



基于昇腾的多模态模型VeRL训练性能优化实践
发表于: 2026/03/26
概述
随着多模态大模型在金融、医疗、教育等领域的广泛应用,其智能化能力的持续提升成为推动行业数字化转型的核心驱动力。在此背景下,基于人类反馈的强化学习(RLHF)技术逐渐成为大模型后训练的关键路径。以GRPO为代表的群组生成强化学习算法,通过利用群体生成数据进行策略优化,显著提升了模型的对齐能力与泛化性能。然而,该类算法在推理阶段引入大量生成耗时,加之长尾样本导致的资源闲置问题,使得整体训练效率面临严峻挑战。
本文基于VeRL开源框架,针对Qwen3-VL-8B模型在昇腾Atlas 800T A2硬件平台上的GRPO后训练流程,系统性地开展性能瓶颈分析与优化,通过推理与训练双路径协同调优,实现端到端性能提升30%。
一、背景与挑战
传统监督微调(SFT)与偏好对齐方法受限于数据采集成本与标注质量,已难以满足多模态模型持续进化的需要。GRPO算法通过群组生成机制,利用多轮采样与奖励反馈实现策略优化,为模型能力拓展提供了新范式。然而,该流程在每轮训练中需执行多次推理生成(rollout),导致推理阶段耗时显著增加,形成“推理瓶颈”。
在实际部署中,我们观察到以下典型问题:
- 推理阶段时间占比超过训练阶段,整体系统呈现“推理绑定”(Inference-bound)特征;
- 长尾样本(如长序列生成)持续占用计算资源,造成短样本请求资源空置;
- 框架底层算子未充分融合,通信与计算重叠不足,Host端算子下发效率低下;
- 缺乏对关键算子(如RMSNorm、Mrope)的NPU原生优化支持。
上述问题严重制约了强化学习后训练的吞吐效率,亟需从框架、算子、调度等多维度进行系统性优化。
版本环境
- vLLM-Ascend: v0.11.0
- CANN: 8.3.RC1
- VeRL: 0.6.1
GRPO算法介绍
GRPO算法流程不再赘述,参考论文https://arxiv.org/pdf/2402.03300,示意图与损失函数如下:
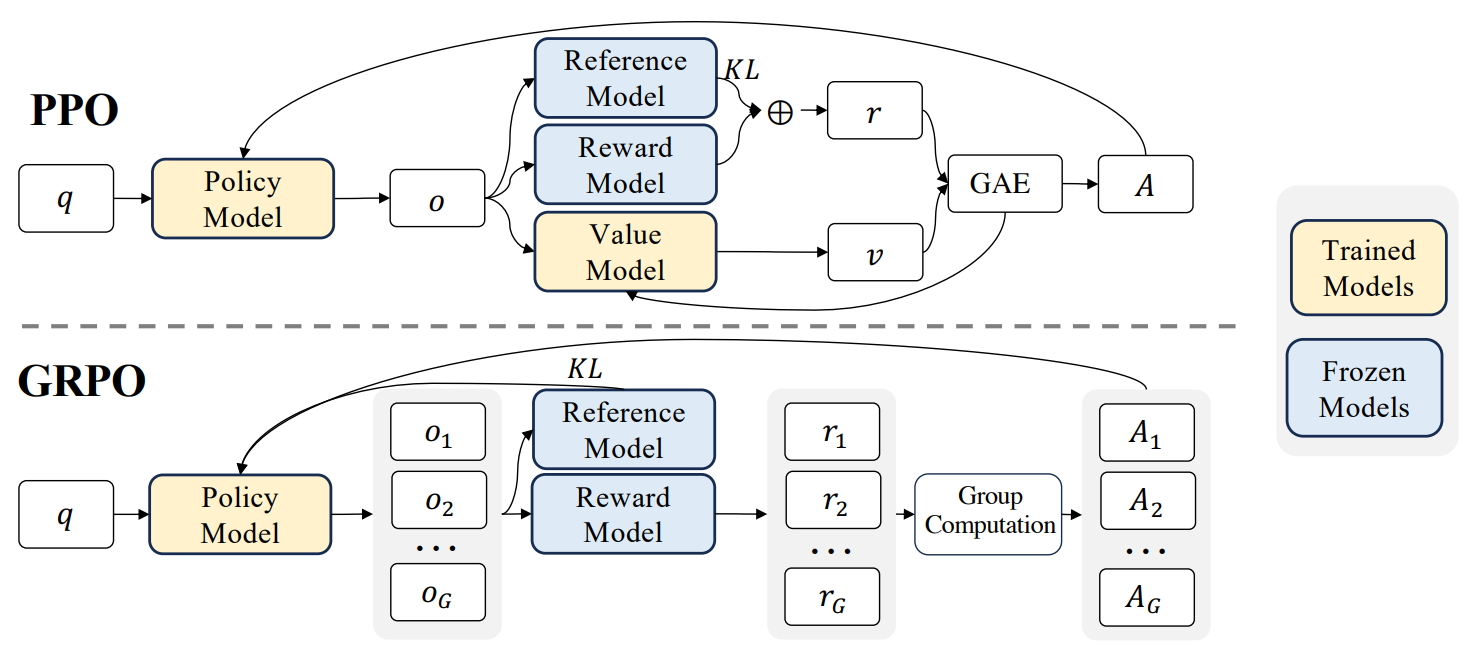
大致有如下几个步骤:
- 首先进行 rollout推理采样,采集满足样本数量要求的sample样本
- 对样本进行奖励reward计算
- 计算old_logp值
- 利用reward 奖励模型,在计算样本组内(o1,o2,…,oG)分别计算优势值 Adv
- 利用 Adv、old_logp 计算loss目标函数,从而进行模型参数的更新训练。
VeRL NPU性能数据采集
为了针对性能问题进行定向分析,我们需要借助Ascend PyTorch Profiler获取更细粒度的性能数据。
Ascend PyTorch Profiler是针对PyTorch框架开发的性能分析工具,通过在PyTorch训练/在线推理脚本中添加相关采集逻辑,执行训练/在线推理的同时采集性能数据,并在完成训练/在线推理后直接输出可视化的性能数据文件。相关修改目前已集成在VeRL框架中,只需在训练开始前设定所需参数即可启用性能采集功能。
VeRL框架下相关使用说明可见昇腾profiling,功能启用与相关配置参数均位于verl/trainer/config/ppo_trainer.yaml。框架使用两级profile设置控制数据采集,由global_profiler控制采集步数和采集模式(npu、torch等),由各角色自身的profiler配置控制具体采集内容和采集粒度。
global_profiler:
steps: [1, 2, 5]
save_path: ./outputs/profile
actor_rollout_ref:
actor: # 设置 actor role 的 profiler 采集配置参数
profiler:
enable: True
all_ranks: True # 控制采集设备
tool_config:
npu:
discrete: False # 离散采集或端到端全量采集
contents: [npu, cpu] # 可选采集信息列表
analysis: True # True为在线解析,False离线解析
考虑到强化学习流程复杂,高采集粒度下原始文件较大、采集时间长,可以考虑使用离线解析的方法。具体参考链接性能数据采集。
from torch_npu.profiler.profiler import analyse
if __name__ == "__main__":
analyse(profiler_path="./result_data", max_process_number=max_process_number)
二、性能瓶颈分析
为精准定位性能瓶颈,我们基于Ascend PyTorch Profiler工具采集了完整训练流程的性能数据,并结合端到端时间分布与算子级耗时进行深度分析。
2.1 训推性能失衡,推理成为关键瓶颈
对比训练与推理阶段的总耗时,发现推理阶段时间占比达58%,远超训练阶段。尤其在rollout生成环节,前向推理耗时占据主导,表明系统整体性能受限于推理能力。
2.2 框架版本特性缺失,关键优化未启用
经核查,当前使用的vLLM-Ascend版本为0.11.0,虽已支持v1引擎与chunked_prefill等优化,但部分关键特性需显式启用。若未开启,将导致前向推理延迟显著增加。
2.3 算子融合策略未完全启用
Profiling分析显示,多个常见算子组合(如matmul + add + bias)未被融合,导致中间结果频繁写回内存,增加带宽压力。此外,推理侧allreduce与matmul之间存在可掩盖的计算与通信开销,未使用mc2融合算子实现通算掩盖。
2.4 Host端Free时间过高,存在Host-bound现象
性能数据中“Free”时间占比超过25%,表明Host端算子下发存在延迟,任务调度效率低下。推测为CPU资源未有效利用,上下文切换频繁所致。
2.5 推理图模式未启用,调度开销大
当前推理流程未开启图模式(Graph Mode),导致每个推理请求均以逐个kernel提交方式执行,调度开销高。同时,二级流水下发(TaskQueue Level 2)与图模式存在冲突,无法共用。
2.6 推理随机性引发拖尾效应
GRPO算法天然具有高随机性,导致相同输入下生成长度差异大。长样本请求长时间占用资源,形成“拖尾”现象,严重拉低整体吞吐。
三、性能优化方案与实践
3.1 通用优化项
3.1.1 RMSNorm融合算子优化
RMSNorm作为大模型中高频使用的归一化操作,其原始实现常以多步自定义方式完成,影响执行效率。通过Ascend PyTorch Adapter集成RMSNorm融合算子,将多个操作合并为单一算子,减少数据传输与临时存储。
针对Qwen3-VL系列模型,需手动在`verl/models/transformers/npu_patch.py`中注入优化逻辑:
from transformers.models.qwen3_vl import modeling_qwen3_vl
from transformers.models.qwen3_vl_moe import modeling_qwen3_vl_moe
modeling_qwen3_vl_moe.Qwen3VLMoeTextRMSNorm.forward = rms_norm_forward
modeling_qwen3_vl_moe.apply_rotary_pos_emb = apply_rotary_pos_emb_qwen3_npu
modeling_qwen3_vl.Qwen3VLTextRMSNorm.forward = rms_norm_forward
modeling_qwen3_vl.Qwen3VLTextMLP.forward = silu_forward
该优化已合并至VeRL主干(PR #4186),可直接使用。
3.1.2 Task Queue流水下发优化
为缓解Host-bound问题,启用一级流水下发机制,通过多级算子队列批量提交任务,提升设备利用率。
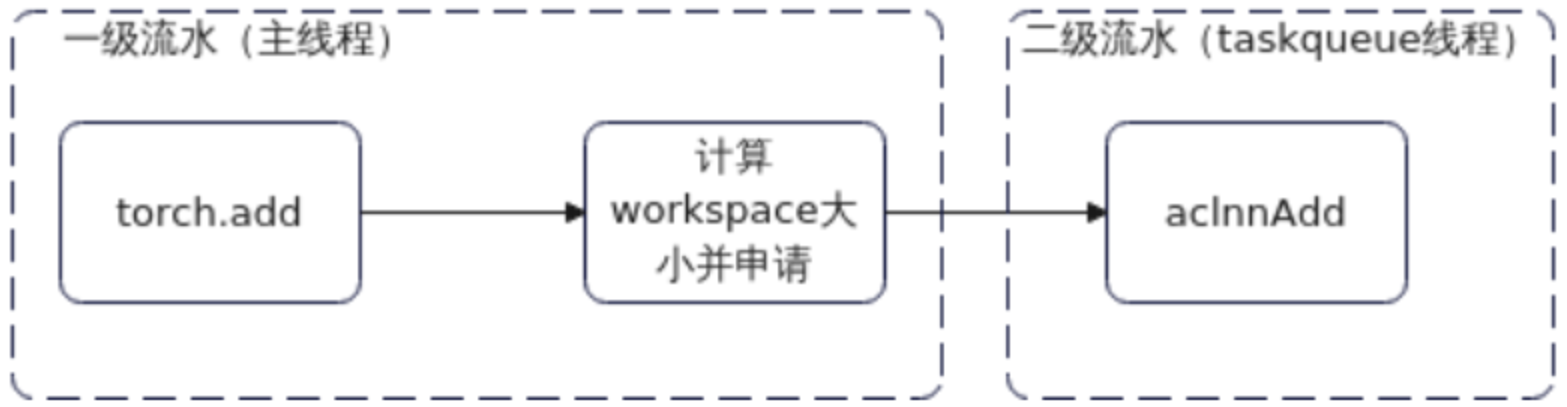
开启方式:
export TASK_QUEUE_ENABLE=1实测性能提升约9%,有效降低Free时间占比。
3.2 训练性能优化(FSDP后端)
3.2.1 动态BatchSize:缓解序列长尾负载不均
在训练阶段,不同batch间序列长度差异显著,导致DP域内负载不均。启用动态BatchSize机制,根据token长度动态打包样本,提升显存利用率与计算效率。
配置方式:
use_dynamic_bsz: true
ppo_max_token_len_per_gpu: 2 * (max_prompt_len + max_response_len)
log_prob_max_token_len_per_gpu: 4 * (max_prompt_len + max_response_len)该优化使端到端性能提升约15%,且可与`entropy_chunking`功能叠加使用,避免OOM问题。
3.2.2 权重预取:通算掩盖提升训练效率
通过开启前向参数预取,提前发起下一层权重的all-gather操作,实现计算与通信的重叠。
配置项:
actor_rollout_ref.actor.fsdp_config.forward_prefetch: true
actor_rollout_ref.ref.fsdp_config.forward_prefetch: true
该机制显著减少等待时间,提升整体训练吞吐。
3.3 推理性能优化
3.3.1 mc2融合算子:通算掩盖提升Matmul性能
mc2(Matmul + AllReduce)融合算子通过将计算与通信流水线化,实现时间掩盖。其核心思想是将输入矩阵沿M轴切分,使第二块的Matmul计算与第一块的通信并行执行。
启用方式:
export VLLM_ASCEND_ENABLE_MATMUL_ALLREDUCE=1需确保vLLM-Ascend版本 ≥ 0.10.0。实测性能提升8%。
3.3.2 Mrope逻辑替换:替代小算子,减少ViewCopy开销
Qwen3-VL系列模型采用Mrope位置编码,其原始实现依赖大量小算子(如view、copy),导致AI-CPU算子占比高,性能瓶颈明显。
优化策略:
1、不同层中的apply_interleaved_rope存在重复计算,提前cache避免重复计算
2、适配npu_rotary_mul,替代apply_rotary_emb_dispath算子
修改关键逻辑如下:
def forward_native():
if is_first_layer:
cos_sin = self.cos_sin_cache[positions]
cos, sin = cos_sin.chunk(2, dim=-1)
if self.mrope_interleaved:
cos = apply_interleaved_rope(cos, self.mrope_section)
sin = apply_interleaved_rope(sin, self.mrope_section)
cos = cos.repeat(1, 2)
sin = sin.repeat(1, 2)
self.cos = cos.unsqueeze(0).unsqueeze(-2).contiguous()
self.sin = sin.unsqueeze(0).unsqueeze(-2).contiguous()
forward_context.is_first_layer = False
query_shape = query.shape
query = query.view(num_tokens, -1, self.head_size)
query_rot = query[..., :self.rotary_dim]
query_pass = query[..., self.rotary_dim:]
query_rot = query_rot.unsqueeze(0)
query_rot = torch_npu.npu_rotary_mul(query_rot, self.cos, self.sin, "half").squeeze(0)
query = torch.cat((query_rot, query_pass), dim=-1).reshape(query_shape)
优化后ViewCopy算子占比下降超40%,端到端性能显著提升。
四、总结与展望
本文围绕GRPO强化学习后训练流程,系统性地开展了基于昇腾A2平台的性能优化实践。通过融合算子替换、图模式启用、流水下发、动态BatchSize、权重预取等多维度优化,成功将端到端训练性能提升30%。关键优化点包括:
- 推理侧:mc2融合、Mrope逻辑替换、图模式启用;
- 训练侧:动态BatchSize、前向预取;
- 框架层:RMSNorm融合、Task Queue流水优化。
未来,随着VeRL框架对多模态引擎VeoMni的集成(PR #4850),将进一步拓展在复杂多模态任务中的性能潜力。我们持续推动昇腾生态下的强化学习技术落地,欢迎开发者参与共建。
附:资源链接
- 昇腾后训练强化学习最佳实践:https://mp.weixin.qq.com/s/TnilRFlpGQkfGQFBDX-wYw
- 昇腾技术文档:https://www.hiascend.com/zh/developer/techArticles/20251107-1
- 昇腾后训练强化学习Docker镜像:https://www.hiascend.com/developer/ascendhub/detail/2c7122f323f94a19ba7fca6b8dccf11e
- 昇腾开源微信小助手:ascendosc
- VeRL开源社区讨论区:https://github.com/volcengine/verl/discussions