功能描述
- 算子功能:对张量x做dequant反量化+swiglu+quant量化操作,同时支持分组。
- 计算公式:
- group分组(目前仅支持count模式):
对输入x进行分组计算,group_index表示每个group分组的Tokens数,每组使用不同的量化scale(如scale activation_scale、quant_scale)。当group_index=1或None时,表示共享一个scale。
举例说明:假设x.shape=[128, 2H],group_index=[2, 0, 3] ,表示有3个group,对应的scale维度为[3, 2H]。每个group数据使用不同的scale分别做dequant反量化+swiglu+quant量化操作。
- group0=x[0:2, :],scale0=scale[0, :]
- group1=x[2:2, :],scale1=scale[1, :]
- group2=x[2:5, :],scale2=scale[2, :]
- dequant反量化:分别进行权重量化的反量化、激活量化的反量化。
- swiglu激活:对反量化后的x做swiglu(通过attr activate_left控制左右激活),以左激活为例。
- 量化:
- group分组(目前仅支持count模式):
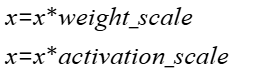
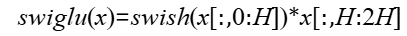
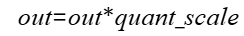
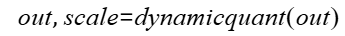
接口原型
torch_npu.npu_dequant_swiglu_quant(Tensor x, *, Tensor? weight_scale=None, Tensor? activation_scale=None, Tensor? bias=None, Tensor? quant_scale=None, Tensor? quant_offset=None, Tensor? group_index=None, bool activate_left=False, int quant_mode=0) -> (Tensor, Tensor)
参数说明

Tensor中shape使用的变量说明:
- TokensNum:表示传输的Tokens数,取值≥0。
- H:表示嵌入向量的长度,取值>0。
- groupNum:表示group_index输入的长度,取值>0。
- x:Tensor类型,表示目标张量。要求是2D的Tensor,shape为[TokensNum, 2H],尾轴为偶数。数据类型支持int32,数据格式为ND。
- weight_scale:Tensor类型,可选参数,表示权重量化对应的反量化系数。要求是2D的Tensor,shape为[groupNum, 2H],数据类型支持float32,数据格式为ND。当x为int32时,要求该参数非None,表示需要做反量化。
- activation_scale:Tensor类型,可选参数,表示per-token权重量化对应的反量化系数。要求是1D的Tensor,shape为[TokensNum],数据类型支持float32,数据格式为ND。当x为int32时,要求该参数非None,表示需要做反量化。
- bias:Tensor类型,可选参数,表示x的偏置变量。数据类型支持int32,数据格式为ND。group_index场景下(非None),该参数不生效为None。
- quant_scale:Tensor类型,可选参数,表示smooth量化系数。要求是2D的Tensor,shape为[groupNum, H],数据类型支持float32,数据格式为ND。
- quant_offset:Tensor类型,可选参数,表示量化中的偏移项。数据类型支持float32,数据格式为ND。group_index场景下(非None),该参数不生效为None。
- group_index:Tensor类型,可选参数,当前只支持count模式,表示该模式下指定分组的Tokens数(要求非负整数)。要求是1D的Tensor,数据类型支持int64,数据格式ND。
- activate_left:bool类型,可选参数,Swiglu流程中是否进行左激活,默认False。
- 取True时,out=swish(split[x, -1, 2][0])*split[x, -1, 2][1]
- 取False时,out=swish(split[x, -1, 2][1])*split[x, -1, 2][0]
- quant_mode:int类型,可选参数,默认0,表示量化类型。0表示静态量化,1表示动态量化。group_index场景下(非None),只支持动态量化即quant_mode=1。
输出说明
- y:Tensor类型,表示量化后的输出tensor。要求是2D的Tensor,shape=[TokensNum, H],数据类型支持int8,数据格式为ND。
- scale: Tensor类型,表示量化的scale参数。要求是1D的Tensor,shape=[TokensNum],数据类型支持float32,数据格式为ND。
约束说明
- 该接口支持推理场景下使用。
- 该接口支持图模式(PyTorch 2.1版本)。
- group_index场景下(非None)约束说明:
- group_index只支持count模式,需要网络保证group_index输入的求和不超过x的TokensNum维度,否则会出现越界访问。
- H轴有维度大小限制:H≤10496同时64对齐场景;规格不满足场景会进行校验。
- 输出y和scale超过group_index总和的部分未进行清理处理,该部分内存为垃圾数据,可能会存在inf/nan异常值,网络使用的时候需要注意影响。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件
Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
import os import shutil import unittest import torch import torch_npu from torch_npu.testing.testcase import TestCase, run_tests from torch_npu.testing.common_utils import SupportedDevices class TestNPUDequantSwigluQuant(TestCase): def test_npu_dequant_swiglu_quant(self, device="npu"): x_shape = [4608, 2048] x = torch.randint(-10, 10, x_shape, dtype=torch.int32).npu() weight_scale = torch.randn(x_shape[1], dtype=torch.float32).npu() activatition_scale = torch.randn((x_shape[0], 1), dtype=torch.float32).npu() bias = None quant_scale = torch.randn((1, x_shape[1] // 2), dtype=torch.float32).npu() quant_offset = None group_index = None y_npu, scale_npu = torch_npu.npu_dequant_swiglu_quant( x, weight_scale=weight_scale, activation_scale=activatition_scale, bias=bias, quant_scale=quant_scale, quant_offset=quant_offset, group_index=group_index, activate_left=False, quant_mode=1, ) if __name__ == "__main__": run_tests()
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
import os import shutil import unittest import torch import torch_npu from torch_npu.testing.testcase import TestCase, run_tests from torch_npu.testing.common_utils import SupportedDevices from torchair.configs.compiler_config import CompilerConfig import torchair as tng config = CompilerConfig() config.experimental_config.frozen_parameter = True config.experimental_config.tiling_schedule_optimize = True npu_backend = tng.get_npu_backend(compiler_config=config) class TestNPUDequantSwigluQuant(TestCase): def test_npu_dequant_swiglu_quant(self, device="npu"): x_shape = [4608, 2048] x = torch.randint(-10, 10, x_shape, dtype=torch.int32).npu() weight_scale = torch.randn(x_shape[1], dtype=torch.float32).npu() activatition_scale = torch.randn((x_shape[0], 1), dtype=torch.float32).npu() bias = None quant_scale = torch.randn((1, x_shape[1] // 2), dtype=torch.float32).npu() quant_offset = None group_index = None grapg_model = torch.compile(torch_npu.npu_dequant_swiglu_quant, backend=npu_backend, dynamic=True, fullgraph=True) y_npu, scale_npu = grapg_model( x, weight_scale=weight_scale, activation_scale=activatition_scale, bias=bias, quant_scale=quant_scale, quant_offset=quant_offset, group_index=group_index, activate_left=False, quant_mode=1, ) if __name__ == "__main__": run_tests()