功能描述
实现“Transformer Attention Score”的融合计算,实现的计算公式如下:
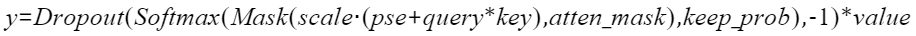
接口原型
torch_npu.npu_fusion_attention(Tensor query, Tensor key, Tensor value, int head_num, str input_layout, Tensor? pse=None, Tensor? padding_mask=None, Tensor? atten_mask=None, float scale=1., float keep_prob=1., int pre_tockens=2147483647, int next_tockens=2147483647, int inner_precise=0, int[]? prefix=None, int[]? actual_seq_qlen=None, int[]? actual_seq_kvlen=None, int sparse_mode=0, bool gen_mask_parallel=True, bool sync=False) -> (Tensor, Tensor, Tensor, Tensor, int, int, int)
参数说明
- query:Device侧的Tensor,公式中输入Q,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- key:Device侧的Tensor,公式中输入K,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- value:Device侧的Tensor,公式中输入V,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。
- head_num:Host侧的int64_t,代表head个数,数据类型支持INT64。
- input_layout:Host侧的string,代表输入query、key、value的数据排布格式,支持BSH、SBH、BSND、BNSD,TND(actual_seq_qlen/actual_seq_kvlen需传值)。
- pse:Device侧的Tensor,公式中输入pse,可选参数,表示位置编码。数据类型支持FLOAT16、BFLOAT16,数据格式支持ND。四维输入,支持BNSS格式、B1SS格式、1NSS格式。alibi位置编码, 如果S大于1024且下三角掩码场景,只输入下三角倒数1024行进行内存优化,参数每个batch不相同,输入BNHS,每个batch相同,输入1NHS(H=1024)。
- padding_mask:Device侧的Tensor,暂不支持该传参。
- atten_mask:Device侧的Tensor,可选参数,取值为1代表该位不参与计算(不生效),为0代表该位参与计算,数据类型支持BOOL、UINT8,数据格式支持ND格式、BNSS格式、B1SS格式、11SS格式、SS格式。
- scale:Host侧的double,可选参数,公式中d开根号的倒数,代表缩放系数,作为计算流中Muls的scalar值,数据类型支持DOUBLE。
- keep_prob:Host侧的double,可选参数,代表dropMask中1的比例,数据类型支持DOUBLE。
- dropMask:Device侧的aclTensor,可选参数,数据类型支持UINT8(标识8个1bit BOOL),数据格式支持ND。
- pre_tockens:Host侧的int64_t,用于稀疏计算的参数,可选参数,数据类型支持INT64。
- next_tockens:Host侧的int64_t,用于稀疏计算的参数,可选参数,数据类型支持INT64。next_tockens和pre_tockens取值与atten_mask的关系请参见sparse_mode参数,参数取值与atten_mask分布不一致可能导致精度问题。
- inner_precise:Host侧的int64_t,用于提升精度,默认配置为0即可。
说明:当前0、1为保留配置值,当计算过程中存在整行mask进而导致精度有损失时,可以尝试将该参数配置为2以提升精度,但是该配置可能会导致性能下降。
- prefix:Device侧的Tensor,可选参数,代表prefix稀疏计算场景每个Batch的N值。数据类型支持INT64,数据格式支持ND。
- actual_seq_qlen:Device侧的Tensor,可选参数,varlen场景需要传。表示query每个S的累加和长度,数据类型支持INT64,数据格式支持ND。
则actual_seq_qlen传:2 4 6 8 10
- actual_seq_kvlen:Device侧的Tensor,可选参数,varlen场景需要传。表示key/value每个S的累加和长度。数据类型支持INT64,数据格式支持ND。
则actual_seq_qlen传:2 4 6 8 10
- sparse_mode:Host侧的int,表示sparse的模式,可选参数。数据类型支持:INT64。
atten_mask的工作原理为,在Mask为True的位置遮蔽query(Q)与key(K)的转置矩阵乘积的值,示意如下:
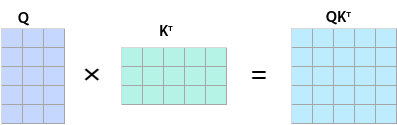
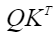 矩阵在atten_mask为Ture的位置会被遮蔽,效果如下:
矩阵在atten_mask为Ture的位置会被遮蔽,效果如下: 说明:下图中的白色表示保留该值,atten_mask中,应该配置为False;阴影表示mask out该值,atten_mask中应配置为True。
说明:下图中的白色表示保留该值,atten_mask中,应该配置为False;阴影表示mask out该值,atten_mask中应配置为True。- sparse_mode为0时,代表defaultMask模式。
- 不传mask:如果atten_mask未传入则不做mask操作,atten_mask取值为None,忽略pre_tockens和next_tockens(内部赋值为INT_MAX)取值。
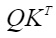 矩阵示意如下:
矩阵示意如下:
- next_tockens取值为0,pre_tockens配置为INT_MAX,表示causal场景sparse,atten_mask应传入下三角矩阵,此时pre_tockens和next_tockens之间的部分需要计算,
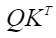 矩阵示意如下:
矩阵示意如下:
atten_mask应传入下三角矩阵,示意如下:

- next_tockens取值为0,pre_tockens配置为小于Sq的正数,表示band场景,此时pre_tockens和next_tockens之间的部分需要计算。
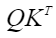 矩阵示意如下:
矩阵示意如下: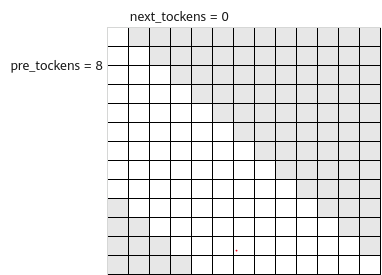
atten_mask应传入band形状矩阵,示意如下:

- pre_tockens,next_tockens都为小于Seq_length的正数,以pre_tockens=4,next_tockens=5为例,pre_tockens和next_tockens之间的部分需要计算。
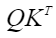 示意如下:
示意如下:
- next_tockens为负数,以pre_tockens=9,next_tockens=-3为例,pre_tockens和next_tockens之间的部分需要计算。
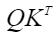 示意如下:
示意如下:说明:next_tockens为负数时,pre_tockens取值必须大于next_tockens的绝对值。

- 不传mask:如果atten_mask未传入则不做mask操作,atten_mask取值为None,忽略pre_tockens和next_tockens(内部赋值为INT_MAX)取值。
- sparse_mode为1时,代表allMask,即传入完整的atten_mask矩阵。
该场景下忽略next_tockens、pre_tockens取值(内部赋值为INT_MAX),
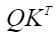 矩阵示意如下:
矩阵示意如下:
- sparse_mode为2时,代表leftUpCausal模式的mask,对应以左上顶点划分的下三角场景(参数起点为左上角)。该场景下忽略next_tockens、pre_tockens取值,
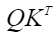 矩阵示意如下:
矩阵示意如下:
传入的atten_mask为优化后的压缩下三角矩阵(2048*2048),压缩下三角矩阵示意(下同):

- sparse_mode为3时,代表rightDownCausal模式的mask,对应以右下顶点划分的下三角场景(参数起点为右下角)。该场景下忽略next_tockens、pre_tockens取值。atten_mask为优化后的压缩下三角矩阵(2048*2048),
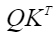 矩阵示意如下:
矩阵示意如下:
- sparse_mode为4时,代表band场景,即计算pre_tockens和next_tockens之间的部分,参数起点为右下角。atten_mask为优化后的压缩下三角矩阵(2048*2048)。
- sparse_mode为5时,代表prefix场景,即在rightDownCasual的基础上,左侧加上一个长为S1,宽为N的矩阵,N的值由新增的输入prefix获取,例如下图中表示band=2场景下prefix传入数组[4,5],且每个Batch轴的N值不一样,参数起点为左上角。
该场景下忽略next_tockens、pre_tockens取值,atten_mask矩阵数据格式须为BNSS或B1SS,示意如下:

atten_mask应传入矩阵示意如下:
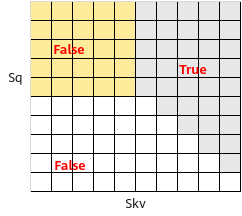
- sparse_mode为6、7、8时,分别代表global、dilated、block_local,均暂不支持。
- sparse_mode为0时,代表defaultMask模式。
- gen_mask_parallel:debug参数,DSA生成dropout随机数向量mask的控制开关,默认值为True:同AICORE计算并行,False:同AICORE计算串行。
- sync:debug参数,DSA生成dropout随机数向量mask的控制开关,默认值为False:dropout mask异步生成,True:dropout mask同步生成。
输出说明
共7个输出
(Tensor, Tensor, Tensor, Tensor, int, int, int)
- 第1个输出为Tensor,计算公式的最终输出y,数据类型支持:FLOAT16、BFLOAT16。
- 第2个输出为Tensor,Softmax 计算的Max中间结果,用于反向计算,数据类型支持:FLOAT。
- 第3个输出为Tensor,Softmax计算的Sum中间结果,用于反向计算,数据类型支持:FLOAT。
- 第4个输出为Tensor,保留参数,暂未使用。
- 第5个输出为int,DSA生成dropoutmask中,Philox算法的seed。
- 第6个输出为int,DSA生成dropoutmask中,Philox算法的offset。
- 第7个输出为int,DSA生成dropoutmask的长度。
约束说明
- 输入query、key、value的B:batchsize必须相等,取值范围1~256。unpad场景B支持1-2K
- 输入query的N和key/value的N 必须成比例关系,即Nq/Nkv必须是非0整数,取值范围1~256。当Nq/Nkv > 1时,即为GQA,当Nkv=1时,即为MQA。
- 输入key/value的shape必须一致。
- 输入query、key、value的S:sequence length,取值范围1~64K。
- 输入query、key、value的D:head dim,取值范围1~512。
- 在使能band sparse、causal计算时,必须输入atten_mask。
- 当所有的atten_mask的shape小于2048且相同的时候,建议使用default模式,来减少内存使用量。
- sparse_mode配置为1、2、3、5时,用户配置的pre_tockens、next_tockens不会生效。
- sparse_mode配置为0、4时,须保证atten_mask与pre_tockens、next_tockens的范围一致。
支持的PyTorch版本
- PyTorch 2.1
- PyTorch 2.0
- PyTorch 1.11.0
支持的型号
Atlas A2 训练系列产品
调用示例
import math
import unittest
import numpy as np
import torch
import torch_npu
from torch_npu.testing.testcase import TestCase, run_tests
from torch_npu.testing.common_utils import SupportedDevices
class TestNPUFlashAttention(TestCase):
def supported_op_exec(self, query, key, value, atten_mask):
scale = 0.08838
qk = torch.matmul(query, key.transpose(2, 3)).mul(scale)
qk = qk + atten_mask * (-10000.0)
softmax_res = torch.nn.functional.softmax(qk, dim=-1, dtype=torch.float32).to(torch.float16)
attention_out = torch.matmul(softmax_res, value)
return attention_out
def custom_op_exec(self, query, key, value, sparse_params):
scale = 0.08838
atten_mask = None
if sparse_params[0] == 0:
shape = [1, 8, 256, 256]
atten_mask_u = np.triu(np.ones(shape), k=sparse_params[1] + 1)
atten_mask_l = np.tril(np.ones(shape), k=-sparse_params[2] - 1)
atten_masks = atten_mask_u + atten_mask_l
atten_mask = torch.tensor(atten_masks).to(torch.float16).bool().npu()
if sparse_params[0] == 2 or sparse_params[0] == 3 or sparse_params[0] == 4:
atten_masks = torch.from_numpy(np.triu(np.ones([2048, 2048]), k=1))
atten_mask = torch.tensor(atten_masks).to(torch.float16).bool().npu()
return torch_npu.npu_fusion_attention(
query, key, value, head_num=8, input_layout="BNSD", scale=scale, sparse_mode=sparse_params[0],
atten_mask=atten_mask, pre_tockens=sparse_params[1], next_tockens=sparse_params[2])
def get_atten_mask(self, sparse_mode=0, pre_tokens=65536, next_tokens=65536):
atten_masks = []
shape = [1, 8, 256, 256]
if sparse_mode == 0:
atten_mask_u = np.triu(np.ones(shape), k=next_tokens + 1)
atten_mask_l = np.tril(np.ones(shape), k=-pre_tokens - 1)
atten_masks = atten_mask_u + atten_mask_l
elif sparse_mode == 1:
atten_masks = np.zeros(shape)
pre_tokens = 65536
next_tokens = 65536
elif sparse_mode == 2:
atten_masks = np.triu(np.ones(shape), k=1)
elif sparse_mode == 3:
atten_masks = np.triu(np.ones(shape), k=1)
elif sparse_mode == 4:
atten_mask_u = np.triu(np.ones(shape), k=next_tokens + 1)
atten_mask_l = np.tril(np.ones(shape), k=-pre_tokens - 1)
atten_masks = atten_mask_u + atten_mask_l
atten_mask = torch.tensor(atten_masks).to(torch.float16)
return atten_mask
# sparse_params = [sparse_mode, pre_tokens, next_tokens]
def check_result(self, query, key, value, sparse_params):
atten_mask = self.get_atten_mask(sparse_params[0], sparse_params[1], sparse_params[2])
output = self.supported_op_exec(query, key, value, atten_mask)
fa_result = self.custom_op_exec(query.npu(), key.npu(), value.npu(), sparse_params)
self.assertRtolEqual(output, fa_result[0], prec=0.01, prec16=0.01)
def test_npu_flash_attention(self, device="npu"):
query = torch.randn(1, 8, 256, 256, dtype=torch.float16)
key = torch.randn(1, 8, 256, 256, dtype=torch.float16)
value = torch.randn(1, 8, 256, 256, dtype=torch.float16)
# sparse_params: [sparse_mode, pre_tokens, next_tokens]
sparse_params_list = [
[0, 128, 128],
[1, 65536, 65536],
[2, 65536, 0],
[3, 65536, 0],
[4, 128, 128]
]
for sparse_params in sparse_params_list:
self.check_result(query, key, value, sparse_params)
if __name__ == "__main__":
run_tests()