功能描述
- 算子功能:MoE网络中,进行AlltoAll操作从其他卡上拿到需要算的token后,将token按照专家序重新排列。
- 计算公式:
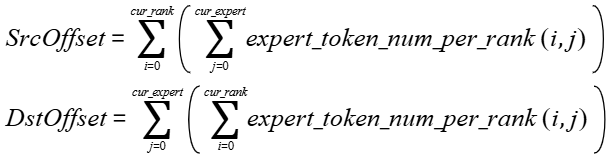
接口原型
torch_npu.npu_moe_re_routing(Tensor tokens, Tensor expert_token_num_per_rank, *, Tensor? per_token_scales=None, int expert_token_num_type=1, int idx_type=0) -> (Tensor, Tensor, Tensor, Tensor)
参数说明

Tensor中shape使用的变量说明:
- A:表示token个数,取值要求Sum(expert_token_num_per_rank)=A。
- H:表示token长度,取值要求0<H<16384。
- N:表示卡数,取值无限制。
- E:表示卡上的专家数,取值无限制。
- tokens:Tensor类型,表示待重新排布的token。要求为2D,shape为[A, H],数据类型支持float16、bfloat16、int8,数据格式为ND。
- expert_token_num_per_rank:Tensor类型,表示每张卡上各个专家处理的token数。要求为2D,shape为[N, E],数据类型支持int32、int64,数据格式为ND。取值必须大于0。
- per_token_scales:Tensor类型,可选,表示每个token对应的scale,需要随token同样进行重新排布。要求为1D,shape为[A],数据类型支持float32,数据格式为ND。
- expert_token_num_type:int类型,可选,表示输出expert_token_num的模式。0为cumsum模式,1为count模式,默认值为1。当前只支持为1。
- idx_type:int类型,可选,表示输出permute_token_idx的索引类型。0为gather索引,1为scatter索引,默认值为0。当前只支持为0。
输出说明
- permute_tokens:Tensor类型,表示重新排布后的token。要求为2D,shape为[A, H],数据类型支持float16、bfloat16、int8,数据格式为ND。
- permute_per_token_scales:Tensor类型,表示重新排布后的per_token_scales,输入不携带per_token_scales的情况下,该输出无效。要求为1D,shape为[A],数据类型支持float32,数据格式为ND。
- permute_token_idx:Tensor类型,表示每个token在原排布方式的索引。要求为1D,shape为[A],数据类型支持int32,数据格式为ND。
- expert_token_num:Tensor类型,表示每个专家处理的token数。要求为1D,shape为[E],数据类型支持int32、int64,数据格式为ND。
约束说明
- 该接口支持推理场景下使用。
- 该接口支持图模式(PyTorch 2.1版本)。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件
Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
import torch import torch_npu import random import copy import math tokens_num = 16384 tokens_length = 7168 rank_num = 16 expert_num = 16 tokens = torch.randint(low=-10, high = 20, size=(tokens_num, tokens_length), dtype=torch.int8) expert_token_num_per_rank = torch.ones(rank_num, expert_num, dtype = torch.int32) tokens_sum = 0 for i in range(rank_num): for j in range(expert_num): if i == rank_num - 1 and j == expert_num - 1: expert_token_num_per_rank[i][j] = tokens_num - tokens_sum break if tokens_num >= rank_num * expert_num : floor = math.floor(tokens_num / (rank_num * expert_num)) rand_num = random.randint(1, floor) elif tokens_sum >= tokens_num: rand_num = 0 else: rand_int = tokens_num - tokens_sum rand_num = random.randint(0, rand_int) rand_num = 1 expert_token_num_per_rank[i][j] = rand_num tokens_sum += rand_num per_token_scales = torch.randn(tokens_num, dtype = torch.float32) expert_token_num_type = 1 idx_type = 0 tokens_npu = copy.deepcopy(tokens).npu() per_token_scales_npu = copy.deepcopy(per_token_scales).npu() expert_token_num_per_rank_npu = copy.deepcopy(expert_token_num_per_rank).npu() permute_tokens_npu, permute_per_token_scales_npu, permute_token_idx_npu, expert_token_num_npu = torch_npu.npu_moe_re_routing(tokens_npu, expert_token_num_per_rank_npu, per_token_scales=per_token_scales_npu, expert_token_num_type=expert_token_num_type, idx_type=idx_type)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
import torch import torch_npu import random import copy import math import torchair as tng from torchair.configs.compiler_config import CompilerConfig config = CompilerConfig() config.experimental_config.keep_inference_input_mutations = True npu_backend = tng.get_npu_backend(compiler_config=config) tokens_num = 16384 tokens_length = 7168 rank_num = 16 expert_num = 16 tokens = torch.randint(low=-10, high = 20, size=(tokens_num, tokens_length), dtype=torch.int8) expert_token_num_per_rank = torch.ones(rank_num, expert_num, dtype = torch.int32) tokens_sum = 0 for i in range(rank_num): for j in range(expert_num): if i == rank_num - 1 and j == expert_num - 1: expert_token_num_per_rank[i][j] = tokens_num - tokens_sum break if tokens_num >= rank_num * expert_num : floor = math.floor(tokens_num / (rank_num * expert_num)) rand_num = random.randint(1, floor) elif tokens_sum >= tokens_num: rand_num = 0 else: rand_int = tokens_num - tokens_sum rand_num = random.randint(0, rand_int) rand_num = 1 expert_token_num_per_rank[i][j] = rand_num tokens_sum += rand_num per_token_scales = torch.randn(tokens_num, dtype = torch.float32) expert_token_num_type = 1 idx_type = 0 tokens_npu = copy.deepcopy(tokens).npu() per_token_scales_npu = copy.deepcopy(per_token_scales).npu() expert_token_num_per_rank_npu = copy.deepcopy(expert_token_num_per_rank).npu() class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, tokens, expert_token_num_per_rank, per_token_scales=None, expert_token_num_type=1, idx_type=0): permute_tokens, permute_per_token_scales, permute_token_idx, expert_token_num = torch_npu.npu_moe_re_routing(tokens, expert_token_num_per_rank, per_token_scales=per_token_scales, expert_token_num_type=expert_token_num_type, idx_type=idx_type) return permute_tokens, permute_per_token_scales, permute_token_idx, expert_token_num model = Model().npu() model = torch.compile(model, backend=npu_backend, dynamic=False) permute_tokens_npu, permute_per_token_scales_npu, permute_token_idx_npu, expert_token_num_npu = model(tokens_npu, expert_token_num_per_rank_npu, per_token_scales_npu, expert_token_num_type, idx_type)