Ascend PyTorch Profiler是针对PyTorch框架开发的性能分析工具,通过在PyTorch训练/在线推理脚本中添加Ascend PyTorch Profiler接口,执行训练/在线推理的同时采集性能数据,完成训练/在线推理后直接输出可视化的性能数据文件,提升了性能分析效率。Ascend PyTorch Profiler接口可全面采集PyTorch训练/在线推理场景下的性能数据,主要包括PyTorch层算子信息、CANN层算子信息、底层NPU算子信息、以及算子内存占用信息等,可以全方位分析PyTorch训练/在线推理时的性能状态。
Ascend PyTorch Profiler接口工具当前支持如下性能数据采集方式:
其他相关功能:
参考信息:
- Ascend PyTorch Profiler接口说明
- profiler_config.json文件说明
- experimental_config参数说明(dynamic_profile动态采集场景)
- experimental_config参数说明
- torch_npu.profiler.schedule类参数说明
- dynamic_profile动态采集维测日志介绍
约束
Ascend PyTorch Profiler接口支持多种采集方式,各采集方式不可同时开启。
Ascend PyTorch Profiler接口进行采集任务时,进程与Device之间的关系如下:
- 多进程多Device场景:支持每个Device下分别设置一个采集进程。
- 单进程多Device场景:不支持。
- 多进程单Device场景:需要保证多进程之间的采集动作是串行的,即各个采集动作不在同一时间开始,且各个采集动作须包含完整的启动和停止。
前提条件
- 请确保完成使用前准备。
- 准备好基于PyTorch 2.1.0或更高版本开发的训练模型以及配套的数据集,并按照《PyTorch 训练模型迁移调优指南》中的“模型迁移”完成PyTorch原始模型向昇腾AI处理器的迁移。
采集并解析性能数据(torch_npu.profiler.profile)
- 在训练脚本(如train_*.py文件)/在线推理脚本内添加如下示例代码进行性能数据采集参数配置,之后启动训练/在线推理。如下示例代码。

- 以下示例代码中的torch_npu.profiler.profile接口详细介绍请参见Ascend PyTorch Profiler接口说明。
- 以下给出两个示例代码,使用不同方式调用torch_npu.profiler.profile接口,可任选其一使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
import torch import torch_npu ... experimental_config = torch_npu.profiler._ExperimentalConfig( export_type=[ torch_npu.profiler.ExportType.Text, torch_npu.profiler.ExportType.Db ], profiler_level=torch_npu.profiler.ProfilerLevel.Level0, msprof_tx=False, aic_metrics=torch_npu.profiler.AiCMetrics.AiCoreNone, l2_cache=False, op_attr=False, data_simplification=False, record_op_args=False, gc_detect_threshold=None ) with torch_npu.profiler.profile( activities=[ torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU ], schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=1), on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"), record_shapes=False, profile_memory=False, with_stack=False, with_modules=False, with_flops=False, experimental_config=experimental_config) as prof: for step in range(steps): train_one_step(step, steps, train_loader, model, optimizer, criterion) prof.step()
或
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
import torch import torch_npu ... experimental_config = torch_npu.profiler._ExperimentalConfig( export_type=[ torch_npu.profiler.ExportType.Text, torch_npu.profiler.ExportType.Db ], profiler_level=torch_npu.profiler.ProfilerLevel.Level0, msprof_tx=False, aic_metrics=torch_npu.profiler.AiCMetrics.AiCoreNone, l2_cache=False, op_attr=False, data_simplification=False, record_op_args=False, gc_detect_threshold=None ) prof = torch_npu.profiler.profile( activities=[ torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU ], schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=1), on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"), record_shapes=False, profile_memory=False, with_stack=False, with_modules=False, with_flops=False, experimental_config=experimental_config) prof.start() for step in range(steps): train_one_step() prof.step() prof.stop()
以上两个示例主要使用tensorboard_trace_handler导出性能数据,也可以使用以下prof.export_chrome_trace方式导出:1 2 3 4 5 6 7 8 9
import torch import torch_npu ... with torch_npu.profiler.profile() as prof: for step in range(steps): train_one_step(step, steps, train_loader, model, optimizer, criterion) prof.export_chrome_trace('./chrome_trace_14.json')
- 性能数据解析。
支持自动解析(参照以上示例代码中tensorboard_trace_handler和prof.export_chrome_trace)和离线解析。
- 查看性能数据结果文件和性能数据分析。
性能数据结果文件详细介绍请参见数据目录说明,性能数据分析请参见《MindStudio Insight 用户指南》将解析后的性能数据文件进行可视化展示和分析。
采集并解析性能数据(dynamic_profile)
dynamic_profile动态采集,主要功能是在执行模型训练/在线推理过程中可以随时开启采集进程。
以下方式只选择一种使用,不可同时使用两种及以上方式开启dynamic_profile。
环境变量方式
- 配置如下环境变量:
export PROF_CONFIG_PATH="profiler_config_path"
配置该环境变量后启动训练,dynamic_profile会在profiler_config_path下自动创建模板文件profiler_config.json,用户可基于模板文件自定义修改配置项。
- 该方式仅支持训练场景。
- 该方式下dynamic_profile不支持采集第一个迭代(step0)的数据。
- 该方式依赖torch原生Optimizer.step()划分训练过程中Profiling的step,不支持自定义Optimizer场景。
- profiler_config_path路径格式仅支持由字母、数字和下划线组成的字符串,不支持软链接。
- 启动训练任务。
- 重新开启一个命令行窗口,修改profiler_config.json配置文件用以使能Profiling任务。配置文件中包含Profiler的性能数据采集参数,用户可以参考profiler_config.json文件说明修改配置文件参数来执行不同的Profiling任务。
- dynamic_profile通过识别profiler_config.json文件的状态判断文件是否被修改:
- dynamic_profile每2s轮询一次,若发现profiler_config.json文件改动,则启动采集流程,之后记录step10到step11之间的运行间隔,将此时间作为新的轮询时间,最小值为1s。
- 若在dynamic_profile采集执行期间,profiler_config.json文件被修改,则在采集进程结束之后,再次启动最后一次文件修改的dynamic_profile采集。
- 建议用户使用共享存储设置dynamic_profile的profiler_config_path。
- profiler_config_path目录下会自动记录dynamic_profile的维测日志,详细介绍请参见dynamic_profile动态采集维测日志介绍。
- dynamic_profile通过识别profiler_config.json文件的状态判断文件是否被修改:
- 性能数据解析。
支持自动解析和手动解析,请参见表5中的analyse参数。
- 查看性能数据结果文件和性能数据分析。
性能数据结果文件详细介绍请参见数据目录说明,性能数据分析请参见《MindStudio Insight 用户指南》将解析后的性能数据文件进行可视化展示和分析。
msMonitor nputrace方式
支持使用msMonitor(基于Dynolog开发)进行非侵入式采集NPU环境的性能数据,当启动msMonitor时,进程通过拉起dynamic_profile进程,获取Dynolog的采集指令与dynamic_profile进行交互,采集和解析流程与“环境变量方式”一致。
export KINETO_USE_DAEMON=1
msMonitor具体实现与使用详细介绍请参见msMonitor: MindStudio一站式在线监控工具。
修改用户训练/在线推理脚本,添加dynamic_profile接口方式
- 在训练脚本(如train_*.py文件)/在线推理脚本中添加如下示例代码:
1 2 3 4 5 6 7 8 9
# 加载dynamic_profile模块 from torch_npu.profiler import dynamic_profile as dp # 设置Profiling配置文件的路径 dp.init("profiler_config_path") … for step in steps: train_one_step() # 划分step dp.step()
init时,dynamic_profile会在profiler_config_path下自动创建模板文件profiler_config.json,用户可基于模板文件自定义修改配置项。
profiler_config_path路径格式仅支持由字母、数字和下划线组成的字符串,不支持软链接。
- 启动训练/在线推理任务。
- 重新开启一个命令行窗口,修改profiler_config.json配置文件用以使能Profiling任务。配置文件中包含Profiler的性能数据采集参数,用户可以参考profiler_config.json文件说明修改配置文件参数来执行不同的Profiling任务。
- dynamic_profile通过识别profiler_config.json文件的状态判断文件是否被修改:
- dynamic_profile每2s轮询一次,若发现profiler_config.json文件改动,则启动采集流程,之后记录step10到step11之间的运行间隔,将此时间作为新的轮询时间,最小值为1s。
- 若在dynamic_profile采集执行期间,profiler_config.json文件被修改,则在采集进程结束之后,再次启动最后一次文件修改的dynamic_profile采集。
- 建议用户使用共享存储设置dynamic_profile的profiler_config_path。
- profiler_config_path目录下会自动记录dynamic_profile的维测日志,详细介绍请参见dynamic_profile动态采集维测日志介绍。
- dynamic_profile通过识别profiler_config.json文件的状态判断文件是否被修改:
- 性能数据解析。
支持自动解析和手动解析,请参见表5中的analyse参数。
- 查看性能数据结果文件和性能数据分析。
性能数据结果文件详细介绍请参见数据目录说明,性能数据分析请参见《MindStudio Insight 用户指南》将解析后的性能数据文件进行可视化展示和分析。
修改用户训练/在线推理脚本,添加dynamic_profile的dp.start()函数方式
- 在训练脚本(如train_*.py文件)/在线推理脚本中添加如下示例代码:
1 2 3 4 5 6 7 8 9 10 11 12
# 加载dynamic_profile模块 from torch_npu.profiler import dynamic_profile as dp # 设置init接口Profiling配置文件路径 dp.init("profiler_config_path") … for step in steps: if step==5: # 设置start接口Profiling配置文件路径 dp.start("start_config_path") train_one_step() # 划分step,需要进行profile的代码需在dp.start()接口和dp.step()接口之间 dp.step()
start_config_path同样指定为profiler_config.json,但需要用户根据profiler_config.json文件说明手动创建配置文件并根据场景需要配置参数。此处须指定具体文件名,例如dp.start("/home/xx/start_config_path/profiler_config.json")。
profiler_config_path和start_config_path路径格式仅支持由字母、数字和下划线组成的字符串,不支持软链接。
- 添加dp.start()后,当训练/在线推理任务进行到dp.start()时,会自动按照start_config_path指定的profiler_config.json文件进行采集。dp.start()函数不感知profiler_config.json文件的修改,只会在训练/在线推理过程中触发一次采集任务。
- 添加dp.start()并启动训练/在线推理后:
- 若dp.start()未指定profiler_config.json配置文件或配置文件因错误未生效,则执行到dp.start()后按照profiler_config_path目录下的profiler_config.json文件配置进行采集。
- 若在dp.init()配置的dynamic_profile生效期间,脚本运行至dp.start(),则dp.start()不生效。
- 若在dp.init()配置的dynamic_profile采集结束后,脚本运行至dp.start(),则继续执行dp.start()采集,并在prof_dir目录下生成新的性能数据文件目录。
- 若在dp.start()配置的dynamic_profile生效期间,改动profiler_config_path目录下的profiler_config.json文件,dp.init()会等待dp.start()采集完成后启动,并在prof_dir目录下生成新的性能数据文件目录。
- 建议用户使用共享存储设置dynamic_profile的profiler_config_path。
- 启动训练/在线推理任务。
- 性能数据解析。
支持自动解析和手动解析,请参见表5中的analyse参数。
- 查看性能数据结果文件和性能数据分析。
性能数据结果文件详细介绍请参见数据目录说明,性能数据分析请参见《MindStudio Insight 用户指南》将解析后的性能数据文件进行可视化展示和分析。
采集并解析性能数据(torch_npu.profiler._KinetoProfile)
- 在训练脚本(如train_*.py文件)/在线推理脚本内添加如下示例代码进行性能数据采集参数配置,之后启动训练/在线推理。如下示例代码。
1 2 3 4 5 6 7 8 9 10 11 12 13
import torch import torch_npu ... prof = torch_npu.profiler._KinetoProfile(activities=None, record_shapes=False, profile_memory=False, with_stack=False, with_flops=False, with_modules=False, experimental_config=None) for epoch in range(epochs): train_model_step() if epoch == 0: prof.start() if epoch == 1: prof.stop() prof.export_chrome_trace("result_dir/trace.json")
该方式不支持使用schedule和tensorboard_trace_handler导出性能数据。
- 性能数据解析。
支持自动解析(参照以上示例代码中prof.export_chrome_trace)。
- 查看性能数据结果文件和性能数据分析。
性能数据结果文件详细介绍请参见数据目录说明,性能数据分析请参见《MindStudio Insight 用户指南》将解析后的性能数据文件进行可视化展示和分析。
采集并解析msprof_tx数据(可选)
针对大集群场景传统Profiling数据量大、分析流程复杂的现象,通过experimental_config的msprof_tx参数开启自定义打点功能,自定义采集时间段或者关键函数的开始和结束时间点,识别关键函数或迭代等信息,对性能问题快速定界。
使用方式及示例代码如下:
- 使能torch_npu.profiler,打开msprof_tx开关,搭配profiler_level开关设置为Level_none(可根据实际采集需要,配置对应的level),采集打点数据。
- 在PyTorch脚本中对于想采集的事件调用torch_npu.npu.mstx、torch_npu.npu.mstx.mark、torch_npu.npu.mstx.range_start、torch_npu.npu.mstx.range_end、torch_npu.npu.mstx.mstx_range的打点mark接口实现打点,采集对应事件的耗时。接口详细介绍请参见《Ascend Extension for PyTorch API参考》中的“Ascend Extension for PyTorch自定义API > torch_npu.npu > profiler”。
只记录Host侧range耗时:
1 2 3 | id = torch_npu.npu.mstx.range_start("dataloader", None) # 第二个入参设置None或者不设置,只记录Host侧range耗时 dataloader() torch_npu.npu.mstx.range_end(id) |
在计算流上打点,记录Host侧range耗时和Device侧对应的range耗时:
1 2 3 4 | stream = torch_npu.npu.current_stream() id = torch_npu.npu.mstx.range_start("matmul", stream) # 第二个入参设置有效的stream,记录Host侧range耗时和Device侧对应的range耗时 torch.matmul() torch_npu.npu.mstx.range_end(id) |
在集合通信流上打点:
1 2 3 4 5 6 7 8 9 10 11 12 13 | from torch.distributed.distributed_c10d import _world if (torch.__version__ != '1.11.0') : stream_id = _world.default_pg._get_backend(torch.device('npu'))._get_stream_id(False) collective_stream = torch.npu.Stream(stream_id=collective_stream_id, device_type=20, device_index=device_id) # device_index设置实际业务的device_id值 else: stream_id = _world.default_pg._get_stream_id(False) current_stream = torch.npu.current_stream() cdata = current_stream._cdata & 0xffff000000000000 collective_stream = torch.npu.Stream(_cdata=( stream_id + cdata), device_index=device_id) # device_index设置实际业务的device_id值 id = torch_npu.npu.mstx.range_start("allreduce", collective_stream) # 第二个入参设置有效的stream,记录Host侧range耗时和Device侧对应的range耗时 torch.allreduce() torch_npu.npu.mstx.range_end(id) |
在P2P通信流上打点:
1 2 3 4 5 6 7 8 9 10 11 12 13 | from torch.distributed.distributed_c10d import _world if (torch.__version__ != '1.11.0') : stream_id = _world.default_pg._get_backend(torch.device('npu'))._get_stream_id(True) p2p_stream = torch.npu.Stream(stream_id=collective_stream_id, device_type=20, device_index=device_id) # device_index设置实际业务的device_id值 else: stream_id = _world.default_pg._get_stream_id(True) current_stream = torch.npu.current_stream() cdata = current_stream._cdata & 0xffff000000000000 p2p_stream = torch.npu.Stream(_cdata=( stream_id + cdata), device_index=device_id) # device_index设置实际业务的device_id值 id = torch_npu.npu.mstx.range_start("send", p2p_stream) # 第二个入参设置有效的stream,记录Host侧range耗时和Device侧对应的range耗时 torch.send() torch_npu.npu.mstx.range_end(id) |
想要采集如上场景数据,需要配置torch_npu.profiler.profile接口,使能msprof_tx开关,参考样例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import torch_npu stream = torch_npu.npu.current_stream() id = torch_npu.npu.mstx.range_start("Func", stream) # 标识func函数在Host侧以及在Device侧的range开始 func() # 业务代码 torch_npu.npu.mstx.range_end(id) # 标识func函数在Host侧以及在Device侧的range结束 experimental_config = torch_npu.profiler._ExperimentalConfig( profiler_level=torch_npu.profiler.ProfilerLevel.Level_none, msprof_tx=True, export_type=[ torch_npu.profiler.ExportType.Db ], with torch_npu.profiler.profile( schedule=torch_npu.profiler.schedule(wait=1, warmup=1, active=2, repeat=2, skip_first=1), on_trace_ready=torch_npu.profiler.tensorboard_trace_handler("./result"), experimental_config=experimental_config) as prof: for epoch in range(epochs): torch_npu.npu.mstx.mark("train epoch start") # 标识在Host侧以及在Device侧的瞬时时刻,也可以使用torch_npu.npu.mstx().mark("train epoch start") for step in range(steps): train_one_step(step, steps, train_loader, model, optimizer, criterion) prof.step() |
打点数据使用MindStudio Insight工具打开,可视化效果如下:
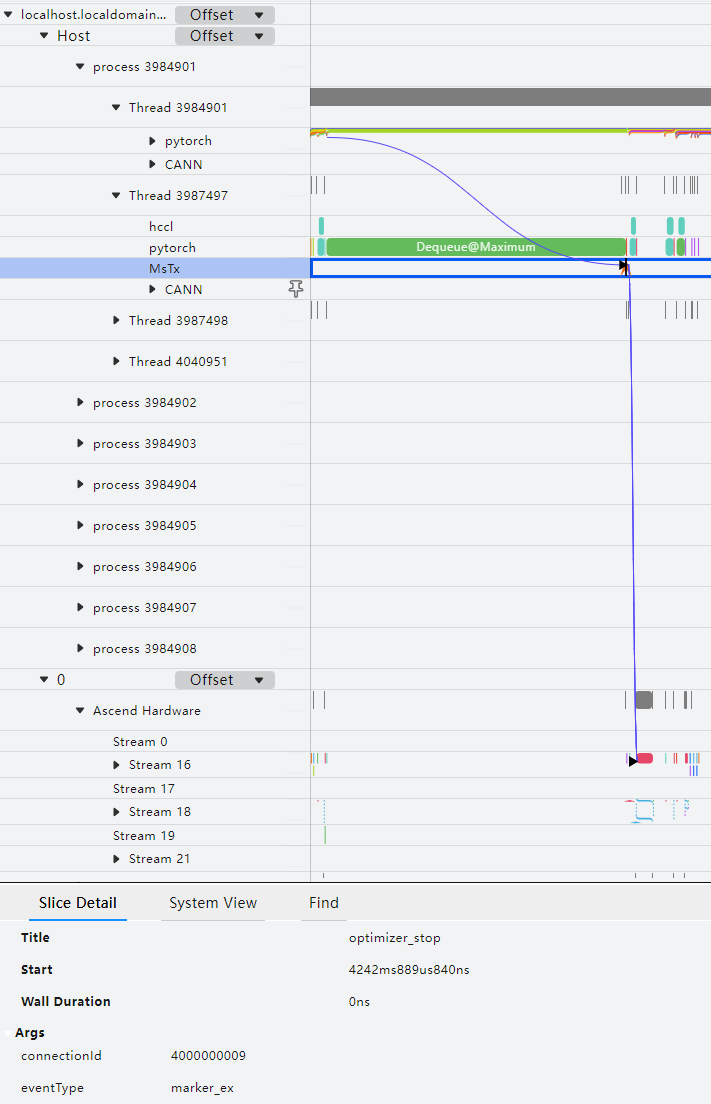
msprof_tx功能默认采集通信算子、Dataloader耗时、保存检查点接口耗时的性能数据,数据内容格式分别为:
- 格式:{"streamId": "{pg streamId}","count": "{count}","dataType": "{dataType}",["srcRank": "{srcRank}"],["destRank": "{destRank}"],"groupName": "{groupName}","opName": "{opName}"}
示例:{"streamId": "32","count": "25701386","dataType": "fp16","groupName": "group_name_43","opName": "HcclAllreduce"}
- streamId:用于执行打点任务的Stream ID。
- count:输入数据个数。
- dataType:输入数据的数据类型。
- srcRank:通信域内数据发送端的Rank ID,hcclRecv算子才有srcRank。
- destRank:通信域内数据接收端的Rank ID,hcclSend算子才有destRank。
- groupName:通信域名称。
- opName:算子名称。
- dataloader
- save_checkpoint
此外,msprof_tx功能还可以通过mstx_torch_plugin获取PyTorch模型中的dataloader、forward、step、save_checkpoint这四个关键阶段的性能数据,详细介绍请参见《mstx_torch_plugin》。
可以通过该功能查看用户自定义打点从框架侧到CANN层再到NPU侧的执行调度情况,进而帮助识别用户想观察的关键函数或者事件,定界性能问题。
msprof_tx采集结果数据详细介绍请参见msproftx数据说明。
采集环境变量信息(可选)
通过Ascend PyTorch Profiler接口采集性能数据时,默认采集环境变量信息,当前支持采集的环境变量如下:
- "ASCEND_GLOBAL_LOG_LEVEL"
- "HCCL_RDMA_TC"
- "HCCL_RDMA_SL"
- "ACLNN_CACHE_LIMIT"
操作步骤:
- 在环境下配置环境变量,示例如下:
export ASCEND_GLOBAL_LOG_LEVEL=1 export HCCL_RDMA_TC=0 export HCCL_RDMA_SL=0 export ACLNN_CACHE_LIMIT=4096
环境变量根据用户实际需要配置。
- 执行Ascend PyTorch Profiler接口采集。
- 查看结果数据。
- 当experimental_config参数的export_type配置为torch_npu.profiler.ExportType.Text时,以上步骤配置的环境变量信息将保存在{worker_name}_{时间戳}_ascend_pt目录下的profiler_metadata.json文件中。
- 当experimental_config参数的export_type配置为torch_npu.profiler.ExportType.Db时,在ascend_pytorch_profiler_{rank_id}.db文件下的META_DATA表写入环境变量信息。
以自定义字符串键和字符串值的形式标记性能数据采集过程(可选)
- 示例一
1 2
with torch_npu.profiler.profile(...) as prof: prof.add_metadata(key, value)
- 示例二
1 2
with torch_npu.profiler._KinetoProfile(...) as prof: prof.add_metadata_json(key, value)
add_metadata和add_metadata_json可以配置在torch_npu.profiler.profile和torch_npu.profiler._KinetoProfile下,须添加在profiler初始化后,finalize之前,即性能数据采集过程的代码中。
类、函数名 |
说明 |
||
|---|---|---|---|
add_metadata |
添加字符串标记,可取值:
示例:
|
||
add_metadata_json |
添加json格式字符串标记,可取值:
示例:
|
调用此接口传入的metadata数据写入到Ascend PyTorch Profiler接口的采集结果根目录下的profiler_metadata.json文件中。
显存可视化(可选)
本功能实现在模型训练过程中训练进程占用存储空间时,对所占用的数据进行分类并可视化展示。主要通过export_memory_timeline导出可视化文件memory_timeline.html。输出html文件需要先在Python环境中安装matplotlib,且将对应的torch_npu.profiler.profile参数设置设为True,另外使用该功能会在当前目录下生成后缀为ascend_pt数据文件。操作示例如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | import torch import torch_npu ... def trace_handler(prof: torch_npu.profiler.profile): prof.export_memory_timeline(output_path="./memory_timeline.html", device="npu:0") with torch_npu.profiler.profile( activities=[ torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU ], schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=4, repeat=1, skip_first=0), on_trace_ready=trace_handler, record_shapes=True, # 设为True profile_memory=True, # 设为True with_stack=True, # with_stack或者with_modules其中一个设为True with_modules=True ) as prof: for _ in range(steps): ... prof.step() |
执行采集并导出memory_timeline.html后,可视化效果如下:
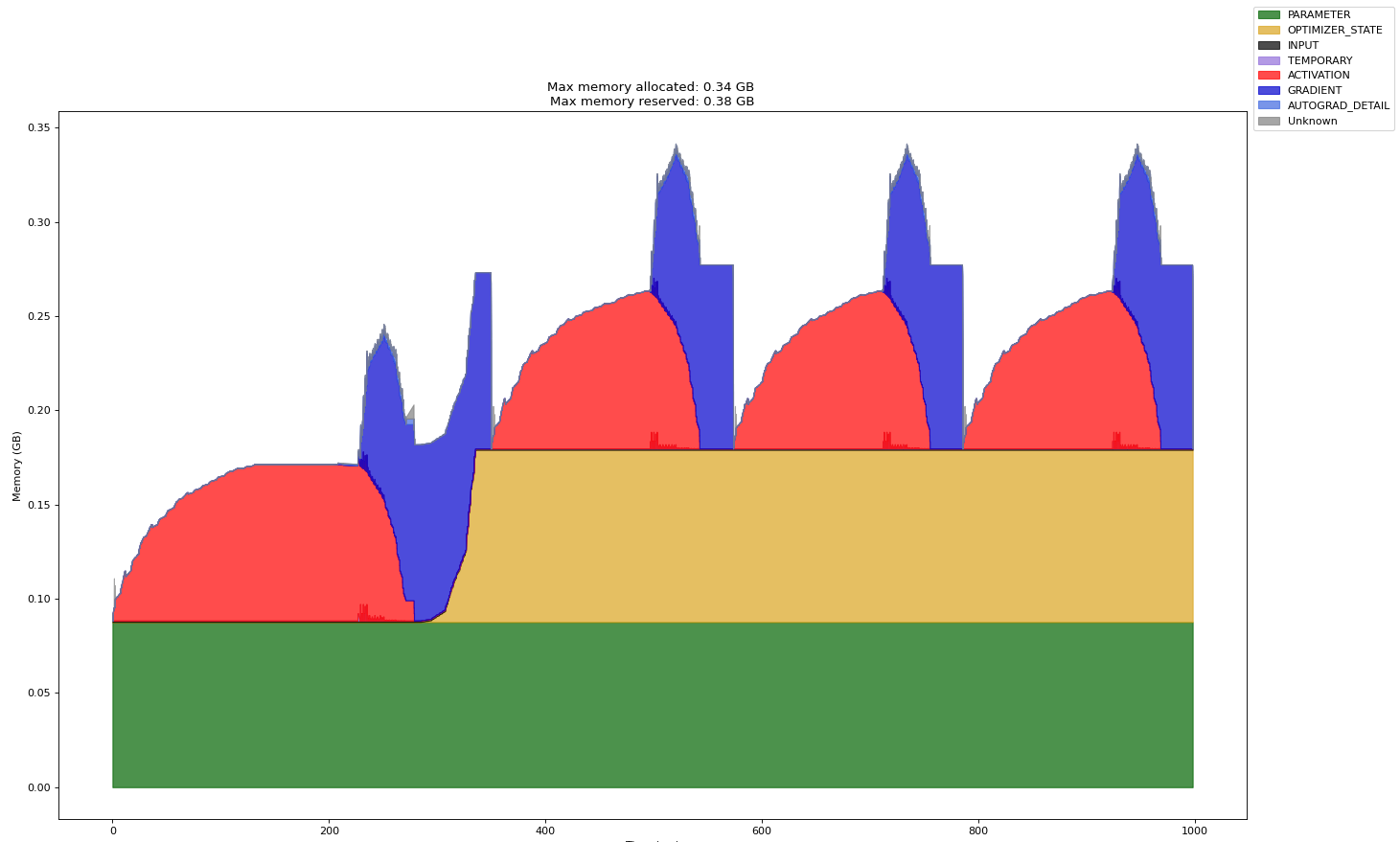
- Time(ms):为横坐标,表示tensor类型对内存的占用时间,单位ms。
- Memory(GB):为纵坐标,表示tensor类型占用的内存大小,单位GB。
- Max memory allocated:最大内存分配总额,单位GB。
- Max memory reserved:最大内存预留总额,单位GB。
- PARAMETER:模型参数、模型权重。
- OPTIMIZER_STATE:优化器状态,例如Adam优化器会记录模型训练过程中的一些状态。
- INPUT:输入数据。
- TEMPORARY:临时占用,这里被定义为单个算子下申请后又被释放,通常是一些保存中间值的tensor。
- ACTIVATION:前向计算中得到的激活值。
- GRADIENT:梯度值。
- AUTOGRAD_DETAIL:反向计算过程中产生的内存占用。
- UNKNOWN:未知类型。
Ascend PyTorch Profiler接口说明
参数名称 |
说明 |
是否必选 |
|---|---|---|
activities |
CPU、NPU事件采集列表,Enum类型。取值为:
默认情况下两个开关同时开启。 |
否 |
schedule |
设置不同step的行为,Callable类型,由schedule类控制。默认不执行任何操作。 torch_npu.profiler._KinetoProfile不支持该参数。 |
否 |
on_trace_ready |
采集结束时自动执行操作,Callable类型。当前支持执行tensorboard_trace_handler函数操作。当采集的数据量过大时,在当前环境下不适合直接解析性能数据,或者采集过程中中断了训练/在线推理进程,只采集了部分性能数据,可以采用离线解析。 默认不执行任何操作。 torch_npu.profiler._KinetoProfile不支持该参数。 说明:
对于使用共享存储的多卡大集群场景,直接使用on_trace_ready执行tensorboard_trace_handler函数的方式进行性能数据落盘,可能因多卡数据直接落盘到共享存储导致性能膨胀的问题。解决方式请参见PyTorch多卡大集群场景如何避免性能数据直接落盘到共享存储时导致的性能膨胀问题。 |
否 |
record_shapes |
算子的InputShapes和InputTypes,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 |
否 |
profile_memory |
算子的内存占用情况,Bool类型。取值为:
说明:
已知在安装有glibc<2.34的环境上采集memory数据,可能触发glibc的一个已知Bug 19329,通过升级环境的glibc版本可解决此问题。 |
否 |
with_stack |
算子调用栈,Bool类型。包括框架层及CPU算子层的调用信息。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 说明:
开启该配置后会引入额外的性能膨胀。 |
否 |
with_modules |
modules层级的Python调用栈,即框架层的调用信息,Bool类型。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 说明:
开启该配置后会引入额外的性能膨胀。 |
否 |
with_flops |
算子浮点操作,Bool类型(该参数暂不支持解析性能数据)。取值为:
开启torch_npu.profiler.ProfilerActivity.CPU时生效。 |
否 |
experimental_config |
扩展参数,通过扩展配置性能分析工具常用的采集项。支持采集项和详细介绍请参见experimental_config参数说明。 |
否 |
use_cuda |
昇腾环境不支持。开启采集cuda性能数据开关,Bool类型。取值为:
torch_npu.profiler._KinetoProfile不支持该参数。 |
否 |
方法名 |
说明 |
||
|---|---|---|---|
step |
划分不同迭代。 torch_npu.profiler._KinetoProfile不支持该方法。 |
||
export_chrome_trace |
导出trace。在指定的.json文件里写入trace数据。Trace为Ascend PyTorch Profiler接口整合框架侧CANN软件栈及NPU数据后展示的各算子和接口的运行时间及关联关系。包含参数:
在设置了torch_npu.profiler.tensorboard_trace_handler的情况下,export_chrome_trace不生效。 多卡场景下需要将不同卡设置不同的文件名,示例代码:
|
||
export_stacks |
导出堆栈信息到文件。包含参数:
与export_chrome_trace方法在训练/在线推理脚本中的位置相同,示例如下:
导出的结果文件可使用FlameGraph工具进行查看,操作方法如下: git clone https://github.com/brendangregg/FlameGraph cd FlameGraph ./flamegraph.pl –title "NPU time" –countname "us." profiler.stacks > perf_viz.svg |
||
从采集的数据中导出给定设备的内存事件信息,并导出时间线图。使用 export_memory_timeline可以导出3个文件,每个文件都由output_path的后缀控制:
参数:
配置示例:
详细操作指导请参见显存可视化(可选)。 |
|||
start |
设置采集开始的位置。可参考如下样例,在需要采集性能数据的训练/在线推理代码前后添加start和stop:
|
||
stop |
设置采集结束的位置,需要先执行start。 |
类、函数名 |
说明 |
|---|---|
torch_npu.profiler.schedule |
设置不同step的行为,默认不执行该操作。为了获取更稳定的性能数据,建议配置该类的具体参数,参数取值及详细用法请参见torch_npu.profiler.schedule类参数说明。 |
导出性能数据。取值为:
torch_npu.profiler._KinetoProfile不支持该函数。 解析过程日志存放在{worker_name}_{时间戳}_ascend_pt/logs目录下。 |
|
torch_npu.profiler.ProfilerAction |
Profiler状态,Enum类型。取值为:
|
torch_npu.profiler._ExperimentalConfig |
性能数据采集扩展,Enum类型。通过torch_npu.profiler.profile的experimental_config调用,详细介绍请参见experimental_config参数说明。 |
torch_npu.profiler.supported_activities |
查询当前支持采集的activities参数的CPU、NPU事件。 |
torch_npu.profiler.supported_profiler_level |
查询当前支持的experimental_config参数的profiler_level级别。 |
torch_npu.profiler.supported_ai_core_metrics |
查询当前支持的experimental_config参数的AI Core性能指标采集项。 |
torch_npu.profiler.supported_export_type |
查询当前支持的torch_npu.profiler.ExportType的性能数据结果文件类型。 |
性能数据会占据一定的磁盘空间,可能存在磁盘写满导致服务器不可用的风险。性能数据所需空间跟模型的参数、采集开关配置、采集的迭代数量有较大关系,须用户自行保证落盘目录下的可用磁盘空间。
profiler_config.json文件说明
profiler_config.json文件内容如下,以默认配置为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | { "activities": ["CPU", "NPU"], "prof_dir": "./", "analyse": false, "record_shapes": false, "profile_memory": false, "with_stack": false, "with_flops": false, "with_modules": false, "active": 1, "warmup": 0, "start_step": 0, "is_rank": false, "rank_list": [], "experimental_config": { "profiler_level": "Level0", "aic_metrics": "AiCoreNone", "l2_cache": false, "op_attr": false, "gc_detect_threshold": null, "data_simplification": true, "record_op_args": false, "export_type": "text", "msprof_tx": false } } |
参数 |
说明 |
是否必选 |
||
|---|---|---|---|---|
start_step |
设置开始采集的step,默认值为0(即不采集),须配置正整数才有效。启动采集进程首先需要配置该参数为有效值。 |
是 |
||
activities |
CPU、NPU事件采集列表。取值为:
默认情况下两个开关同时开启。 |
否 |
||
prof_dir |
采集到的性能数据的存放路径。默认路径为:./。路径格式仅支持由字母、数字和下划线组成的字符串,不支持软链接。 |
否 |
||
analyse |
性能数据自动解析开关,可取值:
|
否 |
||
record_shapes |
算子的InputShapes和InputTypes。取值为:
activities配置为CPU时生效。 |
否 |
||
profile_memory |
算子的内存占用情况。取值为:
说明:
已知在安装有glibc<2.34的环境上采集memory数据,可能触发glibc的一个已知Bug 19329,通过升级环境的glibc版本可解决此问题。 |
否 |
||
with_stack |
算子调用栈。包括框架层及CPU算子层的调用信息。取值为:
activities配置为CPU时生效。 |
否 |
||
with_flops |
算子浮点操作,Bool类型(该参数暂不支持解析性能数据)。取值为:
activities配置为CPU时生效。 |
否 |
||
with_modules |
modules层级的Python调用栈,即框架层的调用信息。取值为:
activities配置为CPU时生效。 |
否 |
||
is_rank |
开启指定Rank采集功能。取值为:
开启后,dynamic_profile会识别rank_list参数中配置的Rank ID,根据配置的Rank ID识别环境中存在的对应Rank执行采集操作;若开启后rank_list配置为空则不采集性能数据。 开启后,analyse自动解析不生效,需要使用离线解析。 |
否 |
||
rank_list |
配置采集的Rank ID,取值为整数,默认值为空,表示不采集任何性能数据。须配置为环境中有效的Rank ID。可同时指定一个或多个Rank,配置示例:"rank_list": [1,2,3]。 |
否 |
||
async_mode |
控制是否开启异步解析(表示解析进程不会阻塞AI任务主流程),bool类型。可取值True(开启异步解析)、False(关闭异步解析,即同步解析,默认值)。 |
否 |
||
experimental_config |
扩展参数,通过扩展配置性能分析工具常用的采集项。详见experimental_config参数说明(dynamic_profile动态采集场景)。 对于动态采集场景,该配置文件中配置的experimental_config的子参数选项取实际参数值即可,例如"aic_metrics": "PipeUtilization"。 |
否 |
||
metadata |
采集模型超参数(key)和配置信息(value)。
配置示例:
|
否 |
||
active |
配置采集的迭代数,取值为正整数,默认值为1。 |
否 |
||
warmup |
预热的step轮数,默认值为0,建议设置1轮预热。 |
否 |
experimental_config参数说明(dynamic_profile动态采集场景)
experimental_config参数均为可选参数,支持扩展的采集项如下:
参数 |
说明 |
|---|---|
export_type |
设置导出的性能数据结果文件格式,List类型。可取值:
设置无效值或未配置均取默认值Text。两个参数可同时配置,表示同时导出timeline、summary和db文件。 解析结果数据请参见Ascend PyTorch Profiler接口采集数据。 |
profiler_level |
采集的Level等级。可取值如下:
|
msprof_tx |
打点控制开关,通过开关开启自定义打点功能。可取值true(开启)或false(关闭),默认关闭。该参数使用请参见采集并解析msprof_tx数据(可选)。 |
data_simplification |
数据精简模式,开启后将在导出性能数据后删除多余数据,仅保留profiler_*.json文件、ASCEND_PROFILER_OUTPUT目录、PROF_XXX目录下的原始性能数据、FRAMEWORK目录和logs目录,以节省存储空间。可取值true(开启)或false(关闭),默认开启。 |
aic_metrics |
AI Core的性能指标采集项。可取值如下: 以下采集项的结果数据将在Kernel View呈现。 以下采集项的结果数据含义可参见op_summary(算子详细信息),但具体采集结果请以实际情况为准。
|
l2_cache |
控制L2 Cache数据采集开关。可取值true(开启)或false(关闭),默认关闭。该采集项在ASCEND_PROFILER_OUTPUT生成l2_cache.csv文件,结果字段介绍请参见l2_cache(L2 Cache命中率)。 |
op_attr |
控制采集算子的属性信息开关,当前仅支持采集aclnn算子。可取值true(开启)或false(关闭),默认关闭。该参数采集的性能数据仅支持export_type为db时解析的db格式文件。Level_none时,该参数不生效。 |
record_op_args |
控制算子信息统计功能开关。可取值true(开启)或false(关闭),默认关闭。开启后会在{worker_name}_{时间戳}_ascend_pt_op_args目录输出采集到算子信息文件。 说明:
该参数在AOE工具执行PyTorch训练场景下调优时使用,且不建议与其他性能数据采集接口同时开启。详见《AOE调优工具》。 |
gc_detect_threshold |
GC检测阈值。取值范围为大于等于0的数值,单位ms。当用户设置的阈值为数字时,表示开启GC检测,只采集超过阈值的GC事件。 配置为0时表示采集所有的GC事件(可能造成采集数据量过大,请谨慎配置),推荐设置为1ms。 默认为null,表示不开启GC检测功能。 GC是Python进程对已经销毁的对象进行内存回收。 解析结果文件格式配置为torch_npu.profiler.ExportType.Text时,则在解析结果数据trace_view.json中生成GC层。 解析结果文件格式配置为torch_npu.profiler.ExportType.Db时,则在ascend_pytorch_profiler_{rank_id}.db中生成GC_RECORD表。可通过MindStudio Insight工具查看。 |
experimental_config参数说明
experimental_config参数均为可选参数,支持扩展的采集项如下:
参数 |
说明 |
|---|---|
export_type |
设置导出的性能数据结果文件格式,List类型。可取值:
设置无效值或未配置均取默认值torch_npu.profiler.ExportType.Text。两个参数可同时配置,表示同时导出timeline、summary和db文件。 解析结果数据请参见Ascend PyTorch Profiler接口采集数据。 |
profiler_level |
采集的Level等级,Enum类型。可取值如下:
|
msprof_tx |
打点控制开关,通过开关开启自定义打点功能,bool类型。可取值True(开启)或False(关闭),默认关闭。该参数使用请参见采集并解析msprof_tx数据(可选)。 |
data_simplification |
数据精简模式,开启后将在导出性能数据后删除多余数据,仅保留profiler_*.json文件、ASCEND_PROFILER_OUTPUT目录、PROF_XXX目录下的原始性能数据、FRAMEWORK目录和logs目录,以节省存储空间。可取值true(开启)或false(关闭),默认开启。 |
aic_metrics |
AI Core的性能指标采集项。可取值如下: 以下采集项的结果数据将在Kernel View呈现。 以下采集项的结果数据含义可参见op_summary(算子详细信息),但具体采集结果请以实际情况为准。
|
l2_cache |
控制L2 Cache数据采集开关,bool类型。可取值True(开启)或False(关闭),默认关闭。该采集项在ASCEND_PROFILER_OUTPUT生成l2_cache.csv文件,结果字段介绍请参见l2_cache(L2 Cache命中率)。 |
op_attr |
控制采集算子的属性信息开关,当前仅支持采集aclnn算子,bool类型。可取值True(开启)或False(关闭),默认关闭。该参数采集的性能数据仅支持export_type为torch_npu.profiler.ExportType.Db时解析的db格式文件。torch_npu.profiler.ProfilerLevel.None时,该参数不生效。 |
record_op_args |
控制算子信息统计功能开关,bool类型。可取值True(开启)或False(关闭),默认关闭。开启后会在{worker_name}_{时间戳}_ascend_pt_op_args目录输出采集到算子信息文件。 说明:
该参数在AOE工具执行PyTorch训练场景下调优时使用,且不建议与其他性能数据采集接口同时开启。详见《AOE调优工具》。 |
gc_detect_threshold |
GC检测阈值,float类型。取值范围为大于等于0的数值,单位ms。当用户设置的阈值为数字时,表示开启GC检测,只采集超过阈值的GC事件。 配置为0时表示采集所有的GC事件(可能造成采集数据量过大,请谨慎配置),推荐设置为1ms。 默认为None,表示不开启GC检测功能。 GC是Python进程对已经销毁的对象进行内存回收。 解析结果文件格式配置为torch_npu.profiler.ExportType.Text时,则在解析结果数据trace_view.json中生成GC层。 解析结果文件格式配置为torch_npu.profiler.ExportType.Db时,则在ascend_pytorch_profiler_{rank_id}.db中生成GC_RECORD表。可通过MindStudio Insight工具查看。 |
torch_npu.profiler.schedule类参数说明
torch_npu.profiler.schedule类用于在采集进程中设置在不同step时的采集行为。接口原型为:
torch_npu.profiler.schedule (wait, active, warmup = 0, repeat = 0, skip_first = 0)
参数 |
说明 |
|---|---|
wait |
每次重复执行采集跳过的step轮数,int类型。必选。 |
active |
采集的step轮数,int类型。必选。 |
warmup |
预热的step轮数,int类型。默认值为0。建议设置1轮预热。可选。 |
repeat |
重复执行wait+warmup+active的次数,int类型。默认值为0,表示重复执行repeat不停止,建议配置为大于0的整数。可选。 |
skip_first |
采集前先跳过的step轮数,int类型。默认值为0。动态Shape场景建议跳过前10轮保证性能数据稳定;对于其他场景,可以根据实际情况自行配置。可选。 |
注:建议根据此公式配置schedule:step总数 >= skip_first+(wait+warmup+active)*repeat |
|
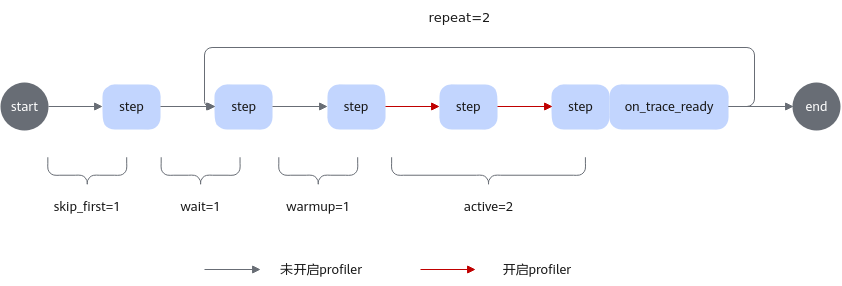
torch_npu.profiler.schedule类、step和on_trace_ready函数使用关系示意图如下:
设置示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | with torch_npu.profiler.profile( activities=[ torch_npu.profiler.ProfilerActivity.CPU, torch_npu.profiler.ProfilerActivity.NPU, ], schedule=torch_npu.profiler.schedule( wait=1, # 等待阶段,跳过1个step warmup=1, # 预热阶段,跳过1个step active=2, # 记录2个step的活动数据,并在之后调用on_trace_ready repeat=2, # 循环wait+warmup+active过程2遍 skip_first=1 # 跳过1个step ), on_trace_ready=torch_npu.profiler.tensorboard_trace_handler('./result') ) as prof: for _ in range(9): train_one_step() prof.step() # 通知profiler完成一个step |
dynamic_profile动态采集维测日志介绍
1 2 3 4 5 6 7 8 | profiler_config_path/ ├── log │ ├── dp_ubuntu_xxxxxx_rank_*.log │ ├── dp_ubuntu_xxxxxx_rank_*.log.1 │ ├── monitor_dp_ubuntu_xxxxxx_rank_*.log │ ├── monitor_dp_ubuntu_xxxxxx_rank_*.log.1 ├── profiler_config.json └── shm |
- dp_ubuntu_xxxxxx.log:dynamic_profile动态采集的执行日志,记录动态采集执行过程中的所有动作(INFO)、警告(WARNING)和错误(ERROR)。文件命名格式:dp_{操作系统}_{AI任务进程ID}_{rank_id}.log。
AI任务启动时每个Rank会开启一个AI任务进程,dynamic_profile根据每个AI任务进程ID生成各个AI任务进程下的日志文件。
- dp_ubuntu_xxxxxx.log.1:日志老化备份文件,dp_ubuntu_xxxxxx.log文件的存储上限为200K,达到上限后将时间最早的日志记录转移到dp_ubuntu_xxxxxx.log.1中,dp_ubuntu_xxxxxx.log.1文件存储上限同样为200K,达到上限后则将最早的日志记录老化删除。
- monitor_dp_ubuntu_xxxxxx.log:profiler_config.json文件修改日志,开启dynamic_profile动态采集后,实时记录profiler_config.json文件的每次修改时间、修改是否生效以及dynamic_profile进程的结束,示例如下:
1 2 3
2024-08-21 15:51:46,392 [INFO] [2127856] _dynamic_profiler_monitor.py: Dynamic profiler process load json success 2024-08-21 15:51:58,406 [INFO] [2127856] _dynamic_profiler_monitor.py: Dynamic profiler process load json success 2024-08-21 15:58:16,795 [INFO] [2127856] _dynamic_profiler_monitor.py: Dynamic profiler process done
文件命名格式:monitor_dp_{操作系统}_{monitor进程ID}_{rank_id}.log。
- monitor_dp_ubuntu_xxxxxx.log.1:日志老化备份文件,monitor_dp_ubuntu_xxxxxx.log文件的存储上限为200K,达到上限后将时间最早的日志记录转移到monitor_dp_ubuntu_xxxxxx.log.1中,monitor_dp_ubuntu_xxxxxx.log.1文件存储上限同样为200K,达到上限后则将最早的日志记录老化删除。
- shm目录:为了适配Python3.7,dynamic_profile会在py37环境下会生成shm目录,目录下生成一个二进制文件(DynamicProfileNpuShm+时间)映射共享内存, 程序正常结束后会自动清理,当使用pkill终止程序时,由于是异常终止,程序无法释放资源,需要用户手动清理此文件,否则短时间内(<1h)下次使用同一配置路径启动dynamic_profile,则会导致dynamic_profile异常。对于Python3.8及以上版本,二进制文件(DynamicProfileNpuShm+时间)存放在 /dev/shm目录下,当使用pkill终止程序时,同样需要手动清理此文件。