功能描述
- 算子功能:融合了MLA(Multi-head Latent Attention)结构中RMSNorm归一化计算与RoPE(Rotary Position Embedding)位置编码以及更新KVCache的ScatterUpdate操作。
- 计算公式:
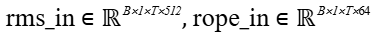
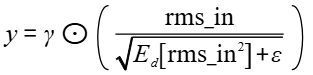
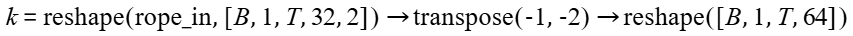
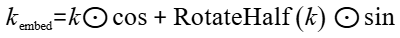
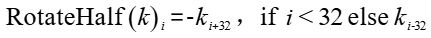
接口原型
torch_npu.npu_kv_rmsnorm_rope_cache(Tensor kv, Tensor gamma, Tensor cos, Tensor sin, Tensor index, Tensor k_cache, Tensor ckv_cache, *, Tensor? k_rope_scale=None, Tensor? c_kv_scale=None, Tensor? k_rope_offset=None, Tensor? c_kv_offset=None, float epsilon=1e-5, str cache_mode='Norm', bool is_output_kv=False) -> (Tensor, Tensor, Tensor, Tensor)
参数说明

Tensor中shape使用的变量说明:
- batch_size:batch的大小。
- seq_len:sequence的长度。
- hidden_size:表示MLA输入的向量长度,取值仅支持576。
- rms_size:表示RMSNorm分支的向量长度,取值仅支持512。
- rope_size:表示RoPE分支的向量长度,取值仅支持64。
- cache_length:Norm模式下有效,表示KVCache支持的最大长度。
- block_num:PagedAttention模式下有效,表示Block的个数。
- block_size:PagedAttention模式下有效,表示Block的大小。
- kv:Tensor类型,表示输入的特征张量。数据类型支持bfloat16、float16,数据格式为BNSD,要求为4D的Tensor,形状为[batch_size, 1, seq_len, hidden_size] ,其中hidden_size=rms_size(RMS)+rope_size(RoPE)。
- gamma:Tensor类型,表示RMS归一化的缩放参数。数据类型支持bfloat16、float16,数据格式为ND,要求为1D的Tensor,形状为[rms_size]。
- cos:Tensor类型,表示RoPE旋转位置编码的余弦分量。数据类型支持bfloat16、float16,数据格式为ND,要求为4D的Tensor,形状为[batch_size, 1, seq_len, rope_size]。
- sin:Tensor类型,表示RoPE旋转位置编码的正弦分量。数据类型支持bfloat16、float16,数据格式为ND,要求为4D的Tensor,形状为[batch_size, 1, seq_len, rope_size]。
- index:Tensor类型,表示缓存索引张量,用于定位k_cache和ckv_cache的写入位置。数据类型支持int64,数据格式为ND。shape取决于cache_mode。
- k_cache:Tensor类型,用于存储量化/非量化的键向量。数据类型支持bfloat16、float16、int8, 数据格式为ND。shape取决于cache_mode。
- ckv_cache:Tensor类型,用于存储量化/非量化的压缩后的kv向。数据类型支持bfloat16、float16、int8, 数据格式为ND。shape取决于cache_mode。
- k_rope_scale:Tensor类型,可选,默认值None,表示k旋转位置编码的量化缩放因子。数据类型支持float32,数据格式为ND,要求为1D的Tensor,形状为[rope_size]。量化模式下必填。
- c_kv_scale:Tensor类型,可选, 默认值None,表示压缩后kv的量化缩放因子。数据类型支持float32,数据格式为ND,要求为1D的Tensor,形状为[rms_size]。量化模式下必填。
- k_rope_offset:Tensor类型,可选,默认值None, 表示k旋转位置编码量化偏移量。数据类型支持float32,数据格式为ND,要求为1D的Tensor,形状为[rope_size]。量化模式下必填。
- c_kv_offset:Tensor类型,可选,默认值None,表示压缩后kv的量化偏移量。数据类型支持float32,数据格式为ND,要求为1D的Tensor,形状为[rms_size]。量化模式下必填。
- epsilon:float类型,可选,默认值1e-5,表示RMS归一化中的极小值,防止除以零。
- cache_mode:string类型,可选,默认值'Norm',表示缓存模式,支持的模式如下:
枚举值
模式名
说明
Norm
KV-Cache更新模式
k_cache形状为[batch_size, 1, cache_length, rope_size],ckv_cache形状为[batch_size, 1, cache_length, rms_size]。index形状为[batch_size, seq_len],index里的值表示每个Batch下的偏移。
PA/PA_BNSD
PagedAttention模式
k_cache形状为[block_num, block_size, 1, rope_size],ckv_cache形状为[block_num, block_size, 1, rms_size]。index形状为[batch_size*seq_len],index里的值表示每个token的偏移。
PA_NZ
Cache数据格式为FRACTAL_NZ的PagedAttention模式
k_cache形状为 [block_num, block_size, 1, rope_size],ckv_cache形状为[block_num, block_size, 1, rms_size]。index形状为[batch_size * seq_len],index里的值表示每个token的偏移。
不同量化模式下数据排布不同:
- 非量化模式下:k_cache数据排布为[block_num, rope_size//16, block_size, 1, 16],ckv_cache数据排布为[block_num, rms_size//16, block_size, 1, 16]
- 量化模式下:k_cache数据排布为[block_num, rope_size//32, block_size, 1, 32],ckv_cache数据排布为[block_num, rms_size//32, block_size, 1, 32]
PA_BLK_BNSD
特殊的PagedAttention模式
k_cache形状为[block_num, block_size, 1, rope_size],ckv_cache形状为[block_num, block_size, 1, rms_size]。index形状为[batch_size*Ceil(seq_len/block_size)],index里的值表示每个block的起始偏移,不再和token一一对应。
PA_BLK_NZ
Cache数据格式为FRACTAL_NZ的特殊的PagedAttention模式
k_cache形状为 [block_num, block_size, 1, rope_size],ckv_cache形状为[block_num, block_size, 1, rms_size]。index形状为[batch_size * Ceil(seq_len / block_size)],index里的值表示每个block的起始偏移,不再和token一一对应。
不同量化模式下数据排布不同:
- 非量化模式下:k_cache数据排布为[block_num, rope_size//16, block_size, 1, 16],ckv_cache数据排布为[block_num, rms_size//16, block_size, 1, 16]
- 量化模式下:k_cache数据排布为[block_num, rope_size//32, block_size, 1, 32],ckv_cache数据排布为[block_num, rms_size//32, block_size, 1, 32]
- is_output_kv:bool类型,可选,表示是否输出处理后的k_embed_out和y_out(未量化的原始值),默认值False不输出,仅cache_mode在(PA/PA_BNSD/PA_NZ/PA_BLK_BNSD/PA_BLK_NZ)模式下有效。
输出说明
- k_cache:Tensor类型,和输入k_cache的数据类型、维度、数据格式完全一致(本质in-place更新)。
- ckv_cache:Tensor类型,和输入ckv_cache的数据类型、维度、数据格式完全一致(本质in-place更新)。
- k_embed_out:Tensor类型,仅当is_output_kv=True时输出,表示RoPE处理后的值。要求为4D的Tensor,形状为[batch_size, 1, seq_len, 64],数据类型和格式同输入kv一致。
- y_out:Tensor类型,仅当is_output_kv=True时输出,表示RMSNorm处理后的值。要求为4D的Tensor,形状为[batch_size, 1, seq_len, 512],数据类型和格式同输入kv一致。
约束说明
- 该接口支持推理场景下使用。
- 该接口支持图模式(PyTorch 2.1版本)。
- 量化模式:当k_rope_scale和c_kv_scale非空时,k_cache和ckv_cache的dtype为int8,缓存形状的最后一个维度需要为32(Cache数据格式为FRACTAL_NZ模式),k_rope_scale和c_kv_scale必须同时非空,k_rope_offset和c_kv_offset必须同时为None为非空。
- 非量化模式:当k_rope_scale和c_kv_scale为空时,k_cache和ckv_cache的dtype为bfloat16或float16。
- 索引映射:所有cache_mode缓存模式下,index的值不可以重复,如果传入的index值存在重复,算子的行为是未定义的且不可预知的。
- Norm:index的值表示每个Batch下的偏移
- PA/PA_BNSD/PA_NZ:index的值表示全局的偏移。
- PA_BLK_BNSD/PA_BLK_NZ:index的值表示每个页的全局偏移;这个场景假设cache更新是连续的,不支持非连续更新的cache。
- Shape关联规则:不同的cache_mode缓存模式有不同的Shape规则。
- Norm:k_cache形状为[batch_size, 1, cache_length, rope_size],ckv_cache形状为[batch_size, 1, cache_length, rms_size],index形状为[batch_size, seq_len], cache_length>=seq_len。
- 非Norm模式(PagedAttention相关模式):要求block_num>=Ceil(seq_len/block_size)*batch_size。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件
Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
import torch import torch_npu class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale=None, c_kv_scale=None, k_rope_offset=None, c_kv_offset=None, epsilon=1e-05, cache_mode="Norm", is_output_kv=False): k_cache, v_cache, k_rope, c_kv = torch_npu.npu_kv_rmsnorm_rope_cache(kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale=k_rope_scale, c_kv_scale=c_kv_scale, k_rope_offset=k_rope_offset, c_kv_offset=c_kv_offset, epsilon=epsilon, cache_mode=cache_mode, is_output_kv=is_output_kv) return k_cache, v_cache, k_rope, c_kv model = Model().npu() _, _, k_rope, c_kv = model(kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale, c_kv_scale, None, None, 1e-5, cache_mode, is_output_kv)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
import torch import torch_npu import torchair as tng from torchair.configs.compiler_config import CompilerConfig config = CompilerConfig() config.experimental_config.keep_inference_input_mutations = True npu_backend = tng.get_npu_backend(compiler_config=config) class Model(torch.nn.Module): def __init__(self): super().__init__() def forward(self, kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale=None, c_kv_scale=None, k_rope_offset=None, c_kv_offset=None, epsilon=1e-05, cache_mode="Norm", is_output_kv=False): k_cache, v_cache, k_rope, c_kv = torch_npu.npu_kv_rmsnorm_rope_cache(kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale=k_rope_scale, c_kv_scale=c_kv_scale, k_rope_offset=k_rope_offset, c_kv_offset=c_kv_offset, epsilon=epsilon, cache_mode=cache_mode, is_output_kv=is_output_kv) return k_cache, v_cache, k_rope, c_kv model = Model().npu() model = torch.compile(model, backend=npu_backend, dynamic=False) _, _, k_rope, c_kv = model(kv, gamma, cos, sin, index, k_cache, ckv_cache, k_rope_scale, c_kv_scale, None, None, 1e-5, cache_mode, is_output_kv)