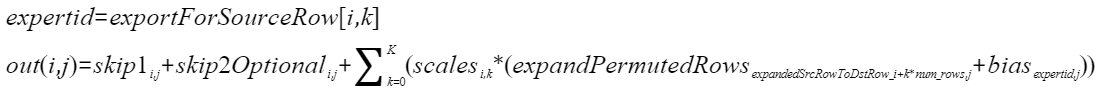
接口原型
npu_moe_finalize_routing(Tensor expanded_permuted_rows, Tensor skip1, Tensor? skip2, Tensor bias, Tensor scales, Tensor expanded_src_to_dst_row, Tensor export_for_source_row) -> Tensor
参数说明
- expanded_permuted_rows:必选参数,经过专家处理过的结果,要求是一个2D的Tensor,数据类型支持FLOAT16、BFLOAT16、FLOAT32,数据格式要求为ND。shape支持(NUM_ROWS * K, H),NUM_ROWS为行数,K为从总的专家E中选出K个专家,H为列数。
- skip1:必选参数,求和的输入参数1,要求是一个2D的Tensor,数据类型要求与expanded_permuted_rows一致 ,shape要求与输出out的shape一致。
- skip2:可选参数,求和的输入参数2,要求是一个2D的Tensor,数据类型要求与expanded_permuted_rows一致 ,shape要求与输出out的shape一致。
- bias:必选参数,专家的偏差,要求是一个2D的Tensor,数据类型要求与expanded_permuted_rows一致。shape支持(E,H),E为总的专家个数,H为列数。
- scales:必选参数,专家的权重,要求是一个2D的Tensor,数据类型要求与expanded_permuted_rows一致。
- expanded_src_to_dst_row: 必选参数,保存每个专家处理结果的索引,要求是一个1D的Tensor,数据类型支持INT32。shape支持(NUM_ROWS * K),NUM_ROWS为行数,K为从总的专家E中选出K个专家,Tensor中的值取值范围是[0,NUM_ROWS * K-1]。
- export_for_source_row: 必选参数,每行处理的专家号,要求是一个2D的Tensor,数据类型支持INT32。shape支持(NUM_ROWS,K),NUM_ROWS为行数,K为从总的专家E中选出K个专家
输出说明
out:Device侧的Tensor类型,最后处理合并MoE FFN的输出结果。
约束说明
尾轴H,K中最大值小于8KB。
支持的PyTorch版本
- PyTorch 2.3
- PyTorch 2.2
- PyTorch 2.1
- PyTorch 1.11.0
支持的型号
Atlas A2 训练系列产品
调用示例
import torch
import torch_npu
expert_num = 16
token_len = 10
top_k = 4
num_rows = 50
device =torch.device('npu')
dtype = torch.float32
expanded_permuted_rows = torch.randn((num_rows * top_k, token_len), device=device, dtype=dtype)
skip1 = torch.randn((num_rows, token_len), device=device, dtype=dtype)
skip2_optional = torch.randn((num_rows, token_len), device=device, dtype=dtype)
bias = torch.randn((expert_num, token_len), device=device, dtype=dtype)
scales = torch.randn((num_rows, top_k), device=device, dtype=dtype)
expert_for_source_row = torch.randint(low=0, high=expert_num, size=(num_rows, top_k), device=device, dtype=torch.int32)
expanded_src_to_dst_row = torch.randint(low=0, high=num_rows * top_k, size=(num_rows * top_k,), device=device, dtype=torch.int32)
output = torch_npu.npu_moe_finalize_routing(expanded_permuted_rows, skip1, skip2_optional, bias, scales, expanded_src_to_dst_row, expert_for_source_row)