



Mindspeed-LLM权重转换异常问题排查与解决方案
发表于: 2026/06/03
背景概述
在基于MindSpeed-LLM进行大模型训练与微调的实践中,模型权重的格式转换是关键环节之一。通常流程为:先将Hugging Face格式的原始模型权重通过hf2mcore脚本转换为 MindSpore Core(MCore)格式,用于训练;训练完成后,再通过mcore2hf脚本将训练得到的MCore权重转回Hugging Face格式,以便在其他推理框架中使用。该流程在非MoE模型场景下普遍适用,但若转换脚本版本不一致,可能导致运行时异常。
本文针对在使用Qwen3-8B模型进行LoRA微调后,执行mcore2hf转换时报出AssertionError: Num-layer (36) must be greater than first-k-dense-replace (36) when first-k-dense-replace is set的问题,进行系统性分析与解决,总结出通用排查思路与最佳实践。
问题现象
使用Mindspeed-llm对qwen3-8b模型进行lora微调,微调后执行mcore2hf(mcore权重转回hugging face格式)转换脚本时,出现如下错误:
AssertionError: Num-layer (36) must be greater than first-k-dense-replace (36) when first-k-dense-replace is set.

原因分析
1. 版本一致性检查
需要逐个检查个组件版本是否满足如下约束:
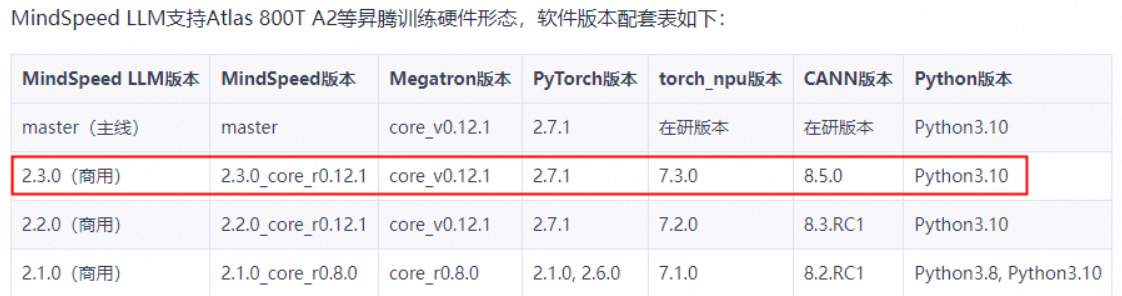
具体版本约束详见代码分支对应的readme,以2.3.0分支为例:https://gitcode.com/Ascend/MindSpeed-LLM/blob/2.3.0/README.md
经检查,各组件都满足版本约束。
2. 参数配置核查
检查mcore2hf脚本(路径:MindSpeed-LLM/examples/mcore/qwen3/ckpt_convert_qwen3_mcore2hf_lora.sh)中以下关键参数:
- TP和PP是否设置为1;
- lora-r与lora-alpha是否与训练脚本保持一致;
- load-dir、lora-load、save-dir路径是否正确。
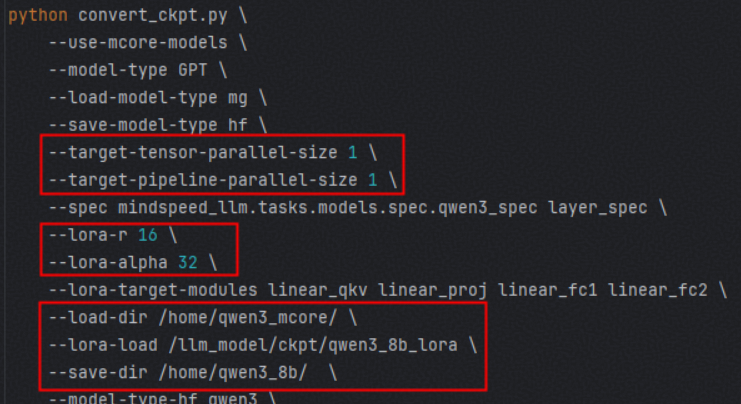
经检查,所有参数配置均无误,排除配置错误。
3. 错误参数溯源
回归报错码本身进行排查:Num-layer (36) must be greater than first-k-dense-replace (36) when first-k-dense-replace is set
其中Num-layer在微调脚本中被设置为36:--num-layers 36 \
first-k-dense-replace在训练、转换脚本中都没有设置;当前项目中全局查找该参数,发现是出现在convert_ckpt_v2.py中


convert_ckpt_v2.md中关于该参数的描述如下,可见是MOE模型中才会用到的参数,但是微调的模型并非MOE模型。
[--first-k-dense-replace]
指定的减层模型中moe层前的dense层数,不能大于原始模型的dense层数,默认值为None 非减层情况下通过配置文件传入,无需指定该参数。
如果需要配合训练脚本进行减层调试,请注意此参数需要和训练脚本保持一致。且mcore2hf的转换脚本中使用的是convert_ckpt.py,该脚本中并不存在first-k-dense-replace这个参数检查微调前使用的hf2mcore(hugging face转 mcore)转换脚本,使用的是convert_ckpt_v2.py:(原始权重转换脚本路径:MindSpeed-LLM/examples/mcore/qwen3/ckpt_convert_qwen3_hf2mcore.sh)综上,怀疑是hf2mcore时使用的convert_ckpt_v2.py,而mcore2hf时使用的convert_ckpt.py,导致first-k-dense-replace逻辑判断异常。
4. 尝试统一微调前后的转换脚本
由于当前lora微调指导中都是建议使用convert_ckpt.py,所以保持mcore2hf脚本不变,修改hf2mcore脚本使其使用convert_ckpt.py
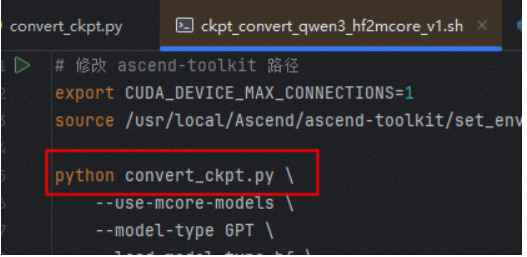
使用新的hf2mcore进行原始权重转换后重新进行lora微调,然后进行mcore2hf权重转换成功。
问题根因
原始权重转时的hf2mcore脚本中使用的是convert_ckpt_v2.py,而lora微调结束后mcore2hf的脚本中使用的是convert_ckpt.py,代码仓不支持在一个训练过程中convert_ckpt.py和convert_ckpt_v2.py混用。
解决方案
短期方案:统一转换脚本版本
为确保转换流程一致性,需保证hf2mcore与mcore2hf 使用相同的转换脚本。由于当前 LoRA 微调指导推荐使用 convert_ckpt.py,因此:
1. 修改原始权重转换脚本(ckpt_convert_qwen3_hf2mcore.sh),将调用的 convert_ckpt_v2.py 替换为 convert_ckpt.py;
2. 重新执行hf2mcore转换,生成新的MCore格式权重;
3. 使用原 mcore2hf脚本完成权重回传,转换成功。
✅ 成功验证:转换流程顺利通过,未再出现断言错误。
长期方案:升级至最新版本
当前 master 分支已支持 LoRA微调场景下使用convert_ckpt_v2.py,并修复了脚本间兼容性问题。建议拉取最新代码:
- Issue:(https://gitcode.com/Ascend/MindSpeed-LLM/issues/1246)
- 合入 PR:(https://gitcode.com/Ascend/MindSpeed-LLM/pull/4319)
升级后,可自由选择使用 convert_ckpt.py 或 convert_ckpt_v2.py,系统将自动处理参数兼容性。
最佳实践建议
为避免类似问题,建议在使用 MindSpeed-LLM 进行模型训练与转换时,遵循以下原则:
1. 统一转换脚本
在整个流程中,确保 hf2mcore 与 mcore2hf 使用同一版本的转换脚本(convert_ckpt.py 或 convert_ckpt_v2.py),禁止混用。
2. 参考官方文档配置
详细参数说明请查阅对应文档:
checkpoint_convert.md:对应convert_ckpt.py;checkpoint_convert-v2.md:对应convert_ckpt_v2.py;- 路径:(https://gitcode.com/Ascend/MindSpeed-LLM/tree/2.3.0/docs/pytorch/solutions/checkpoint )
3. 版本管理规范
严格遵循代码仓版本约束,确保 CANN、PyTorch、MindSpeed-LLM 等组件版本匹配,避免因版本差异引入隐式问题。
总结
在大模型训练与微调流程中,权重格式转换是连接训练与推理的关键桥梁。本案例表明,即使参数配置正确,若前后转换脚本版本不一致,仍可能引发运行时异常。通过统一脚本版本、遵循文档规范,可有效规避此类问题。开发者在使用过程中,应始终关注转换脚本的一致性,确保训练与推理流程的无缝衔接。