生成的grafana dashboard中包含以下可视化图像:
可视化图像名称 |
描述 |
|---|---|
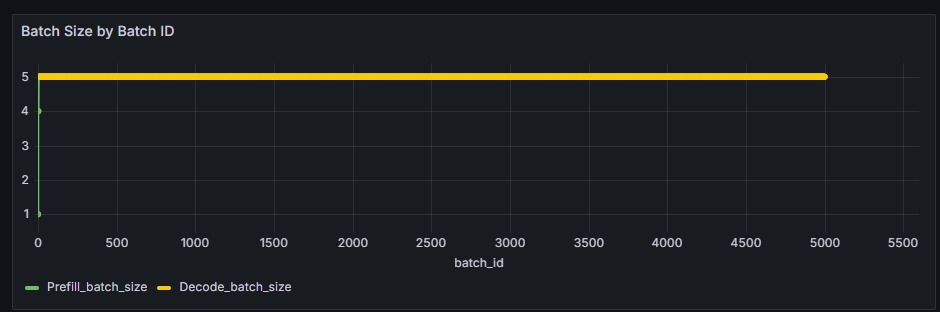
Batch Size by Batch ID |
记录BatchSchedule过程中每个batch包含的请求数量折线图。根据时间排序,区分Prefill和Decode。 |
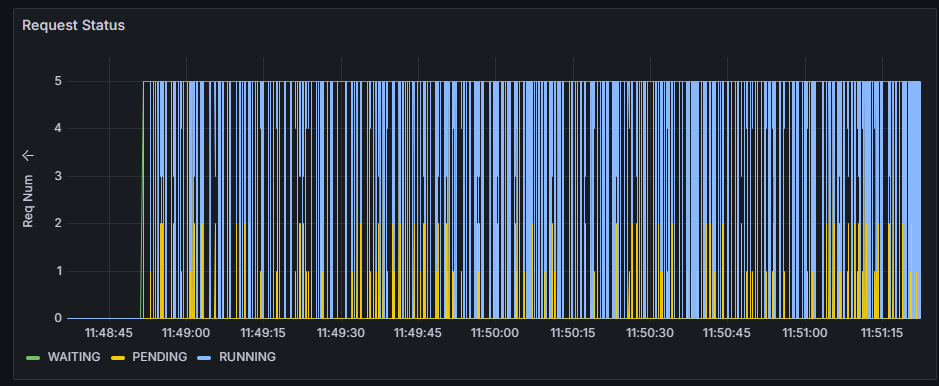
Request Status |
服务中处于不同状态下的请求数目随时间变化的折线图。 |
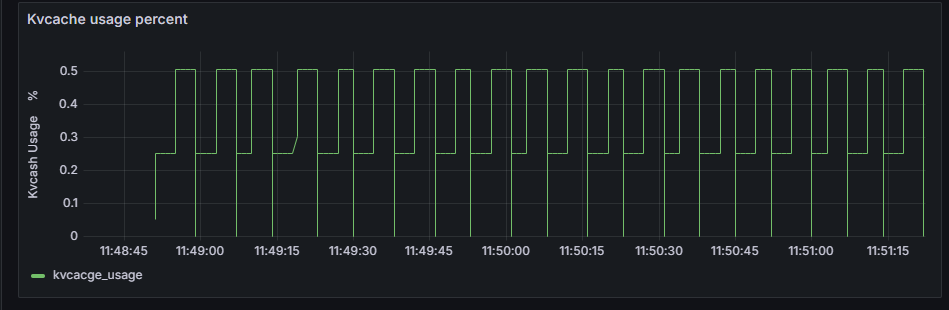
Kvcache usage percent |
所有请求Kvcache使用率随时间变换折线图。包含所有请求的Kvcache使用率情况。 |
first_token_latency |
所有请求首token时延随时间变化折线图。包含所有请求首token时延的平均值avg,分位值p99、p90、p50等。 |
prefill_generate_speed_latency |
所有请求Prefill阶段,不同时刻吞吐的token平均时延随时间变化折线图。包含所有请求不同时刻吞吐的token平均时延的平均值avg,分位值p99、p90、p50等。 |
decode_generate_speed_latency |
所有请求Decode阶段,不同时刻吞吐的token平均时延随时间变化折线图。包含所有请求不同时刻吞吐的token平均时延的平均值avg,分位值p99、p90、p50等。 |
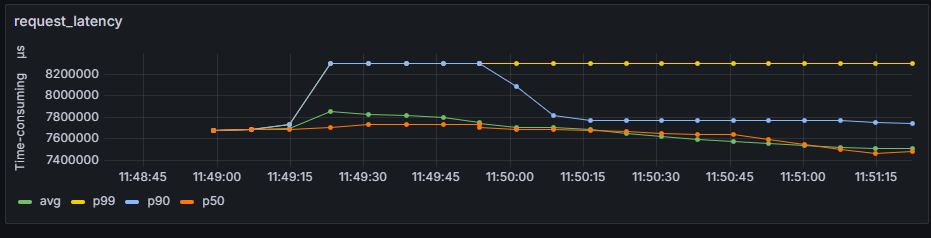
request_latency |
所有请求端到端时延随时间变化折线图。包含所有请求端到端时延的平均值avg,分位值p99、p90、p50等。 |
Batch Size by Batch ID
记录BatchSchedule过程中每个batch包含的请求数量折线图。
横轴:按执行时间顺序的第x个batch,从0开始。
纵轴:记录对应batch的batch size,区分Prefill batch和Decode batch。
Request Status
服务化过程中处于不同状态下的请求数目随时间变化的折线图。
横轴:服务化推理运行时间轴。
纵轴:当前时刻处于该状态的请求总数。
Kvcache usage percent
所有请求Kvcache使用率随时间变化折线图。
横轴:服务化推理运行时间轴。
纵轴:所有请求Kvcache使用率的变化情况。单位:百分率%。
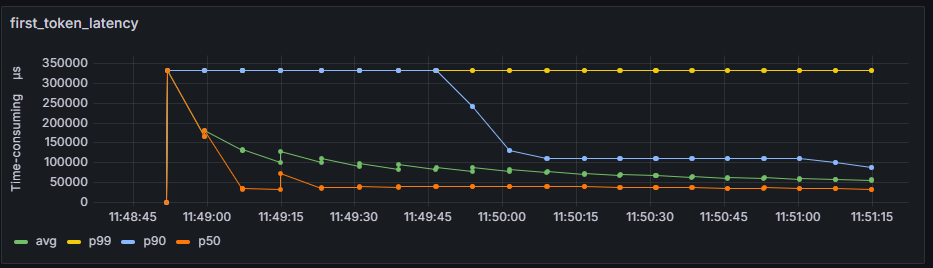
first_token_latency
所有请求token时延随时间变化折线图。
横轴:服务化推理运行时间轴。
纵轴:所有请求首token时延的平均值avg,分位值p99、p90、p50。单位:us。
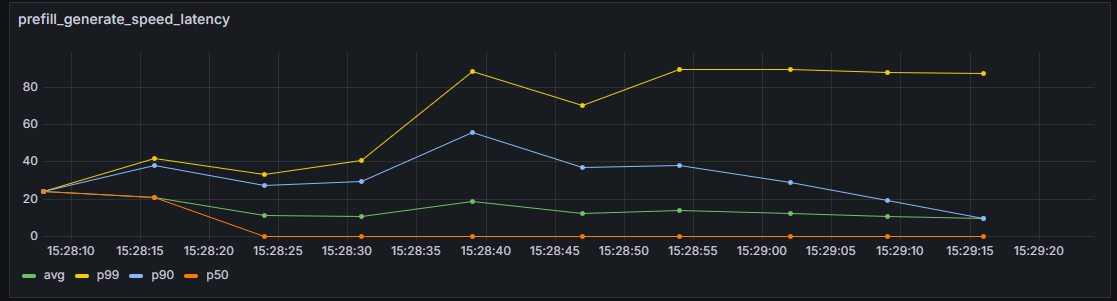
prefill_generate_speed_latency
所有请求Prefill阶段,不同时刻吞吐的token平均时延随时间变化折线图。
横轴:服务化推理运行时间轴。
纵轴:所有请求Prefill阶段不同时刻吞吐的token平均时延的平均值avg,分位值p99、p90、p50。单位:token个数/s。
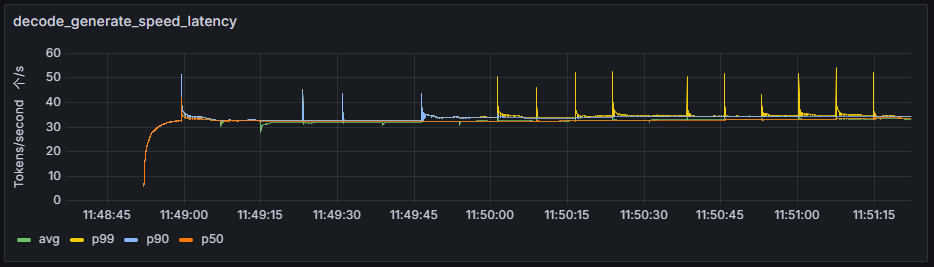
decode_generate_speed_latency
所有请求Decode阶段,不同时刻吞吐的token平均时延随时间变化折线图。
横轴:服务化推理运行时间轴。
纵轴:所有请求Decode阶段不同时刻吞吐的token平均时延的平均值avg,分位值p99、p90、p50。单位:token个数/s。
request_latency
所有请求端到端时延随时间变化折线图。
横轴:服务化推理运行时间轴。
纵轴:所有请求端到端时延的平均值avg,分位值p99、p90、p50。单位:us。