LLaMA2引入了一系列预训练和微调大语言模型,参数量范围从7B到70B。相比LLaMA,LLaMA2的训练token增加了40%,上下文长度更长,支持旋转位置编码, 并且利用了分组查询注意力机制来节省参数量,从而加速训练和推理。LLaMA的高效、开源以及对商业使用的宽容使得它成为目前客户最愿意尝试训练的模型。
本小节将以NPU平台上的客户实际成功案例来介绍LLaMA2-70B模型的训练过程。
主要模型与优化器初始配置
配置项 |
说明 |
数值 |
|---|---|---|
tensor-model-parallel-size |
张量并行度 |
8 |
pipeline-model-parallel-size |
流水线并行度 |
8 |
num-layers |
层数 |
80 |
hidden-size |
隐状态维度 |
8192 |
ffn-hidden-size |
前馈网络隐状态维度 |
28672 |
num-attention-heads |
注意力头的数量 |
64 |
normalization |
归一化方法 |
RMSNorm |
num-query-groups |
查询组数量 |
8 |
micro-batch-size |
微批大小 |
2 |
global-batch-size |
全局批大小 |
1024 |
seq-length |
序列长度 |
4096 |
max-position-embeddings |
最大输入序列长度 |
4096 |
hidden_dropout |
隐藏层dropout |
0.0 |
attention_dropout |
注意力层dropout |
0.0 |
lr |
学习率 |
1.5e-4 |
lr-decay-style |
学习率衰减方式 |
cosine |
min-lr |
最低学习率 |
1e-5 |
weight-decay |
权重衰减 |
1e-2(过低) |
clip-grad |
修剪梯度 |
1 |
lr-warmup-fraction |
学习率预热步数占比 |
0.01 |
adam-beta1 |
adam优化器梯度动量参数 |
0.9 |
adam-beta2 |
adam优化器梯度方差参数 |
0.999 (参数过大) |
adam-eps |
adam优化器极小值参数 |
1e-8 |
- 模型使用ModelLink LLaMA2预训练脚本,主要模型与优化器初始配置参见表1。
- 从表1中,可观察到:
- 70B模型开启了张量并行和流水线并行,全局batch token数配置为global-batch-size * seq-length=4M。
- 隐藏层(MLP和注意力输出)和注意力层(注意力概率张量)的dropout都被关闭。
- 70B模型未开始旋转位置编码,仍然用的固定位置编码,最长序列4096。
- 优化器配置对大语言模型训练的稳定性非常重要。
- 此模型使用的学习率是1.5e-4,对4M token的全局batch来说,1e-4量级的基准学习率是合适的。对于1M token的全局batch来说,一般的基准学习率在1e-5量级。
- 在整个训练过程中,学习率会不断变化。
在初始阶段,优化方向波动比较大,训练不太稳定,此时学习率会从最低1e-5开始线性上升,称为warmup。warmup步数占总体训练步数的比例是0.01,如果训练2万步,则在200步时学习率达到基准的1.5e-4。之后通过线性或者余弦曲线逐步下降,以适应后期可能出现的训练不稳定,此模型使用的是余弦学习率衰减。
- 权重衰减作为正则方法的一种,通过调节模型复杂度对损失函数的影响,防止过拟合。
权重衰减0.01是参数值平方和的惩罚系数,也叫L2 penalty。在bfloat16混合精度训练中,权重衰减能够防止突然的loss发散。所以0.01的权重衰减容易引起尖刺,修改为0.1会有利于避免训练不稳定。
- Adam优化器广泛应用于大语言模型训练,主要有以下三个参数:
- adam-beta1:影响梯度动量。
- adam-beta2:影响梯度方差。
- adam-eps:为了防止除0异常加入的一个极小值。
问题分析及优化方案
- loss尖刺问题
- 问题分析:
LLaMA2-70B模型在训练过程中,遇到的最常见问题是loss尖刺。首先要明确的是loss尖刺并非NPU平台独有,在主流AI处理器上训练大语言模型同样会遇到loss尖刺。MetaAI的研究表明loss尖刺是Adam优化器进入了不稳定状态。 不稳定状态的根源又在于更新张量的时序依赖。
- 优化方案:
在本模型训练中, 我们将adam_beta2从0.999降低到0.95后,大部分loss尖刺消失,剩余loss尖刺幅度也极大降低。对于剩余的loss尖刺,可以通过跳过batch消除,如果尖刺可以快速恢复正常, 也可以忽略尖刺继续训练。
除此之外,消除loss尖刺的方式还包括:
- 问题分析:
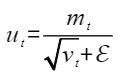
- 下游评测任务跑分不达预期
- 问题分析:
LLaMA2-70B模型在训练完成后,遇到的问题是下游评测任务跑分不达预期。在分析不达预期模型的训练过程后,发现训练过程太多不稳定。
- 优化方案:
从第一个不稳定点重新训练后,在训练稳定收敛的情况下,下游评测任务跑分可以达到预期。
- 问题分析:
- 大集群内部分机器的通信问题
- 问题分析:
LLaMA2-70B模型训练过程中,遇到的另外一个问题是大集群拉起时部分机器存在通信问题,慢机、故障机以及HPFS(High Performance File System)高性能文件系统挂载失败等。
- 优化方案:
改进的措施包括获取裸金属机器后,需对集群中各节点机器进行连通性检查和性能验证。另外数据集最好预先下载到本地磁盘,免去共享磁盘多节点读写的时间成本。拉起等待时间过长主要原因是带宽不够,IO时间过长,也有一些问题机器拖了后腿。可以通过小集群排查,对比性能数据,排除性能较差的机器。
- 问题分析:
- 超参配置导致的问题
- 问题分析:
客户拥有主流AI处理器的环境时,也会拿NPU训练做对比,借此检验NPU平台训练的稳定性。因为训练框架各异,并不能完全做一对一的比较。但是实际情况中遇到最多的训练稳定性或者loss高过预期,最后都确认为超参配置问题。
例如:- adam优化器beta2设为0.999,推荐值为0.95。过大的beta2更可能使训练进入不稳定。
- adam优化器epsilon设为1e-5,比推荐值1e-8大了几个数量级。
- 开启dropout引起训练的不确定。
- 软件栈版本不一致,例如DeepSpeed、Megatron-LM版本。
- 配套的CANN以及Ascend Extension for PyTorch版本较老。
- 过高的学习率(例如2e-2),且未设置学习率warmup。
- 使用不共享word embedding层设置的预训练权重,去初始化共享word embedding层的模型,使得模型训练loss不收敛。用不同参数配置的权重去初始化往往不如随机初始化从头训练收敛的更好。
- DeepSpeed分布式优化器存在计算通信同步bug。
- 优化方案:
根据发现的错误进行优化和问题消减。
- 问题分析: