功能描述
全量FA实现,实现对应公式:
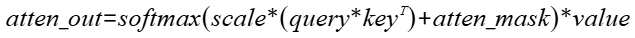
接口原型
torch_npu.npu_prompt_flash_attention(Tensor query, Tensor key, Tensor value, *, Tensor? pse_shift=None, padding_mask=None, Tensor? atten_mask=None, int[]? actual_seq_lengths=None, Tensor? deq_scale1=None, Tensor? quant_scale1=None, Tensor? deq_scale2=None, Tensor? quant_scale2=None, Tensor? quant_offset2=None, int num_heads=1, float scale_value=1.0, int pre_tokens=2147473647, int next_tokens=0, str input_layout="BSH", int num_key_value_heads=0, int[]? actual_seq_lengths_kv=None, int sparse_mode=0) -> Tensor
参数说明
- query(Tensor*,计算输入):Device侧的Tensor,公式中的输入Q,数据类型支持FLOAT16、BFLOAT16、INT8,数据类型与key的数据类型需满足数据类型推导规则,即保持与key、value的数据类型一致。不支持非连续的Tensor,数据格式支持ND,Atlas 推理系列加速卡产品仅支持FLOAT16。
- key(Tensor*,计算输入):Device侧的Tensor,公式中的输入K,数据类型支持FLOAT16、BFLOAT16、INT8,数据类型与query的数据类型需满足数据类型推导规则,即保持与query、value的数据类型一致。不支持非连续的Tensor,数据格式支持ND,Atlas 推理系列加速卡产品仅支持FLOAT16。
- value(Tensor*,计算输入):Device侧的Tensor,公式中的输入V,数据类型支持FLOAT16、BFLOAT16、INT8,数据类型与query的数据类型需满足数据类型推导规则,即保持与query、key的数据类型一致。不支持非连续的Tensor,数据格式支持ND,Atlas 推理系列加速卡产品仅支持FLOAT16。
- *:代表其之前的变量是位置相关,需要按照顺序输入,必选;之后的变量是键值对赋值的,位置无关,可选(不输入会使用默认值)。
- pse_shift(Tensor*,计算输入):Device侧的Tensor,可选参数,数据类型支持FLOAT16、BFLOAT16,且在pseShift为FLOAT16类型时,要求此时的query、key、value均为FLOAT16类型,而在pseShift为BFLOAT16类型时,要求此时的query、key、value均为BFLOAT16类型。在query、key、value为FLOAT16且pseShift存在的情况下,默认走高精度模式。不支持非连续的Tensor,数据格式支持ND。输入shape类型需为(B,N,Q_S,KV_S)或(1,N,Q_S,KV_S),其中Q_S为query的shape中的S,KV_S为key和value的shape中的S。对于pseShift的KV_S为非32字节对齐的场景,建议padding到32字节来提高性能,多余部分的填充值不做要求。如不使用该功能时可传入nullptr。综合约束请见约束与限制,Atlas 推理系列加速卡产品仅支持nullptr。
- padding_mask:预留参数,暂未使用,默认值为None。
- atten_mask(Tensor*,计算输入):Device侧的Tensor,代表下三角全为0上三角全为负无穷的倒三角mask矩阵,不支持非连续的Tensor,数据类型支持BOOL、INT8和UINT8。数据格式支持ND。如果不使用该功能可传入nullptr。通常建议shape输入Q_S,KV_S;B,Q_S,KV_S;1,Q_S,KV_S;B,1,Q_S,KV_S;1,1,Q_S,KV_S,其中Q_S为query的shape中的S,KV_S为key和value的shape中的S,对于atten_mask的KV_S为非32字节对齐的场景,建议padding到32字节对齐来提高性能,多余部分填充成1。综合约束请见约束与限制。
- actual_seq_lengths(IntArray*,计算输入):Host侧的IntArray,代表不同Batch中query的有效Sequence Length,数据类型支持INT64。如果不指定seqlen可以转入nullptr,表示和query的shape的s长度相同。限制:该入参中每个batch的有效Sequence Length应该不大于query中对应batch的Sequence Length,Atlas 推理系列加速卡产品器仅支持nullptr。
- deq_scale1(Tensor*,计算输入):Device侧的Tensor,数据类型支持UINT64、FLOAT32。数据格式支持ND(参考),表示BMM1后面反量化的量化因子,支持per-tensor。 如不使用该功能时可传入nullptr,Atlas 推理系列加速卡产品仅支持nullptr。
- quant_scale1(Tensor*,计算输入):Device侧的Tensor,数据类型支持FLOAT32。数据格式支持ND(参考),表示BMM2前面量化的量化因子,支持per-tensor。 如不使用该功能时可传入nullptr,Atlas 推理系列加速卡产品仅支持nullptr。
- deq_scale2(Tensor*,计算输入):Device侧的Tensor,数据类型支持UINT64、FLOAT32。数据格式支持ND(参考),表示BMM2后面量化的量化因子,支持per-tensor。 如不使用该功能时可传入nullptr,Atlas 推理系列加速卡产品仅支持nullptr。
- quant_scale2(Tensor*,计算输入):Device侧的Tensor,数据类型支持FLOAT32。数据格式支持ND(参考),表示输出量化的量化因子,支持per-tensor,per-channel。 如不使用该功能时可传入nullptr,Atlas 推理系列加速卡产品仅支持nullptr。
- quant_offset2(Tensor*,计算输入):Device侧的Tensor,数据类型支持FLOAT32。数据格式支持ND(参考),表示输出量化的量化偏移,支持per-tensor,per-channel。 如不使用该功能时可传入nullptr,Atlas 推理系列加速卡产品仅支持nullptr。
- num_heads(int64_t,计算输入):Host侧的int,代表query的head个数,数据类型支持INT64。
- scale_value(double,计算输入):Host侧的double,公式中d开根号的倒数,代表缩放系数,作为计算流中Muls的scalar值,数据类型支持DOUBLE。数据类型与query的数据类型需满足数据类型推导规则。用户不特意指定时可传入默认值1.0。
- pre_tokens(int64_t,计算输入):Host侧的int,用于稀疏计算,表示attention需要和前几个Token计算关联,数据类型支持INT64。用户不特意指定时可传入默认值2147483647,sparseMode不为4且D不超过512时支持负数,Atlas 推理系列加速卡产品仅支持默认值2147483647。
- next_tokens(int64_t,计算输入):Host侧的int,用于稀疏计算,表示attention需要和后几个Token计算关联。数据类型支持INT64。用户不特意指定时可传入默认值0,sparseMode不为4且D不超过512时支持负数,Atlas 推理系列加速卡产品仅支持默认值0和2147483647。
- input_layout(char*,计算输入):Host侧的字符指针CHAR*,用于标识输入query、key、value的数据排布格式,当前支持BSH、BSND、BNSD。用户不特意指定时可传入默认值"BSH”。
- num_key_value_heads(int64_t,计算输入):Host侧的int,代表key、value中head个数,用于支持GQA(Grouped-Query Attention,分组查询注意力)场景,数据类型支持INT64。用户不特意指定时可传入默认值0,表示和key/value的head个数相等。限制:在BNSD场景下,需要与shape中的key/value的N轴shape值相同,且需要满足num_heads整除num_key_value_heads,num_heads与num_key_value_heads的比值不能大于64,否则报错,Atlas 推理系列加速卡产品仅支持默认值0。
- actual_seq_lengths_kv(IntArray*,计算输入):Host侧的aclIntArray,可传入nullptr,代表不同batch中key/value的有效Sequence Length。数据类型支持INT64。限制:该入参中每个batch的有效Sequence Length应该不大于key/value中对应batch的Sequence Length,Atlas 推理系列加速卡产品仅支持nullptr。
- sparse_mode(int64_t,计算输入):Host侧的int,表示sparse的模式。数据类型支持INT64,Atlas 推理系列加速卡产品仅支持默认值0。
- sparse_mode为0时,代表defaultMask模式,如果atten_mask未传入则不做mask操作,忽略pre_tokens和next_tokens(内部赋值为INT_MAX);如果传入,则需要传入完整的atten_mask矩阵(S1 * S2),表示pre_tokens和next_tokens之间的部分需要计算。
- sparse_mode为1时,代表allMask。
- sparse_mode为2时,代表leftUpCausal模式的mask,需要传入优化后的atten_mask矩阵(2048*2048)。
- sparse_mode为3时,代表rightDownCausal模式的mask,均对应以左顶点为划分的下三角场景,需要传入优化后的atten_mask矩阵(2048*2048)。
- sparse_mode为4时,代表band模式的mask,需要传入优化后的atten_mask矩阵(2048*2048)。
- sparse_mode为5、6、7、8时,分别代表prefix、global、dilated、block_local,均暂不支持。用户不特意指定时可传入默认值0。综合约束请见约束与限制。
输出说明
共一个输出,为计算的最终结果atten_out,类型为Tensor,shape与query保持一致。·
约束说明
- 该接口与pytorch配合使用时,需要保证CANN相关包与PyTorch相关包的版本匹配。
- 入参为空的处理:算子内部需要判断参数query是否为空,如果是空则直接返回。参数query不为空Tensor,参数key、value为空tensor(即S2为0),则填充全零的对应shape的输出(填充attention_out)。attention_out为空Tensor时,AscendCLNN框架会处理。其余在上述参数说明中标注了"可传入nullptr"的入参为空指针时,不进行处理。
- query,key,value输入,功能使用限制如下:
- Atlas A2 训练系列产品:
- 支持B轴小于等于65535(64k),D轴32byte不对齐时仅支持到128。
- 支持N轴小于等于256。
- 高性能模式S支持小于等于524288(512k),高精度模式小于等于262144(256k);
- 支持D轴小于等于512。
- Atlas 推理系列加速卡产品:
- 支持B轴小于等于128。
- 支持N轴小于等于256。
- 支持S轴小于等于65535(64k), 大于等于16,如果S轴大于128,则必须128对齐,且不对齐不等长场景不支持配置atten_mask。
- 支持D轴小于等于512。
- 不对齐不等长场景该版本实现部分泛化,若有需求,优先推荐使用后续版本。
- Atlas A2 训练系列产品:
- 参数sparse_mode当前仅支持值为0、1、2、3、4的场景,取其它值时会报错。
- sparse_mode= 0时,atten_mask如果为空指针,则忽略入参pre_tokens、next_tokens(内部赋值为INT_MAX)。
- sparse_mode= 2、3、4时,atten_mask的shape需要为S,S或1,S,S或1,1,S,S,其中S的值需要固定为2048,且需要用户保证传入的atten_mask为下三角,不传入attenMask或者传入的shape不正确报错。
- sparse_mode= 1、2、3的场景忽略入参pre_tokens、next_tokens并按照相关规则赋值。
- sparse_mode= 4时,pre_tokens、next_tokens必须为非负数。
- int8量化相关入参数量与输入、输出数据格式的综合限制:
- 输入为INT8,输出为INT8的场景:入参deq_scale1、quant_scale1、deq_scale2、quant_scale2需要同时存在,quant_offset2可选,不传时默认为0。
- 输入为INT8,输出为FLOAT16的场景:入参deq_scale1、quant_scale1、deq_scale2需要同时存在,若存在入参quant_offset2或 quant_scale2(即不为nullptr),则报错并返回。
- 输入为FLOAT16或BFLOAT16,输出为INT8的场景:入参quant_scale2需存在,quant_offset2可选,不传时默认为0,若存在入参deq_scale1或 quant_scale1或 deq_scale2(即不为nullptr),则报错并返回。
- 入参 quant_offset2和 quant_scale2支持 per-tensor 或 per-channel 格式和 FLOAT32/BFLOAT16 两种数据类型。
- pse_shift功能使用限制如下:
- 仅支持query,key,value数据类型为FLOAT16或BFLOAT16场景下使用该功能。
- query,key,value数据类型为FLOAT16且pseShift存在时,强制走高精度模式,对应的限制继承自高精度模式的限制。
- Q_S需大于等于query的S长度,KV_S需大于等于key的S长度。
- 输出为INT8,入参quantOffset2传入非空指针和非空tensor值,并且sparse_mode、pre_tokens和next_tokens满足以下条件,矩阵会存在某几行不参与计算的情况,导致计算结果误差,该场景会拦截:
- sparse_mode= 0,atten_mask如果非空指针,每个batch actual_seq_lengths-actual_seq_lengths_kv- pre_tokens> 0 或 next_tokens< 0 时,满足拦截条件
- sparse_mode= 1 或 2,不会出现满足拦截条件的情况。
- sparse_mode= 3,每个batch actual_seq_lengths_kv- actual_seq_lengths< 0,满足拦截条件。
- sparse_mode= 4,pre_tokens< 0 或 每个batch next_tokens+ actual_seq_lengths_kv- actual_seq_lengths< 0 时,满足拦截条件。
支持的PyTorch版本
- PyTorch 2.1
支持的芯片型号
- Atlas A2 训练系列产品
- Atlas 推理系列加速卡产品
调用示例
# 单算子调用方式
import torch
import torch_npu
import math
# 生成随机数据,并发送到npu
q = torch.randn(1, 8, 164, 128, dtype=torch.float16).npu()
k = torch.randn(1, 8, 1024, 128, dtype=torch.float16).npu()
v = torch.randn(1, 8, 1024, 128, dtype=torch.float16).npu()
scale = 1/math.sqrt(128.0)
# 调用PFA算子
out = torch_npu.npu_prompt_flash_attention(q, k, v, num_heads = 8, input_layout = "BNSD", scale_value=scale, pre_tokens=65535, next_tokens=65535)
# 执行上述代码的输出类似如下
tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140],
[ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117],
[ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062],
...,
[ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039],
[ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164],
[ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]],
device='npu:0', dtype=torch.float16)
# 入图方式
import torch
import torch_npu
import math
import torchair as tng
from torchair.ge_concrete_graph import ge_apis as ge
from torchair.configs.compiler_config import CompilerConfig
import torch._dynamo
TORCHDYNAMO_VERBOSE=1
TORCH_LOGS="+dynamo"
# 支持入图的打印宏
import logging
from torchair.core.utils import logger
logger.setLevel(logging.DEBUG)
config = CompilerConfig()
config.aoe_config.aoe_mode = "2"
config.debug.graph_dump.type = "pbtxt"
npu_backend = tng.get_npu_backend(compiler_config=config)
from torch.library import Library, impl
# 数据生成
q = torch.randn(1, 8, 164, 128, dtype=torch.float16).npu()
k = torch.randn(1, 8, 1024, 128, dtype=torch.float16).npu()
v = torch.randn(1, 8, 1024, 128, dtype=torch.float16).npu()
scale = 1/math.sqrt(128.0)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self):
return torch_npu.npu_prompt_flash_attention(q, k, v, num_heads = 8, input_layout = "BNSD", scale_value=scale, pre_tokens=65535, next_tokens=65535)
def MetaInfershape():
with torch.no_grad():
model = Model()
model = torch.compile(model, backend=npu_backend, dynamic=False, fullgraph=True)
graph_output = model()
single_op = torch_npu.npu_prompt_flash_attention(q, k, v, num_heads = 8, input_layout = "BNSD", scale_value=scale, pre_tokens=65535, next_tokens=65535)
print("single op output with mask:", single_op, single_op.shape)
print("graph output with mask:", graph_output, graph_output.shape)
if __name__ == "__main__":
MetaInfershape()
# 执行上述代码的输出类似如下
single op output with mask: tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140],
[ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117],
[ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062],
...,
[ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039],
[ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164],
[ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]],
device='npu:0', dtype=torch.float16) torch.Size([1, 8, 164, 128])
graph output with mask: tensor([[[[ 0.0219, 0.0201, 0.0049, ..., 0.0118, -0.0011, -0.0140],
[ 0.0294, 0.0256, -0.0081, ..., 0.0267, 0.0067, -0.0117],
[ 0.0285, 0.0296, 0.0011, ..., 0.0150, 0.0056, -0.0062],
...,
[ 0.0177, 0.0194, -0.0060, ..., 0.0226, 0.0029, -0.0039],
[ 0.0180, 0.0186, -0.0067, ..., 0.0204, -0.0045, -0.0164],
[ 0.0176, 0.0288, -0.0091, ..., 0.0304, 0.0033, -0.0173]]]],
device='npu:0', dtype=torch.float16) torch.Size([1, 8, 164, 128])