在算子实现章节已经介绍了host侧tiling核心的实现方法,本章节侧重于介绍接入CANN框架时编程模式和API的使用。
大多数情况下,Local Memory的存储,无法完整的容纳算子的输入与输出,需要每次搬运一部分输入进行计算然后搬出,再搬运下一部分输入进行计算,直到得到完整的最终结果,这个数据切分、分块计算的过程称之为Tiling。根据算子的shape等信息来确定数据切分算法相关参数(比如每次搬运的块大小,以及总共循环多少次)的计算程序,称之为Tiling实现。
Tiling实现完成后,获取到的Tiling切分算法相关参数,会传递给kernel侧,用于指导并行数据的切分。由于Tiling实现中完成的均为标量计算,AI Core并不擅长,所以我们将其独立出来放在host CPU上执行。

如上图所示,Tiling实现即为根据算子shape等信息来确定切分算法相关参数的过程,这里的算子shape等信息可以理解为是Tiling实现的输入,切分算法相关参数可以理解为是Tiling实现的输出。输入和输出都通过Tiling函数的参数(TilingContext* context上下文结构)来承载。也就是说,开发者可以从上下文结构中获取算子的输入、输出以及属性信息,也就是Tiling实现的输入,经过Tiling计算后,获取到TilingData数据结构(切分算法相关参数)、blockDim变量、用于选择不同的kernel实现分支的TilingKey、算子workspace的大小,也就是Tiling实现的输出,并将这些输出设置到上下文结构中。
TilingData、blockDim、TilingKey、workspace这些概念的具体解释如下:
- TilingData:切分算法相关参数,比如每次搬运的块大小,以及总共循环多少次,通过结构体存储,由开发者自行设计。
TilingData结构定义支持单结构定义方法,也支持结构体嵌套:
- 单结构定义方法,以平铺的形式定义:
1 2 3 4 5 6 7 8 9
namespace optiling { BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF(uint32_t, field1); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field2); TILING_DATA_FIELD_DEF(uint32_t, field3); END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 }
Tiling实现函数中对tiling结构成员赋值的方式如下:
1 2 3
MyAddTilingData myTiling; myTiling.set_field1(1); myTiling.set_field2(2);
- 支持结构体嵌套:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
namespace optiling { BEGIN_TILING_DATA_DEF(MyStruct1) // 声明结构1名字 TILING_DATA_FIELD_DEF(uint32_t, field1); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field2); // 结构成员的类型和名字 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyStruct1Op, MyStruct1) // 注册结构体到<op_type>Op BEGIN_TILING_DATA_DEF(MyStruct2) // 声明结构2名字 TILING_DATA_FIELD_DEF(uint32_t, field3); // 结构成员的类型和名字 TILING_DATA_FIELD_DEF(uint32_t, field4); // 结构成员的类型和名字 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyStruct2Op, MyStruct2) // 注册结构体到<op_type>Op BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF_STRUCT(MyStruct1, st1); // 结构成员的引用结构体 TILING_DATA_FIELD_DEF_STRUCT(MyStruct2, st2); // 结构成员的引用结构体 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 }
Tiling实现函数中对tiling结构成员赋值的方式如下:
1 2 3 4 5
MyAddTilingData myTiling; myTiling.st1.set_field1(1); myTiling.st1.set_field2(2); myTiling.st2.set_field3(3); myTiling.st2.set_field4(4);
- 单结构定义方法,以平铺的形式定义:
- blockDim:规定了核函数将会在几个核上执行。例如,需要计算8M的数据,每个核上计算1M的数据,blockDim设置为8,但是为了充分利用硬件资源,一般将blockDim设置为硬件平台的核数,根据核数进行数据切分。

blockDim是逻辑核的概念,取值范围为[1,65535]。为了充分利用硬件资源,一般设置为物理核的核数或其倍数。对于耦合架构和分离架构,blockDim在运行时的意义和设置规则有一些区别,具体说明如下:
- 耦合架构:由于其Vector、Cube单元是集成在一起的,blockDim用于设置启动多个AICore核实例执行,不区分Vector、Cube。AI Core的核数可以通过GetCoreNumAiv或者GetCoreNumAic获取。
- 分离架构
- 针对仅包含Vector计算的算子,blockDim用于设置启动多少个Vector(AIV)实例执行,比如某款AI处理器上有40个Vector核,建议设置为40。
- 针对仅包含Cube计算的算子,blockDim用于设置启动多少个Cube(AIC)实例执行,比如某款AI处理器上有20个Cube核,建议设置为20。
- 针对Vector/Cube融合计算的算子,启动时,按照AIV和AIC组合启动,blockDim用于设置启动多少个组合执行,比如某款AI处理器上有40个Vector核和20个Cube核,一个组合是2个Vector核和1个Cube核,建议设置为20,此时会启动20个组合,即40个Vector核和20个Cube核。注意:该场景下,设置的blockDim逻辑核的核数不能超过物理核(2个Vector核和1个Cube核组合为1个物理核)的核数。
- AIC/AIV的核数分别通过GetCoreNumAic和GetCoreNumAiv接口获取。
- TilingKey(可选):TilingKey是一个算子内为了区分不同的实现而将kernel代码进行区分的方法,该方法类似于C++的Template模板机制,可减少不必要的icache miss以及scalar耗时,有助于优化单次调用kernel的性能。不同的kernel实现分支可以通过TilingKey来标识,host侧设置TilingKey后,可以选择对应的分支。例如,一个算子在不同的shape下,有不同的算法逻辑,kernel侧可以通过TilingKey来选择不同的算法逻辑,在host侧Tiling算法也有差异,host/kernel侧通过相同的TilingKey进行关联。
假如有如下kernel代码:
1 2 3 4 5
if (condition) { ProcessA(); } else { ProcessB(); }
如果函数ProcessA、ProcessB两个函数是个非常大的函数,那么上述代码在编译后会变得更大,而每次kernel运行只会选择1个分支,条件的判断和跳转在代码大到一定程度(16-32K,不同芯片存在差异)后会出现icache miss。通过TilingKey可以对这种情况进行优化,给2个kernel的处理函数设置不同的TilingKey 1和2:
1 2 3 4 5
if (TILING_KEY_IS(1)) { ProcessA(); } else if (TILING_KEY_IS(2)) { ProcessB(); }
这样device kernel编译时会自动识别到2个TilingKey并编译2个kernel入口函数,将条件判断进行常量折叠。同时需要和host tiling函数配合,判断走ProcessA的场景设置TilingKey为1,走ProcessB的场景设置TilingKey为2:
1 2 3 4 5 6 7 8 9 10
static ge::graphStatus TilingFunc(gert::TilingContext* context) { // some code if (condition) { context->SetTilingKey(1); } else { context->SetTilingKey(2); } return ge::GRAPH_SUCCESS; }
- WorkspaceSize(可选):workspace是设备侧Global Memory上的一块内存。在Tiling函数中可以设置workspace的大小,框架侧会为其申请对应大小的设备侧Global Memory,在对应的算子kernel侧实现时可以使用这块workspace内存。
workspace内存分为两部分:Ascend C API需要的workspace内存和算子实现使用到的workspace内存(按需)。
- Ascend C API需要预留workspace内存
API在计算过程需要一些workspace内存作为缓存,因此算子Tiling函数需要为API预留workspace内存,预留内存大小通过GetLibApiWorkSpaceSize接口获取。
- 算子实现使用到的workspace内存(按需)
整体的workspace内存就是上述两部分之和,在Tiling函数中设置方法如下:
1 2
auto workspaceSizes = context->GetWorkspaceSizes(1); // 只使用1块workspace workspaceSizes[0] = sysWorkspaceSize + usrWorkspaceSize;
- Ascend C API需要预留workspace内存
Tiling实现基本流程
Tiling实现开发的流程图如下:
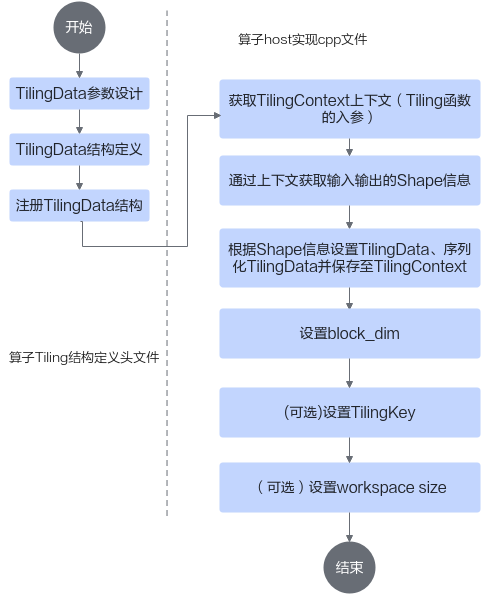
下面将从一个简单的Add算子为例介绍Tiling的实现流程。本样例中待处理数据的Shape大小可以平均分配到每个核上,并且可以对齐到一个datablock(32B)的大小。
首先完成算子TilingData结构定义头文件的编写,该文件命名为“算子名称_tiling.h”,位于算子工程的op_host目录下。样例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { BEGIN_TILING_DATA_DEF(TilingData) // 注册一个tiling的类,以tiling的名字作为入参 TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 添加tiling字段,总计算数据量 TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 添加tiling字段,每个核上总计算数据分块个数 END_TILING_DATA_DEF; // 注册算子tilingdata类到对应的AddCustom算子 REGISTER_TILING_DATA_CLASS(AddCustom, TilingData) } #endif // ADD_CUSTOM_TILING_H |
具体的编写步骤如下:
- 代码框架编写,需要增加#ifndef...的判断条件,防止头文件的重复包含;需要包含register/tilingdata_base.h头文件,tilingdata_base.h中定义了多个用于tilingdata注册的宏。样例代码如下:
1 2 3 4 5 6 7 8 9
#ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { // tiling结构定义和注册代码 // ... } #endif // ADD_CUSTOM_TILING_H
- TilingData参数设计,TilingData参数本质上是和并行数据切分相关的参数,本示例算子使用了2个tiling参数:totalLength、tileNum。totalLength是指需要计算的数据量大小,tileNum是指每个核上总计算数据分块个数。比如,totalLength这个参数传递到kernel侧后,可以通过除以参与计算的核数,得到每个核上的计算量,这样就完成了多核数据的切分。
- TilingData结构定义,通过BEGIN_TILING_DATA_DEF接口定义一个TilingData的类,通过TILING_DATA_FIELD_DEF接口增加TilingData的两个字段totalLength、tileNum,通过END_TILING_DATA_DEF接口结束TilingData定义。相关接口的详细说明请参考TilingData结构定义。
1 2 3 4
BEGIN_TILING_DATA_DEF(TilingData) // 注册一个tiling的类,以tiling的名字作为入参 TILING_DATA_FIELD_DEF(uint32_t, totalLength); // 添加tiling字段,总计算数据量 TILING_DATA_FIELD_DEF(uint32_t, tileNum); // 添加tiling字段,每个核上总计算数据分块个数 END_TILING_DATA_DEF;
- 注册TilingData结构,通过REGISTER_TILING_DATA_CLASS接口,注册TilingData类,和自定义算子相关联。REGISTER_TILING_DATA_CLASS第一个参数为op_type(算子类型),本样例中传入AddCustom,第二个参数为TilingData的类名。REGISTER_TILING_DATA_CLASS接口介绍请参考TilingData结构注册。
1 2
// 注册算子tilingdata类到对应的AddCustom算子 REGISTER_TILING_DATA_CLASS(AddCustom, TilingData)
然后完成算子host实现cpp文件中Tiling函数实现,该文件命名为“算子名称.cpp”,位于算子工程的op_host目录下。样例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
namespace optiling { const uint32_t BLOCK_DIM = 8; const uint32_t TILE_NUM = 8; static ge::graphStatus TilingFunc(gert::TilingContext *context) { TilingData tiling; uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize(); context->SetBlockDim(BLOCK_DIM); tiling.set_totalLength(totalLength); tiling.set_tileNum(TILE_NUM); tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0; return ge::GRAPH_SUCCESS; } } // namespace optiling |
具体步骤如下:
- 获取TilingContext的上下文,即Tiling函数的入参gert::TilingContext* context。
- 设置TilingData。在步骤3中定义了TilingData类后,可以创建该类的一个实例,并通过调用set_{field_name}方法来设置各个字段值(其中field_name是步骤3中定义的tiling字段名)。设置完tiling字段后,通过调用SaveToBuffer方法完成TilingData实例的序列化和保存。
- 通过上下文获取输入输出shape信息。本样例中通过TilingContext的GetInputShape接口获取输入的shape大小。
1 2
// 获取输入shape信息 uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize();
- 设置TilingData。通过调用set_{field_name}方法来设置TilingData的字段值。
1 2 3 4 5
// 用TilingData定义一个具体的实例 TilingData tiling; // 设置TilingData tiling.set_totalLength(totalLength); tiling.set_tileNum(TILE_NUM);
- 调用TilingData类的SaveToBuffer接口完成序列化并保存至TilingContext上下文。SaveToBuffer的第一个参数为存储Buffer的首地址,第二个参数为Buffer的长度。通过调用GetRawTilingData获取无类型的TilingData的地址,再通过GetData获取数据指针,作为Buffer的首地址;通过调用GetRawTilingData获取无类型的TilingData的地址,再通过GetCapacity获取TilingData的长度,作为Buffer的长度。完成SaveToBuffer操作后需要通过SetDataSize设置TilingData的长度,该长度通过TilingData类的GetDataSize接口获取。
1 2 3
// 序列化并保存 tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize());
- 通过上下文获取输入输出shape信息。本样例中通过TilingContext的GetInputShape接口获取输入的shape大小。
- 通过SetBlockDim接口设置blockDim。
1context->SetBlockDim(BLOCK_DIM);
- (可选)通过SetTilingKey设置TilingKey。
1context->SetTilingKey(1);
- (可选)通过GetWorkspaceSizes获取workspace size指针,并设置size大小。此处仅作为举例,设置workspace的大小为0。
1 2
size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0;
Tiling参数设计更多样例-属性信息通过TilingData传递
如果算子包含属性信息,该属性信息可以通过TilingData传递到kernel侧,参与kernel侧算子核函数的计算。以ReduceMaxCustom算子为例,该算子用于对输入数据按维度dim返回最大值,并且返回索引。ReduceMaxCustom算子有两个属性,reduceDim和isKeepDim,reduceDim表示按照哪一个维度进行reduce操作;isKeepDim表示是否需要保持输出的维度与输入一样。本样例仅支持对最后一维做reduce操作,输入数据类型为half。
- ReduceMaxCustom算子TilingData的定义如下:这里我们重点关注reduceAxisLen。参数reduceAxisLen表示获取reduceDim轴的长度,这里也就是最后一维的长度。该参数后续会通过TilingData传递到kernel侧参与计算。
1 2 3 4 5 6 7 8 9 10 11 12 13
#ifndef REDUCE_MAX_CUSTOM_TILING_H #define REDUCE_MAX_CUSTOM_TILING_H #include "register/tilingdata_base.h" namespace optiling { BEGIN_TILING_DATA_DEF(ReduceMaxTilingData) TILING_DATA_FIELD_DEF(uint32_t, reduceAxisLen); // 添加tiling字段,reduceDim轴的长度 //其他TilingData参数的定义 ... END_TILING_DATA_DEF; // 注册算子tilingdata类到对应的ReduceMaxCustom算子 REGISTER_TILING_DATA_CLASS(ReduceMaxCustom, ReduceMaxTilingData) } #endif // REDUCE_MAX_CUSTOM_TILING_H
- ReduceMaxCustom算子的Tiling实现如下。这里我们重点关注属性信息通过TilingData传递的过程:首先通过TilingContext上下文从attr获取reduceDim属性值;然后根据reduceDim属性值获取reduceDim轴的长度并设置到TilingData中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
namespace optiling { static ge::graphStatus TilingFunc(gert::TilingContext* context) { ReduceMaxTilingData tiling; // 从attr获取reduceDim属性值,因为reduceDim是第一个属性,所以GetAttrPointer传入的索引值为0 const gert::RuntimeAttrs* attrs = context->GetAttrs(); const uint32_t* reduceDim = attrs->GetAttrPointer<uint32_t>(0); // 获取reduceDim轴的长度 const gert::StorageShape* xShapePtr = context->GetInputShape(0); const gert::Shape& xShape = xShapePtr->GetStorageShape(); const uint32_t reduceAxisLen = xShape.GetDim(*reduceDim); // 计算TilingData中除了reduceAxisLen之外其他成员变量的值 ... // 将reduceAxisLen设置到tiling结构体中,传递到kernel函数使用 tiling.set_reduceAxisLen(reduceAxisLen); // 设置TilingData中除了reduceAxisLen之外其他成员变量的值 ... // TilingData序列化保存 tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); ... return ge::GRAPH_SUCCESS; }} // namespace optiling
Tiling参数设计更多样例-使用高阶API时配套的Tiling
- 首先进行tiling结构定义:
1 2 3 4 5 6 7
namespace optiling { BEGIN_TILING_DATA_DEF(MyAddTilingData) // 声明tiling结构名字 TILING_DATA_FIELD_DEF_STRUCT(TCubeTiling, cubeTilingData); // 引用高阶API的tiling结构体 TILING_DATA_FIELD_DEF(uint32_t, field); // 结构成员的引用结构体 END_TILING_DATA_DEF; REGISTER_TILING_DATA_CLASS(MyAdd, MyAddTilingData) // tiling结构注册给算子 }
- 通过高阶API配套的tiling函数对tiling结构初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
static ge::graphStatus TilingFunc(gert::TilingContext* context) { int32_t M = 1024; int32_t N = 640; int32_t K = 256; int32_t baseM = 128; int32_t baseN = 128; auto ascendcPlatform = platform_ascendc::PlatformAscendC(context->GetPlatformInfo()); MultiCoreMatmulTiling cubeTiling(ascendcPlatform); cubeTiling.SetDim(2); cubeTiling.SetAType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16); cubeTiling.SetBType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT16); cubeTiling.SetCType(TPosition::LCM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT); cubeTiling.SetBiasType(TPosition::GM, CubeFormat::ND, matmul_tiling::DataType::DT_FLOAT); cubeTiling.SetShape(M, N, K); cubeTiling.SetOrgShape(M, N, K); cubeTiling.SetFixSplit(baseM, baseN, -1); cubeTiling.SetBias(true); cubeTiling.SetBufferSpace(-1, -1, -1); MyAddTilingData tiling; if (cubeTiling.GetTiling(tiling.cubeTilingData) == -1){ return ge::GRAPH_FAILED; } // some code }
使用标准C++语法定义TilingData
支持使用标准C++语法定义POD类型(Plain Old Data,即与C语言兼容的数据类型)的TilingData结构体。相比较使用BEGIN_TILING_DATA_DEF等宏进行定义的方式,该方式更符合开发者的开发习惯,并且提供了更大的灵活性。支持结构体数组、自定义TilingData赋值函数、同名结构体等特性。具体使用步骤如下:
- 使用C++语法定义TilingData结构体。
该结构体定义所在头文件需放置算子工程的op_kernel目录下。
1 2 3 4 5 6 7 8 9
#ifndef ADD_CUSTOM_TILING_H #define ADD_CUSTOM_TILING_H #include <cstdint> class TilingData{ public: uint32_t totalLength; uint32_t tileNum; }; #endif // ADD_CUSTOM_TILING_H
- Host侧tiling函数中对TilingData赋值。
- 需要包含TilingData定义头文件。
- 通过GetTilingData获取TilingData,并对其成员变量进行赋值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#include "../op_kernel/add_custom_tiling.h" // 包含TilingData定义头文件 namespace optiling { const uint32_t BLOCK_DIM = 8; const uint32_t TILE_NUM = 8; static ge::graphStatus TilingFunc(gert::TilingContext* context) { TilingData *tiling = context->GetTilingData<TilingData>(); // 获取TilingData结构体 uint32_t totalLength = context->GetInputTensor(0)->GetShapeSize(); context->SetBlockDim(BLOCK_DIM); tiling->totalLength = totalLength; // 赋值TilingData成员变量 tiling->tileNum = TILE_NUM; // 赋值TilingData成员变量 size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0; return ge::GRAPH_SUCCESS; } } // namespace optiling
- Kernel侧通过REGISTER_TILING_DEFAULT或者REGISTER_TILING_FOR_TILINGKEY注册TilingData结构体,解析tiling数据至TilingData结构并使用,其中REGISTER_TILING_DEFAULT同时也用于标识使用标准C++语法定义TilingData结构体。
注册TilingData结构体用于告知框架侧用户使用标准C++语法来定义TilingData,同时告知框架TilingData结构体类型,用于框架做tiling数据解析。
1 2 3 4 5 6 7 8 9 10
#include "kernel_operator.h" #include "add_custom_tiling.h" // 包含TilingData定义头文件 extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) { REGISTER_TILING_DEFAULT(TilingData); // 注册默认TilingData结构体 GET_TILING_DATA(tilingData, tiling); // kernel侧解析tiling数据,对TilingData结构赋值 KernelAdd op; op.Init(x, y, z, tilingData.totalLength, tilingData.tileNum); ...... }
使用标准C++语法定义TilingData时存在如下约束限制:
- TilingData成员变量不支持指针、引用类型,此类数据类型会导致host侧到device侧数据解析异常:
1 2 3 4 5
class TilingData { public: uint32_t* totalLength; // 指针场景不支持,Host无法传递指针到Device uint32_t& tileNum; // 引用场景不支持,Host无法传递指针到Device };
- TilingData结构体仅支持POD类型,没有虚函数、虚继承等面向对象特性,也不支持模板类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class A { public: uint32_t totalLength; uint32_t tileNum; }; class B: public A { public: uint32_t xxx; uint32_t xxx; }; static ge::graphStatus TilingFunc(gert::TilingContext* context) { // 错误用法 B *tiling = context->GetTilingData<A>(); // 不支持,会触发未知问题 // 正确用法 B *tiling = context->GetTilingData<B>(); ...... return ge::GRAPH_SUCCESS; }
- GetTilingData获取的TilingData不包含初值,需显示赋值或在TilingData类中定义并调用赋值函数;
1 2 3 4 5 6 7 8 9
static ge::graphStatus TilingFunc(gert::TilingContext* context) { TilingData *tiling = context->GetTilingData<TilingData>(); //获取TilingData结构体,此时totalLength、tileNum为0,并不会带入初始值 ...... // 需显示赋值 tiling->totalLength = totalLength; // 赋值TilingData成员变量 tiling->tileNum = TILE_NUM; // 赋值TilingData成员变量 ...... return ge::GRAPH_SUCCESS;
Tiling模板编程
在TilingKey编程章节介绍的TilingKey编程方式中,TilingKey不易于记忆和理解,因为它们通常是较长又没有明确含义的数字。
在涉及多个TilingKey的场景中,开发者依赖TilingKey来管理kernel的实现,无论是在管理还是使用上都会遇到相当大的复杂性。为了简化这一过程,可以采用模板编程的方法来替代传统的TilingKey编程,从而减少对TilingKey数值标识的依赖,使kernel的管理更加直观和高效。使用步骤如下:
- 在自定义算子工程的op_kernel目录下,新增定义模板参数和模板参数组合的头文件,本示例中头文件命名为tiling_key_add_custom.h。
- 该头文件中需要包含模板头文件ascendc/host_api/tiling/template_argument.h。
- 定义模板参数ASCENDC_TPL_ARGS_DECL和模板参数组合ASCENDC_TPL_ARGS_SEL(即可使用的模板)。具体API参考见模板参数定义。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35
#include "ascendc/host_api/tiling/template_argument.h" #define ADD_TPL_FP16 1 // 数据类型定义 #define ADD_TPL_FP32 0 #define ADD_TPL_ND 2 // 数据格式定义 #define ADD_TPL_NZ 29 // 模板参数 ASCENDC_TPL_ARGS_DECL(AddTemplateCustom, // 算子OpType ASCENDC_TPL_DTYPE_DECL(D_T_X, ADD_TPL_FP16, ADD_TPL_FP32), // DataType类型的模板参数定义:输入参数x的数据类型,取值范围为float16/float32 ASCENDC_TPL_DTYPE_DECL(D_T_Y, ADD_TPL_FP16, ADD_TPL_FP32), // DataType类型的模板参数定义:输入参数y的数据类型,取值范围为float16/float32 ASCENDC_TPL_DTYPE_DECL(D_T_Z, ADD_TPL_FP16, ADD_TPL_FP32), // DataType类型的模板参数定义:输入参数z的数据类型,取值范围为float16/float32 ASCENDC_TPL_UINT_DECL(TILE_NUM, ASCENDC_TPL_8_BW, ASCENDC_TPL_UI_MIX, 2, 0, 2, 3, 5, 10, 12, 13, 9, 8),// 自定义UINT类型(无符号整形)的模板参数定义:模板参数为切分的块数,编码位宽为ASCENDC_TPL_8_BW即8比特,表示该模板参数的个数不超过8比特能表达的范围;ASCENDC_TPL_UI_MIX表示通过混合模式表达取值范围,有2组的数据{0-2}、{3-5}和穷举值10、12、13、9、8,最后结果为{0, 1, 2, 3, 4, 5, 10, 12, 13, 9, 8} ASCENDC_TPL_BOOL_DECL(IS_SPLIT, 0, 1), // 自定义bool类型的模板参数定义:模板参数为是否切分标志位,取值范围为0和1,1表示切分,0表示不切分 ); // 模板参数组合 // 用于调用GET_TPL_TILING_KEY获取TilingKey时,接口内部校验TilingKey是否合法 ASCENDC_TPL_SEL( ASCENDC_TPL_ARGS_SEL( ASCENDC_TPL_DTYPE_SEL(D_T_X, ADD_TPL_FP16), ASCENDC_TPL_DTYPE_SEL(D_T_Y, ADD_TPL_FP16), ASCENDC_TPL_DTYPE_SEL(D_T_Z, ADD_TPL_FP16), ASCENDC_TPL_UINT_SEL(TILE_NUM, ASCENDC_TPL_UI_LIST, 1, 8), ASCENDC_TPL_BOOL_SEL(IS_SPLIT, 0, 1), ), ASCENDC_TPL_ARGS_SEL( ASCENDC_TPL_DTYPE_SEL(D_T_X, ADD_TPL_FP32), ASCENDC_TPL_DTYPE_SEL(D_T_Y, ADD_TPL_FP32), ASCENDC_TPL_DTYPE_SEL(D_T_Z, ADD_TPL_FP32), ASCENDC_TPL_UINT_SEL(TILE_NUM, ASCENDC_TPL_UI_LIST, 1, 8), ASCENDC_TPL_BOOL_SEL(IS_SPLIT, 0, 1), ), );
- host侧调用GET_TPL_TILING_KEY接口生成TilingKey。
- host实现文件中包含步骤1中定义模板参数和模板参数组合的头文件。
- 调用GET_TPL_TILING_KEY接口生成TilingKey,GET_TPL_TILING_KEY输入参数为模板参数的具体值,传入时需要与定义模板参数和模板参数组合的头文件中的模板参数顺序保持一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41
#include "tiling_key_add_custom.h" static ge::graphStatus TilingFunc(gert::TilingContext *context) { TilingData tiling; uint32_t totalLength = context->GetInputShape(0)->GetOriginShape().GetShapeSize(); ge::DataType dtype_x = context->GetInputDesc(0)->GetDataType(); ge::DataType dtype_y = context->GetInputDesc(1)->GetDataType(); ge::DataType dtype_z = context->GetOutputDesc(1)->GetDataType(); uint32_t D_T_X = ADD_TPL_FP32, D_T_Y=ADD_TPL_FP32, D_T_Z=ADD_TPL_FP32, TILE_NUM=1, IS_SPLIT=0; if(dtype_x == ge::DataType::DT_FLOAT){ D_T_X = ADD_TPL_FP32; }else if(dtype_x == ge::DataType::DT_FLOAT16){ D_T_X = ADD_TPL_FP16; } if(dtype_y == ge::DataType::DT_FLOAT){ D_T_Y = ADD_TPL_FP32; }else if(dtype_y == ge::DataType::DT_FLOAT16){ D_T_Y = ADD_TPL_FP16; } if(dtype_z == ge::DataType::DT_FLOAT){ D_T_Z = ADD_TPL_FP32; }else if(dtype_z == ge::DataType::DT_FLOAT16){ D_T_Z = ADD_TPL_FP16; } if(totalLength< MIN_LENGTH_FOR_SPLIT){ IS_SPLIT = 0; TILE_NUM = 1; }else{ IS_SPLIT = 1; TILE_NUM = DEFAULT_TILE_NUM; } context->SetBlockDim(BLOCK_DIM); tiling.set_totalLength(totalLength); tiling.SaveToBuffer(context->GetRawTilingData()->GetData(), context->GetRawTilingData()->GetCapacity()); context->GetRawTilingData()->SetDataSize(tiling.GetDataSize()); const uint64_t tilingKey = GET_TPL_TILING_KEY(D_T_X, D_T_Y, D_T_Z, TILE_NUM, IS_SPLIT); context->SetTilingKey(tilingKey); size_t *currentWorkspace = context->GetWorkspaceSizes(1); currentWorkspace[0] = 0; return ge::GRAPH_SUCCESS; }
- kernel侧实现
- host实现文件中包含步骤1中定义模板参数和模板参数组合的头文件。
- 核函数添加template模板,以便支持模板参数的传入,参数顺序需要与定义模板参数和模板参数组合的头文件中的模板参数顺序保持一致。
- 通过对模板参数的分支判断,选择不同的kernel侧实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
#include "tiling_key_add_custom.h" ... ... template<int D_T_X, int D_T_Y, int D_T_Z, int TILE_NUM, int IS_SPLIT> __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR workspace, GM_ADDR tiling) { GET_TILING_DATA(tiling_data, tiling); if(D_T_X == ADD_TPL_FP32 && D_T_Y == ADD_TPL_FP32 && D_T_Z == ADD_TPL_FP32){ KernelAdd<float, float, float> op; op.Init(x, y, z, tiling_data.totalLength, TILE_NUM, IS_SPLIT); op.Process1(); }else if(D_T_X == ADD_TPL_FP16 && D_T_Y == ADD_TPL_FP16 && D_T_Z == ADD_TPL_FP16){ KernelAdd<half, half, half> op; if(IS_SPLIT == 0){ op.Init(x, y, z, tiling_data.totalLength, TILE_NUM, IS_SPLIT); op.Process1(); }else if(IS_SPLIT==1){ op.Init(x, y, z, tiling_data.totalLength, TILE_NUM, IS_SPLIT); op.Process2(); } } }