问题现象
常见于算子执行阶段,屏显日志关键报错信息“EI0002: The wait execution of the Notify register times out.”,示例如下:
1 2 3 4 |
Error. Message is EI0002:The wait execution of the Notify register times out. Reason: The Notify register has not received the Notify record from remote rank [4].base information: [streamID:[14],taskID[6], taskType[Notify Wait], tag[AllReduce_6629421139219749105_0].] task information: [notify id:[0x000000700000058], stage:[fffffff], remote rank:[4].] …… there are(is) 1 abnormal device(s): serverId[192.168.100.111], deviceId[4], Heartbeat Lost Occurred, Possible Reason: 1. Process has exited, 2. Network Disconnected |
plog日志中查询Notify,有如下类似信息:
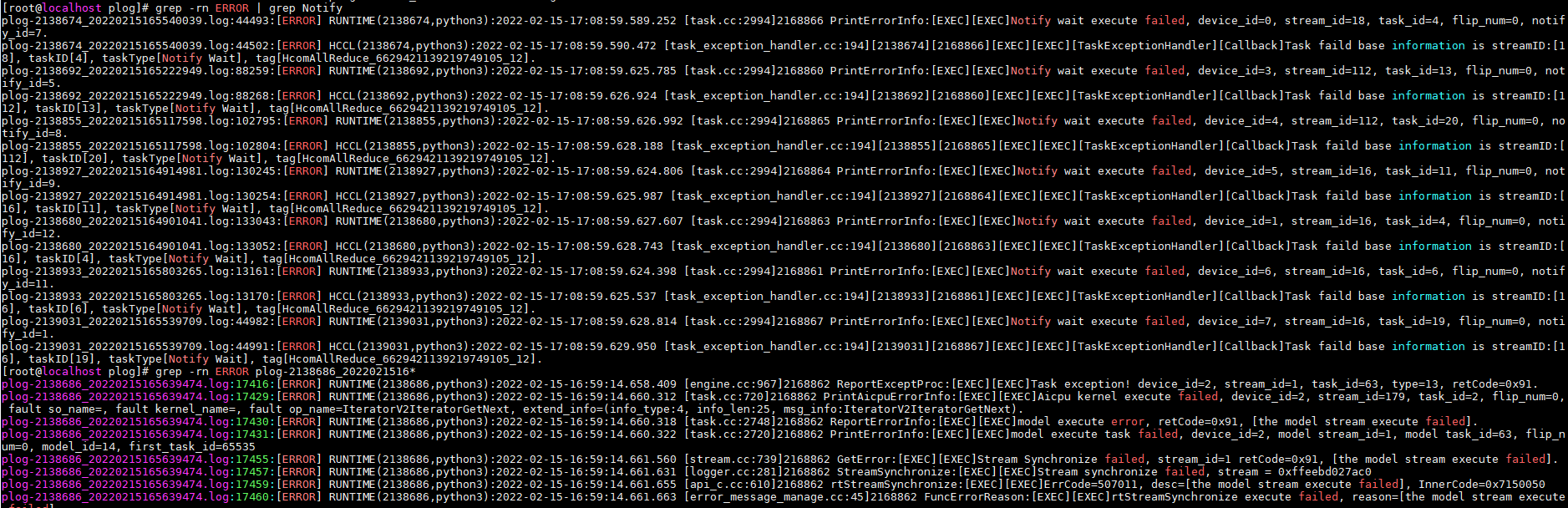
原因分析
HCCL算子的task会在指定集群的每个Device上执行,并通过notify进行状态同步,若任何一个rank或者通信链路在执行前或执行中发生异常,都会导致集群同步失败,剩余卡会出现notify wait timeout。常见的原因主要有:
- 部分卡被某些耗时较长的任务阻塞,在超过设置的执行同步等待时间(可通过环境变量HCCL_EXEC_TIMEOUT配置)后才继续往下执行。
- 部分rank未执行到notify同步阶段。
- 网络模型等原因导致某些rank间的task执行序列不一致。
- 节点间通信链路不稳定。
- 训练场景下,用户设置的HCCL_EXEC_TIMEOUT小于HCCL_CONNECT_TIMEOUT时,建链失败,报notify wait超时。
解决方法
收集所有卡的plog日志后,按如下步骤排查:
- 检查所有卡的报错情况,若有卡未报notify超时错误,请通过训练或者plog日志检查此卡是否存在业务进程报错退出、卡死或异常终止的情况。
- 若所有卡均上报notify超时错误,则检查错误日志中最早报错和最晚报错时间差是否超过算子执行超时阈值,若超过阈值请定位报错时间最晚的rank执行阻塞原因(如save checkpoint)或通过HCCL_EXEC_TIMEOUT环境变量调整超时阈值,例如export HCCL_EXEC_TIMEOUT=3600(此处仅示例,请根据需要配置)。
- 检查集群中是否存在Device网口通信链路不稳定的情况,搜索所有卡的Device侧日志,若存在error cqe的打印,时间位于业务区间内,这种情况可能是发生网络拥塞,需要排查交换机配置是否合理、训练过程中是否有网口link down等情况。
搜索命令样例:grep –rn “err cqe” | grep HCCL
关键日志如下:
119987:[ERROR] HCCL(85111,python3):2023-02-18-09:44:55.431.692 [heartbeat.cc:547][85111][94635][Heartbeat]cqe err status[12],time:[2023-02-18 09:44:55.369944],ip:[*.*.*.*]