功能描述
- 算子功能:MoE(Mixture of Expert)的routing计算,根据torch_npu.npu_moe_gating_top_k_softmax的计算结果做routing处理,支持不量化和动态量化模式。
- 计算公式:
1. 对输入expertIdx做排序,得出排序的结果sortedExpertIdx和对应的序号sortedRowIdx:
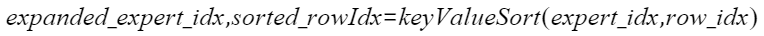
2.以sortedRowIdx做位置映射得出expandedRowIdxOut:
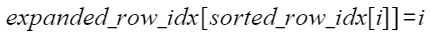
3. 在drop模式下,对sortedExpertIdx的每个专家统计直方图结果,得出expertTokensBeforeCapacityOut:
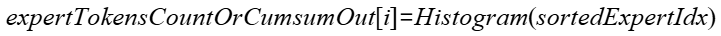
4. 计算quant结果:
动态quant:
若不输入scale:
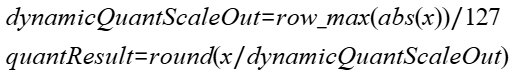
若输入scale:
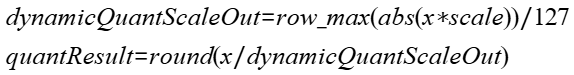
5. 对quantResult取前NUM_ROWS个sortedRowIdx的对应位置的值,得出expandedXOut:
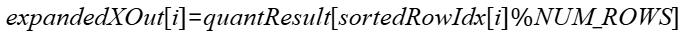
接口原型
torch_npu.npu_moe_init_routing_v2(Tensor x, Tensor expert_idx, *, Tensor? scale=None, Tensor? offset=None, int active_num=-1, int expert_capacity=-1, int expert_num=-1, int drop_pad_mode=0, int expert_tokens_num_type=0, bool expert_tokens_num_flag=False, int quant_mode=0, int[2] active_expert_range=[], int row_idx_type=0) -> (Tensor, Tensor, Tensor, Tensor)
参数说明
- x:Tensor类型,表示MoE的输入即token特征输入,要求为2D的Tensor,shape为(NUM_ROWS, H)。数据类型支持float16、bfloat16、float32、int8,数据格式要求为ND。
- expert_idx:Tensor类型,表示torch_npu.npu_moe_gating_top_k_softmax输出每一行特征对应的K个处理专家,要求是2D的Tensor,shape为(NUM_ROWS, K),且专家id不能超过专家数。数据类型支持int32,数据格式要求为ND。
- scale:Tensor类型,可选输入,用于计算量化结果的参数。数据类型支持float32,数据格式要求为ND。
- 非量化场景下,如果不输入表示计算时不使用scale,且输出expanded_scale中的值未定义;如果输入则要求为1D的Tensor,shape为(NUM_ROWS,)。
- 动态quant场景下,如果不输入表示计算时不使用scale,且输出expanded_scale中的值未定义;如果输入则要求为2D的Tensor,shape为(expert_end-expert_start, H)。
- offset:Tensor类型,可选输入,用于计算量化结果的偏移值。数据类型支持float32,数据格式要求为ND。
- 在非量化场景下不输入。
- 动态quant场景下不输入。
- active_num:int类型,表示总的最大处理row数,输出expanded_x只有这么多行是有效的,取值大于等于0。
- expert_capacity:int类型,表示每个专家能够处理的tokens数,取值范围大于等于0。只有dropless场景下才会校验此输入。
- expert_num:int类型,表示专家数,取值范围[0, 10240]。
- drop_pad_mode:int类型,表示是否为Drop/Pad场景。0表示非Drop/Pad场景,该场景下不校验expert_capacity。
- expert_tokens_num_type:int类型,取值为0和1。0表示cumsum模式 ;1表示count模式,即输出的值为各个专家处理的token数量的累计值。当前仅支持1。
- expert_tokens_num_flag:bool类型,表示是否输出expert_token_cumsum_or_count,默认False表示不输出。当前仅支持True。
- quant_mode:int类型,表示量化模式,支持取值为0、1、-1。0表示静态量化(默认值,但当前版本暂不支持),-1表示不量化场景;1表示动态quant场景。
- active_expert_range:int类型数组,表示活跃expert的范围。数组内值的范围为[expert_start, expert_end],表示活跃的expert范围在expert_start到expert_end之间。要求值大于等于0,并且expert_end不大于expert_num。
- row_idx_type:int类型,表示输出expanded_row_idx使用的索引类型,支持取值0和1,默认值0。0表示gather类型的索引;1表示scatter类型的索引。
输出说明
- expanded_x:Tensor类型,根据expert_idx进行扩展过的特征,要求是2D的Tensor,shape为(NUM_ROWS*K, H)。非量化场景下数据类型同x;量化场景下数据类型支持int8。数据格式要求为ND。
- expanded_row_idx:Tensor类型,expanded_x和x的映射关系, 要求是1D的Tensor,shape为(NUM_ROWS*K, ),数据类型支持int32,数据格式要求为ND。
- expert_token_cumsum_or_count:Tensor类型,active_expert_range范围内expert对应的处理token的总数。要求是1D的Tensor,shape为(expert_end-expert_start, )。数据类型支持int64,数据格式要求为ND。
- expanded_scale:Tensor类型,数据类型支持float32,数据格式要求为ND。
- 非量化场景下,当scale未输入时,输出值未定义。当scale输入时,输出表示一个1D的Tensor,shape为(NUM_ROWS*H*K,)。
- 动态quant场景下,输出量化计算过程中scale的中间值,当scale未输入时,输出值未定义,输出表示一个1D的Tensor,shape为(NUM_ROWS *K)。
约束说明
- 该接口支持推理场景下使用。
- 该接口支持图模式(PyTorch 2.1版本)。
- 不支持静态量化模式。
支持的型号
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件
Atlas A3 训练系列产品/Atlas A3 推理系列产品
调用示例
- 单算子模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
import torch import torch_npu bs = 1 h = 613 k = 475 active_num = 475 expert_capacity = -1 expert_num = 226 drop_pad_mode = 0 expert_tokens_num_type = 1 expert_tokens_num_flag = True quant_mode = -1 active_expert_range = [23, 35] row_idx_type = 0 x = torch.randn((bs, h), dtype=torch.float32).npu() expert_idx = torch.randint(0, expert_num, (bs, k), dtype=torch.int32).npu() scale = torch.randn((bs,), dtype=torch.float32).npu() offset = None expanded_x, expanded_row_idx, expert_token_cumsum_or_count, expanded_scale = torch_npu.npu_moe_init_routing_v2( x, expert_idx, scale=scale, offset=offset, active_num=active_num, expert_capacity=expert_capacity, expert_num=expert_num, drop_pad_mode=drop_pad_mode, expert_tokens_num_type=expert_tokens_num_type, expert_tokens_num_flag=expert_tokens_num_flag, active_expert_range=active_expert_range, quant_mode=quant_mode, row_idx_type=row_idx_type)
- 图模式调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
import torch import torch.nn as nn import torch_npu import torchair as tng from torchair.configs.compiler_config import CompilerConfig config = CompilerConfig() npu_backend = tng.get_npu_backend(compiler_config=config) class MoeInitRoutingV2Model(nn.Module): def __init__(self): super().__init__() def forward(self, x, expert_idx, *, scale=None, offset=None, active_num=-1, expert_capacity=-1, expert_num=-1, drop_pad_mode=0, expert_tokens_num_type=0, expert_tokens_num_flag=False, quant_mode=0, active_expert_range=0, row_idx_type=0): return torch.ops.npu.npu_moe_init_routing_v2(x, expert_idx, scale=scale, offset=offset, active_num=active_num, expert_capacity=expert_capacity, expert_num=expert_num, drop_pad_mode=drop_pad_mode, expert_tokens_num_type=expert_tokens_num_type, expert_tokens_num_flag=expert_tokens_num_flag, active_expert_range=active_expert_range, quant_mode=quant_mode, row_idx_type=row_idx_type) def main(): bs = 1 h = 613 k = 475 active_num = 475 expert_capacity = -1 expert_num = 226 drop_pad_mode = 0 expert_tokens_num_type = 1 expert_tokens_num_flag = True quant_mode = -1 active_expert_range = [23, 35] row_idx_type = 0 x = torch.randn((bs, h), dtype=torch.float32).npu() expert_idx = torch.randint(0, expert_num, (bs, k), dtype=torch.int32).npu() scale = torch.randn((bs,), dtype=torch.float32).npu() offset = None moe_init_routing_v2_model = MoeInitRoutingV2Model().npu() moe_init_routing_v2_model = torch.compile(moe_init_routing_v2_model, backend=npu_backend, dynamic=False) expanded_x, expanded_row_idx, expert_token_cumsum_or_count, expanded_scale = moe_init_routing_v2_model(x, expert_idx, scale=scale, offset=offset, active_num=active_num, expert_capacity=expert_capacity, expert_num=expert_num, drop_pad_mode=drop_pad_mode, expert_tokens_num_type=expert_tokens_num_type, expert_tokens_num_flag=expert_tokens_num_flag, active_expert_range=active_expert_range, quant_mode=quant_mode, row_idx_type=row_idx_type) if __name__ == '__main__': main()