功能描述
GroupedMatmul算子可以实现分组矩阵乘计算,每组矩阵乘的维度大小可以不同,是一种灵活的支持方式。其主要输入与输出均为TensorList,其中输入数据x与输出结果y均支持切分及不切分的模式,根据参数split_item来确定x与y是否需要切分,在x需要切分的情况下使用参数group_list来描述对x的m轴进行切分的方式。
根据输入x、输入weight与输出y的Tensor数量不同,可以支持如下4种场景:
- x、weight、y的Tensor数量等于组数,即每组的数据对应的Tensor是独立的。
- x的Tensor数量为1,weight/y的Tensor数量等于组数,此时需要通过可选属性group_list说明x在行上的分组情况,如group_list[0]=10说明x的前10行参与第一组矩阵乘计算。
- x、weight的Tensor数量等于组数,y的Tensor数量为1,此时每组矩阵乘的结果放在同一个Tensor中连续存放。
- x、y的Tensor数量为1,weight数量等于组数,属于前两种情况的组合。
计算公式为:
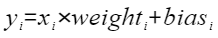
接口原型
参数说明
- x:必选参数,Device侧的TensorList,即输入参数中的x,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,支持的最大长度为128个,其中每个Tensor在split_item=0的模式下最多支持输入6维,其余模式下支持输入为2维。
- weight:必选参数,Device侧的TensorList,即输入参数中matmul的weight输入,数据类型支持FLOAT16、BFLOAT16,数据格式支持ND,支持的最大长度为128个,其中每个Tensor支持输入为2维。
- bias:在PyTorch 1.11与2.0版本中是必选参数,在PyTorch 2.1与2.2版本中是可选参数,Device侧的TensorList,即输入参数中matmul的bias输入,数据类型支持FLOAT16、FLOAT32,数据格式支持ND,支持的最大长度为128个,其中每个Tensor支持输入为1维。
- group_list:可选参数,Host侧的IntArray类型,是切分的索引,代表输入和输出M方向的matmul大小分布,数据类型支持INT64,数据格式支持ND,支持输入为1维,支持的最大长度为128个,默认为空。
- split_item:可选属性,Int类型,切分模式的说明,数据类型支持INT32,可取的值有4个:0表示输入和输出都不需要进行切分;1表示输入需要切分;2表示输出需要切分;3表示输入和输出都需要切分。默认值为0。
输出说明
Device侧的TensorList类型输出,代表GroupedMatmul的计算结果,当split_item取0或1时,其Tensor个数与weight相同,当split_item取2或3时,其Tensor个数为1。
约束说明
- 当split_item取0或2时,x的Tensor个数与weight相同;当split_item取1或3时,x的Tensor个数为1。
- 当split_item取0或2时,group_list为空;当split_item取1或3时,group_list的长度与weight的Tensor个数相同。
- 若bias不为空,其Tensor数量须与weight保持一致。
- 记一个matmul计算涉及的x、weight与y的维度分别为(m×k)、(k×n)和(m×n),每一个matmul的输入与输出须满足[m, k]和[k, n]的k维度相等关系。
- x、weight、bias三个输入支持多种数据类型,此算子支持的数据类型组合为“x-FLOAT16、weight-FLOAT16、bias-FLOAT16”,或“x-BFLOAT16、weight-BFLOAT16、bias-FLOAT32”。
- 对于实际无bias的场景,在PyTorch 1.11与2.0版本中,须手动指定“bias=[]”;在PyTorch 2.1与2.2版本中,可以直接不指定bias参数。
支持的PyTorch版本
- PyTorch 2.2
- PyTorch 2.1
- PyTorch 2.0
- PyTorch 1.11
支持的型号
Atlas A2 训练系列产品
调用示例
# 单算子调用模式 import torch import torch_npu x1 = torch.randn(256, 256, device='npu', dtype=torch.float16) x2 = torch.randn(1024, 256, device='npu', dtype=torch.float16) x3 = torch.randn(512, 1024, device='npu', dtype=torch.float16) x = [x1, x2, x3] weight1 = torch.randn(256, 256, device='npu', dtype=torch.float16) weight2 = torch.randn(256, 1024, device='npu', dtype=torch.float16) weight3 = torch.randn(1024, 128, device='npu', dtype=torch.float16) weight = [weight1, weight2, weight3] bias1 = torch.randn(256, device='npu', dtype=torch.float16) bias2 = torch.randn(1024, device='npu', dtype=torch.float16) bias3 = torch.randn(128, device='npu', dtype=torch.float16) bias = [bias1, bias2, bias3] group_list = None split_item = 0 npu_out = torch_npu.npu_grouped_matmul(x, weight, bias=bias, group_list=group_list, split_item=split_item)