TileLang AscendNPU IR从入门到专家算子开发知识点
发表于: 2026/05/08
DAY1 直播知识点总结
主题:TileLang接入MLIR——NPU算子高效开发新“捷径”
一. TileLang简介
TileLang AscendNPU IR对Ascend架构进行深度适配,能够让开发者像搭积木一样,控制算子在NPU的行为;同时前端与TileLang语法保持高度一致,尽可能降低开发复杂度和学习成本。
TileLang在设计之初,便针对不同使用人群对性能的诉求,设计了Beginner,Developer和Expert三种使用模式,可按需选择,兼顾易用性和极致性能。
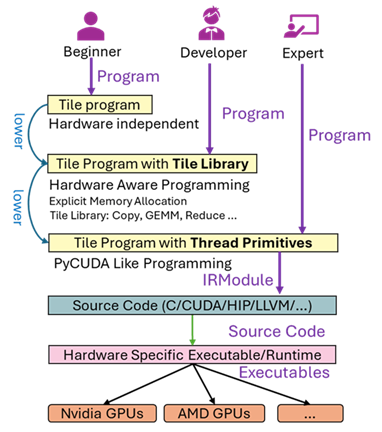
Beginner模式(Doing):为入门用户打造,使用体验极致简洁友好,无需关注硬件细节,上手门槛极低。
Developer模式(Ready):面向对硬件有一定了解的开发者,采用Tile级封装OP实现算子开发。在保持开发便捷性的同时,充分挖掘硬件算力潜力。
Expert模式(Ready):面向充分了解硬件的专家,使用更贴近硬件底层的精细开发,释放极致的硬件性能。
(一)自动内存推断
TileLang可根据运算,自动推导内存在硬件中的位置。
(二)自动向量化
TileLang可根据T.Parallel OP,对计算做自动向量化。
(三)自动流水并行
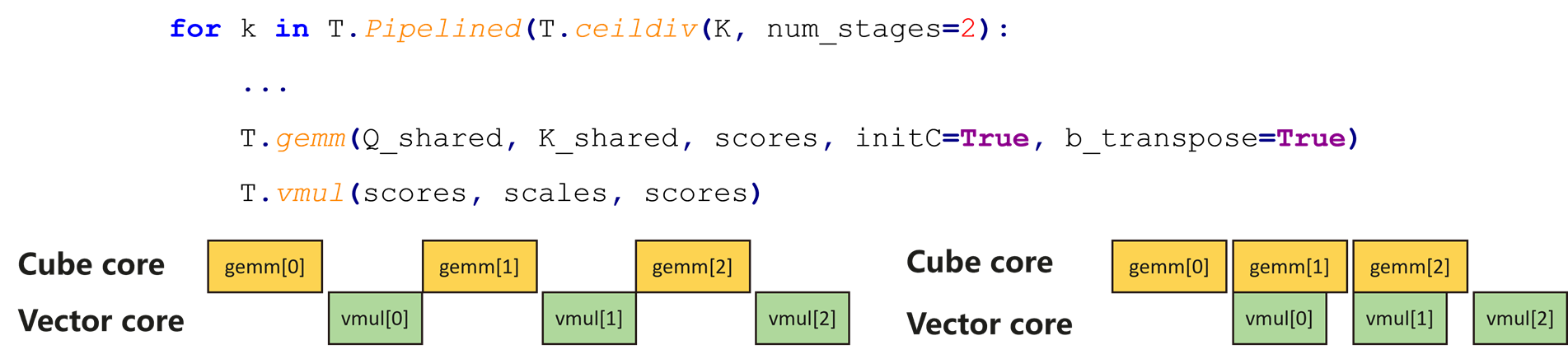
TileLang可自动流水并行,提高算子的性能。
(四)自动内存复用
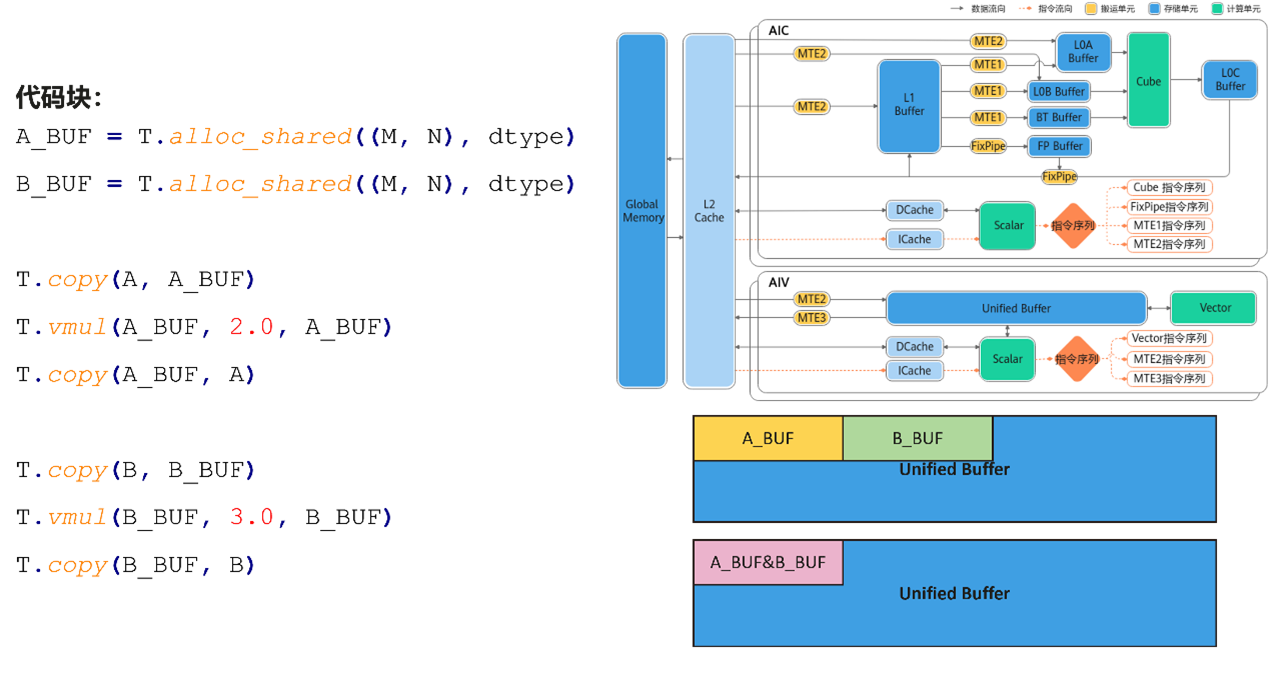
TileLang可自动实现内存复用,节省UB空间,使用户可以开出更大的tiling从而提高性能。
(五)自动同步插入
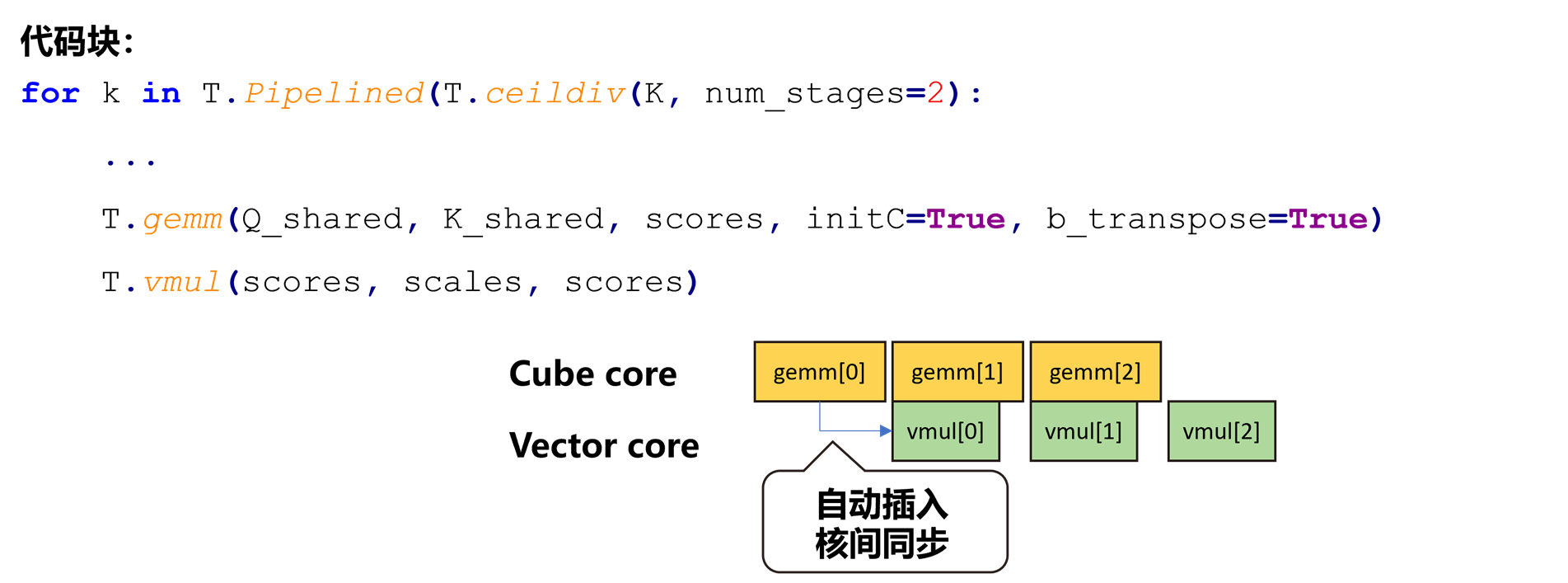
TileLang可自动插入核间同步,降低用户的使用门槛。
二. AscendNPU IR简介
(一) AscendNPU IR是什么
AscendNPU IR是基于MLIR构建,专为昇腾硬件设计的中间表示和编译器框架。
通过提供对昇腾的完备表达能力,丰富的编译器优化来充分发挥硬件的能力。
通过向开源社区开放接口,支持与生态框架的灵活集成。
技术价值的认可:
项目成功地将MLIR作为核心技术基础设施应用于解决某个特定领域的实际问题。
技术成熟度与活跃度的认可:
项目发展到了相对成熟的阶段,拥有稳定的代码库和活跃的开发者社区。它不再是实验性的,而是可以公开访问、被其他人借鉴和使用的项目。
(二) MLIR是什么
何为“摩尔定律的终结” (The End of Moore's Law)?
传统认知:摩尔定律通常指,集成电路上可容纳的晶体管数目,每隔约2年便会增加一倍。从而带来性能的倍增。几十年来,软件开发者几乎可以“免费”享受到硬件性能自然提升带来的好处。
当前挑战:如今,随着物理极限的逼近,这种“免费”的性能增长已难以为继。为了继续获得性能提升,产业界转向了异构计算——即在一个系统中集成多种专用处理器。
带来的问题:这些硬件的架构千差万别,编程模型也各不相同。为每一种新硬件编写和优化编译器,变得异常复杂、昂贵且耗时。这造成了软件开发的“碎片化”和效率瓶颈。
MLIR (Multi-Level Intermediate Representation)正是为驯服这种硬件复杂性而生的。它并没有直接让硬件变得更快,而是从根本上改变了我们为这些硬件编写和优化软件的方式。
(三) MLIR核心创新
1.方言(dialect)
MLIR 最核心的资产,一个逻辑容器,不同的抽象级别和计算领域被封装在特定的“方言”中。每种方言包含特定的操作(Ops)、类型(Types)、属性(Attributes)和pass。
典型方言:
a) TOSA(Tensor Operator Set Architecture):,为机器学习工作负载提供一套标准化、与框架无关且可移植的张量操作集合。
b) linalg:提供线性代数级别的操作(如矩阵乘、卷积),它在张量和循环之间架起了一座桥梁,是进行算子融合和循环优化的关键区域。
c) memref:提供对内存缓冲区的抽象,用于显式地管理内存分配、加载、存储等操作,是靠近底层的表示。
d) scf (Structured Control Flow):提供结构化的控制流操作,如scf.if/scf.for/scf.while,用于表达高级的循环和条件分支。
e) llvm:几乎与 LLVM IR 一一对应,是 MLIR 降低到 LLVM 的最后一级,可以无缝导出为 LLVM IR 供 LLVM 后端使用。
2. 渐进式降级(progressive lowering )
MLIR 不试图一步将高级语言降到机器码,而是通过一系列小步、可组合的转换,让IR在不同抽象层次间平滑过渡。每一步只做少量工作,保留部分语义,逐步暴露底层细节。例如tosa->linalg->memref->scf->llvm
传统编译器:固定几个IR层级(AST → 中间IR → 后端IR),抽象跳跃大,难以插入领域专用优化。
MLIR方式:允许自定义任意多层IR,优化可发生在最适合的层次,且转换Pass可复用。
(四) MLIR的生态应用
在一个性能提升依赖于硬件多样化的后摩尔时代,MLIR通过提供一个革命性、可复用/可扩展的编译器框架,来释放软件的生产力和硬件的潜能.
a) Torch-MLIR:连接PyTorch与MLIR生态
b) ONNX-MLIR:连接ONNX与MLIR生态
c) IREE(Intermediate Representation Execution Environment):基于 MLIR 的端到端编译器和运行时,可将模型降低为统一的IR,该IR可以向上扩展以满足数据中心的需求,向下扩展以满足移动和边缘部署的约束和特殊考虑.
d) CIRCT(Circuit IR Compilers and Tools) :基于 MLIR 的电路编译器和工具链,将MLIR的理念引入到硬件设计领域中,使用方言来描述电路(如Verilog)
e) Polygeist :一个创新的开源编译器项目,由 LLVM 社区开发,旨在提升C/C++代码的性能,通过将这些语言提升到MLIR表示形式,实现更高效的优化和跨平台移植。
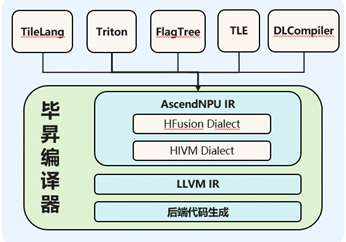
(五) AscendNPU IR架构与关键能力
架构
分层设计,灵活对接,完备表达
为生态框架提供面向昇腾的统一编译接入层和硬件完备表达优化能力
关键能力
多级抽象与易用性
提供高层抽象接口,屏蔽昇腾计算、搬运、同步等指令细节,编译器自动感知硬件架构并将硬件无关表达映射到底层指令;
同时提供细粒度性能控制接口,可精准控制片上内存布局、流水同步插入位置、是否使能乒乓流水等,兼顾易用与性能调优。
分层方言与编译优化
a) HFusion:基于 Linalg 扩展,负责硬件相对无关的优化与生态对接;支持与 Arith、Math、Torch 等方言的转换,以及 Tensor 化简、类型合法化、算子融合生成。
b) HIVM:面向昇腾对计算、搬运、同步进行 Tile 级抽象,屏蔽底层指令参数;负责CV 核映射(Mix Kernel 的 CV 融合、核间同步、CVPipeline 流水与 AutoSubTiling 等)、核内片上内存映射与多级流水/指令映射。
c) HACC:异构硬件抽象,表达 Host/Device 编程模型与 launch 语义;
d) Annotation、Scope 等用于 compiler hint 与作用域标记。
关键编译特性支持 CV 融合与流水(CVPipeline、AutoSubTiling)、自动内存规划(PlanMemory)与流水同步(AutoSync)、块化与调度(AutoBlockify、AutoFlatten、AutoSchedule),以及自定义算子、DFX、CV 优化等,便于在保持高层语义的前提下获得可移植性能。
生态对接与开放通过分层接口支持与 PyTorch(Torch-MLIR)、TileLang、Triton 及各类框架的对接,高性能与易用性灵活平衡,高效使能昇腾 AI 处理器。
DAY2 直播知识点总结
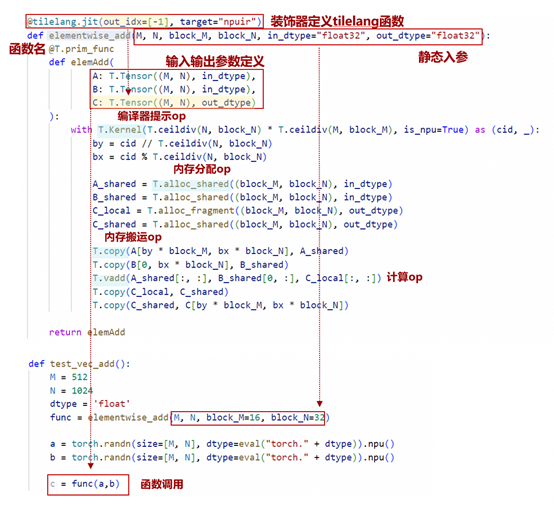
(一):TilelangOp指导手册
Tilelang代码编写结构示例如下:
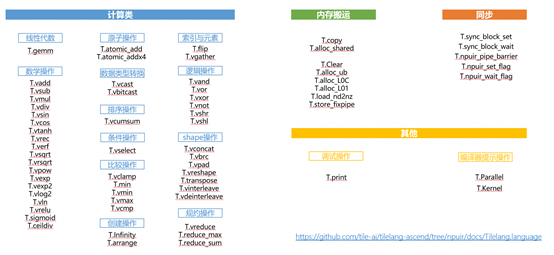
Tilelang op分类
-计算
-内存分配和搬运
-同步
-其他
https://github.com/tile-ai/tilelang-ascend/tree/npuir/docs/Tilelang.language
(二):MiniCV算子
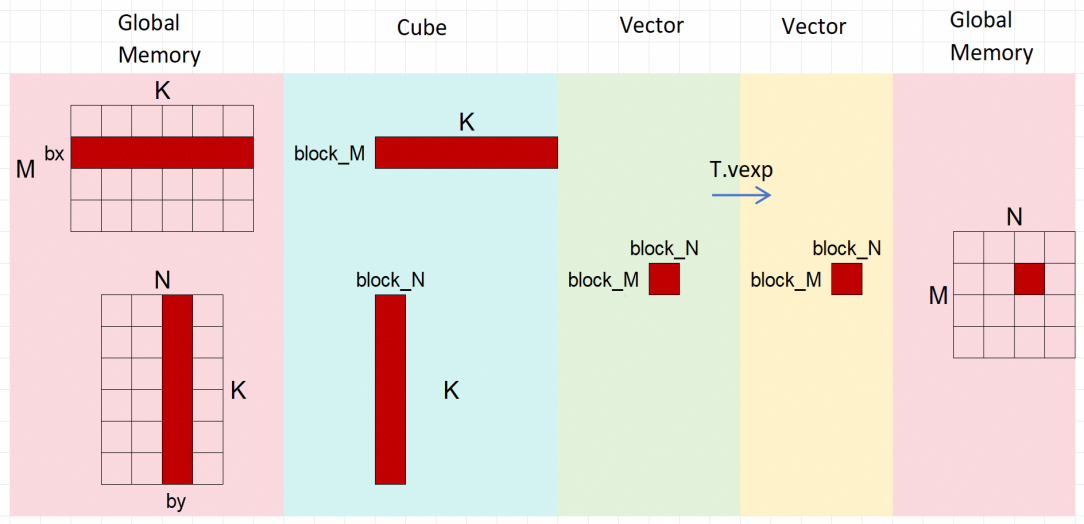
MiniCV算子是一个具有代表性的简单融合算子,结合了矩阵乘法(GEMM)和指数激活函数(Exp),使用了数据分块的思想。下面是GEMM算子的kernel代码:
@tilelang.jit(target="npuir")
def minicv(M, N, K, block_M, block_N):
m_num = M // block_M
n_num = N // block_N
@T.prim_func
def minicv(
A: T.Tensor((M, K), dtype),
B: T.Tensor((K, N), dtype),
C: T.Tensor((M, N), inner_dtype),
D: T.Tensor((M, N), inner_dtype),
):
with T.Kernel(m_num * n_num, is_npu=True) as (cid, _):
bx = (cid // n_num) * block_M
by = (cid % n_num) * block_N
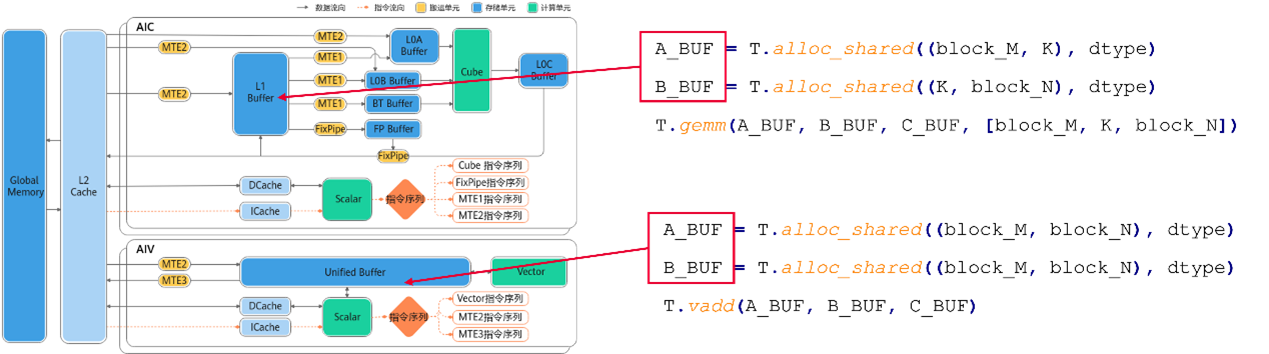
A_BUF = T.alloc_shared((block_M, K), dtype)
下图是对GEMM的CV融合计算、分块思想的图解:
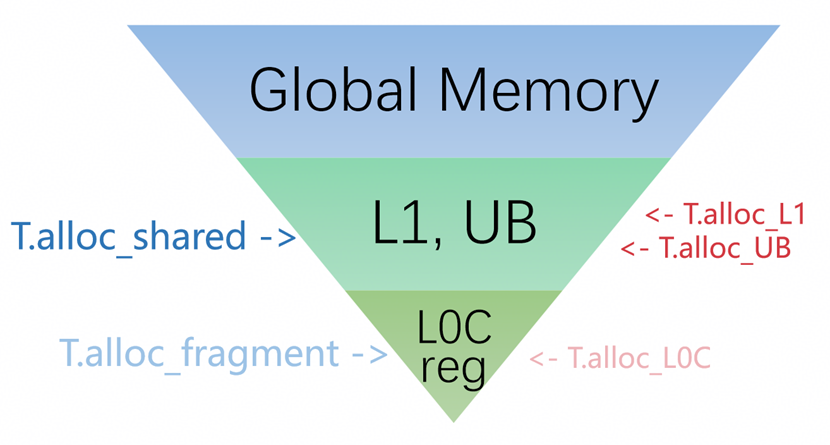
1. T.alloc_*
T.alloc_shared: 映射到L1/UB 高速缓存,存放需要复用的Tile数据
T.alloc_fragment: 映射到 L0C/寄存器,存放计算过程临时结果
Ascend NPU内存层次以及语法对应:
2. T.copy
T.copy 使用方法:
...
T.copy(A[bx : bx + block_M, 0 : K], A_BUF[0:block_M, 0:K])
T.copy(B[0 : K, by : by + block_N], B_BUF[0:K, 0:block_N])
T.copy 语句特色:
1. 支持 Host, Shared, Fragment 相互拷贝
2. Numpy风格切片索引,所见即所得
3. 编译器自动识别切片范围
4. C核V核一套Copy,编译器自动生成对应DMA指令
5. 支持动态维度
6. 支持隐式数据类型转换
(三): Softmax demo和ParallelOp, ReduceOp, T.Kernel
Tilelang softmax代码如下

优点:易用易读:内存分配和搬运以tile语义表达,易写易读(不需要triton地址偏移计算);Parallel: 自动实现循环迭代并行化,用户编写逻辑近python语义(标量索引)
1. T.kernel(内核启动)
定义内核启动域的上下文构造接口。写法:T.Kernel(blocks, threads, is_cpu, prelude, is_npu, pipeline);NPU上的通用写法: with T.kernel(BLOCK_SIZE, is_npu = True) as (cid, _ )
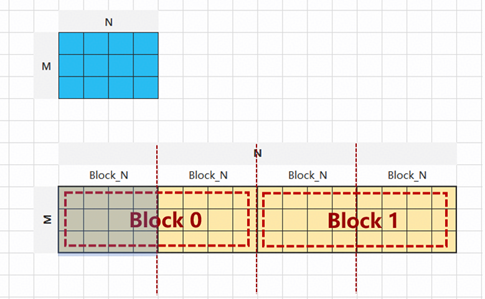
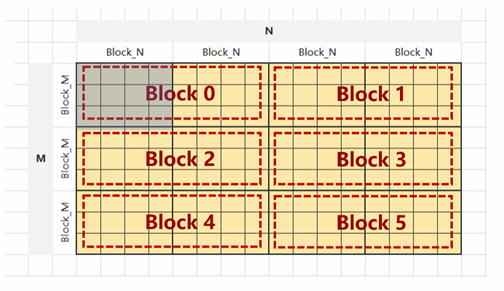
BLOCK SIZE: 启用的逻辑核数量;假设物理核数是24,则当逻辑核=24,实际24个物理核启动1次;当逻辑核=48,实际24个物理核启动2次; 当逻辑核=54,实际24个物理核启动2次+6个 物理核启动1次 (54=24*2+6)。
BLOCK_SIZE不同情况如下图

当1个Kernel内需要处理多个数据块,比如2个[M,block_N]大小的数据块,可以用 T.serial在Kernel内建立内层循环

从1个Kernel处理[M,N]变成1个Kernel处理(N// Block N)次循环, 每个循环处理[M,Block N]。
这里假设两种场景:
场景一:
BLOCK_SIZE=2(启动2个逻辑核),循环计算总数 num_n = N // Block_N(4),每个Kernel内需要做ceildiv(num_n, BLOCK_SIZE) 次循环(2)
场景二:
BLOCK_SIZE=6(启动6个逻辑核);num_m = N // Block_M(4) ;num_n = N // Block_N(3) ;循环计算总数 num_m * num_n (12) ,每个Kernel内需要做ceildiv(num_m * num_n, BLOCK_SIZE)次循环(2)
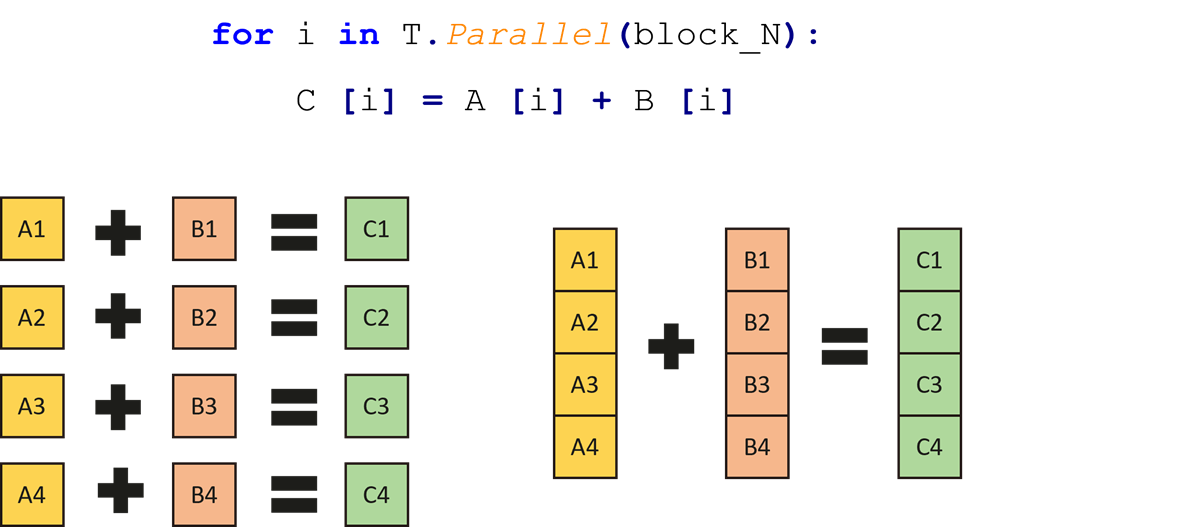
2. ParallelOp:自动并行化
以Tile为单位的自动向量化运算:元素级别运算并行;各元素运算之间独立无依赖
T.Parallel->NpuLoopVectorize()
将for循环+下标索引的标量操作(a[i]+b[i])转换为向量化操作(T.npuir_add(a, b))
T.Parallel 目前已支持标量操作为:
• 指数计算:T.exp
• 加减乘除:使用 +, -, *, /
• sigmoid:T.sigmoid
• 广播:T.vbrc
• 比较操作:使用 ==, !=, <, <=, >, >=
• 条件分支:T.if_then_else

3. ReduceOp:规约操作
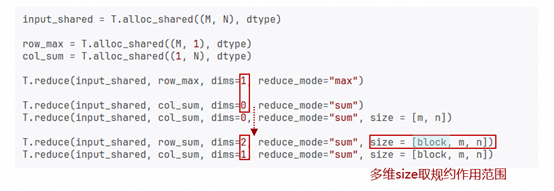
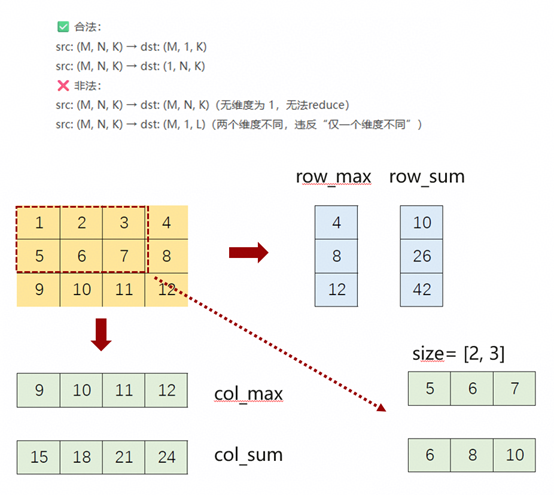
T.reduce:对张量在指定维度上进行聚合运算(如 sum、max、min 等),将多个元素压缩为更少元素或标量的操作,写法如下:T.reduce(src, dst, dims=1, reduce_mode="sum", clear=True, size=[m,n]) T.reduce_max(src, dst, dim=0, clear = False)其中size:控制 reduce 实际参与计算的数据范围,clear: 是否在reduce前对目标张量进行初始化。
DAY 3 FlashAttention(TileLang实现)知识点总结
一、Attention 与 FlashAttention 核心计算
标准 Attention 计算由四个阶段组成:首先计算 Q⋅K^T 得到相似度矩阵,其次进行缩放以稳定数值分布,然后根据需要施加 mask(如 causal mask),接着通过 softmax 转换为概率分布,最后与 V矩阵相乘得到输出结果。

FlashAttention 的核心优化在于重构计算顺序,不再显式构造完整的QK^T矩阵,而是采用分块(tiling)方式逐块计算,并在计算过程中完成 softmax 的归一化,从而将显存复杂度降低。
二、Online Softmax 数值稳定机制

在处理每个新分块时,先计算当前块的局部最大值,并与历史最大值比较得到新的全局最大值;然后基于指数函数计算修正因子,用于对历史累积结果进行重标定:接着对当前分块进行指数归一化并更新分母;最后同步更新输出累积值。该机制确保即使在分块计算中也能得到与标准softmax等价的结果,同时避免数值溢出问题。
三. TileLang 编程模型关键能力自动软件流水
TileLang 提供以 tile 为核心的计算表达方式,通过 T.Kernel 定义 block 级计算逻辑,使开发者可以直接描述 NPU 上的执行单元行为,而无需关注线程级细节。矩阵计算通过 T.gemm 表达,向量运算通过一系列 T.v* 指令完成,整体表达更贴近硬件执行模型。
在内存管理方面,TileLang 支持显式控制不同层级的数据存储,包括通过 T.alloc_shared,T.alloc_fragment 使用定义内存,并通过 T.copy 控制数据搬运路径。这种方式可以最大化利用带宽并减少不必要的数据访问开销。
执行模型上,TileLang 支持 pipeline 机制,通过 T.Pipelined 将数据加载与计算阶段重叠执行,从而隐藏内存访问延迟,提高整体吞吐率。这种机制对于 FlashAttention 这种带有明显数据复用和分块特征的算子尤为关键。
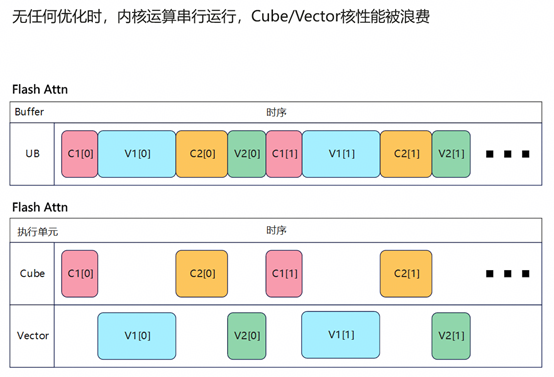
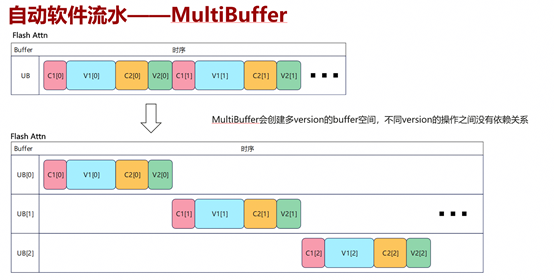
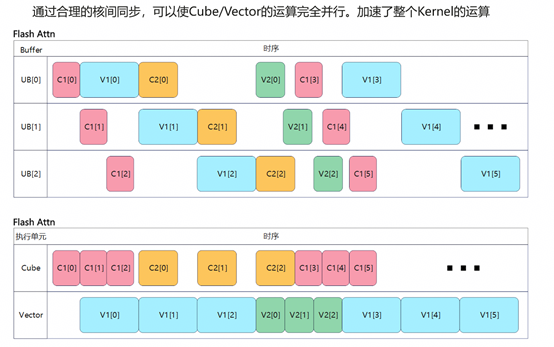
四、TileLang 算子调试方法体系
TileLang 算子调试主要分为三类问题。第一类是精度问题,即算子能够成功运行但结果与参考显示不一致,此时通常通过T.print打印关键中间变量(如scores、最大值和分母)进行定位。第二类是编译失败,表现为无法生成IR或目标代码,通常需要检查shape、数据类型以及API使用是否符合规范。第三类是运行时失败,即编译成功但执行崩溃,这类问题通常与内存访问越界或pipeline依赖错误有关。
针对编译阶段问题,可以使用 debug 版本的编译工具进行全量 pass 打印,查看从高层 IR 到底层 IR 的每一步转换过程,从而定位具体是哪一个优化或 lowering 过程引入了错误。这种方法对于复杂算子的调试具有决定性作用。
DAY 4 从FA算子掌握性能优化方法
一. 从开发者模式向专家模式的迁移
STEP1 – 申请缓存
目的:将泛用缓存申请接口T.alloc_shared和T.alloc_fragment根据昇腾架构修改为T.alloc_ub, T.alloc_L1, T.alloc_L0C。
示例:
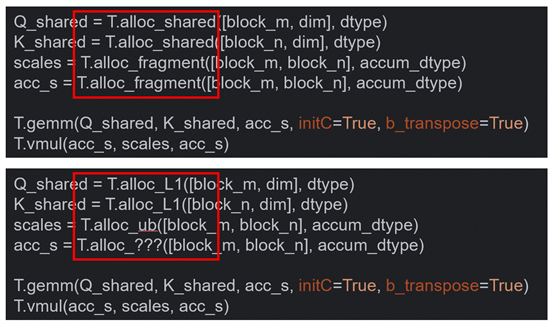
STEP2 – 插入workspace
目的:当前昇腾架构上ub和L1/L0之间的数据无法直接相互拷贝,因此对于同时需要用在ub和L1/L0上的数据需要申请两份缓存,且通过插入workspace来进行互相之间的拷贝。
示例:

STEP3 – CV分核
目的:根据昇腾架构区分矩阵核心的接口和向量核心的接口,分别放在两个不同的表示核心类型的上下文管理器中。
示例:
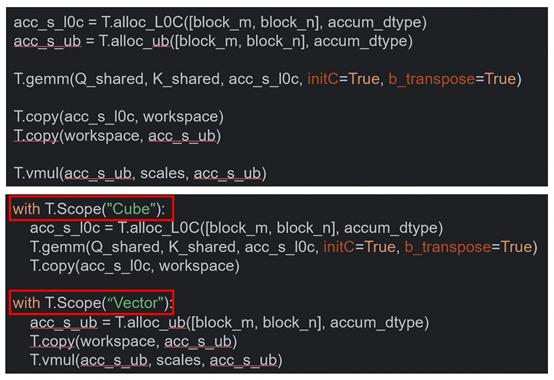
STEP4 – 核间同步
目的:分核之后需要通过核间同步正确控制计算流程
示例:
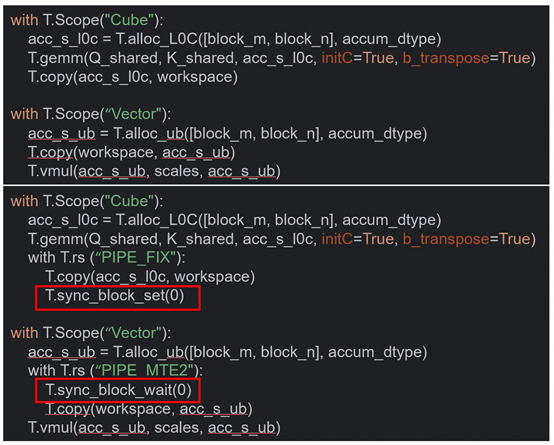
STEP5 – 双向量核心(VV分核)
目的:通过让两个向量核心各处理一半的数据来充分利用双向量核心,提升性能。
示例:
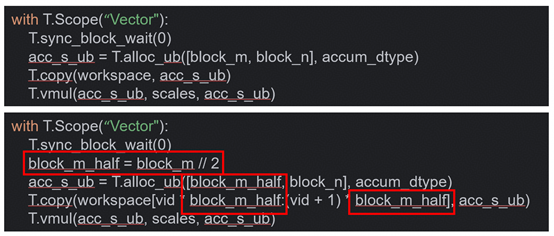
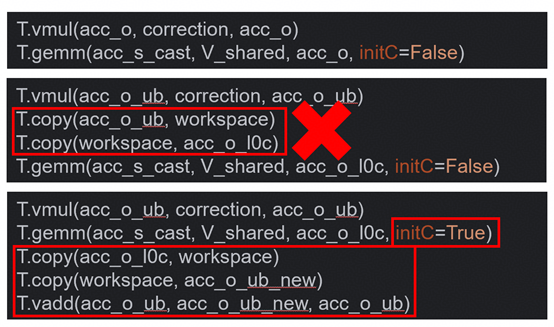
STEP6 – 处理硬件特例
目的:额外处理由于L0C不接受直接数据写入的硬件特例
示例:
二. 专家模式算子性能优化
手写FA算子:
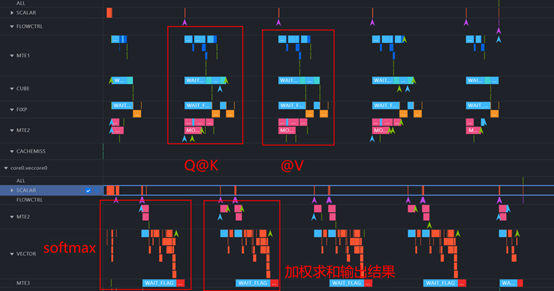
通过msprof op simulator命令查看流水
能够发现其完全是CV串行,有很多空泡,需要进行优化。
优化方案:
下图为例,算子执行两轮循环,通过手动排流水,
C核将QK矩阵乘连续执行两次,V核softmax操作也连续执行两次
V核在做第一次softmax操作时, C核就可以进行第二次QK矩阵乘
空泡被填充
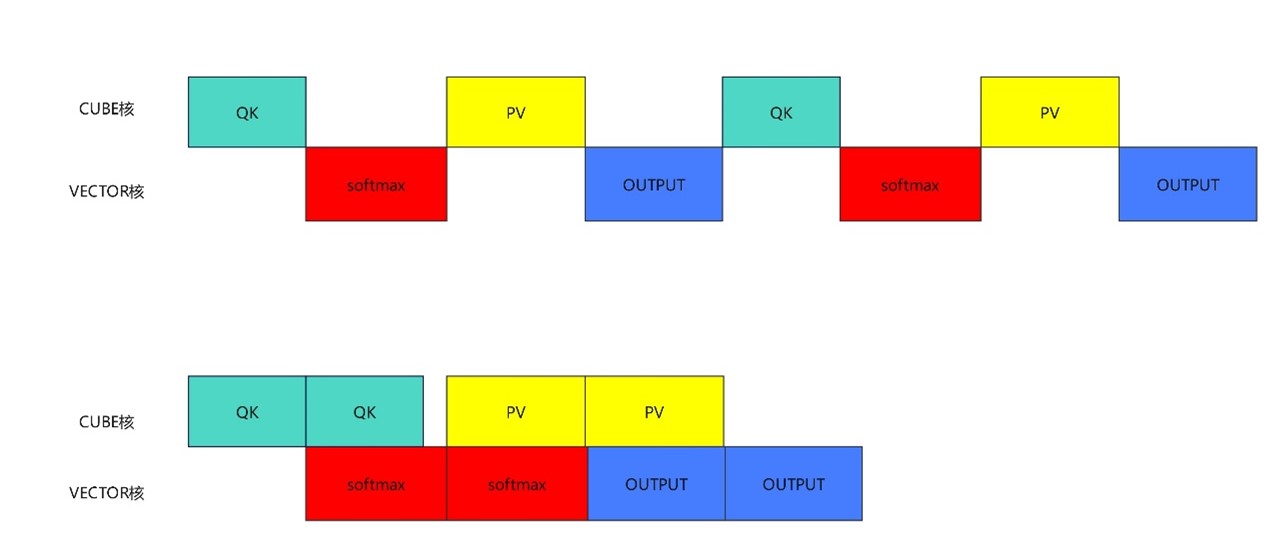
方案结果:
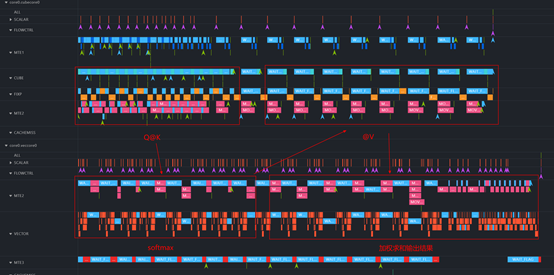
空泡基本能被填满
手写算子性能:44.9us
优化后性能:22.28us
性能大幅提升
结合芯片架构看流水:
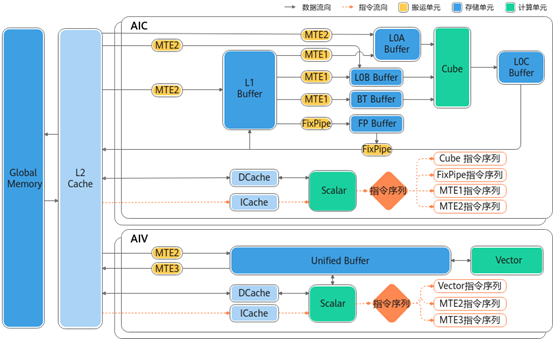
搬运指令
MTE2: GM->UB
MOVE_OUT_TO_L1_MULTI_ND2NZ
MTE3:UB->GM
MOV_SRC_TO_DST_ALIGN
FixPipe:L0C->GM
FIX_L0C_TO_DST
计算指令:
CUBE计算: MMAD
VECTOR计算: VEXP, VSUB…
SCALAR计算: MOVK, INSERT_XD…
同步指令:
SET_FLAG、WAIT_FLAG
DAY5直播知识点总结
一. Jit编译核心概念
TileLang-Ascend是基于TVM的Ascend NPU张量计算框架,通过JIT编译将Python DSL代码转换为NPU二进制。
1. 编译流程概览
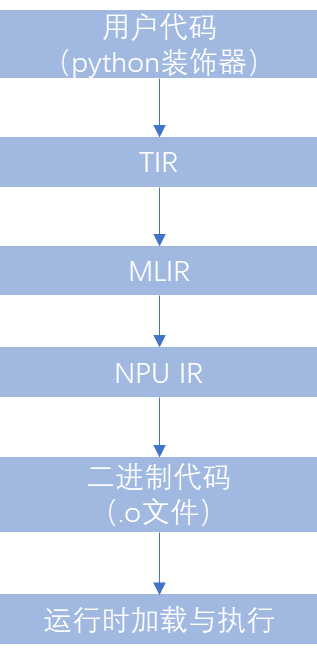
2. 核心文件
文件 | 路径 | 功能描述 |
jit_npu.py | tilelang/jit/jit_npu.py | NPU JIT编译核心实现 |
lower.py | tilelang/engine/lower.py | TIR到MLIR的转换 |
phase.py | tilelang/engine/phase.py | 编译Pass调度 |
npu_utils.py | tilelang/utils/npu_utils.py | NPU工具函数 |
npu_utils.cpp | tilelang/utils/npu_utils.cpp | NPU底层C++接口 |
二. 整体架构
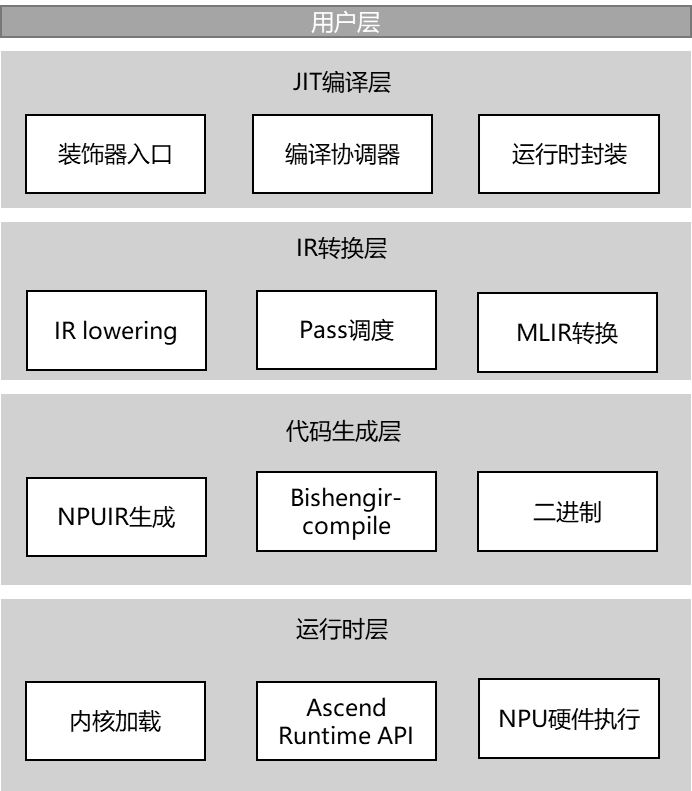
三. 编译流程核心步骤
1. 前端处理
参数信息提取:从PrimFunc提取张量参数的dtype、shape和is_output信息
符号变量提升:将动态形状中的符号变量提升为函数参数
网格信息解析:提取blockIdx.x作为并行执行的网格维度
2. TIR转换与优化
LowerAndLegalize阶段:
- 绑定目标设备
- 简化IR表达式
- 移除空操作
OptimizeForTarget阶段:
- NPU循环向量化
- Buffer分配位置规划
- 降低不透明块
3. NPU代码生成
MLIR → NPU IR:通过tladapter passes转换 (包含NPU定制优化pass)
NPU IR → 二进制:使用bishengir-compile编译器
关键编译选项:
- --enable-auto-multi-buffer=true:自动多缓冲区优化
- --enable-triton-kernel-compile=true:Triton风格内核编译
- --enable-hivm-compile=true:HIVM编译流程
4. 包装器生成
生成C++包装器代码,包含:
- 参数结构定义
- 内核启动函数
- Python调用入口
四. TileLang Ascend Operators 开发者教程
1. 快速开始
安装与使用

2. 新增算子开发流程
新增一个算子需要完成以下步骤:
Step 1: 编写内核定义
在 compile/kernels/ 目录下创建内核定义文件,例如 compile/kernels/new_op.py:

Step 2: 注册内核到编译脚本
在 compile/kernels/__init__.py 中注册新内核:

Step 3: 编写算子定义
在 src/ops/ 目录下创建算子定义文件,例如 src/ops/new_op.py:

Step 4: 注册算子
在 src/registry.py 中注册新算子:

Step 5: 导出 Python API

Step 6: 编写测试
在 tests/ 目录下创建测试文件,例如 tests/test_new_op.py:

Step 7: 预编译和测试
3. 开发原理
架构概览

为什么需要预编译?
1. 消除编译时依赖
TileLang 编译内核需要:
- tilelang 源码
- Bisheng 编译器(华为 Ascend 编译器)
- g++ 编译器
- TVM 框架
预编译后,运行时只需要:
- PyTorch
- torch_npu
2. 提高部署效率
阶段 | 编译时 | 运行时 |
编译内核 | 分钟级 | - |
加载内核 | - | 毫秒级 |
3. 保护知识产权
预编译后的 .so 文件是二进制格式,无法直接查看源码。
预编译产物说明
metadata.pkl
包含内核运行所需的所有元数据:
main.so
启动器,包含 launch 函数,负责:
· 接收参数
· 调用内核执行
npu_utils.so
工具库,包含:
- load_kernel_binary: 加载内核二进制到设备
- 其他 NPU 运行时工具函数
五. 算子接入DeepSeek V4
DeepSeek V4已于4月24日发布,TileLang AscendNPU IR已经完成了0Day算子接入,接入后的DeepSeek V4发布在tilelang-mlir-ascend github代码仓的examples目录下,地址如下所示:
https://github.com/tile-ai/tilelang-mlir-ascend/tree/main/examples/deepseek_v4
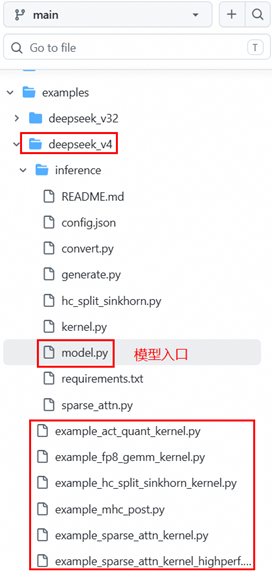
其中,example_xxx.py就是基于TileLang AscendNPU IR实现的相关算子,inference/model.py是模型的入口文件。
通过简单的2行import即可将基于TileLang AscendNPU IR实现的算子,接入到DeepSeek V4,如下图所示:
下面是执行python inference/model.py后的效果。