介绍
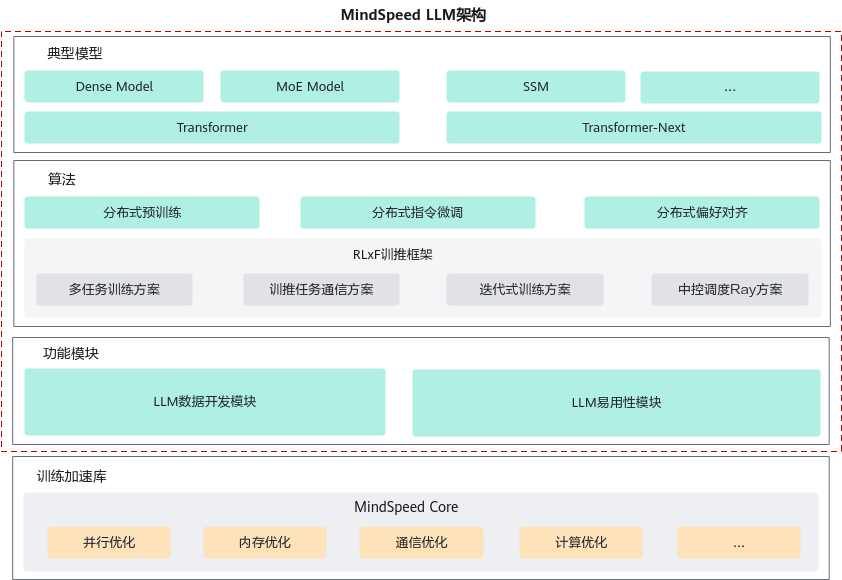
MindSpeed LLM,作为昇腾大模型训练框架,旨在为华为昇腾硬件提供端到端的大语言模型训练方案,包含分布式预训练、分布式指令微调、分布式偏好对齐以及对应的开发工具链。MindSpeed LLM架构关系如图1所示。MindSpeed LLM支持Transformer架构的LLM(Large Language Model,大语言模型)模型,支持MoE大模型的训练和调优。预制100+主流公版模型,提供开箱即用的高性能模型训练脚本。并且,MindSpeed LLM支持分布式场景下的预训练、指令微调、偏好对齐等训练方案,RLXF训推框架通过多任务训练方案、任务通信方案、中控调度方案等实现训推融合的效果。此外,MindSpeed LLM具备大模型开发功能模块,包括预训练/指令微调数据集处理、权重格式转换、大模型Benchmark评估、性能分析Profiling数据采集等。MindSpeed LLM是基于训练加速库MindSpeed的大语言模型分布式训练框架,原生对接MindSpeed训练加速库,从并行优化、内存优化、通信优化、计算优化四大方面,极致优化基于昇腾硬件的大模型训练。
使用MindSpeed LLM大模型套件
为提升大模型的易用性与训练效率,昇腾精心打造MindSpeed LLM大模型套件,该套件以MindSpeed为核心加速引擎,为用户构建了一套全面且高效的解决方案,旨在简化大模型训练流程。MindSpeed LLM目前涵盖了LLaMA、Qwen、DeepSeek、Mixtral、GLM、InternLM、Baichuan等业界领先的LLM系列,所有支持的模型列表可单击Link进行参考。用户仅需进行简单的参数配置调整,在MindSpeed LLM支持的主流大模型上即可无缝使用MindSpeed训练加速库的优化特性,极致优化训练大模型性能,提升大模型训练易用性。
以MindSpeed LLM支持的LLaMA2 7B大模型为例,运行大模型预训练。
前提准备
在进行大模型预训练前需要完成前期准备工程,包括如下步骤。
- 参考安装依赖软件完成环境准备。
- 拉取源码和安装依赖项。
git clone https://gitee.com/ascend/MindSpeed-LLM.git git clone https://github.com/NVIDIA/Megatron-LM.git cd Megatron-LM git checkout core_r0.6.0 cp -r megatron ../MindSpeed-LLM/ cd .. cd MindSpeed-LLM git checkout 1.0.0 mkdir logs mkdir model_from_hf mkdir dataset mkdir ckpt # 安装加速库 git clone https://gitee.com/ascend/MindSpeed.git cd MindSpeed # checkout commit from MindSpeed core_r0.6.0 in 1021 git checkout 969686ff pip install -r requirements.txt pip3 install -e . cd .. # 安装其余依赖库 pip install -r requirements.txt
- 下载权重。
可单击llama-2-7b获取模型配置和权重文件(pytorch_model-0000*-of-00002.bin),并放于model_from_hf/Llama2-hf目录下。

用户需要自行设置代理,以便访问或下载权重。
model_from_hf/Llama2-hf参考目录如下:
├── Llama2-hf ├── .gitattributes ├── README.md ├── config.json ├── generation_config.json ├── pytorch_model-00001-of-00002.bin ├── pytorch_model-00002-of-00002.bin ├── pytorch_model.bin.index.json ├── special_tokens_map.json ├── tokenizer.json ├── tokenizer.model └── tokenizer_config.json - 数据准备和处理。
- 数据集下载。
可单击Alpaca数据集下载数据集,放置在dataset目录下。
用户需要自行设置代理,以便访问或下载数据集。
- 数据集处理。
# 按照真实环境修改 set_env.sh 路径 source /usr/local/Ascend/ascend-toolkit/set_env.sh python ./preprocess_data.py \ --input ./dataset/train-00000-of-00001-a09b74b3ef9c3b56.parquet \ --tokenizer-name-or-path ./model_from_hf/Llama2-hf/ \ --tokenizer-type PretrainedFromHF \ --handler-name GeneralPretrainHandler \ --output-prefix ./dataset/alpaca \ --json-keys text \ --workers 4 \ --log-interval 1000
- 数据集下载。
大模型预训练
- 配置路径。
以LLaMA2 7B模型为例,预训练脚本为examples/mcore/llama2/pretrain_llama2_7b_ptd.sh,用户需根据实际情况修改脚本中的路径和参数值。
1 2 3 4
CKPT_SAVE_DIR="your model save ckpt path" DATA_PATH="your data path" TOKENIZER_MODEL="your tokenizer path" CKPT_LOAD_DIR="your model ckpt path"
修改示例如下:
1 2 3 4
CKPT_SAVE_DIR=./ckpt DATA_PATH=./dataset/alpaca_text_document TOKENIZER_MODEL=./model_from_hf/Llama2-hf/tokenizer.model CKPT_LOAD_DIR=./
- 启动预训练脚本。
bash examples/mcore/llama2/pretrain_llama2_7b_ptd.sh
配置说明
- 并行算法
--tensor-model-parallel-size # 张量并行 --pipeline-model-parallel-size # 流水线并行 --sequence-parallel # 序列并行
- 融合算子
--use-flash-attn # Flash Attention融合算子 --normalization RMSNorm # RMSNorm归一化 --use-fused-rmsnorm # RMSNorm融合算子 --swiglu # SwiGLU激活函数 --use-fused-swiglu # SwiGLU融合优化 --position-embedding-type rope # RoPE位置嵌入 --use-fused-rotary-pos-emb # RoPE融合算子
- 通信优化
--overlap-grad-reduce # 异步DDP