功能说明
在某些算法下,一次完整的集合通信任务可以细分为多个步骤,对每个步骤的数据完成点对点的通信任务,称为细粒度通信。以通信算法"AlltoAll=level0:fullmesh;level1:pairwise"、通信步长为1的AlltoAllV通信任务为例,这里参数level0代表配置Server(昇腾AI Server,通常是8卡或16卡的昇腾NPU设备组成的服务器形态的统称)内通信算法,参数level1代表配置Server间通信算法,fullmesh为全连接通信算法,pairwise为逐对通信算法,详细的算法内容可参见集合通信算法;如下图所示,该示例展示了AlltoAllV通信的所有待发送数据、每一步通信完成后各卡收到的数据。
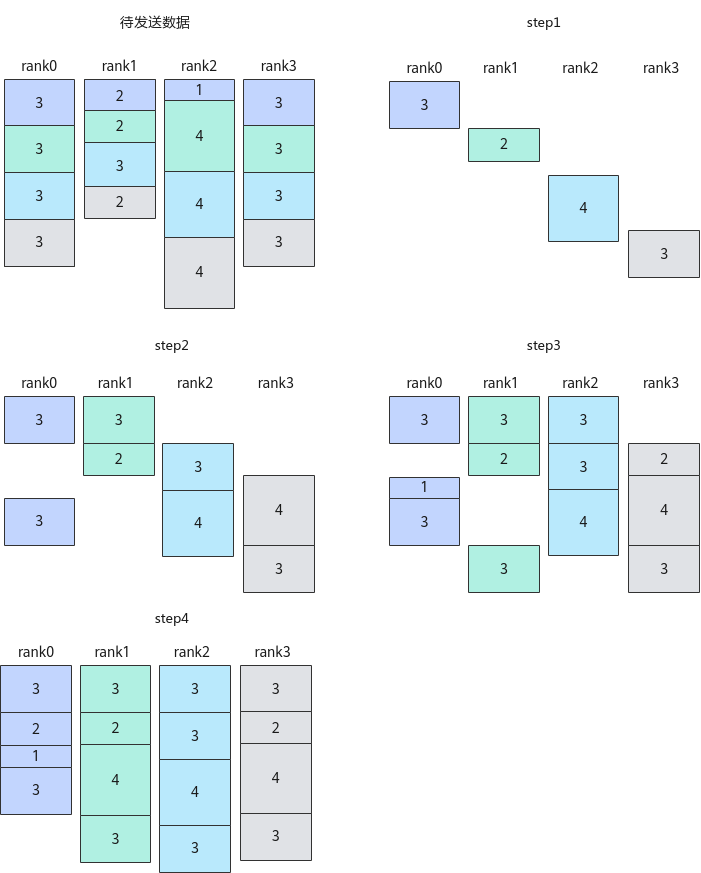
在通算融合算子中,通过调用本接口,结合对应的Prepare原语,获取通信算法每一步的输入或输出,让计算、通信实现更精细粒度的流水排布,从而获得更好的性能收益。
函数原型
1 2 |
template <bool sync = true> __aicore__ inline int32_t Iterate(HcclHandle handleId, uint16_t *seqSlices, uint16_t seqSliceLen) |
参数说明
|
参数名 |
输入/输出 |
描述 |
|---|---|---|
|
sync |
输入 |
bool类型。是否需要等待当前通信步骤完成再进行后续计算或通信任务,参数取值如下:
|
|
参数名 |
输入/输出 |
描述 |
||
|---|---|---|---|---|
|
handleId |
输入 |
对应通信任务的标识ID,只能使用Prepare原语接口的返回值。
|
||
|
seqSlices |
输出 |
由用户申请的栈空间,用于保存当前通信步骤的输入或输出数据块的索引下标。在先计算后通信场景,该参数返回当前通信步骤需要的输入数据块索引;在先通信后计算场景,该参数返回当前通信步骤的输出数据块索引。 |
||
|
seqSliceLen |
输入 |
seqSlices数组的长度。根据算法的通信步长及算法逻辑,取每一步通信需要保存的数据块索引个数为该数组长度。 |
返回值
- 当通信任务未结束时:
- 在先计算后通信场景,返回值为当前通信步骤需要的输入数据块数量,与参数seqSliceLen数值相同。
- 在先通信后计算场景,返回值为当前通信步骤产生的输出数据块数量,与参数seqSliceLen数值相同。
- 当通信任务结束后,返回值为0。
支持的型号
约束说明
- 调用本接口前确保已调用过Init和SetCcTiling接口。
- 入参handleId只能使用Prepare原语对应接口的返回值。
- 本接口当前支持的通信算法为"AlltoAll=level0:fullmesh;level1:pairwise"。
调用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
extern "C" __global__ __aicore__ void alltoallv_custom(GM_ADDR sendBuf, GM_ADDR recvBuf, GM_ADDR workspaceGM, GM_ADDR tilingGM) { // 指定AIV核通信 if (AscendC::g_coreType != AIV) { return; } constexpr uint32_t RANK_NUM = 4U; constexpr uint64_t sendCounts[RANK_NUM][RANK_NUM] = { {3, 3, 3, 3}, {2, 2, 3, 2}, {1, 4, 4, 4}, {3, 3, 3, 3} }; constexpr uint64_t sDisplacements[RANK_NUM][RANK_NUM] = { {0, 3, 6, 9}, {0, 2, 4, 7}, {0, 1, 5, 9}, {0, 3, 6, 9} }; constexpr uint64_t recvCounts[RANK_NUM][RANK_NUM] = { {3, 2, 1, 3}, {3, 2, 4, 3}, {3, 3, 4, 3}, {3, 2, 4, 3} }; constexpr uint64_t rDisplacements[RANK_NUM][RANK_NUM] = { {0, 3, 5, 6}, {0, 3, 5, 9}, {0, 3, 6, 10}, {0, 3, 5, 9} }; HcclDataType dtype = HcclDataType::HCCL_DATA_TYPE_FP16; REGISTER_TILING_DEFAULT(AllToAllVCustomTilingData); // AllToAllVCustomTilingData为对应算子头文件定义的结构体 auto tiling = (__gm__ AllToAllVCustomTilingData *)tilingGM; GM_ADDR contextGM = AscendC::GetHcclContext<0>(); // AscendC自定义算子kernel中,通过此方式获取Hccl context __gm__ void *mc2InitTiling = (__gm__ void *)(&tiling->mc2InitTiling); __gm__ void *alltoallvTiling = (__gm__ void *)(&(tiling->alltoallvCcTiling)); Hccl hccl; hccl.Init(contextGM, mc2InitTiling); auto ret = hccl.SetCcTiling(alltoallvTiling); if (ret != HCCL_SUCCESS) { return; } const uint32_t selfRankId = hccl.GetRankId(); uint16_t sliceInfo[RANK_NUM]; if (TILING_KEY_IS(1000UL)) { // 通算融合中的“先通信后计算”场景,即每一步都是先通信,再将通信的输出作为计算的输入并执行计算 const auto handleId = hccl.AlltoAllV<true>(sendBuf, sendCounts[selfRankId], sDisplacements[selfRankId], dtype, recvBuf, recvCounts[selfRankId], rDisplacements[selfRankId], dtype); // 模板参数sync = true,表示该接口会阻塞等待每一步通信结果,并将输出数据块的下标索引填入sliceInfo中 while (hccl.Iterate<true>(handleId, sliceInfo, RANK_NUM)) { // 每一步通信的输出数据块的下标索引保存在sliceInfo中,可以插入相应的计算流程,实现细粒度的通算融合 } // Iterate已经会阻塞等待,因此不再需要Wait // hccl.Wait(handleId); } else if (TILING_KEY_IS(1001UL)) { // 通算融合中的“先计算后通信”场景,即每一步都是先计算,再将计算的结果作为通信的输入并提交通信事务 const auto handleId = hccl.AlltoAllV<false>(sendBuf, sendCounts[selfRankId], sDisplacements[selfRankId], dtype, recvBuf, recvCounts[selfRankId], rDisplacements[selfRankId], dtype); // 模板参数sync = false,表示该接口不会阻塞等待,只会将当前这一步通信的输入数据块填入sliceInfo中 while (hccl.Iterate<false>(handleId, sliceInfo, RANK_NUM)) { // 根据sliceInfo,进行相应的计算,并将计算结果填入sliceInfo对应的GM地址,保证通信的输入正确 // 通过Commit接口通知服务端进行集合通信 hccl.Commit(handleId); } // 等待通信任务完成(当前通信任务总步数为RANK_NUM,步长为1,因此需要调用RANK_NUM次wait) for (uint32_t i = 0; i < RANK_NUM; ++i) { hccl.Wait(handleId); } } AscendC::SyncAll<true>(); hccl.Finalize(); } |