cached_prompt = torchair.inference.cache_compile(self.prompt, ge_cache=True) self.cached_decode = torchair.inference.cache_compile(self.decode, ge_cache=True) |
缓存的编译结果文件路径与封装的func函数缓存文件路径一致,即${work_dir}/.torchair_cache/${model_info}/${func}/ge_cache_${timestamp}.om文件。
其中${work_dir}为当前工作目录,${model_info}为模型信息,${func}为封装的func函数,${timestamp}为落盘的时间戳,缓存路径会自动增加ge_cache关键词。
- CANN包跨版本的缓存无法保证兼容性,如果版本升级,需要清理缓存目录并重新GE编译生成缓存。
- ge_cache参数不支持和固定权重类输入地址功能同时开启。
- 在单算子和图混跑场景下,开启该功能会增加通信域资源开销,有额外显存消耗。
具体代码示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | import dataclasses import logging from typing import List import torch import torch_npu import torchair from torchair import logger logger.setLevel(logging.INFO) # InputMeta为仿照VLLM(Versatile Large Language Model)框架的入参结构 @dataclasses.dataclass class InputMeta: data: torch.Tensor is_prompt: bool config = torchair.CompilerConfig() class Model(torch.nn.Module): def __init__(self): super().__init__() self.linear1 = torch.nn.Linear(2, 1) self.linear2 = torch.nn.Linear(2, 1) for param in self.parameters(): torch.nn.init.ones_(param) # 通过torchair.inference.cache_compile实现编译缓存 self.cached_prompt = torchair.inference.cache_compile(self.prompt, config=config, ge_cache=True) self.cached_decode = torchair.inference.cache_compile(self.decode, config=config, ge_cache=True) def forward(self, x: InputMeta, kv: List[torch.Tensor]): # 添加调用新函数的判断逻辑 if x.is_prompt: return self.cached_prompt(x, kv) return self.cached_decode(x, kv) def _forward(self, x, kv): return self.linear2(x.data) + self.linear2(kv[0]) # 重新封装为prompt函数 def prompt(self, x, y): return self._forward(x, y) # 重新封装为decode函数 def decode(self, x, y): return self._forward(x, y) x = InputMeta(data=torch.randn(2, 2).npu(), is_prompt=True) kv = [torch.randn(2, 2).npu()] model = Model().npu() # 执行prompt res_prompt = model(x, kv) x.is_prompt = False # 执行decode res_decode = model(x, kv) |