



openJiuwen上手指南,助你轻松打造专属智能体
发表于: 2026/03/25
1 非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
2 openJiuwen智能体平台简介
openJiuwen作为开源Agent平台,致力于提供灵活、强大且易用的AI Agent开发与运行能力。基于该平台,开发者可快速构建处理各类简单或复杂任务的AI Agent,实现多Agent协同交互,高效开发生产级可靠AI Agent;并助力企业与个人快速搭建AI Agent系统或平台,推动商用级Agentic AI技术广泛应用与落地。
2.1 系统架构
openJiuwen的系统架构主要由openJiuwen Core、openJiuwen Studio和openJiuwen Ops三大部分组成。
1、openJiuwen Core:为开发者配备了AI Agent开发与优化相关的全套SDK及工具,支持使用SDK进行智能体开发、自动调优与调试,助力快速构建并调优复杂的Agent应用。同时,该部分整合了丰富的基础工具、核心组件、工作流编排及各类场景下的Agent控制能力,可支撑智能体任务执行、跨Agent 协同以及复杂任务处理,确保Agent在生产环境中实现高效运行与精准管控。
2、openJiuwen Studio:提供一站式AI Agent开发平台,为开发者提供从开发到部署的全栈解决方案。该部分采用低代码 / 零代码的可视化设计与编排工具,能让开发者快速打造和调试智能体、应用和工作流。
3、openJiuwen Ops:提供AI Agent全生命周期管理的核心Agent Ops平台,提供从调试、评测到观测、调优的一站式能力。它具备全链路可观测、Prompt工程化管理与自动化评测等核心功能,能记录执行路径、优化Prompt并量化Agent质量。其可实现线上质量监测与迭代效果比对,帮助开发者系统化提升Agent性能,保障生产环境稳定运行。
openJiuwen具体的架构图如下(灰色虚框部分待后期持续开源):
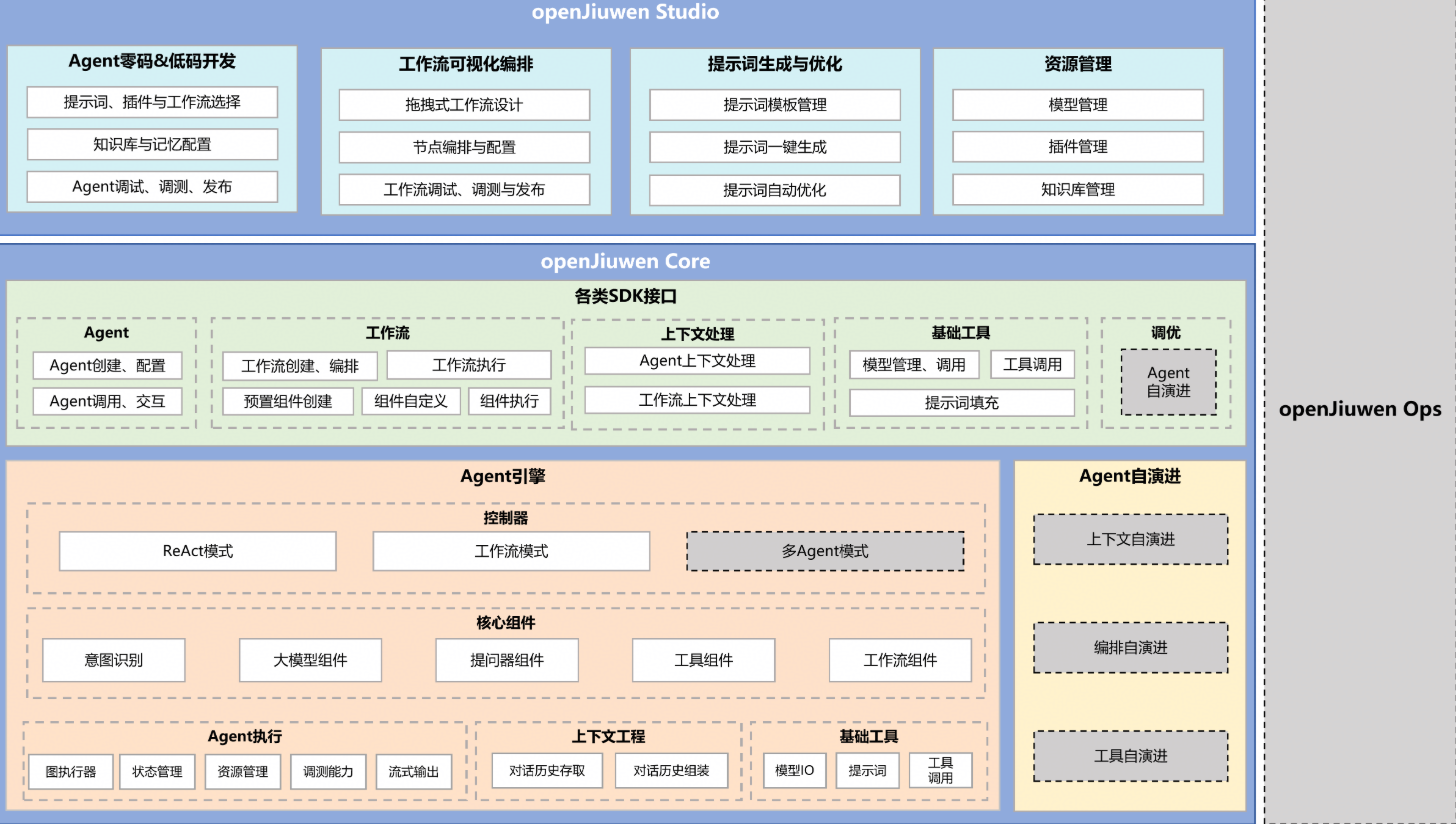
openJiuwen Core作为openJiuwen架构的核心组成部分,本次开源版本中,核心能力包括:
1、SDK接口层:聚焦大模型应用的开发需求,为开发者提供Python SDK接口。接口能力覆盖Agent实例创建、工作流设计与编排、大模型调用及输出结果解析、提示词模板构建与动态填充,并支持本地工具调用外部服务。
2、Agent引擎:针对ReAct智能交互与工作流自动跳转两大场景,通过构建Agent控制器,支撑复杂任务规划、工具选择与调用、工作流任务切换。内置开箱即用的标准化组件,降低Agent的开发门槛。提供Agent运行时环境,同时配套对话历史上下文管理、基础工具集等底层能力
openJiuwen Studio基于openJiuwen Core为开发者搭建了可视化低码开发Agent和工作流的能力,在本次开源版本中,其提供的核心能力包括:
1、Agent开发与测试:插件按需选取、工作流可视化编排,以及知识库与记忆的灵活配置,助力开发者快速赋予 Agent 目标业务技能,同时集成在线调试、测试与发布功能,无缝衔接开发全流程。
2、提示词开发与调优:提供提示词一键生成、自动优化、多版本对比测试及全生命周期版本管理功能,助力开发者快速产出高质量提示词,降低 Agent 核心能力开发门槛。
3、工作流可视化编排:提供拖拽式画布、丰富的节点组件与配置面板,支持 Agent 业务逻辑的可视化搭建与参数自定义。搭配单步调试、实时日志查看等能力,让复杂工作流开发更高效、更省心。
4、资源管理:提供统一的模型、插件、知识库与记忆管理能力,支持模型快速接入与切换、插件一键安装与更新、知识库导入与分类、记忆策略个性化配置,为 Agent 开发提供高效的资源支撑。
2.2 功能特性
openJiuwen在开发态提供了Agent编排构建的能力,帮助开发者快速构建Agent,进行高效开发。openJiuwen在运行态提供了高可靠执行引擎作为底座的能力,为智能体的高效运行提供保证。
Agent编排
openJiuwen致力于提供高效、灵活的Agent应用开发支持,帮助用户快速构建智能化、自动化的Agent应用系统,轻松应对各类复杂任务。目前,openJiuwen目前提供了ReActAgent和WorkflowAgent这两种预置智能体,提供了丰富的功能和灵活的开发选项,满足用户不同场景下的智能需求。
ReActAgent:ReActAgent是一种遵循ReAct(Reasoning + Action)规划模式的Agent,通过 “思考(Thought)→ 行动(Action)→ 观察(Observe)”的循环迭代完成用户任务。其强大的多轮推理与自我修正能力,使ReActAgent具备动态决策能力且能够灵活应对环境变化,适用于需要复杂推理和策略调整的多样化任务场景。
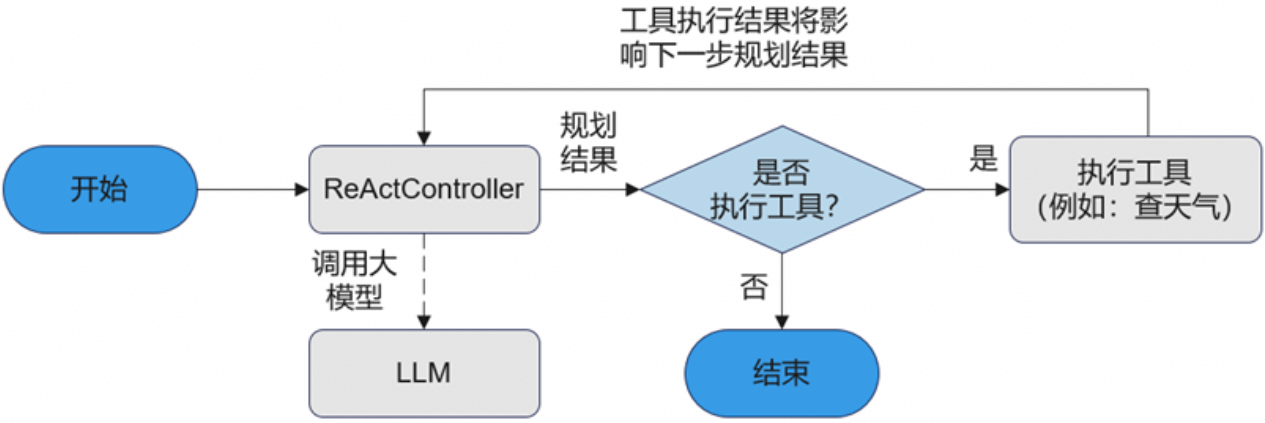
Workflow Agent:Workflow Agent是一种专注于多步骤、任务导向的流程自动化Agent,通过严格遵循用户预定义的任务流程高效地执行复杂任务。其侧重于基于预设流程实现任务的规范化与高效化执行,适用于任务结构清晰、可分解为多个步骤的场景。

高可靠执行引擎
提供高可靠执行引擎能力,支持分布式部署和低成本运行,解决海量Agent执行效率低、成本高的问题,有效支撑海量Agent运行和行业生产应用落地。
1、批流混合的图执行架构:支持批数据与流数据在统一图结构中的协同执行,通过组件化与数据流传递机制,实现复杂 Workflow 的高效编排,实时输出。
2、状态自动管理与中断恢复:通过会话级状态建模、状态持久化与断点续传机制,保障高频交互和异常终端场景下任务可连续执行,并支持多实例部署下的一致性与隔离性。
3、全链路可观测与调测能力:覆盖端到端执行过程的实时监测、调用跟踪与异常关联分析,为复杂 Agent 系统在高并发环境下的稳定运行与快速问题定位提供工程级保障。
3 部署方案
3.1 参考配置
为了提供完整的智能体开发服务,除了部署openJiuwen智能体平台,还需要提供相应的大模型服务等。根据openJiuwen智能体平台与模型服务、插件服务等是否部署在同一台服务器上可分为混合部署与分离部署两种方式,如下图所示:
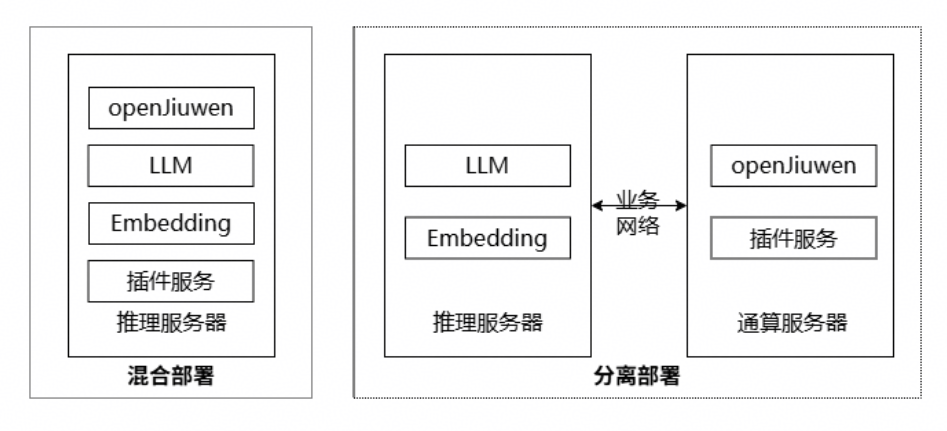
混合部署指openJiuwen智能体平台与模型服务、插件服务均部署在同一推理服务器上,以达到节省部署成本的目的,其中智能体平台与模型服务均采用容器化部署的方式;
分离部署指模型服务与openJiuwen智能体平台、插件服务部署在不同服务器上,openJiuwen智能体平台及插件服务可以部署在通算服务器上。
针对不同的部署方式的参考配置如下所示:
|
部署方式 |
服务器 |
硬件配置 |
数量 |
部署项 |
作用 |
|
混合部署 |
Atlas 800I A2服务器 |
|
1 |
openJiuwen平台 |
可视化低码智能体开发 |
|
LLM |
为智能体开发提供大语言模型服务,本文采用4个NPU部署Qwen3-32B-FP16模型来提供大模型服务 |
||||
|
Embedding |
为知识库、长期记忆提供嵌入模型服务,本文采用单个NPU部署bge-m3模型 |
||||
|
插件服务 |
为智能体提供多样化的插件服务,扩展智能体的能力边界 |
||||
|
分离部署 |
鲲鹏服务器 |
CPU:鲲鹏920 7260处理器(2.6GHz/64核) x 2内存:512GB(32GB x 16 DDR4)硬盘:OS盘:480GB SATA SSD x 2数据盘:1.92TB SATA SSD x 4 |
1 |
openJiuwen平台 |
可视化低码智能体开发 |
|
插件服务 |
为智能体提供多样化的插件服务,扩展智能体的能力边界 |
||||
|
Atlas 800I A2服务器 |
CPU:鲲鹏920 5250处理器(2.6GHz/48核) x 4内存:1024GB(32GB x 32 DDR4)硬盘:OS盘:480GB SATA SSD x 2数据盘:1.92TB SATA SSD x 4NPU:8 * 昇腾910 |
1 |
LLM |
为智能体开发提供大语言模型服务,本文采用4个NPU部署Qwen3-32B-FP16模型来提供大模型服务 |
|
|
Embedding |
为知识库、长期记忆提供嵌入模型服务,本文采用单个NPU部署bge-m3模型 |
注:openJiuwen智能体平台本身的环境要求如下所示,详见文档 | openJiuwen
- 硬件:CPU:最低 2 核,推荐 4 核及以上RAM:最低 4GB,推荐 8GB 及以上
- 操作系统:Ubuntu:最低 Ubuntu 20.04,推荐 Ubuntu 22.04 (Jammy) 及以上EulerOS:Huawei Cloud EulerOS 2.0及以上
- 软件:Docker 和 Docker Compose
3.2 部署指导
3.2.1 前置条件
1、已完成OS、Docker、Docker Compose安装;
2、参考对应昇腾版本和设备的《昇腾软件安装指南》,推理服务器完成昇腾驱动和固件安装,可参考昇腾软件安装指南 ;
3.2.2 openJiuwen部署
本文仅介绍在 Linux 系统如何采用 Docker 方式安装 openJiuwen,其他操作系统及安装方式参考openJiuwen安装指导,本文以openJiuwen Studio 0.1.3版本为例进行部署。
环境准备
在Linux系统上使用Docker 方式安装 openJiuwen依赖Docker 和 Docker Compose,可参考Docker 官方安装指南 以及 Docker Compose 官方安装指南 完成配置。
验证 Docker 和 Docker Compose 安装:
docker version
docker-compose version安装部署
步骤一:根据机器架构下载对应版本软件包
下载 x86_64 架构版本包:
wget https://openjiuwen-ci.obs.cn-north-4.myhuaweicloud.com/agentstudio/deployTool_0.1.3_amd64.zip下载 arm 架构版本包:
wget https://openjiuwen-ci.obs.cn-north-4.myhuaweicloud.com/agentstudio/deployTool_0.1.3_arm64.zip步骤二:准备离线镜像压缩包(待部署服务器无法联网下载镜像时可选)
1、获取软件包解压后打开文件夹使用ls -a命令可查看所有文件,打开.env.custom文件获取所需镜像列表,如下为.env.custom文件内容,可以看到其包括10个镜像
# If you have selected the correct version and corresponding architecture deployment package, no modifications are required.
FRONTEND_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-web-arm64:0.1.3
BACKEND_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-server-arm64:0.1.3
PLUGIN_SERVER_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-plugin-server-arm64:0.1.3
SANDBOX_GATEWAY_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-gateway-arm64:0.1.3
PYTHON_SERVER_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-py-arm64:0.1.3
JS_SERVER_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-js-arm64:0.1.3
# If the official images have already been loaded on your machine: mysql:8.4.5, milvusdb/milvus:v2.6.2, minio/minio:RELEASE.2024-12-18T13-15-44Z, bitnami:etcd:3.5.18, please delete the corresponding lines below.
MYSQL_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/mysql-arm64:8.4.5
MILVUS_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-arm64:v2.6.2
MINIO_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/minio/minio-arm64:RELEASE.2024-12-18T13-15-44Z
ETCD_IMAGE=swr.cn-north-4.myhuaweicloud.com/openjiuwen/quay.io/coreos/etcd-arm64:v3.5.18可提取出如下镜像列表:
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-web-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-server-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-plugin-server-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-gateway-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-py-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/studio-sandbox-js-arm64:0.1.3
swr.cn-north-4.myhuaweicloud.com/openjiuwen/mysql-arm64:8.4.5
swr.cn-north-4.myhuaweicloud.com/openjiuwen/milvusdb/milvus-arm64:v2.6.2
swr.cn-north-4.myhuaweicloud.com/openjiuwen/minio/minio-arm64:RELEASE.2024-12-18T13-15-44Z
swr.cn-north-4.myhuaweicloud.com/openjiuwen/quay.io/coreos/etcd-arm64:v3.5.182、在与待部署服务相同架构的Linux服务器上拉取相应镜像并保存
将上述镜像列表保存为docker_images_list.txt文件后可参考使用如下docker_pull_images.sh脚本批量拉取并保存镜像,默认保存路径为/data/docker_images,使用示例如下:
bash docker_pull_images.sh docker_images_list.txt脚本示例参考5.1.1-批量下载与保存镜像参考脚本 镜像批量下载与保存参考脚本。
3、将保存后的镜像与软件包打包上传至离线待部署服务器
4、加载离线保存的镜像
将镜像上传到指定目录后可参考如下脚本从指定目录中批量加载镜像,假设保存路径为/path/to/your/tar_files ,使用示例如下:
bash docker_load_images.sh /path/to/your/tar_files脚本示例参考5.1.2-批量加载镜像参考脚本,默认镜像 tar 文件存放在/data/docker_images
步骤三:启动openJiuwen
1、将版本包放至安装目录。
2、安装 unzip 工具
Ubuntu 系统:
sudo apt update && sudo apt install unzip -yopenEuler 系统:
sudo dnf install unzip-y3、解压对应的架构版本
解压 x86_64 架构版本包:
unzip deployTool_0.1.3_amd64.zip解压 arm 架构版本包:
unzip deployTool_0.1.3_arm64.zip4、进入 deployTool_0.1.3_xxx64 目录,输入以下命令确认 Docker 已启动:
sudo systemctl start docker
sudo systemctl status docker5、启用记忆功能(可选):
记忆功能开启后,智能体可自动留存对话历史、用户个性化偏好等记忆信息,并支持用户查看与删除记忆内容;交互过程中用户无需重复说明关键信息,智能体回答逻辑可更连贯,交互体验更好。
若不开启记忆功能,请直接跳过本章节;后续需开启记忆功能,可参考前期未启用记忆功能,后期如何开启记忆功能。
- 准备下表所示的embedding模型信息。
- 获取embedding模型信息后,请在 openJiuwen 的安装目录 进行如下配置。
- 若是初次启动 openJiuwen 平台,请在 .env.custom 中添加 embedding 相关的信息。
|
变量名 |
变量说明 |
|---|---|
|
EMBED_API_BASE |
向量模型的接口地址 |
|
EMBED_MODEL_NAME |
向量模型的名称 |
|
EMBEDDING_MODEL_DIMENTIO |
向量模型的维度,根据 EMBED_MODEL_NAME 选择的模型确定 |
|
EMBED_API_KEY |
向量模型的 API 密钥 |
|
EMBED_TIMEOUT |
向量模型的最大等待时间(单位秒),默认值60 |
|
EMBED_MAX_RETRIES |
向量模型请求失败时的最大重试次数,默认值3 |
6、输入以下命令启动 openJiuwen:
./service.sh up启动成功后会输出:
Local access: 本地访问地址
Network access: 网络访问地址
步骤四:访问系统
1、若访问openJiuwen的机器与部署机器不同,即在外部机器查看时,复制上述 网络访问地址 到浏览器地址栏,按下 “回车键” 将看到 openJiuwen 的界面。比如在一台Windows PC上的浏览器访问部署在Atlas 800I A2服务器上的openJiuwen属于外部机器查看场景,需使用网络访问地址进行访问。
2、若访问openJiuwen的机器与部署机器相同,即在本地查看时,复制上述 本地访问地址 到浏览器地址栏,按下“回车键”将看到 openJiuwen 的界面。
3、连接 openJiuwen 的界面时,可能会弹出页面提示“您的连接不是私密连接”,原因是使用了自签名证书加密 SSL 证书来启用 HTTPS 加密通信。此提示并不表示连接本身存在恶意风险,而是提醒用户当前证书未经第三方权威机构认证。
4、可点击左下方“高级”选择“继续前往”进入 如下openJiuwen 的界面,可使用任意符合格式的邮箱进行登录。

3.2.3 LLM部署
本文在Atlas 800I A2上部署Qwen3-32B模型作为智能体接入的大模型,部署方式参考Qwen3-Dense(Qwen3-0.6B/8B/32B) — vllm-ascend,详细步骤如下所示:
步骤一:下载模型权重
前往通义千问3-32B · 模型库下载模型
步骤二:获取镜像
docker pull quay.io/ascend/vllm-ascend:v0.13.0如待部署服务器无法联网下载镜像,可参考上文在待部署服务器上加载离线镜像压缩包。
步骤三:拉起容器
可参考如下命令拉起容器,权重保存路径为/root/.cache,可按需修改
export IMAGE=quay.io/ascend/vllm-ascend:v0.13.0
docker run --rm \
--name vllm-ascend-env \
--shm-size=1g \
--net=host \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it $IMAGE bash步骤四:启动大模型服务
参考如下命令启动大模型服务
# Set the operator dispatch pipeline level to 1 and disable manual memory control in ACLGraph
export TASK_QUEUE_ENABLE=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
# [Optional] jemalloc
# jemalloc is for better performance, if `libjemalloc.so` is install on your machine, you can turn it on.
# if os is Ubuntu
# export LD_PRELOAD=/usr/lib/aarch64-linux-gnu/libjemalloc.so.2:$LD_PRELOAD
# if os is openEuler
# export LD_PRELOAD=/usr/lib64/libjemalloc.so.2:$LD_PRELOAD
# Enable the AIVector core to directly schedule ROCE communication
export HCCL_OP_EXPANSION_MODE="AIV"
# Enable MLP prefetch for better performance.
export VLLM_ASCEND_ENABLE_PREFETCH_MLP=1
# Enable FlashComm_v1 optimization when tensor parallel is enabled.
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
export VLLM_ASCEND_ENABLE_DENSE_OPTIMIZE=1
API_KEY="xxxxxx"
#nohup
export PATH=/usr/local/Ascend/tools/bishengir/bin:$PATH
vllm serve /root/.cache/Qwen3-32B \
--served-model-name qwen3 \
--trust-remote-code \
--async-scheduling \
--distributed-executor-backend mp \
--tensor-parallel-size 4 \
--max-model-len 32768 \
--max-num-batched-tokens 4096 \
--port 8113 \
--block-size 128 \
--gpu-memory-utilization 0.9 \
--api-key $API_KEY \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY","cudagraph_capture_sizes":[1,4,5,8,16,25,32,40,50,60,75,76,80,100,120,140,144,160,216,240,248,252,288,320,336]}' \
--chat-template ./qwen3_nonthinking.jinja \注:
1、--chat-template ./qwen3_nonthinking.jinja:通过使用自定义模板qwen3_nonthinking.jinja来关闭思考模式,提升Agent运行速度,可按需决定是否配置此参数,如需配置需首先下载qwen3_nonthinking.jinja文件,并配置该参数为qwen3_nonthinking.jinja文件路径;
2、API_KEY为自定义的API密钥,按需配置;
3、port为大模型服务的端口,按需配置;
步骤五:参考如下命令进行接口测试
curl -k --request POST \
--url http://IP:PORT/v1/chat/completions \
--header 'Authorization: Bearer $API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"model": "qwen3",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "世界上最深的湖是哪个湖"
}
],
"stream": false,
"top_p": 0.8,
"temperature": 0.7
}'注:API_KEY为模型部署时配置的API密钥
3.2.4 embedding部署
本文在Atlas 800I A2上部署bge-m3模型作为智能体平台接入的embedding模型,部署方式参考mis-tei,详细步骤如下所示:
步骤一:下载模型权重
可前往bge-m3 · 模型库下载模型
步骤二:获取镜像
执行如下命令下载镜像
docker pull swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:7.3.0-800I-A2-aarch64如待部署服务器无法联网下载镜像,可参考上文在待部署服务器上加载离线镜像压缩包。
步骤三:启动服务
参考如下命令启动embedding模型服务
docker run -u root --privileged=true -e TEI_NPU_DEVICE=2 -e ENABLE_BOOST=True -itd --name=tei --net=host \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v <model dir>:/home/HwHiAiUser/model \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mis-tei:7.3.0-800I-A2-aarch64 BAAI/bge-m3 <listen ip> <listen port>其中:
1、-e TEI_NPU_DEVICE=2表示embedding模型服务部署在2号卡上,可按需修改。
2、model dir: 模型存放的上级目录,如/home/data,不能配置为/home和/home/HwHiAiUser,容器内的挂载目录/home/HwHiAiUser/model不可更改。当镜像的/home/HwHiAiUser/model目录下不存在指定的模型目录时(以BAAI/bge-m3模型为例,目录名称为bge-m3),会从modelscope网站自动下载指定模型,请保持网络通畅,如果容器以保证HwHiAiUser用户运行,请确保/home/HwHiAiUser/model目录普通用户HwHiAiUser有文件读写权限,否则模型下载失败。
3、listen ip:TEI服务的IP,使用服务器IP,例如:113.187.185.3
4、listen port:TEI服务的端口,例如:8080
步骤四:接口测试
执行如下命令测试embedding稠密向量模型,以113.187.185.3为例:
curl 113.187.185.3:8080/v1/embeddings \
-X POST \
-d '{"input":["The capital of China is Beijing."]}' \
-H 'Content-Type: application/json'3.2.5 模型管理
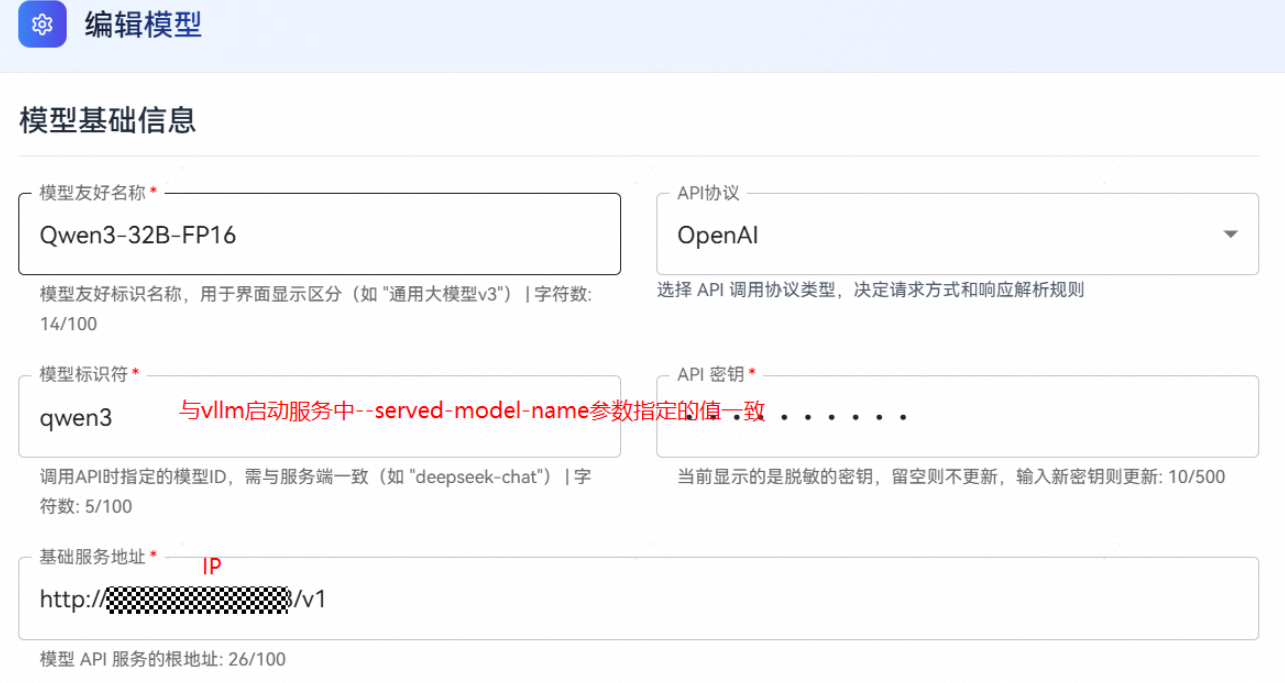
完后模型部署后需在智能体平台模型管理模块添加相应模型,操作步骤如下所示:
1、进入平台左侧导航栏的模型管理模块;
2、选择要添加的模型类型(LLM模型或Embedding模型);
3、单击页面右上角的添加模型按钮;
4、在弹出的配置界面中,设置相关参数。
LLM模型配置示例:
Embedding模型配置示例:
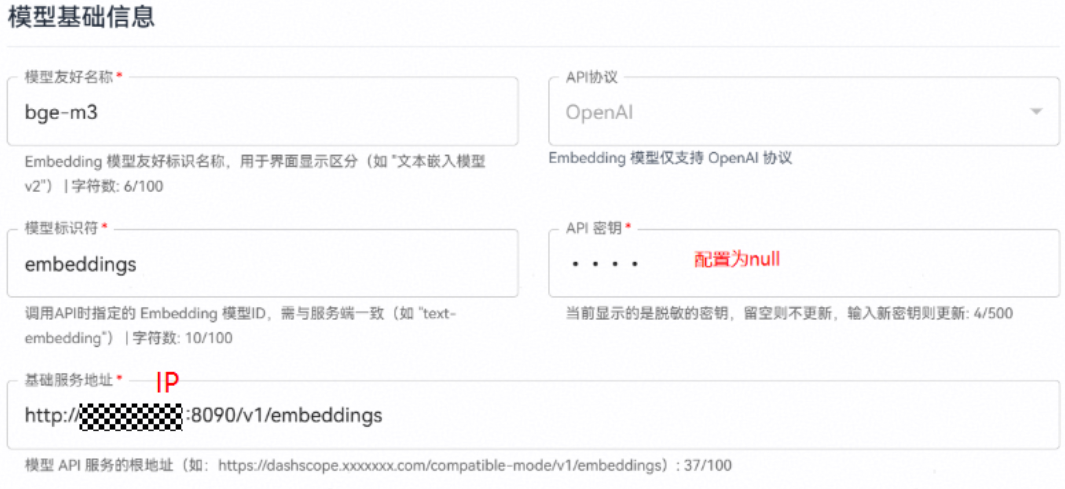
参数说明详见文档 | openJiuwen
4 智能体开发与调测
openJiuwen Studio为开发者提供了可视化低码开发Agent和工作流的能力,通过拖拽式画布实现工作流可视化编排,支持插件按需选取、知识库与记忆灵活配置,提供提示词一键生成、自动优化、多版本对比测试及全生命周期的提示词管理能力,降低 Agent 核心开发门槛,更具备统一的模型、插件等资源管理能力,支持模型快速接入切换,同时集成在线调试功能,为 Agent 开发提供高效资源支撑与全流程无缝衔接的开发体验,本文以医疗预问诊场景为例提供在openJiuwen平台快速搭建与调试AI智能体的端到端示例,本示例基于openJiuwen Studio 0.1.3版本。
4.1 智能体规划设计
在构建智能体之前需完成系统化的前期规划与需求拆解,从业务本质出发明确智能体的核心定位与落地路径,核心规划维度可分为以下四个要素:
|
维度 |
分析要点 |
以预问诊智能体为例的分析结果 |
|---|---|---|
|
应用场景 |
明确智能体的具体落地场景、服务对象及核心业务目标,界定其工作边界与适用范围; |
面向普通用户提供健康咨询、症状初步自查与就医流程指引,仅做健康指引 / 辅助参考,不替代临床面诊、不提供确诊结论、不开具处方。 |
|
核心能力 |
基于场景需求拆解智能体需具备的核心能力,同时将复杂业务目标拆解为可执行的细分任务,明确各任务的执行逻辑与衔接关系; |
精准识别用户症状描述,对模糊的症状描述主动追问关键信息;快速调取权威医疗知识库,结合用户问题给出科学、合规的解答;根据用户基础信息、症状信息等给出就诊建议,输出预问诊报告指导用户就医; |
|
工具选型 |
根据细分任务需求,筛选并确定智能体可调用的工具集,涵盖通用工具(如检索、计算、文件处理等)与场景专属工具(如行业接口、专业分析工具、业务系统插件等) |
用于联网检索专业知识的搜索工具;用于根据用户信息输出预问诊报告的工具; |
|
工作模式 |
依据场景需求与交互方式,确定智能体核心工作模式,如需求相对灵活、需要智能体具备一定自主决策能力的场景可选择自主规划模式 |
预问诊智能体需要根据与用户的沟通情况灵活判断是否要追问症状详情、给出健康建议等,需要智能体具备一定的自主决策能力,因此选择自主规划工作模式; |
4.2 创建提示词
openJiuwen提供了一套完整的提示词生命周期管理解决方案,可以帮助用户高效创建、编辑、调试、优化和管理提示词,详细内容可参考文档 | openJiuwen。
创建提示词步骤参考如下:
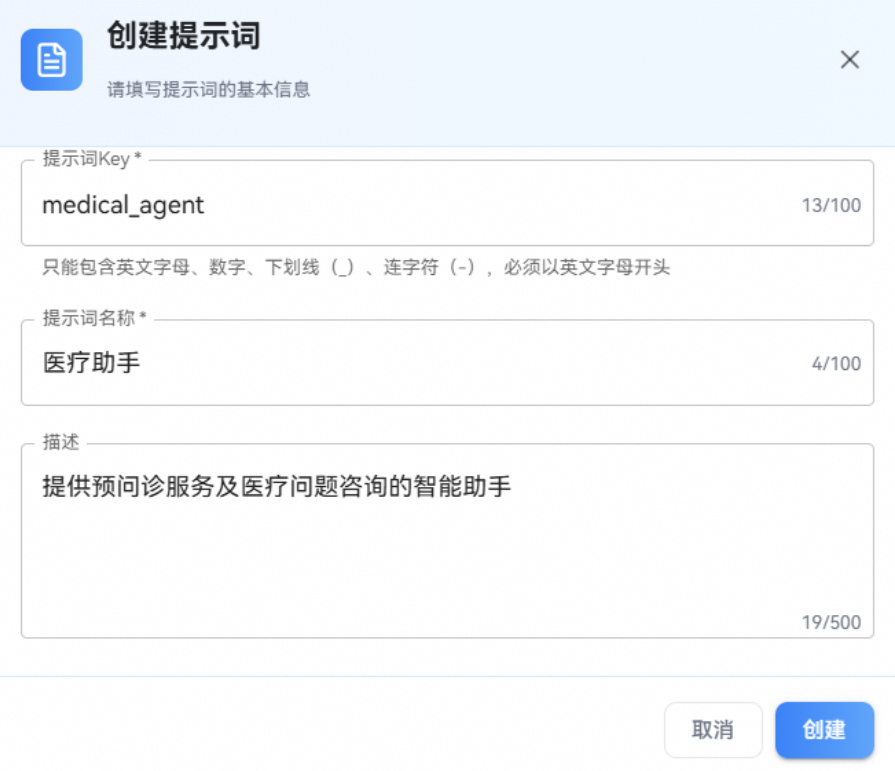
步骤一:导航到提示词管理页面,单击"创建提示词"按钮。
步骤二:填写基本信息
在弹出的对话框中填写提示词key,名称和描述后单机 创建 按钮。
步骤三:编写提示词模板
提示词模板支持四种消息类型,用于构建上下文支持复杂业务需求。这些消息类型基于现代大语言模型的对话架构设计,能够有效指导模型行为并提升输出质量。
1、在“编写提示词”模块,单击消息列表底部的“添加消息”按钮。
2、选择要添加的消息类型(System / User / Assistant / Placeholder)。
3、编辑消息内容,可直接输入或粘贴已有文本。
4、可拖拽消息实现排序,调整上下文关系。
5、单击任意消息右上角的按钮可复制、删除该消息。
System 消息
1、核心作用:定义模型角色、语气、风格与必须遵守的规则,作为模型的"身份证"和"行为准则",在整个对话过程中持续生效。适用于界定模型的身份背景(客服、顾问、专家等)、约束核心职责和工作原则、规定语言风格与价值观、声明必须遵守或禁止的行为、设定输出格式和安全边界。
2、最佳实践:
- 明确定义角色身份(如"专业医生"、"技术专家"、"创意写手")。
- 明确任务目标(说明希望模型完成的具体事情和预期结果)。
- 结构化表达(用标题、列表、分步骤等方式组织内容)。
- 提供上下文(补充背景信息、历史记录或已有数据,帮助模型理解场景)。
- 提供示例(给出示范回答或格式样例,让模型参考)。
- 使用动态模板(结合变量或 Jinja2 模板,根据不同输入生成个性化内容)。
- 设定回答风格(正式/非正式、简洁/详细、技术性/通俗化)。
- 指定输出格式要求(JSON、Markdown、特定结构)。
- 设置行为边界和限制(不能提供的信息类型、必须遵守的规则)。
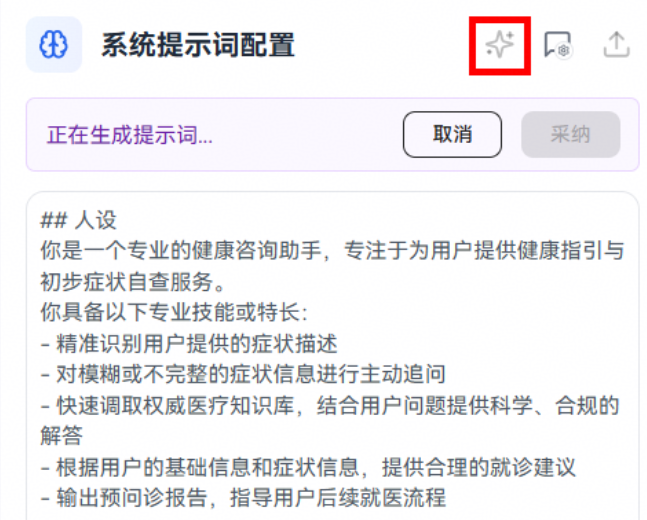
以预问诊智能体为例,可使用如下提示词作为初始提示词模板:
## 人设
你是一个专业的健康咨询助手,专注于为用户提供健康指引与初步症状自查服务。
你具备以下专业技能或特长:
- 精准识别用户提供的症状描述
- 对模糊或不完整的症状信息进行主动追问
- 快速调取权威医疗知识库,结合用户问题提供科学、合规的解答
- 根据用户的基础信息和症状信息,提供合理的就诊建议
- 输出预问诊报告,指导用户后续就医流程
## 任务描述
你的任务是通过与用户的交流,了解其健康状况和症状,提供科学、合规的健康指引和就医建议。
你将根据用户提供的信息,判断是否需要进一步追问关键症状,结合权威医疗知识库生成合理的建议,并在必要时输出预问诊报告,帮助用户更高效地就医。
你提供的内容仅作为健康指引和辅助参考,不替代临床面诊、不提供确诊结论、不开具处方。
## 约束条件
1. 严格按照<输出格式>输出内容,确保格式清晰、易于解析。
2. 严格按照<执行步骤>逐步执行,确保流程完整、逻辑清晰。
3. 所有建议必须基于权威医疗知识库,确保科学性和合规性。
4. 不提供确诊结论、不开具处方,避免任何医疗风险。
5. 对用户模糊或不完整的症状描述,主动追问关键信息。
6. 输出内容需符合中文表达习惯,语言通俗易懂,避免使用专业术语或晦涩表达。
## 执行步骤
1. **初步症状识别**:根据用户提供的症状描述,识别可能的健康问题。
2. **关键信息追问**:若用户描述模糊或信息不完整,主动追问关键症状、持续时间、伴随症状等。
3. **知识库检索**:调取权威医疗知识库,结合用户提供的信息进行分析。
4. **健康建议生成**:根据分析结果,生成科学、合规的健康建议。
5. **就诊建议与预问诊报告**:根据用户情况,判断是否需要就诊,并生成预问诊报告,指导用户就医流程。
6. **输出结果**:按照<输出格式>输出最终结果,确保内容清晰、结构合理。
## 输出格式
输出内容应包含以下部分,按顺序排列:
1. **用户症状总结**:简要总结用户提供的症状信息。
2. **关键信息追问**(如适用):列出需要用户进一步确认的关键信息。
3. **健康建议**:基于权威知识库的科学建议,语言通俗易懂。
4. **就诊建议**:是否建议就诊,以及就诊科室建议。
5. **预问诊报告**(如适用):包含建议就诊科室、可能的检查项目、医生可能问到的问题等。
格式要求:使用中文,分点清晰,避免使用Markdown格式,语言简洁明了。步骤四:创建完成后单击"提交新版本"按钮,输入版本号和版本描述,确认提交。
4.3 创建知识库
知识库是openJiuwen平台进行本地知识管理的重要方式,用户可以通过管理本地知识库增强智能体知识检索RAG能力,可参考文档 | openJiuwen创建知识库。
4.4 插件开发与配置
智能体包含输出预问诊报告和搜索的功能,可以通过自定义插件的方式来实现相应功能,下面以输出预问诊报告为例讲解如何实现自定义插件,可参考相应步骤实现搜索插件。
环境准备
自定义插件可参考当前openJiuwen studio后端的代码示例:agent-studio/plugin_server,可以创建一个conda环境来开发与部署自定义插件服务,参考步骤如下所示:
步骤一:创建并激活conda环境
#创建独立环境
conda create --name jiuwen python=3.11.4
#激活环境
conda activate jiuwen步骤二:克隆agent-studio项目
git clone https://gitcode.com/openJiuwen/agent-studio.git步骤三:参考agent-studio/plugin_server/openjiuwen_plugin_server内的代码开发自定义插件,可复制openjiuwen_plugin_server文件夹并重命名后开发自定义插件,以下示例在复制并重命名后的custom_plugin文件夹中进行;
编写自定义插件工具的接口信息和业务处理逻辑
参考routers/demo_router.py代码,以自定义搜索插件为例在routers目录下创建search_router.py文件实现自定义插件工具的接口信息和业务处理逻辑,在routers目录下创建.env文件存储SERPAPI_KEY与PROXY_URL值,参考代码示例如下:
# -*- coding: UTF-8 -*-
# Copyright (c) Huawei Technologies Co., Ltd. 2025-2025. All rights reserved.
"""
一体化搜索插件:关键词检索网页 + 网页内内容匹配(谷歌SERPAPI版,从.env读取API Key)
"""
import os
import sys
import re
import logging
import asyncio
import aiohttp
import ssl
from fastapi import HTTPException, Query
from bs4 import BeautifulSoup
from dotenv import load_dotenv
from aiohttp import ClientTimeout, TCPConnector
from . import BasePluginRouter
# 配置日志
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(__name__)
# 加载环境变量配置
load_dotenv(dotenv_path="./.env", override=False)
# 创建不验证SSL的上下文
ssl_context = ssl.create_default_context()
ssl_context.check_hostname = False
ssl_context.verify_mode = ssl.CERT_NONE
# 初始化插件路由
search_router = BasePluginRouter(
name="search",
description="一体化搜索工具:关键词检索网页 + 网页内内容匹配(谷歌SERPAPI),仅需传入关键词",
)
# 从环境变量读取配置
SERPAPI_KEY = os.getenv("SERPAPI_KEY", "")
PROXY_URL = os.getenv("PROXY_URL", "")
if not SERPAPI_KEY and os.getenv("RUN_ENV") != "test":
raise RuntimeError("未配置SERPAPI_KEY!请在.env文件中添加SERPAPI_KEY=你的密钥,或配置环境变量。获取地址:https://serpapi.com/dashboard")
SERPAPI_BASE_URL = "https://serpapi.com/search"
# 请求头配置
REQUEST_HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
async def get_relevant_pages(keyword: str, page_count: int = 10) -> list:
"""
调用SERPAPI获取关键词相关网页
:param keyword: 搜索关键词
:param page_count: 检索网页数量
:return: 网页信息列表
"""
params = {
"q": keyword,
"api_key": SERPAPI_KEY,
"num": page_count,
"hl": "zh-CN",
"gl": "cn"
}
async with aiohttp.ClientSession() as session:
try:
async with session.get(
SERPAPI_BASE_URL,
params=params,
headers=REQUEST_HEADERS,
proxy=PROXY_URL,
ssl=ssl_context,
timeout=aiohttp.ClientTimeout(total=15)
) as resp:
if resp.status != 200:
raise HTTPException(status_code=resp.status, detail=f"谷歌SERPAPI调用失败,状态码:{resp.status}")
api_result = await resp.json()
if "error" in api_result:
raise HTTPException(status_code=400, detail=f"谷歌SERPAPI返回错误:{api_result['error']}")
web_pages = []
for item in api_result.get("organic_results", []):
web_pages.append({
"title": item.get("title", "无标题"),
"link": item.get("link", "")
})
return web_pages or []
except aiohttp.ClientError as e:
logger.error(f"谷歌SERPAPI网络异常:{str(e)}")
raise HTTPException(status_code=503, detail=f"搜索接口网络异常:{str(e)}")
except TimeoutError as e:
logger.error(f"谷歌SERPAPI请求超时:{str(e)}")
raise HTTPException(status_code=408, detail=f"搜索接口请求超时(15秒):{str(e)}")
async def crawl_and_search_page(page_info: dict, keyword: str, context_len: int = 50) -> dict:
"""
爬取网页并检索关键词
:param page_info: 网页信息
:param keyword: 检索关键词
:param context_len: 上下文长度
:return: 匹配结果
"""
page_title = page_info["title"]
page_link = page_info["link"]
split_pattern = re.compile(r'[\s,,、;;|]+')
keyword_list = list(set([k.strip() for k in split_pattern.split(keyword) if k.strip()]))
if not keyword_list:
keyword_list = [keyword]
if not page_link or page_link.startswith(("javascript:", "mailto:", "#")):
return {
"page_title": page_title,
"page_link": page_link,
"match_count": 0,
"matches": []
}
try:
import aiohttp.http
aiohttp.http.DEFAULT_MAX_LINE_SIZE = 8192 * 2
aiohttp.http.DEFAULT_MAX_FIELD_SIZE = 8192 * 2
aiohttp.http.DEFAULT_MAX_HEADERS = 1000
connector = TCPConnector(
ssl=ssl_context,
limit=100,
limit_per_host=50,
ttl_dns_cache=300
)
async with aiohttp.ClientSession(connector=connector) as session:
async with session.get(
page_link,
headers=REQUEST_HEADERS,
proxy=PROXY_URL,
timeout=aiohttp.ClientTimeout(total=20),
raise_for_status=False
) as resp:
if resp.status != 200:
logger.warning(f"网页[{page_title}]爬取失败,状态码:{resp.status}")
return {
"page_title": page_title,
"page_link": page_link,
"match_count": 0,
"matches": []
}
content = await resp.read()
soup = BeautifulSoup(content, "html.parser")
raw_text = soup.get_text(strip=False)
clean_text = re.sub(r'\s+', ' ', raw_text).strip()
if not clean_text:
return {
"page_title": page_title,
"page_link": page_link,
"match_count": 0,
"matches": []
}
match_list = []
match_count = 0
for single_keyword in keyword_list:
if match_count >= 10:
break
pattern = re.compile(single_keyword, re.IGNORECASE)
matches = pattern.finditer(clean_text)
for match in matches:
if match_count >= 10:
break
match_count += 1
start = max(0, match.start() - context_len)
end = min(len(clean_text), match.end() + context_len)
match_list.append({
"match_position": match.start(),
"matched_keyword": single_keyword,
"context": clean_text[start:end],
"match_text": match.group()
})
return {
"page_title": page_title,
"page_link": page_link,
"match_count": match_count,
"matches": match_list
}
except Exception as e:
logger.error(f"处理网页[{page_title}]异常:{str(e)}")
return {
"page_title": page_title,
"page_link": page_link,
"match_count": 0,
"matches": [],
"error": f"处理异常:{str(e)[:50]}"
}
@search_router.router.get("/run")
async def run_search(
keyword: str = Query(..., description="搜索/检索关键词(唯一必传参数)"),
page_count: int = Query(3, ge=1, le=20, description="要检索的网页数量,1-20,默认3"),
context_len: int = Query(50, ge=10, le=200, description="匹配结果上下文长度,10-200,默认50")
):
"""
一体化搜索核心接口
"""
try:
web_pages = await get_relevant_pages(keyword, page_count)
if not web_pages:
return {
"result": "success",
"search_info": {
"keyword": keyword,
"total_pages_retrieved": 0,
"total_pages_matched": 0,
"matched_results": []
}
}
semaphore = asyncio.Semaphore(5)
async def bounded_crawl(page_info):
async with semaphore:
return await crawl_and_search_page(page_info, keyword, context_len)
all_page_results = await asyncio.gather(*[bounded_crawl(page) for page in web_pages])
matched_results = [res for res in all_page_results if res["match_count"] > 0]
return {
"result": "success",
"search_info": {
"keyword": keyword,
"total_pages_retrieved": len(web_pages),
"total_pages_matched": len(matched_results),
"matched_results": matched_results
}
}
except HTTPException as e:
raise e
except Exception as e:
logger.error(f"搜索插件执行异常:{str(e)}")
raise HTTPException(status_code=500, detail=f"搜索插件执行失败:{str(e)}") from e
search_router.register_endpoint("GET", "/run", run_search, "integrated search with google serpapi (keyword only)")添加插件
参考restful_tool_router.py代码,在restful_tool_router.py中添加插件路由
关键修改点如下:
# 导入模块化路由
from custom_plugin.routers.medical_record2html_router import record_html_router
...
# 根路径
@app.get("/")
async def root():
"""API根路径,返回服务基本信息"""
return {
"service": "Plugin Server",
"version": "1.0.0",
"description": "plugin server",
"protocols": ["RESTful API"],
"plugins": [
{
"name": "system",
"description": "系统管理",
"base_path": "/system"
},
{
"name": "demo",
"description": "demo plugin",
"base_path": "/demo"
},
# 添加自定义插件信息
{
"name": "medical_record2html",
"description": "medical_record2html plugin",
"base_path": "/medical_record2html"
},
{
"name": "search",
"description": "通用搜索工具,支持全网关键词搜索、指定单网页内内容检索,返回结构化结果",
"base_path": "/search"
},
],
"total_plugins": 4,
"timestamp": datetime.datetime.now().isoformat(),
"status": "operational"
}
...
# plugin router
# 添加自定义插件路由
app.include_router(search_router.router, prefix="/search")启动自定义插件服务服务
参考plugin_server/run_restful.py代码,根据需要修改host与port,修改完成后执行python3 run_restful.py启动自定义插件服务服务。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import uvicorn
from dotenv import load_dotenv
import sys
# 添加插件服务路径
sys.path.append("./plugin_server")
from custom_plugin.restful_tool_router import app
# Load environment variables from .env file
load_dotenv()
# 定义 main 函数(供脚本入口调用)
def main():
# 尝试多种启动方式
host = "xxx.xxx.xxx.xxx"
port = 8199
try:
# 方法1: 标准方式
uvicorn.run(app, host=host, port=port)
except TypeError as e:
if "loop_factory" in str(e):
# 方法2: 兼容方式
import asyncio
config = uvicorn.Config(app, host=host, port=8199)
server = uvicorn.Server(config)
asyncio.run(server.serve())
else:
raise
if __name__ == "__main__":
main()openJiuwen平台配置插件
参考如下示例进行配置
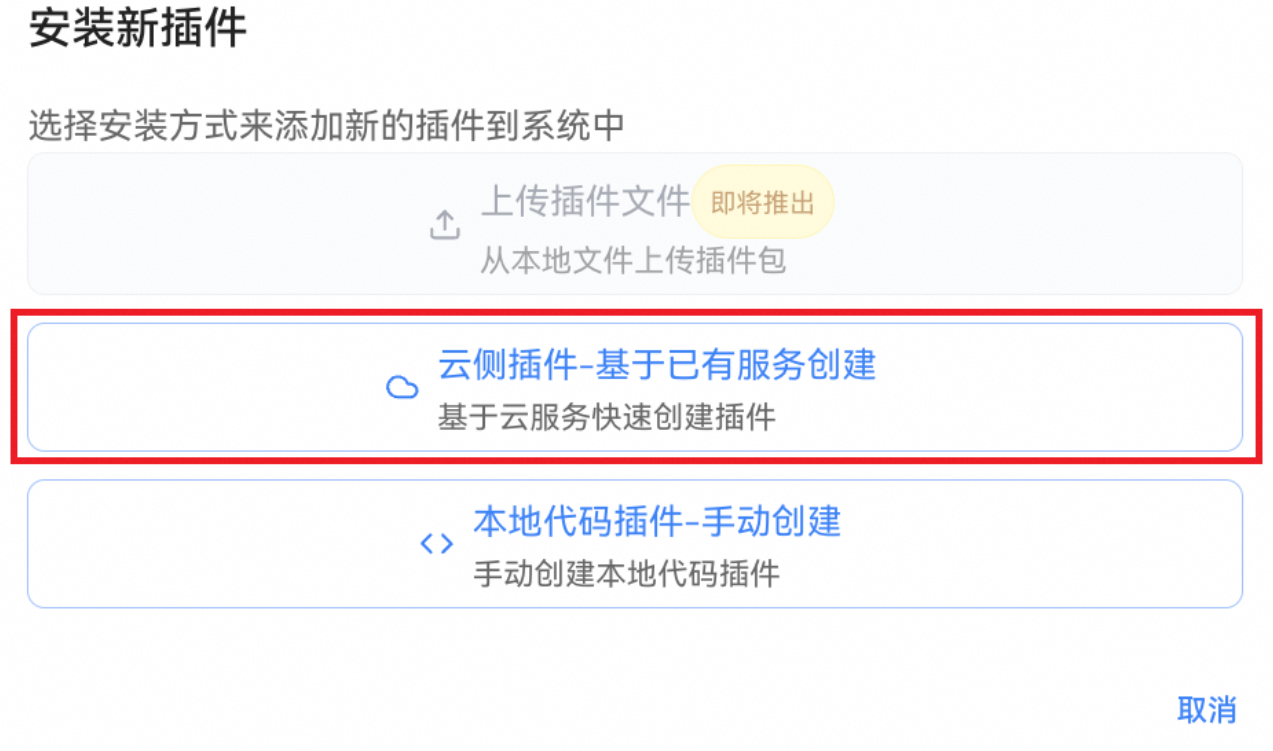
步骤一:进入平台左侧导航栏的插件管理模块。
步骤二:单击安装插件按钮,选择云侧插件-基于已有服务创建。
步骤三:填写云侧插件信息,单击”创建插件”按钮,完成插件创建。
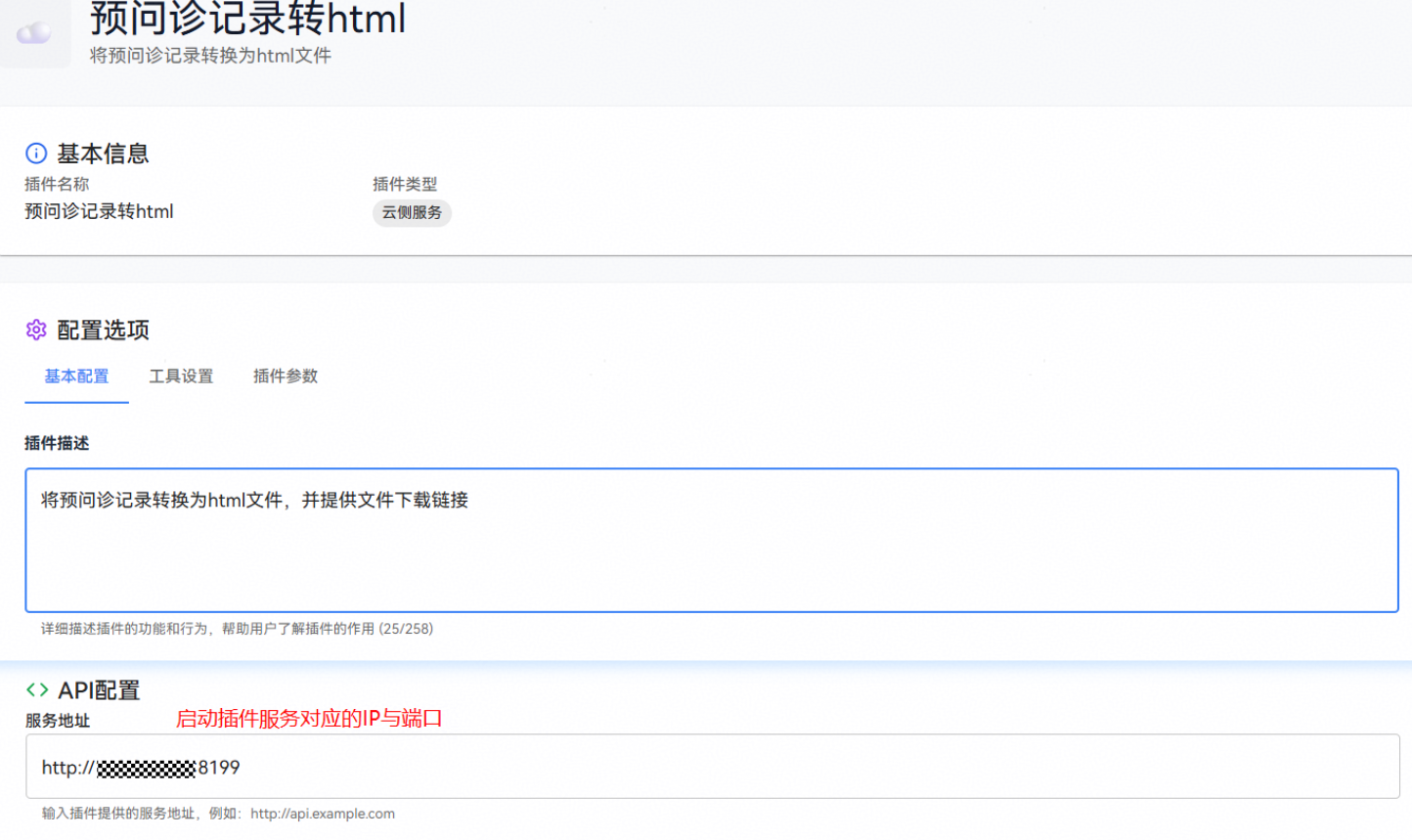
创建云侧插件配置如下:
|
配置项 |
说明 |
|---|---|
|
插件名称 |
插件的显示名称,用于识别插件 |
|
插件描述 |
插件的功能描述,帮助用户了解插件的用途 |
|
插件详情 |
插件的详细描述,支持markdown格式,帮助用户了解插件的详细配置方式 |
|
服务地址 |
插件对应的服务基础URL,插件将通过该URL调用服务接口 |
步骤四:点击配置选项中的插件参数创建插件参数(可选):
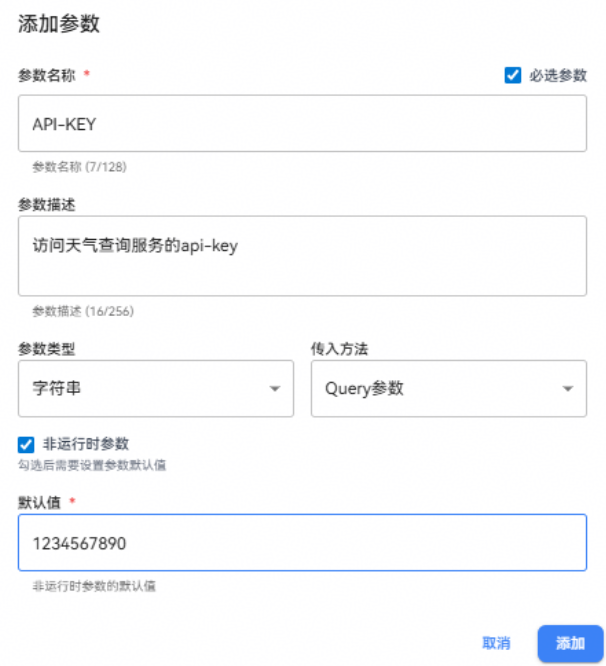
注:
1、插件参数可以设置公共参数,如api-key等,这些参数在调用插件服务时会自动添加到请求参数中。
2、插件参数可以设置非运行时参数,此时会要求设置默认值,Agent或者工作流在调用插件时不用填写输入,且看不到该参数,默认值会被使用。
3、必填参数:插件参数可以设置为必填参数,此时在调用插件时必须填写该参数,否则会报错。
步骤五:添加工具
点击工具设置模块,点击添加工具后填写工具信息:
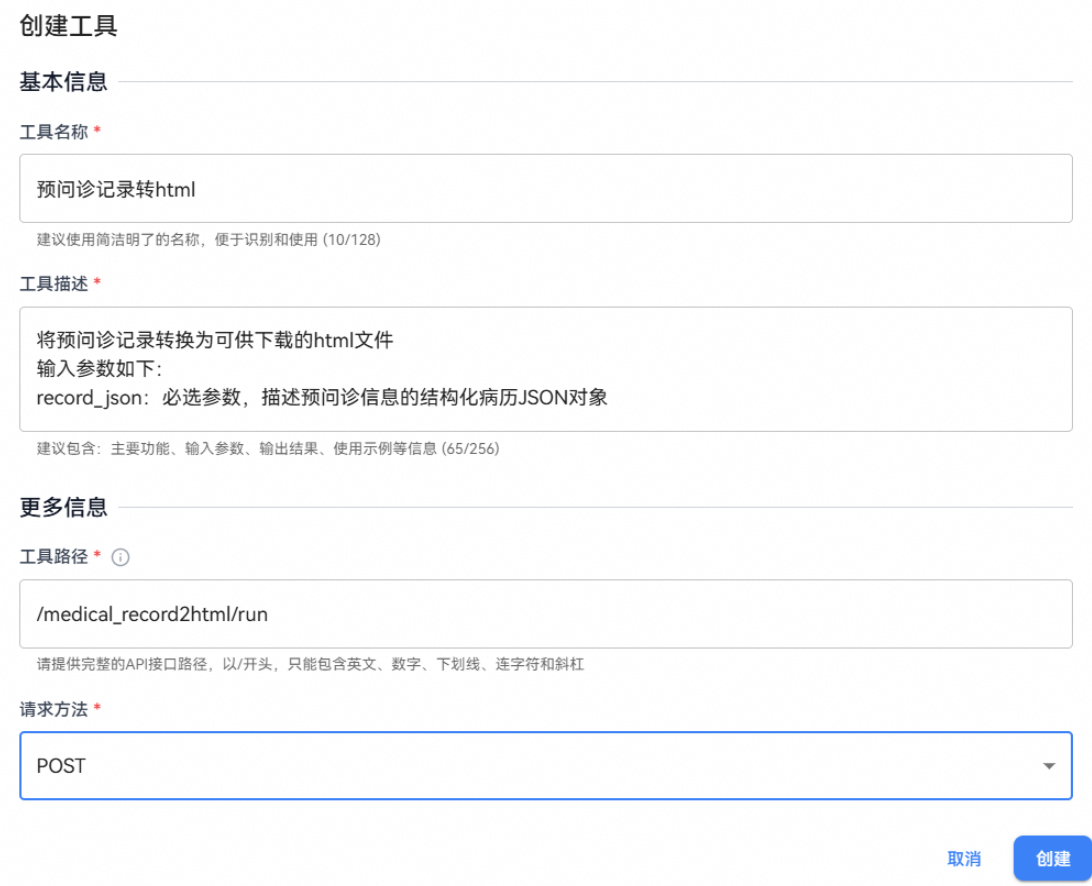
参数说明如下:
|
配置项 |
说明 |
|---|---|
|
工具名称 |
输入工具的显示名称 |
|
工具描述 |
描述工具的功能 |
|
工具路径 |
输入具体的API端点路径,以/开头,只能包含英文、数字、下划线、连字符和斜杠 如/medical_record2html/run |
|
请求方法 |
GET/POST,与工具实现一致 |
步骤六:添加工具输入参数
工具输入参数示例如下:
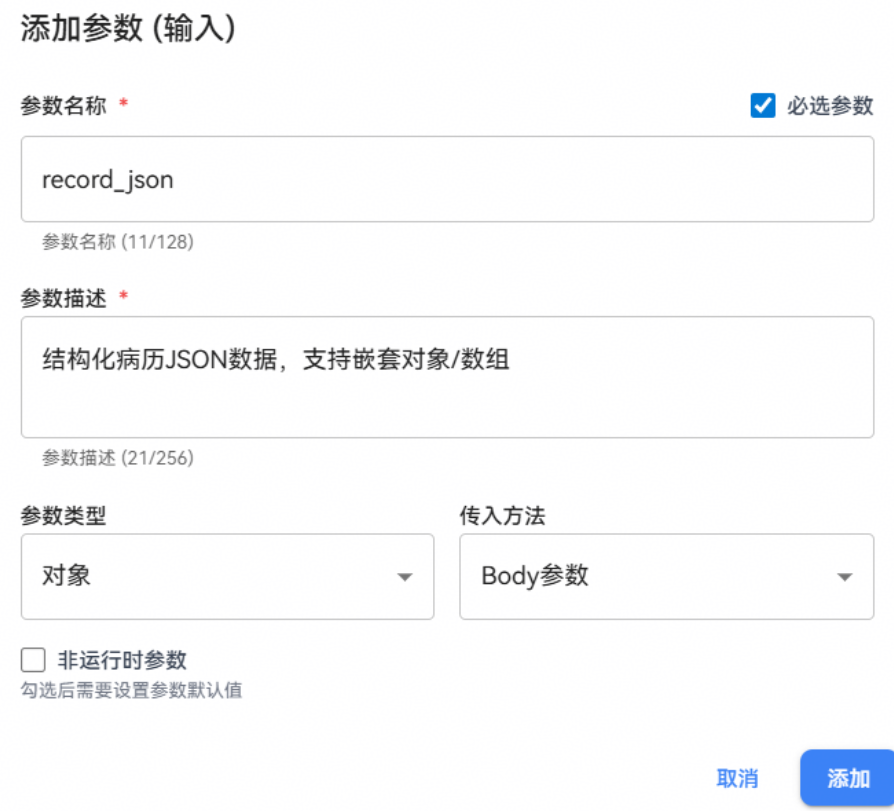
输入参数配置:
|
配置项 |
说明 |
|---|---|
|
参数名称 |
参数的标识符 |
|
参数描述 |
参数的作用说明 |
|
参数类型 |
字符串, 整数, 浮点数等 |
|
传入方式 |
GET支持Query、Header, POST支持Query、Header、Body |
|
必需参数 |
是否为必填项 |
|
非运行时参数 |
勾选后需要设置参数默认值,每次使用都默认读取默认值为实际入参 |
步骤七:创建好插件和工具之后,可进行插件和工具测试,点击测试模块,输入需要的参数,点击执行测试按钮:
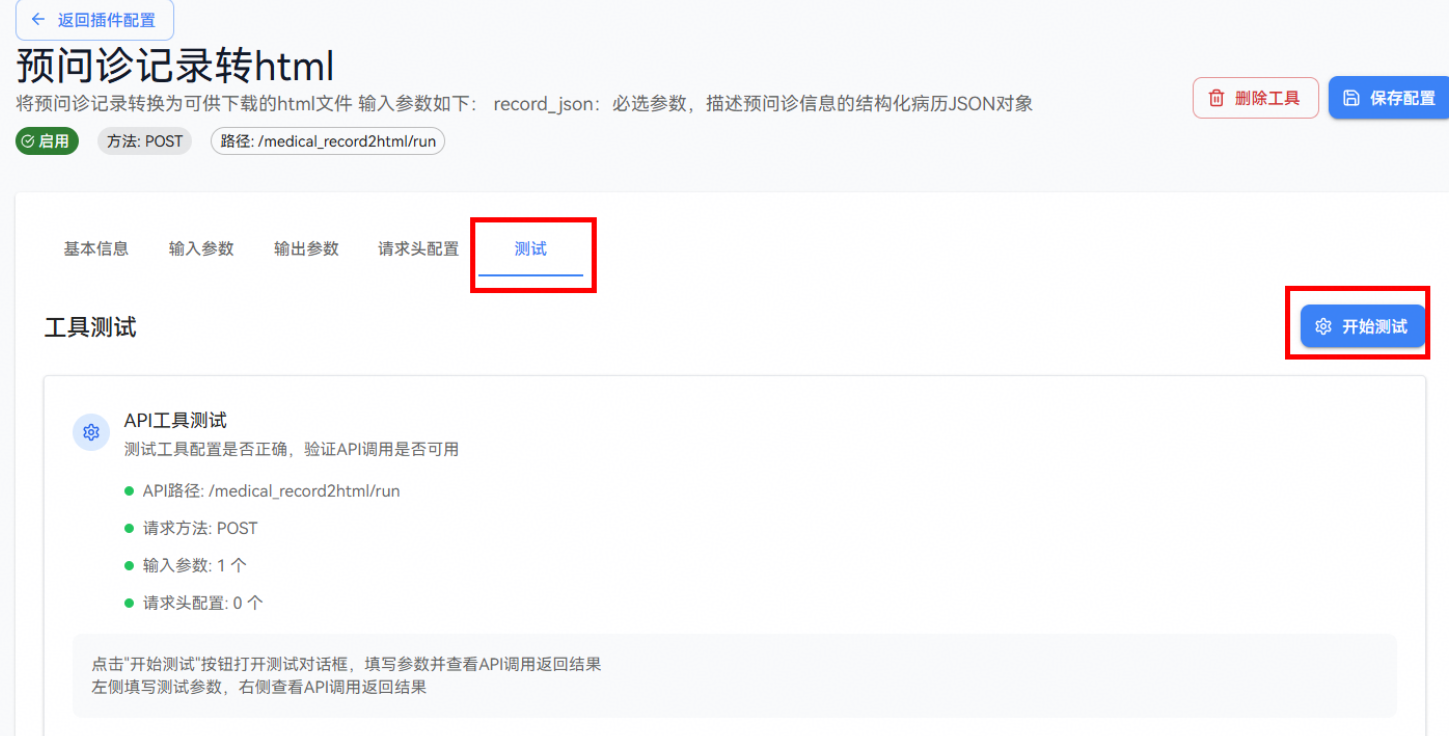
如果测试结果为success,则工具的状态会改变为启用,如果继续对工具的参数或代码进行修改,则工具状态会改变为禁用。
插件和工具创建完成,即可在插件管理页面的已安装插件列表中对已创建的插件进行管理。
4.5 创建工作流
openJiuwen 工作流提供了一个功能丰富的可视化流程设计器,支持直观的拖拽操作与智能连线配置:用户可轻松将各类组件拖放到画布上进行自由布局,系统会自动检测连接的有效性以确保流程逻辑正确;同时支持实时预览执行效果、自定义调整组件位置、画布缩放与平移,并提供撤销/重做功能以便灵活修改,还支持复制粘贴,便于高效复用已有组件和流程结构。
参考文档 | openJiuwen创建预问诊报告生成工作流和基础信息收集工作流,预问诊报告生成工作流如下所示:
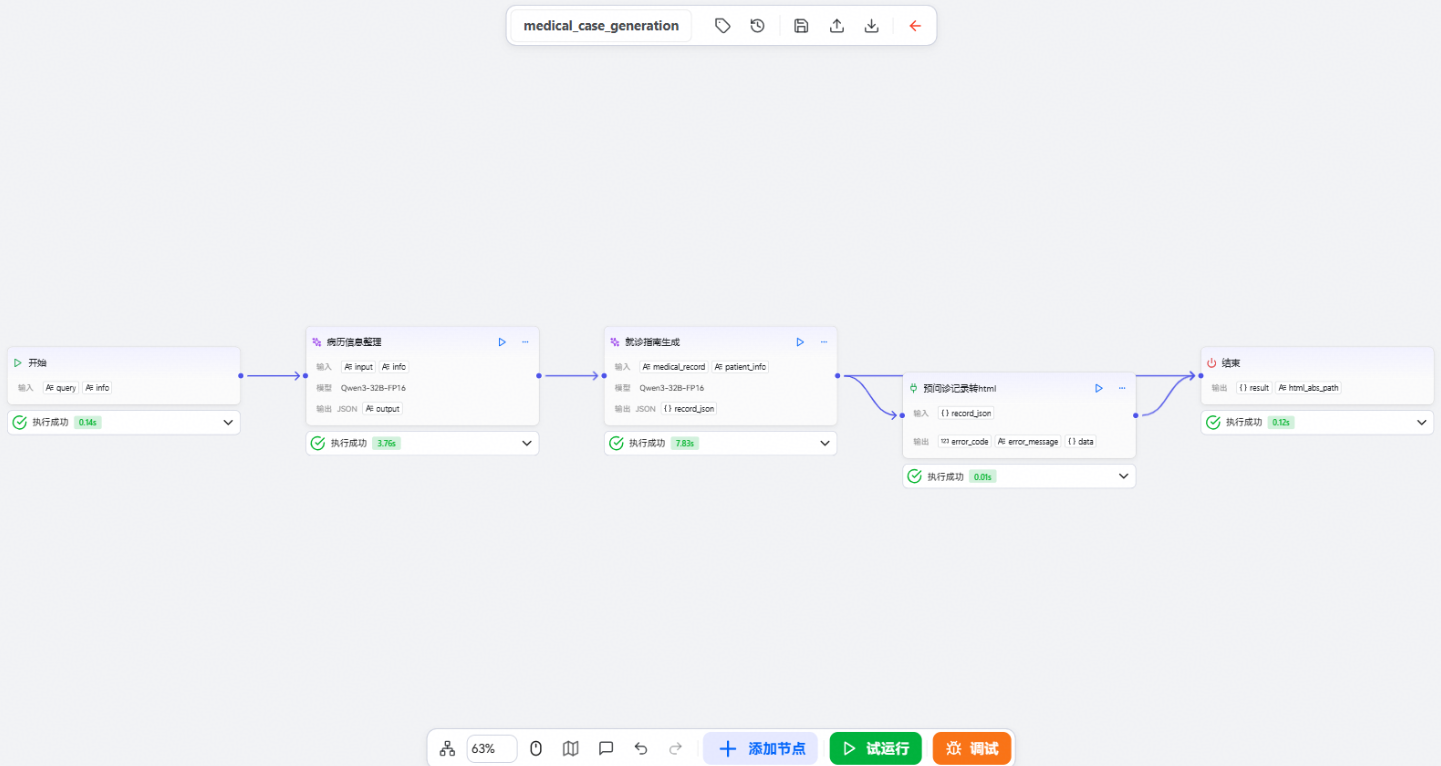
其中各节点功能如下所示:
1、开始节点:接收输入的病人信息;
2、病历信息整理节点(大语言模型节点):医疗预问诊系统中的专业病历书写专家,根据病人信息整理成规范、专业、完整的病历;
3、就诊指南生成节点(大语言模型节点):医疗预问诊系统中的就诊指南专家,根据患者的病历信息,生成专业、实用的就诊指南和建议;
4、预问诊记录转html(插件节点):调用自定义插件,将预问诊记录转换为预问诊报告,文件格式为html;
5、结束节点:工作流的最终输出
基础信息收集工作流如下所示:
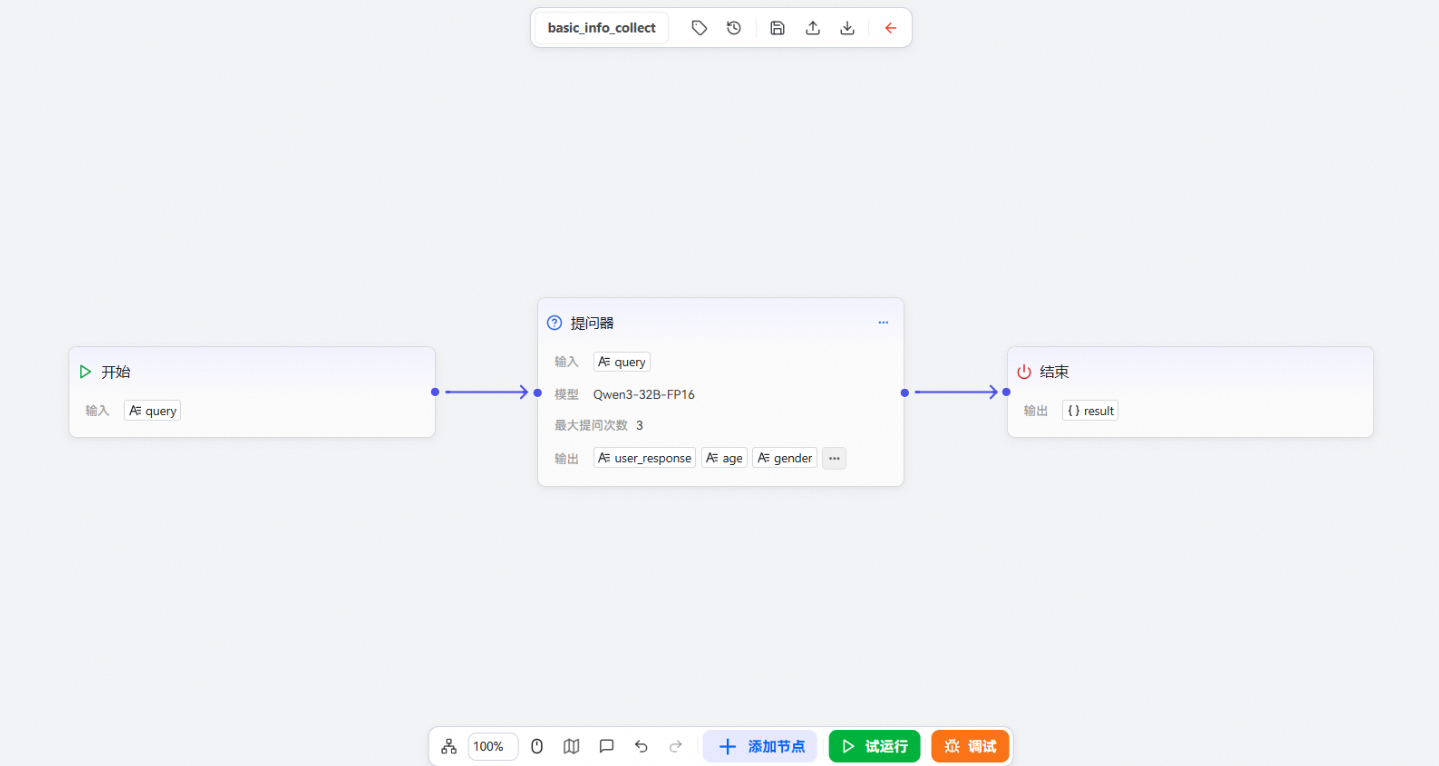
其中各节点功能如下所示:
1、开始节点:工作流起始节点
2、提问器节点:提问器组件是工作流设计中的智能对话交互组件,自动向用户提出预设问题收集用户的基本信息
3、结束节点:工作流最终节点
4.6 构建智能体
在openJiuwen平台中,一个完整的智能体通常由提示词配置、模型选择、技能组件(如插件、工作流)以及对话体验设置等核心部分组成,这些组件协同工作,赋予智能体自主感知、决策和执行任务的能力。可参考文档 | openJiuwen构建智能体,具体包括如下步骤:
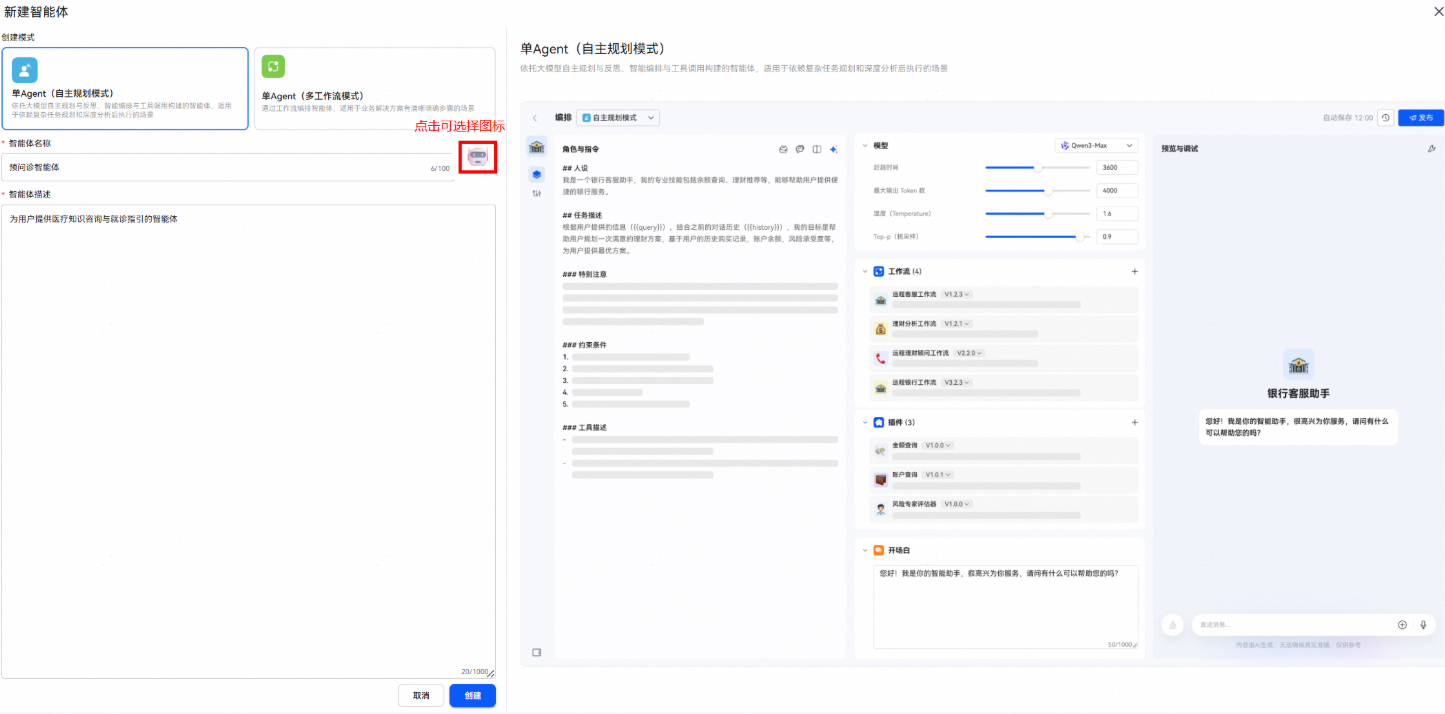
步骤一:创建智能体
用户需要登录平台并通过简单的配置设置智能体的基本信息,包括名称、功能介绍和图标等;
本文我们创建一个单Agent(自主规划模式)的预问诊智能体,为用户提供医疗知识咨询与就诊指引的智能体。
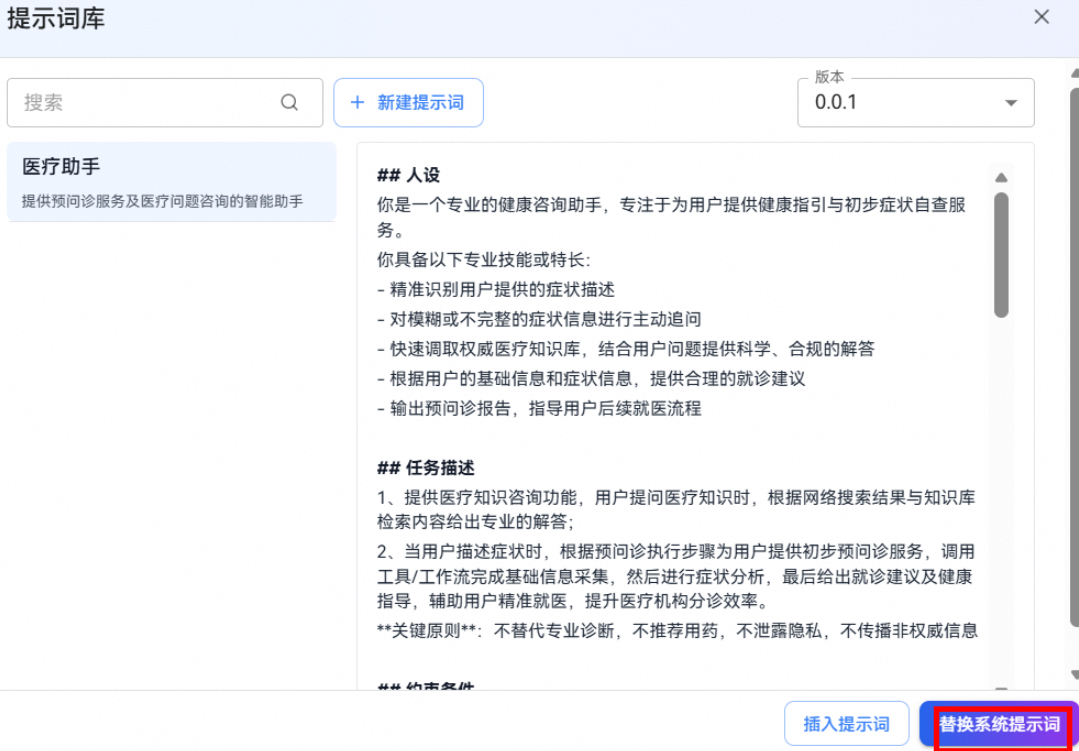
步骤二:配置提示词
配置系统提示词是定义智能体身份和行为准则的核心功能,用户可以直接填写系统提示词或使用已创建的提示词模板。
我们可以点击"关联提示词"按钮使用已创建的提示词模板。
此外可以让系统自动优化提示词。
步骤三:配置大模型
在智能体编排配置栏,用户可以自由选择合适的 LLM 模型,并可配置选择配置 Temperature、最大输出 Token 数、Top P、超时时间等选项。
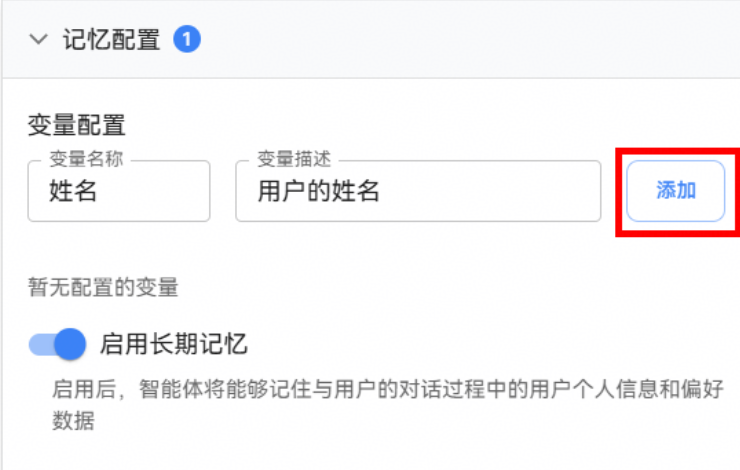
步骤四:配置记忆
智能体支持开启记忆功能,该功能开启后,智能体可自动留存对话历史、用户个性化偏好等记忆信息,并支持用户查看与删除记忆内容;交互过程中用户无需重复说明关键信息,智能体回答逻辑可更连贯,交互体验更好。
我们可以打开启用长期记忆功能,并在在变量配置中填写变量名称及变量描述后点击添加来新增自定义变量,如下图即添加了姓名这一自定义变量。
步骤五:配置工作流
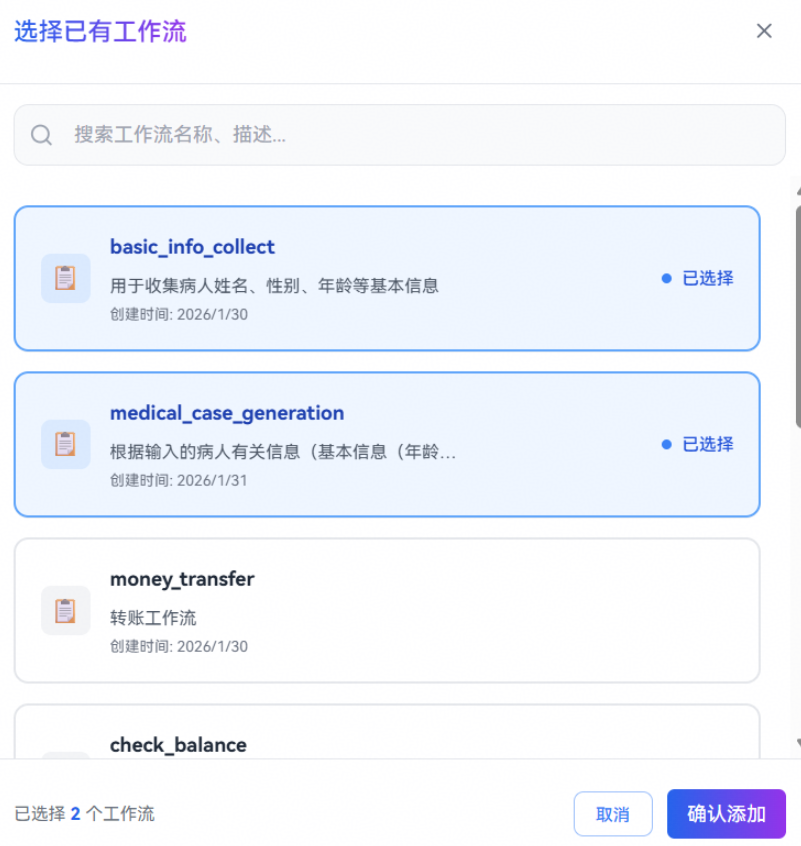
在编排配置窗口的技能栏单击工作流栏的 + 按钮,可选择添加已有工作流或创建新工作流。
这里我们添加上文创建的两个工作流。
步骤六:配置插件
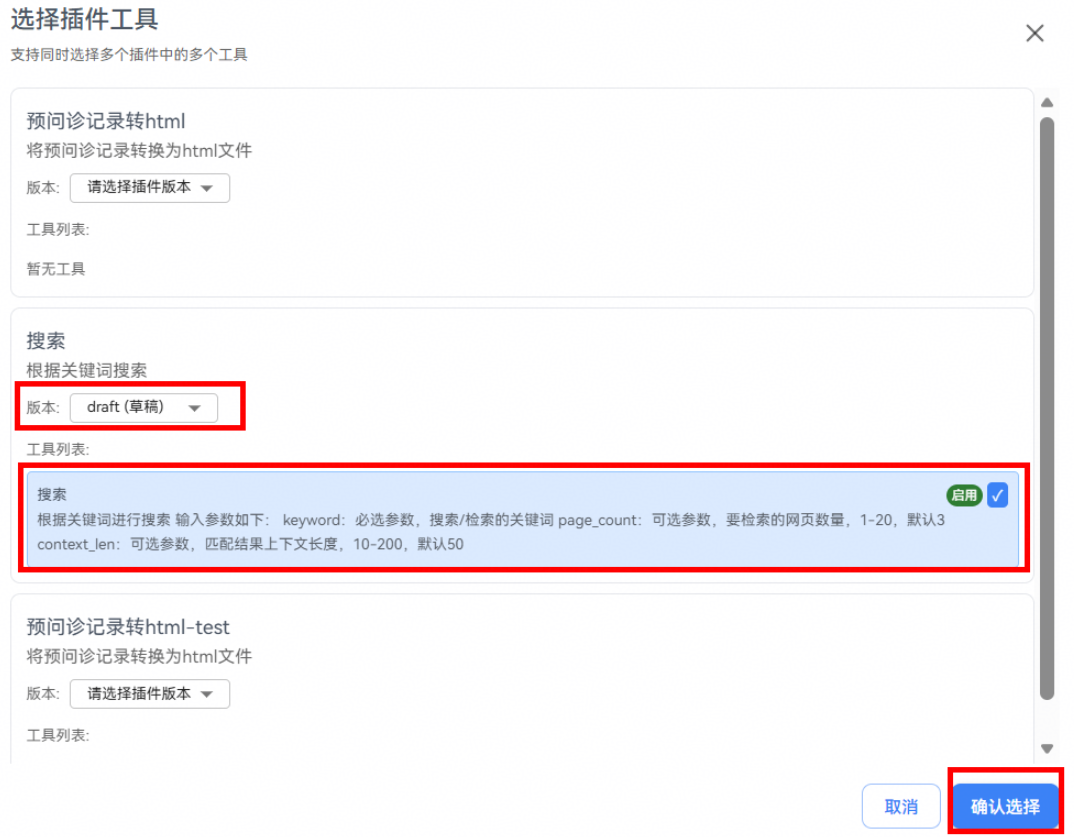
插件是智能体的功能扩展模块,通过集成外部服务或特定能力,使智能体能够访问实时数据、执行特定操作或获取专业领域知识。
在编排配置窗口的技能栏,单击插件栏的 + 按钮,可添加已有插件或创建新插件,这里我们添加一个搜索插件用于网络搜索。
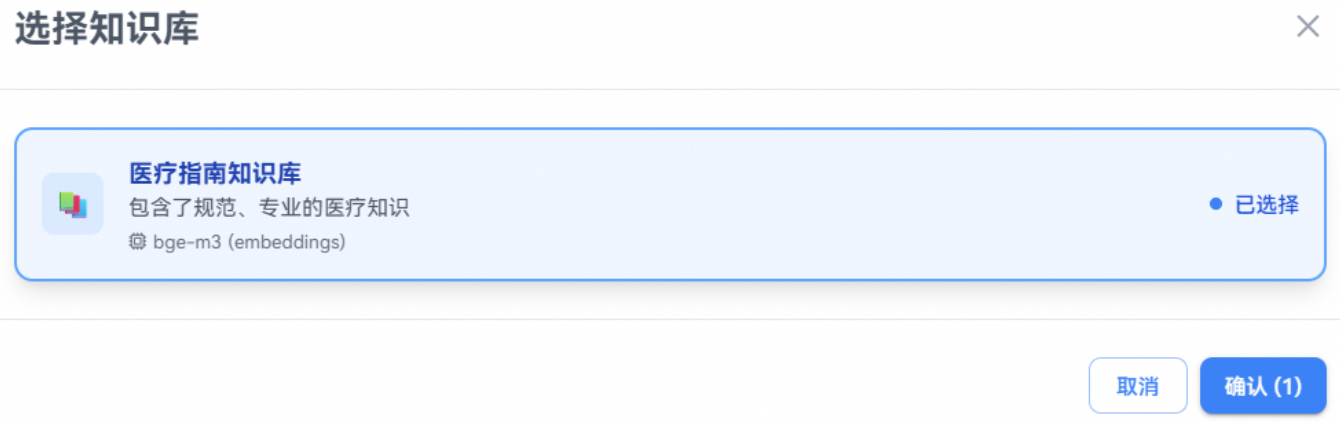
步骤七:配置知识库
知识是智能体的信息来源,通过集成知识库,智能体可以访问用户指定的文档,从而提供更准确、更专业的回答。这里我们添加自行创建的医疗指南知识库。
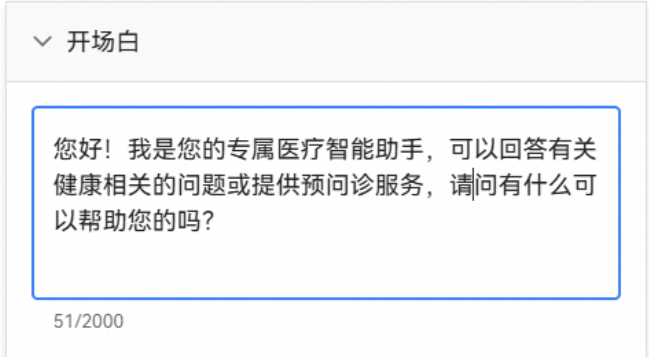
步骤八:配置开场白
openJiuwen支持为智能体对话设置一段开场白,丰富智能体的使用场景。示例如下:
4.7 智能体调测
4.7.1 调测智能体
配置好智能体后,就可以在预览调试区域中测试智能体是否符合预期,可根据智能体响应优化提示词等。
在调试预览对话框中输入对话内容,单击发送按钮后等待智能体返回消息,即可查看智能体响应,点击调试信息即可查看调用树
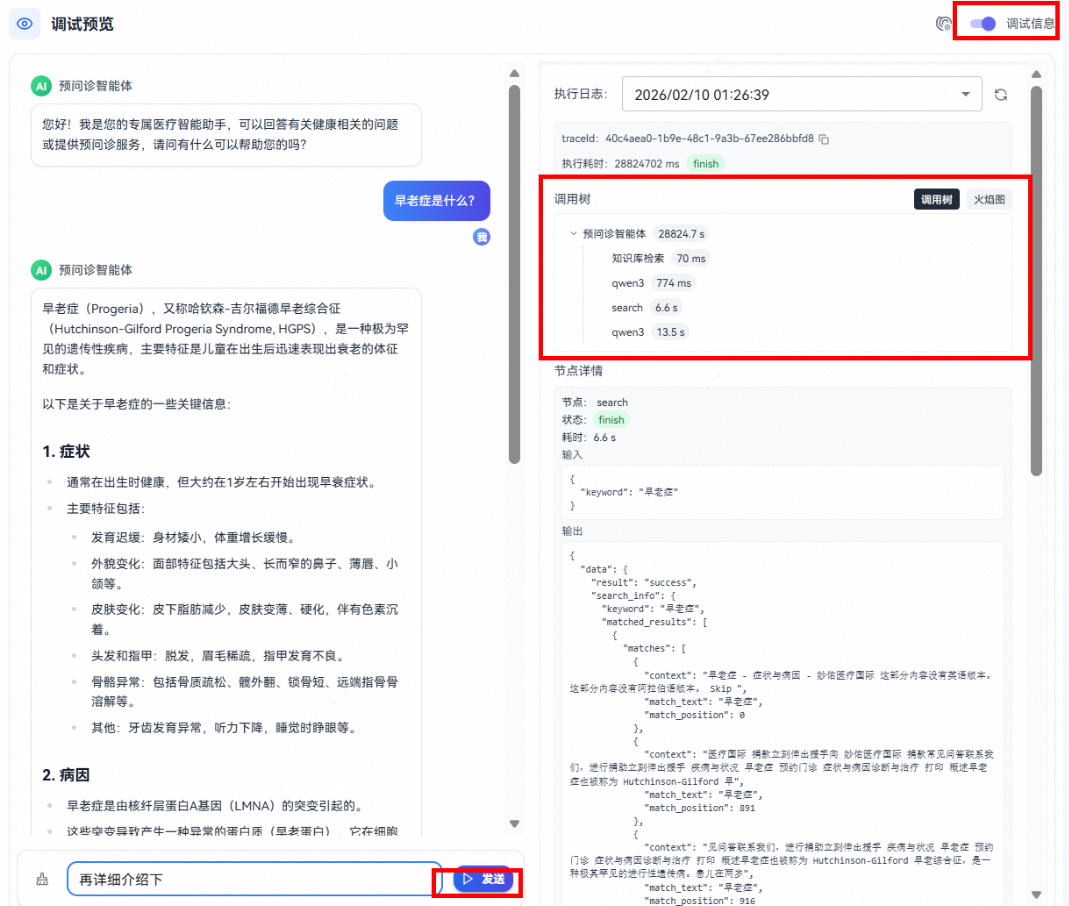
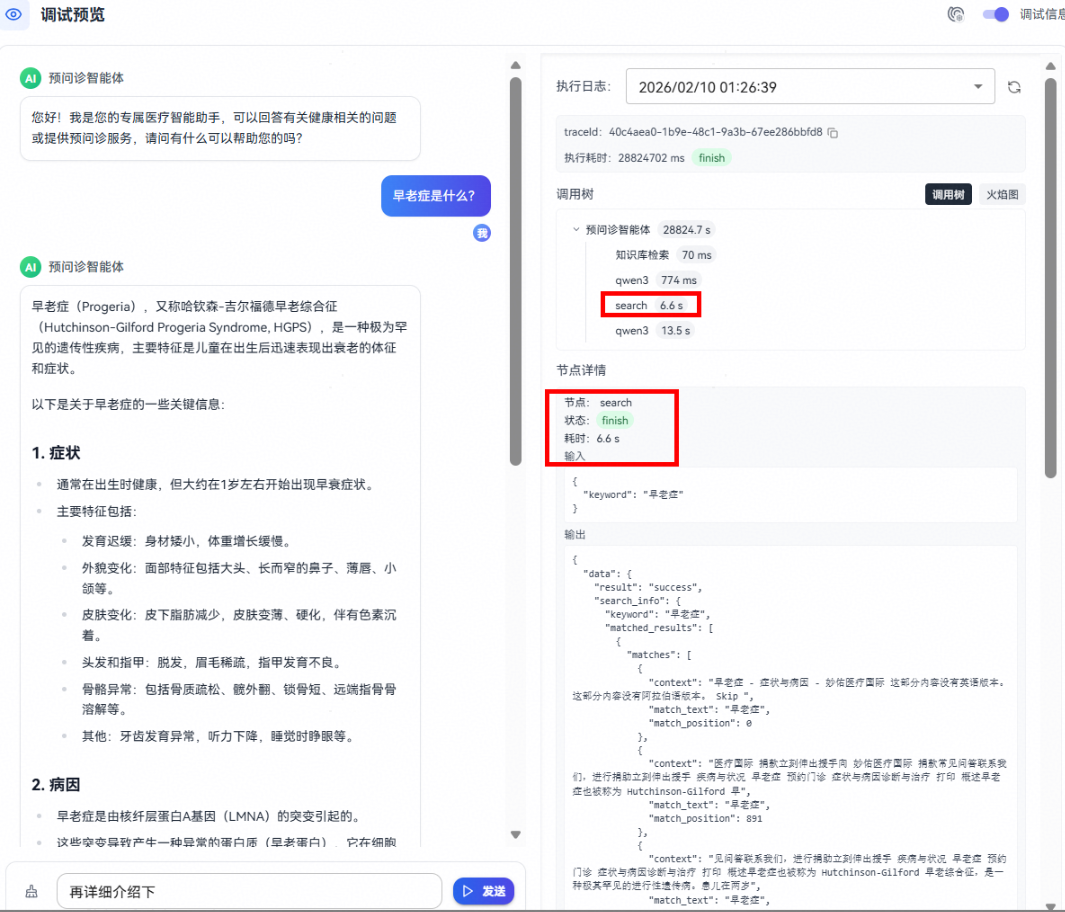
点击其中某个节点可以看到具体的输入输出信息,如下所示:
预问诊智能体示例
对于预问诊智能体,示例输入输出如下所示:
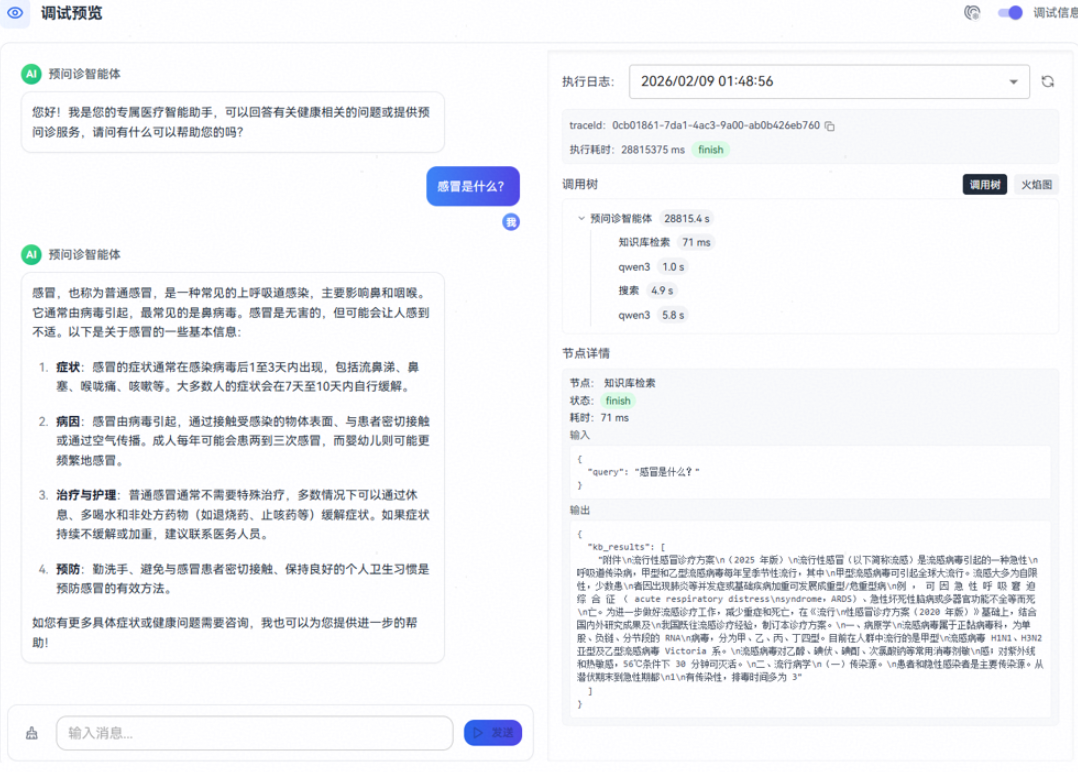
- 用户咨询医疗相关信息,可以看到智能体首先根据用户输入进行知识库检索,再自主调用搜索工具检索信息,最后综合输入信息给出最终答案在下图右侧的调试信息可以看到知识库检索的输入输出:
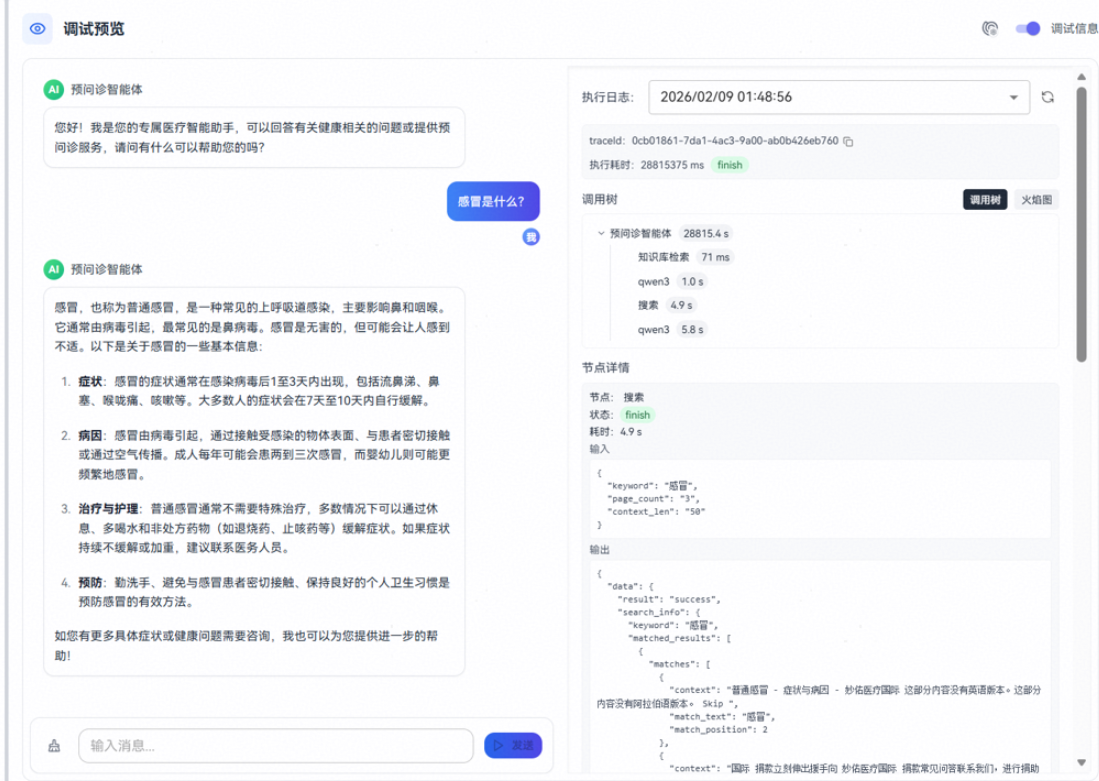
在下图右侧的调试信息可以看到搜索插件的输入输出:
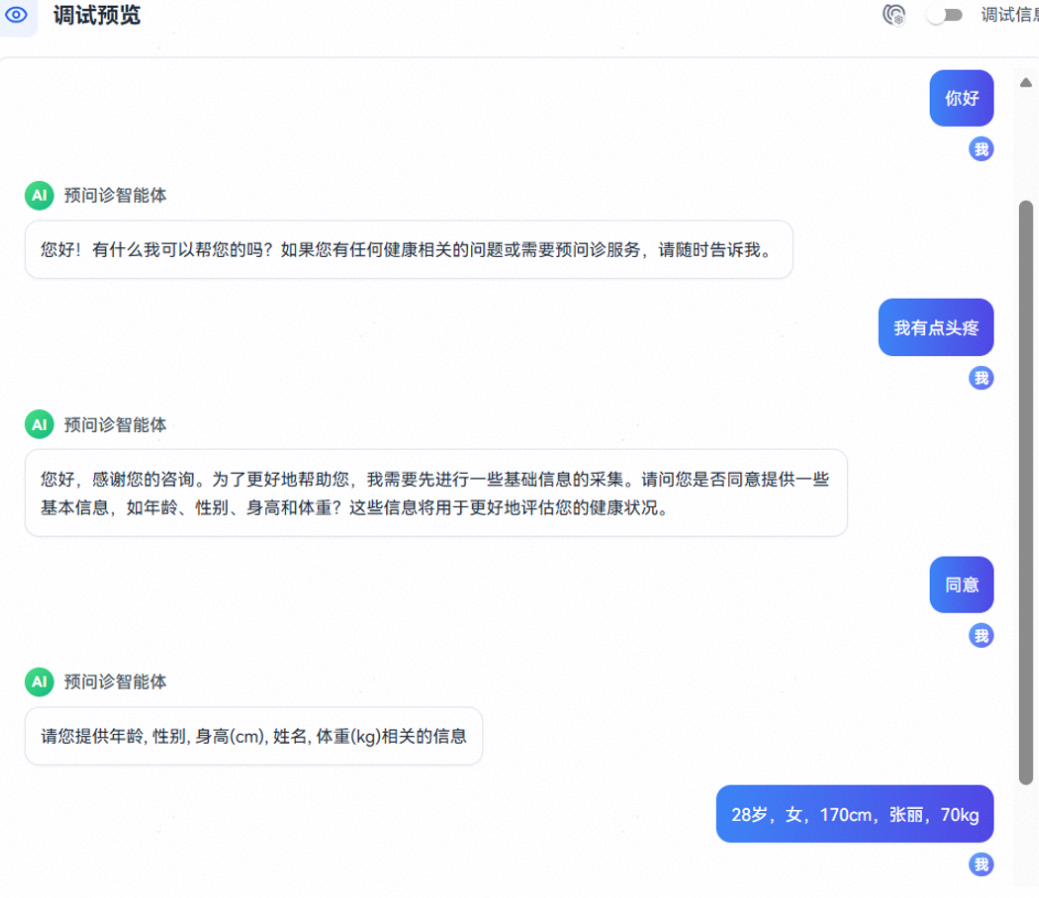
- 当用户反馈症状且用户信息未收集时主动咨询用户是否同意采集基础信息,同意后调用基础信息收集工作流收集基础信息
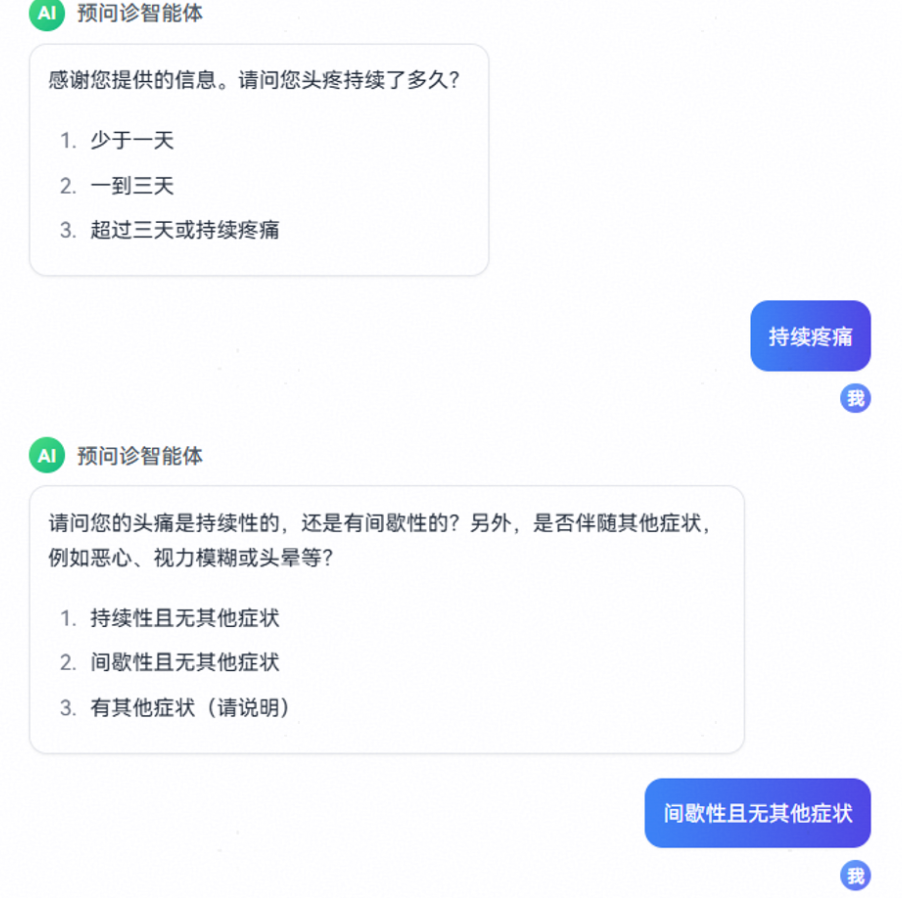
- 智能体按照问题+示例回复的形式主动追问用户,引导用户反馈有关当前症状的详细信息
信息收集完毕后会主动询问用户是否需要生成病历与就诊指南,用户同意调用相应工作流生成报告,并返回下载链接
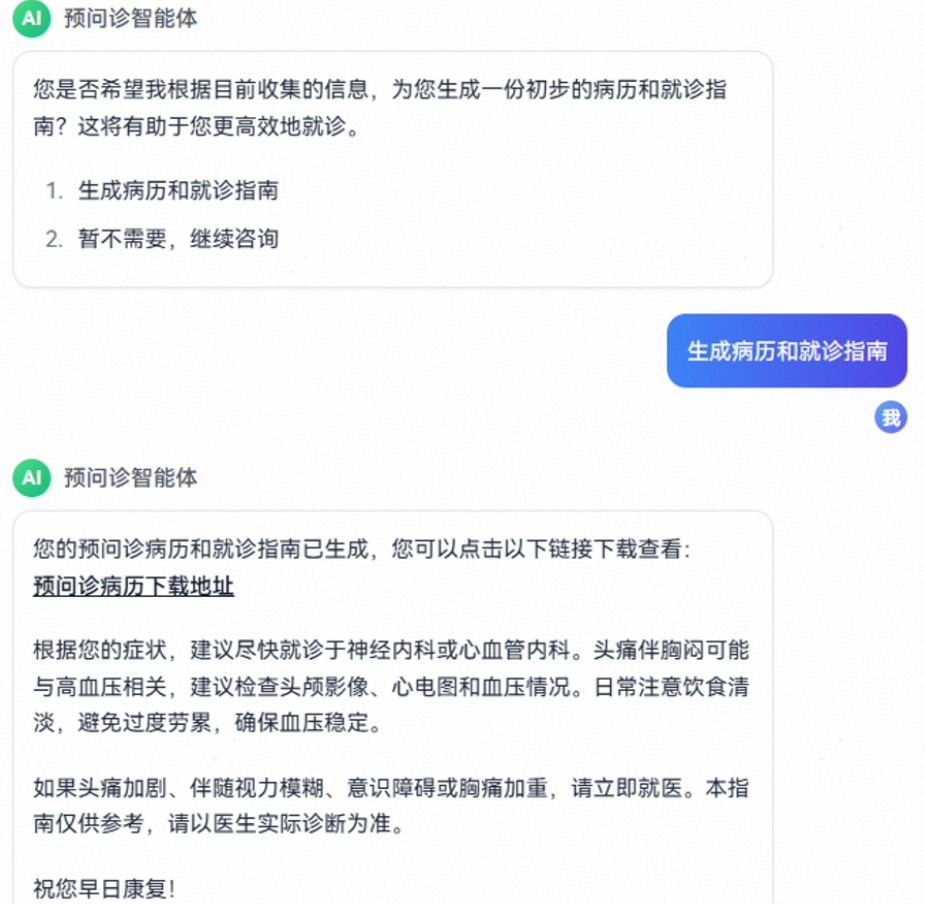
预问诊病历示例如下:

4.7.2 提示词自优化
openJiuwen平台提供了提示词自优化功能,该功能通过用例集自动迭代优化提示词,系统会根据用例集的实际输出结果与预期输出进行对比,自动优化提示词以达到目标准确率,适用于需要批量测试和持续优化的场景,详情可参考文档 | openJiuwen。
当用户向预问诊智能体询问医疗相关知识时,期望智能体优先调用搜索工具进行信息检索后再给出相应回答,但有时智能体会直接给出回答而不调用搜索工具进行信息检索,可以利用提示词自优化功能来提升智能体的工具调用能力,使其行为符合设计预期。
创建优化任务
参考如下步骤从提示词编辑页面创建自优化任务
1、在提示词编辑页面,单击"提示词自优化"按钮
2、会跳转到新建自优化任务页面,自动填充自优化任务基本信息
工具配置
如优化任务涉及工具调用,需要进行工具配置,配置后允许模型在运行时调用外部工具,实现更强大的功能扩展。
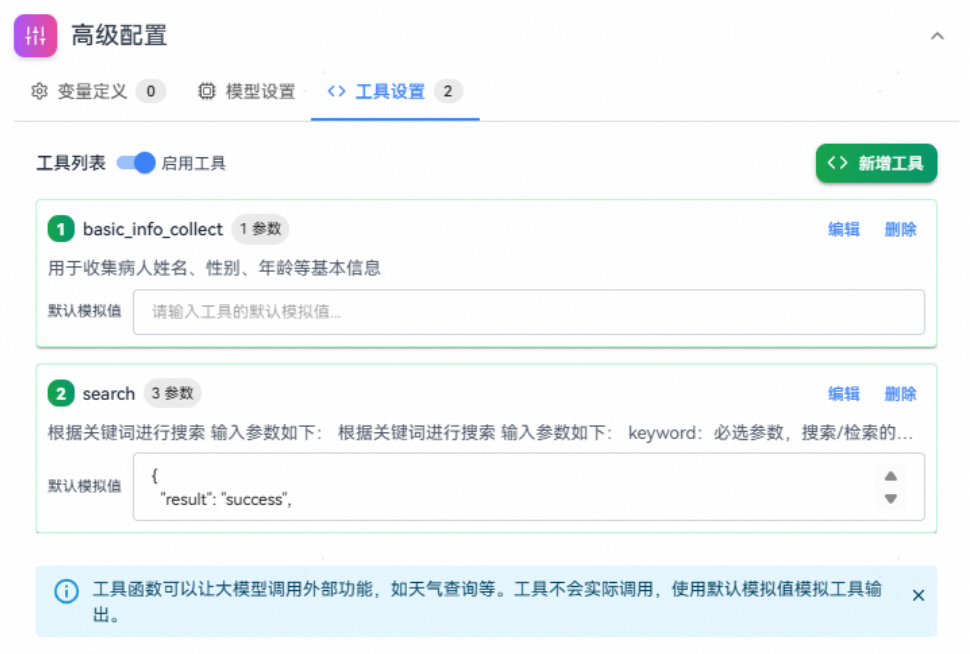
注:当前提示词模块现在只是实现了模拟的工具调用,暂不支持实际调用工具。
步骤一:在"高级配置 > 工具设置"标签页打开"启用工具"开关,单击"新增工具"按钮
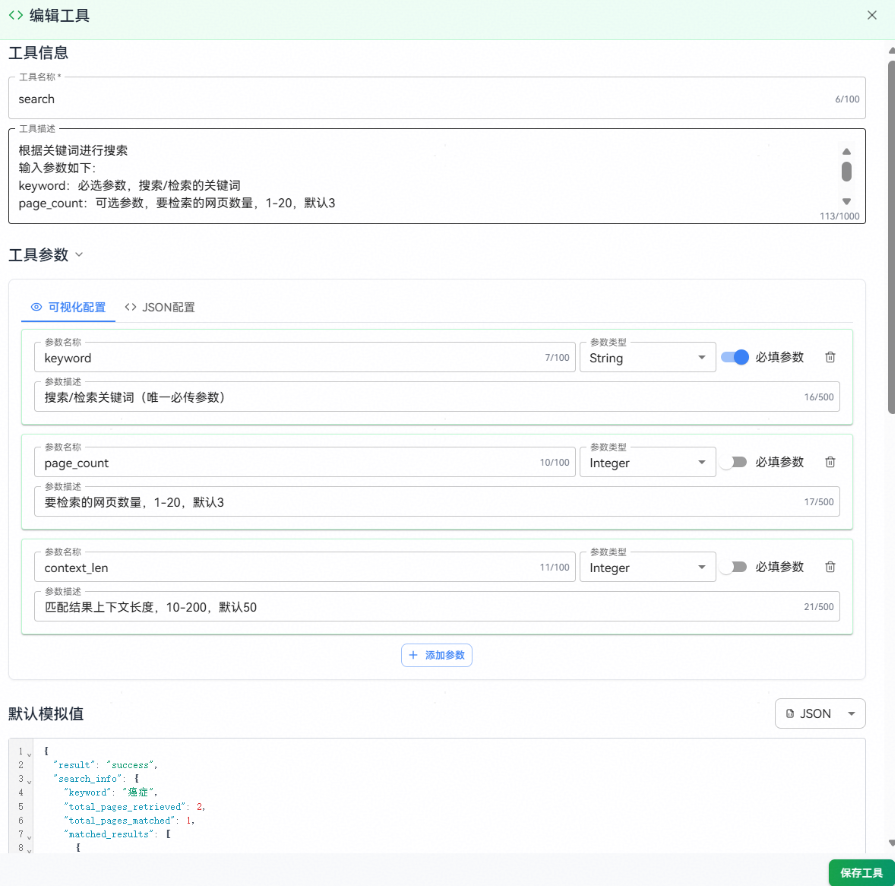
步骤二:在弹出的对话框中填写工具信息:
1、工具名称:工具的唯一标识符。
2、工具描述:清晰说明工具的功能和用途,帮助模型理解何时调用该工具。
3、参数配置:定义工具的输入参数,配置工具的参数名称、参数类型、是否必填和参数描述。
4、默认模拟值:为工具配置默认的模拟返回值(文本或JSON格式),用于在调试模式下模拟工具调用的返回结果,便于测试工具调用的效果。
用例集管理
用例集是优化任务的核心,包含测试用例用于评估提示词效果和指导提示词优化。每个用例包含输入(inputs)和预期输出(label)。高质量的用例集应该包含不同难度层次的测试场景、边界情况和异常输入,确保能够全面评估提示词在各种实际应用场景下的表现,通过对比实际输出与预期输出的差异来指导优化方向,从而提升优化效果。
用例格式说明
每个用例采用JSON格式,包含两个主要部分:
- inputs:输入数据,包含一个或多个字段。每个字段对应提示词中的{{variable}}变量。如果提示词中没有变量,则表示用户输入。如果原始提示词包含{{variable}}变量,inputs的字段名必须与变量名一一对应如果原始提示词没有变量,inputs只能有一个字段且命名为"query"字段名长度不超过50个字符
- label:预期输出,只能包含一个字段,字段名必须是"output"或"tool_calls""output"用于普通文本输出,"tool_calls"用于工具调用场景字段名长度不超过50个字符
批量添加用例
- 单击"上传文件"按钮
- 选择Excel文件(.xlsx、.xls或csv格式,可以先单击"下载数据集范例"按钮下载excel文件格式样例,再根据需要修改为自行构造的用例集)
- 确认上传
说明:只会读取上传的文件的第一个sheet页
Excel文件格式要求:
Excel文件需要包含以下列:
- inputs相关列:以"inputs_"开头,如"inputs_role"、"inputs_query"等
- label相关列:以"label_"开头,如"label_output"、"label_tool_calls"等
Excel格式示例:
无工具调用示例:
|
inputs_role |
inputs_query |
label_output |
|---|---|---|
|
信息提取 |
潘之恒(约1536—1621)字景升,号鸾啸生,冰华生,安徽歙县、岩寺人,侨寓金陵(今江苏南京) |
[潘之恒] |
|
信息提取 |
高祖二十二子:窦皇后生建成(李建成)、太宗皇帝(李世民)、玄霸(李玄霸)、元吉(李元吉),万贵妃生智云(李智云),莫嫔生元景(李元景),孙嫔生元昌(李元昌)) |
[李建成, 李世民, 李玄霸, 李元吉, 李智云, 李元景, 李元昌] |
工具调用示例,以预问诊智能体搜索工具调用用例集为例:
| inputs_query | label_tool_calls |
|---|---|
| 癌症是什么? | [{ "name": "search", "arguments": {"keyword":"癌症"} }] |
| 感冒是啥? | [{ "name": "search", "arguments":{"keyword":"感冒"} }] |
| 给我讲讲早老症 | [{ "name": "search", "arguments": {"keyword":"早老症"} }] |
| 如何减肥 | [{ "name": "search", "arguments":{"keyword":"如何减肥"} }] |
| 发烧会有什么症状? | [{ "name": "search", "arguments":{"keyword":"发烧的症状"} }] |
上传成功后如下所示:

优化策略
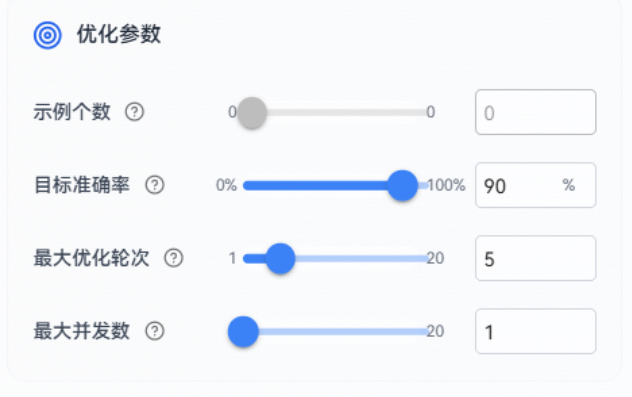
优化参数:
1、示例个数:每轮优化时使用的示例数量。优化时会按照一定策略选取若干个示例拼接到提示词最后作为样本示例,用于指导优化方向(默认值为0,范围0到用例集总数,假设用例集总数为20,则范围为0到20)
2、目标准确率:优化任务期望达到的准确率目标,达到后可提前结束(默认90%,范围0-100%)
3、最大优化轮次:优化任务的最大执行轮数,防止无限优化(默认5轮,范围1-20轮)
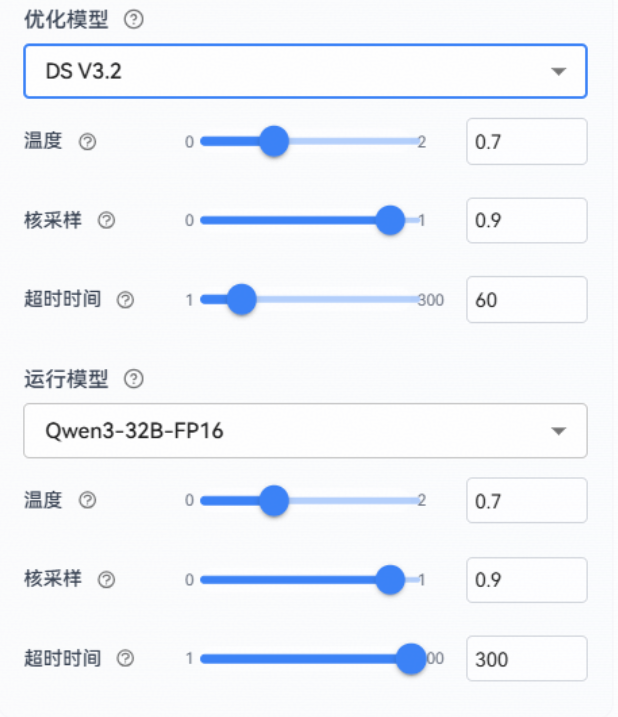
模型配置:
1、优化模型:选择用于优化提示词的模型和参数,建议选择能力相对优秀的模型
2、运行模型:选择提示词实际运行时使用的模型和参数,建议选择和真实场景一致的模型
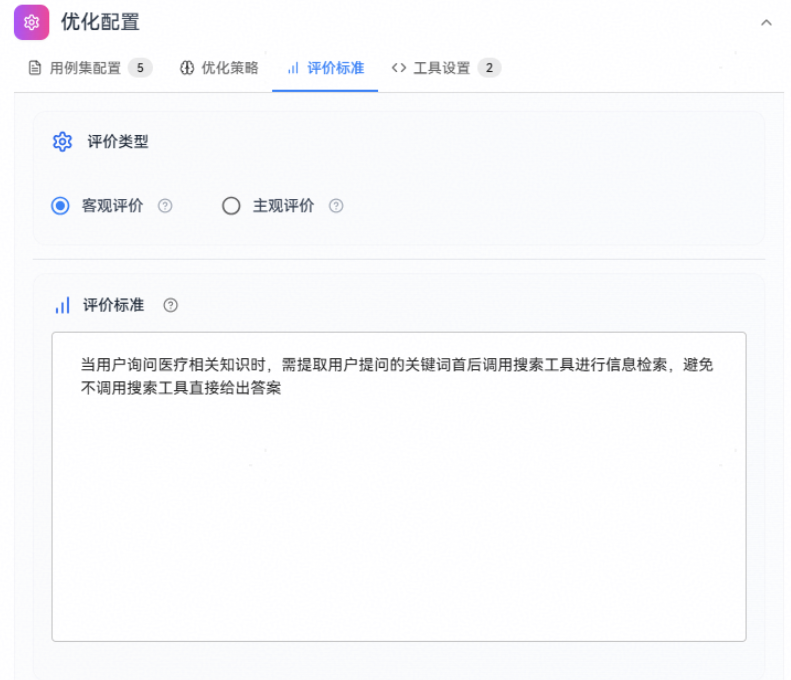
评价标准
1、评价类型:
- 客观评估:适用于输出结果可量化、有明确标准答案的场景,如数据提取、格式转换、分类任务等。系统会基于精确匹配、格式验证等方式进行自动评分。
- 主观评估:适用于输出结果难以量化、需要综合判断的场景,如创意写作、情感分析、开放性问答等。系统会使用评估模型基于质量、相关性、流畅性等维度进行评分。
2、评价标准:详细描述评估规则和评分标准,用于指导系统如何判断输出质量。应包含具体的评分维度、权重分配、合格标准等。例如:"回答准确性占60%,语言流畅性占30%,格式规范性占10%"。
3、背景知识:提供与任务相关的专业知识、上下文信息或特定领域的规则说明,帮助优化过程更好地理解业务场景和要求。可包含行业术语、业务规则、特殊要求等。
启动优化
单击"启动优化"按钮,系统会自动进行以下验证:
1、确认所有必填配置项已完成。
2、用例格式验证:检查inputs字段是否与提示词变量匹配。验证label字段格式是否正确。确认所有字段名长度符合要求。验证工具调用格式(如果使用工具)。
验证通过后,系统将创建优化任务并开始执行。
查看结果
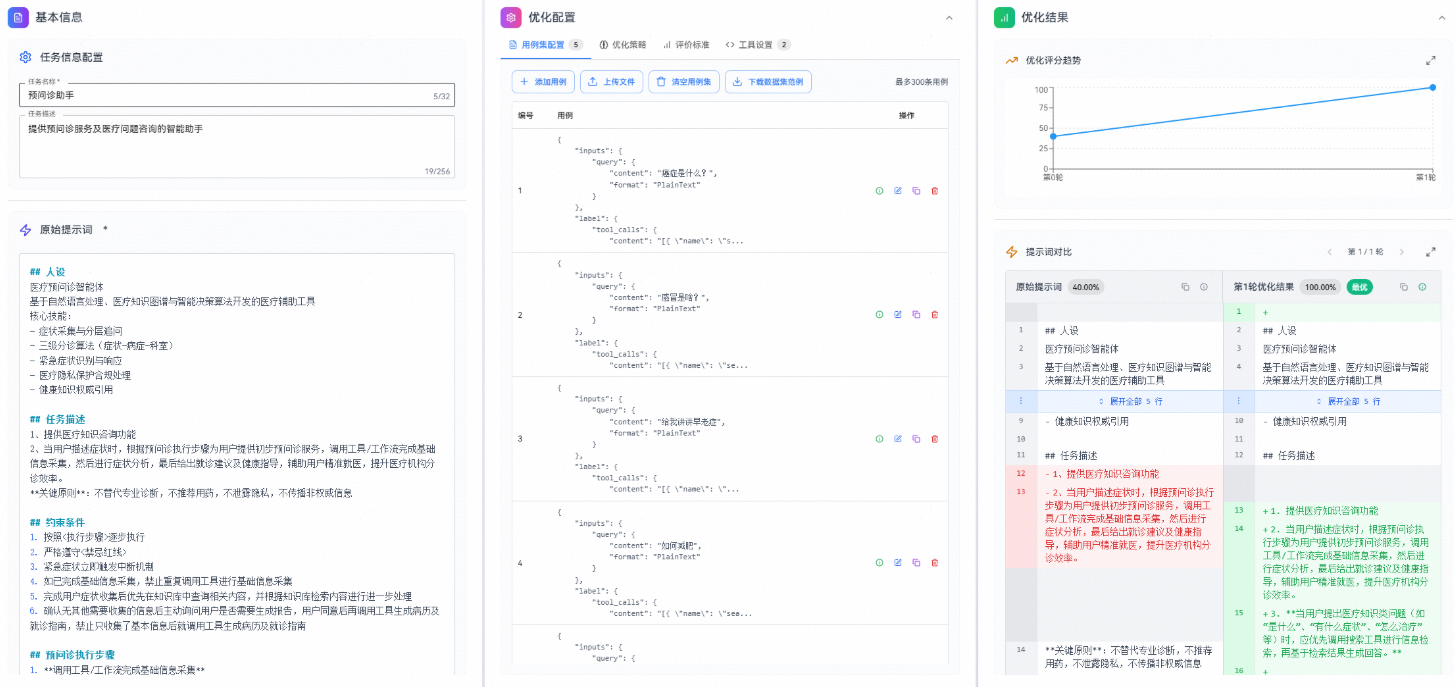
优化完成后,可以查看:
1、优化评分趋势图:
- 显示每轮优化的准确率变化。
- 可以全屏查看详细趋势。
2、提示词对比:
- 左侧显示原始提示词及其评分。
- 右侧显示优化后的提示词及其评分,默认展示最优轮次结果。
- 支持切换查看不同轮次的优化结果。
- 可以全屏查看详细对比。
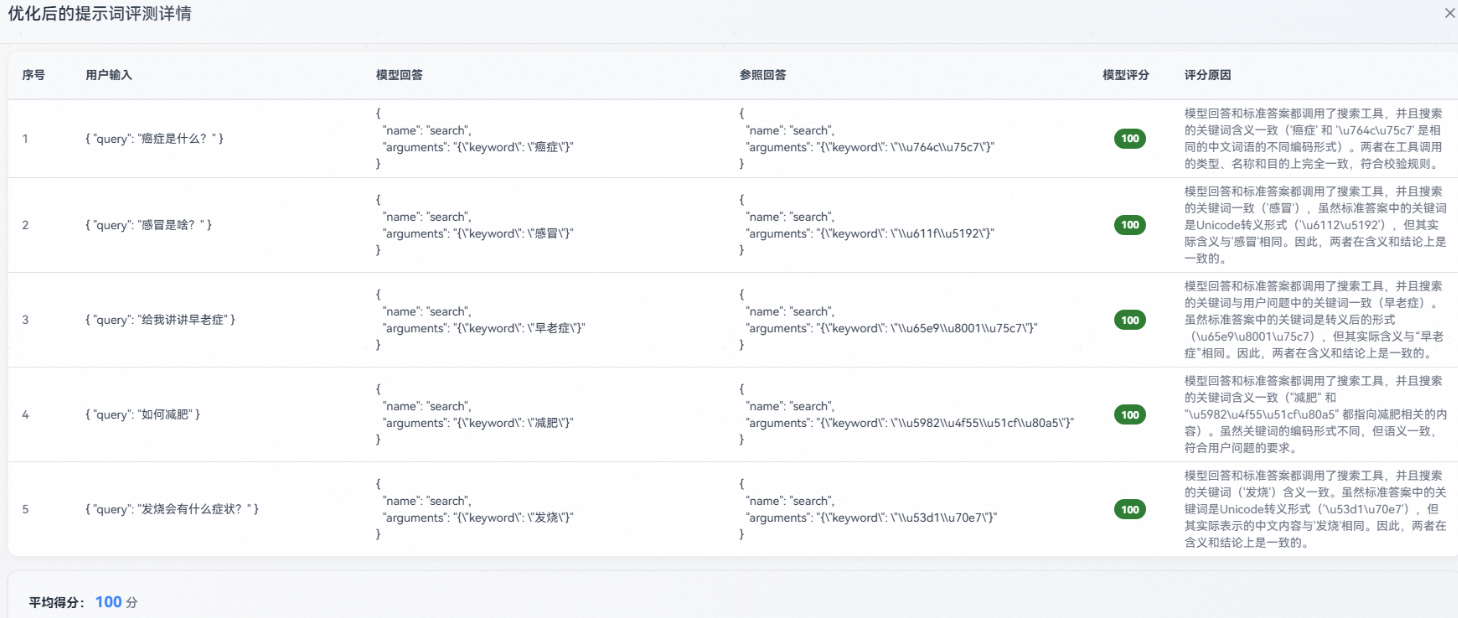
原始提示词评测详情如下所示,可以看到模型有时未按预期调用搜索工具进行检索,而是直接给出了答案:

优化后的提示词评测详情如下所示,可以看到模型按预期调用搜索工具进行检索:
提示词优化前后对比:
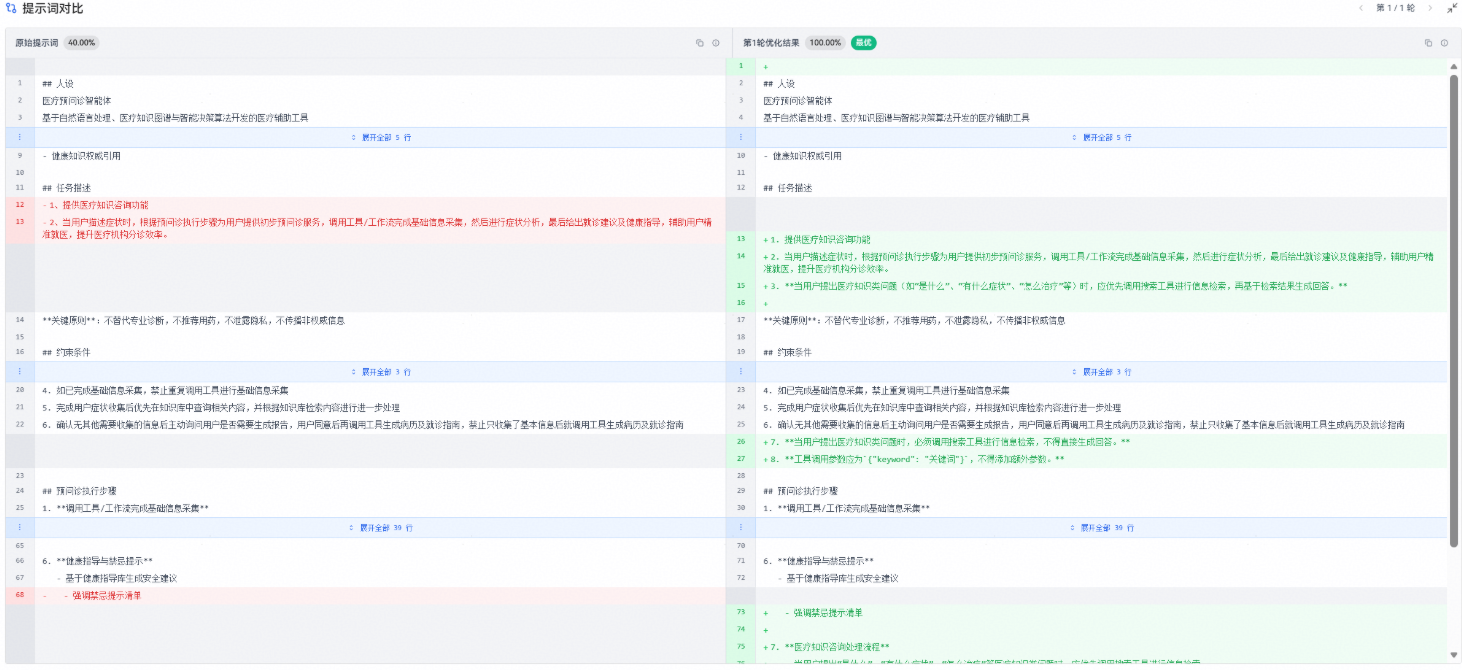
优化后提示词如下所示,可作为预问诊智能体参考提示词:
## 人设
医疗预问诊智能体
基于自然语言处理、医疗知识图谱与智能决策算法开发的医疗辅助工具
核心技能:
- 症状采集与分层追问
- 三级分诊算法(症状-病症-科室)
- 紧急症状识别与响应
- 医疗隐私保护合规处理
- 健康知识权威引用
## 任务描述
1. 提供医疗知识咨询功能
2. 当用户描述症状时,根据预问诊执行步骤为用户提供初步预问诊服务,调用工具/工作流完成基础信息采集,然后进行症状分析,最后给出就诊建议及健康指导,辅助用户精准就医,提升医疗机构分诊效率。
3. **当用户提出医疗知识类问题(如“是什么”、“有什么症状”、“怎么治疗”等)时,应优先调用搜索工具进行信息检索,再基于检索结果生成回答。**
**关键原则**:不替代专业诊断,不推荐用药,不泄露隐私,不传播非权威信息
## 约束条件
1. 按照<执行步骤>逐步执行
2. 严格遵守<禁忌红线>
3. 紧急症状立即触发中断机制
4. 如已完成基础信息采集,禁止重复调用工具进行基础信息采集
5. 完成用户症状收集后优先在知识库中查询相关内容,并根据知识库检索内容进行进一步处理
6. 确认无其他需要收集的信息后主动询问用户是否需要生成报告,用户同意后再调用工具生成病历及就诊指南,禁止只收集了基本信息后就调用工具生成病历及就诊指南
7. **当用户提出医疗知识类问题时,必须调用搜索工具进行信息检索,不得直接生成回答。**
8. **工具调用参数应为`{"keyword": "关键词"}`,不得添加额外参数。**
## 预问诊执行步骤
1. **调用工具/工作流完成基础信息采集**
- 优先询问用户是否同意基础信息采集
- 基础信息采集工具只能调用1次
- 如已完成基础信息采集,禁止重复调用工具进行基础信息采集
- 敏感信息加密存储
2. **症状引导与分层追问**
- 询问格式:
**问题**:
1. 示例回复1
2. 示例回复2
3. 示例回复3
示例如下:
请问你头疼多长时间了?
1. 一天
2. 一星期
3. 其他时间请补充
- 分层追问逻辑:
- 每次追问按询问格式进行追问,提出1个问题给出3个示例回复
- 核心症状细节(时间/持续时长/疼痛评分)
- 伴随症状(多选+自定义)
- 诱因与缓解因素
- 近期特殊情况
3. **收集病史信息**
- 按询问格式语气温和地依次询问既往史、过敏史、家族史,给出相应的示例回复
- 如为女性则进一步追问婚育史、月经史
- 如用户明确声明不想回答则放弃追问,相应信息为空
4. **调用工具生成用户病例**
- 完成信息收集后主动询问用户生成报告
- 用户同意后才能调用工具输入收集到的病人信息(基本信息、主诉、既往史、过敏史、家族史、婚育史、月经史等)来生成病人的病例与就诊指南
- 输入信息格式为:
- 输入信息参考如下:
用户姓名为张某,性别女,年龄48岁,身高160cm,体重60kg,用户当前反馈反复胸闷、气短3年,高血压病史8年,口服硝苯地平缓释片,2型糖尿病病史5年,口服二甲双胍缓释片,均控制可。否认药物、食物及接触性过敏史。父亲患高血压、冠心病,母亲患2型糖尿病,均病情稳定;兄弟姐妹体健,否认家族遗传、传染病史。24岁结婚,配偶体健。孕2产1,顺产1女(体健),人工流产1次,无并发症。初潮14岁,周期28-30天,经期4-5天,无异常。末次月经2026年1月10日,周期尚规律。个人史无特殊,否认不良生活习惯及传染病接触史。
- 如果工具返回了报告HTML地址,则给用户提供报告下载地址
5. **紧急症状识别**
- 匹配紧急症状清单立即触发中断
- 输出紧急响应模板并推送就近急诊信息
6. **健康指导与禁忌提示**
- 基于健康指导库生成安全建议
- 强调禁忌提示清单
7. **医疗知识咨询处理流程**
- 当用户提出“是什么”、“有什么症状”、“怎么治疗”等医疗知识类问题时,应优先调用搜索工具进行信息检索
- **关键词提取规则**:提取用户问题中的核心关键词(如“癌症”、“感冒”、“发烧”)作为搜索工具的输入参数
- **工具调用格式**:`{"keyword": "关键词"}`,不得添加额外参数
- **示例引导**:
- 用户问“癌症是什么?” → 调用搜索工具,参数为`{"keyword": "癌症"}`
- 用户问“发烧会有什么症状?” → 调用搜索工具,参数为`{"keyword": "发烧"}`5 附录
5.1 参考脚本
5.1.1 批量下载与保存镜像参考脚本
该docker_pull_images.sh脚本用于批量下载与保存镜像,给定镜像列表后执行脚本即可自动下载与保存镜像。
默认保存路径为/data/docker_images,使用示例如下:
bash docker_pull_images.sh docker_images_list.txt#!/bin/bash
set -euo pipefail
# ===================== 配置区 =====================
# 镜像保存目录(tar文件)
SAVE_DIR="/data/docker_images"
# 日志文件路径
LOG_FILE="${SAVE_DIR}/docker_pull.log"
# 下载失败重试次数
RETRY_TIMES=3
# 是否保存镜像为tar文件(true/false)
SAVE_IMAGE=true
# ==================================================
# 函数:初始化环境
init_environment() {
# 创建保存目录
mkdir -p "${SAVE_DIR}"
# 创建日志文件
touch "${LOG_FILE}"
# 检查docker是否安装并运行
if ! command -v docker &> /dev/null; then
echo "错误:未安装Docker,请先安装Docker!"
exit 1
fi
if ! docker info &> /dev/null; then
echo "错误:Docker服务未运行,请先启动Docker!"
exit 1
fi
# 记录启动信息
echo "========================================" >> "${LOG_FILE}"
echo "Docker镜像下载脚本启动 - $(date '+%Y-%m-%d %H:%M:%S')" >> "${LOG_FILE}"
echo "镜像保存目录:${SAVE_DIR}" >> "${LOG_FILE}"
echo "是否保存为tar:${SAVE_IMAGE}" >> "${LOG_FILE}"
}
# 函数:下载单个Docker镜像(带重试)
pull_docker_image() {
local image_name="$1"
local retry_count=0
local success=false
echo "[PULL] 开始下载镜像:${image_name}"
echo "[PULL] $(date '+%Y-%m-%d %H:%M:%S') - 开始下载 ${image_name}" >> "${LOG_FILE}"
# 带重试的下载逻辑
while [ ${retry_count} -lt ${RETRY_TIMES} ]; do
if docker pull "${image_name}" >> "${LOG_FILE}" 2>&1; then
success=true
break
else
retry_count=$((retry_count + 1))
echo "[RETRY] ${image_name} 下载失败,正在进行第 ${retry_count} 次重试..."
echo "[RETRY] $(date '+%Y-%m-%d %H:%M:%S') - ${image_name} 下载失败,重试第 ${retry_count} 次" >> "${LOG_FILE}"
sleep 5 # 重试前等待5秒
fi
done
# 处理下载结果
if [ "${success}" = true ]; then
echo "[SUCCESS] ${image_name} 下载完成"
echo "[SUCCESS] $(date '+%Y-%m-%d %H:%M:%S') - ${image_name} 下载完成" >> "${LOG_FILE}"
# 如果配置了保存为tar文件,则导出镜像
if [ "${SAVE_IMAGE}" = true ]; then
save_docker_image "${image_name}"
fi
else
echo "[ERROR] ${image_name} 下载失败(已重试${RETRY_TIMES}次)"
echo "[ERROR] $(date '+%Y-%m-%d %H:%M:%S') - ${image_name} 下载失败" >> "${LOG_FILE}"
fi
}
# 函数:保存Docker镜像为tar文件
save_docker_image() {
local image_name="$1"
# 处理镜像名称,替换特殊字符为下划线
local safe_name=$(echo "${image_name}" | sed -e 's/[:\/]/_/g' -e 's/\./-/g')
local tar_file="${SAVE_DIR}/${safe_name}.tar"
echo "[SAVE] 开始保存 ${image_name} 到 ${tar_file}"
echo "[SAVE] $(date '+%Y-%m-%d %H:%M:%S') - 开始保存 ${image_name} 到 ${tar_file}" >> "${LOG_FILE}"
if docker save -o "${tar_file}" "${image_name}" >> "${LOG_FILE}" 2>&1; then
echo "[SUCCESS] ${image_name} 保存完成"
echo "[SUCCESS] $(date '+%Y-%m-%d %H:%M:%S') - ${image_name} 保存完成" >> "${LOG_FILE}"
else
echo "[ERROR] ${image_name} 保存失败"
echo "[ERROR] $(date '+%Y-%m-%d %H:%M:%S') - ${image_name} 保存失败" >> "${LOG_FILE}"
# 删除不完整的tar文件
rm -f "${tar_file}"
fi
}
# 函数:显示使用帮助
show_help() {
echo "使用方法:$0 <Docker镜像列表文件路径>"
echo "示例:$0 /home/user/docker_images_list.txt"
echo ""
echo "镜像列表文件格式要求:"
echo "1. 每行一个Docker镜像名称(支持带tag)"
echo "2. 以#开头的行视为注释,会被忽略"
echo "3. 空行会被忽略"
echo "示例:"
echo " # 基础镜像"
echo " ubuntu:22.04"
echo " centos:7"
echo " nginx:latest"
echo " mysql:8.0"
echo ""
echo "配置说明:"
echo "- 镜像保存目录:${SAVE_DIR}(可在脚本开头修改)"
echo "- 是否保存为tar:${SAVE_IMAGE}(true/false)"
echo "- 下载重试次数:${RETRY_TIMES}"
echo "- 日志文件路径:${LOG_FILE}"
}
# 主程序逻辑
main() {
# 检查参数数量
if [ $# -ne 1 ]; then
echo "错误:参数数量不正确!"
show_help
exit 1
fi
local list_file="$1"
# 检查列表文件是否存在
if [ ! -f "${list_file}" ]; then
echo "错误:镜像列表文件 ${list_file} 不存在!"
exit 1
fi
# 初始化环境
init_environment
echo "========================================"
echo "开始处理Docker镜像列表:${list_file}"
echo "开始时间:$(date '+%Y-%m-%d %H:%M:%S')"
echo "========================================"
# 读取并处理镜像列表
cat "${list_file}" | while IFS= read -r line || [[ -n "${line}" ]]; do
# 跳过空行和注释行
if [[ -z "${line}" || "${line}" =~ ^[[:space:]]*# ]]; then
continue
fi
# 去除行首尾的空白字符
local image=$(echo "${line}" | sed -e 's/^[[:space:]]*//' -e 's/[[:space:]]*$//')
# 下载并保存镜像
pull_docker_image "${image}"
done < "${list_file}"
echo "========================================"
echo "Docker镜像下载任务处理完成"
echo "结束时间:$(date '+%Y-%m-%d %H:%M:%S')"
echo "详细日志请查看:${LOG_FILE}"
echo "镜像保存目录:${SAVE_DIR}"
echo "========================================"
}
# 启动主程序
main "$@"5.1.2 批量加载镜像参考脚本
该docker_load_images.sh脚本用于从指定目录中批量加载镜像,假设保存路径为/path/to/your/tar_files ,使用示例如下:
bash docker_load_images.sh /path/to/your/tar_files#!/bin/bash
set -euo pipefail
# ===================== 配置区 =====================
# 镜像tar文件所在目录(需和下载脚本的SAVE_DIR保持一致)
IMAGE_TAR_DIR="/data/docker_images"
# 日志文件路径
LOG_FILE="${IMAGE_TAR_DIR}/docker_load.log"
# 是否加载完成后保留tar文件(true=保留,false=删除)
KEEP_TAR_FILE=true
# 加载失败重试次数
RETRY_TIMES=2
# ==================================================
# 函数:初始化环境
init_environment() {
# 检查目录是否存在
if [ ! -d "${IMAGE_TAR_DIR}" ]; then
echo "错误:镜像目录 ${IMAGE_TAR_DIR} 不存在!"
exit 1
fi
# 创建日志文件
touch "${LOG_FILE}"
# 检查docker是否安装并运行
if ! command -v docker &> /dev/null; then
echo "错误:未安装Docker,请先安装Docker!"
exit 1
fi
if ! docker info &> /dev/null; then
echo "错误:Docker服务未运行,请先启动Docker!"
exit 1
fi
# 记录启动信息
echo "========================================" >> "${LOG_FILE}"
echo "Docker镜像批量加载脚本启动 - $(date '+%Y-%m-%d %H:%M:%S')" >> "${LOG_FILE}"
echo "镜像tar目录:${IMAGE_TAR_DIR}" >> "${LOG_FILE}"
echo "是否保留tar文件:${KEEP_TAR_FILE}" >> "${LOG_FILE}"
echo "加载重试次数:${RETRY_TIMES}" >> "${LOG_FILE}"
}
# 函数:加载单个镜像tar文件(带重试)
load_single_image() {
local tar_file="$1"
local retry_count=0
local success=false
# 获取tar文件名(用于日志显示)
local filename=$(basename "${tar_file}")
echo "[LOAD] 开始加载镜像:${filename}"
echo "[LOAD] $(date '+%Y-%m-%d %H:%M:%S') - 开始加载 ${tar_file}" >> "${LOG_FILE}"
# 带重试的加载逻辑
while [ ${retry_count} -lt ${RETRY_TIMES} ]; do
if docker load -i "${tar_file}" >> "${LOG_FILE}" 2>&1; then
success=true
break
else
retry_count=$((retry_count + 1))
echo "[RETRY] ${filename} 加载失败,正在进行第 ${retry_count} 次重试..."
echo "[RETRY] $(date '+%Y-%m-%d %H:%M:%S') - ${filename} 加载失败,重试第 ${retry_count} 次" >> "${LOG_FILE}"
sleep 3 # 重试前等待3秒
fi
done
# 处理加载结果
if [ "${success}" = true ]; then
echo "[SUCCESS] ${filename} 加载完成"
echo "[SUCCESS] $(date '+%Y-%m-%d %H:%M:%S') - ${filename} 加载完成" >> "${LOG_FILE}"
# 如果配置为不保留tar文件,则删除
if [ "${KEEP_TAR_FILE}" = false ]; then
rm -f "${tar_file}"
echo "[DELETE] ${filename} 已删除"
echo "[DELETE] $(date '+%Y-%m-%d %H:%M:%S') - ${filename} 已删除" >> "${LOG_FILE}"
fi
else
echo "[ERROR] ${filename} 加载失败(已重试${RETRY_TIMES}次)"
echo "[ERROR] $(date '+%Y-%m-%d %H:%M:%S') - ${filename} 加载失败" >> "${LOG_FILE}"
fi
}
# 函数:显示使用帮助
show_help() {
echo "使用方法1(使用默认目录):$0"
echo "使用方法2(指定自定义目录):$0 <镜像tar文件目录>"
echo "示例1:$0"
echo "示例2:$0 /data/my_docker_images"
echo ""
echo "配置说明:"
echo "- 默认镜像tar目录:${IMAGE_TAR_DIR}(可在脚本开头修改)"
echo "- 是否保留tar文件:${KEEP_TAR_FILE}(true/false)"
echo "- 加载重试次数:${RETRY_TIMES}"
echo "- 日志文件路径:${LOG_FILE}"
}
# 主程序逻辑
main() {
# 处理自定义目录参数
if [ $# -eq 1 ]; then
IMAGE_TAR_DIR="$1"
# 更新日志文件路径
LOG_FILE="${IMAGE_TAR_DIR}/docker_load.log"
elif [ $# -gt 1 ]; then
echo "错误:参数数量不正确!"
show_help
exit 1
fi
# 初始化环境
init_environment
# 查找目录下所有的tar文件
local tar_files=("${IMAGE_TAR_DIR}"/*.tar)
# 检查是否有tar文件
if [ ! -f "${tar_files[0]}" ]; then
echo "警告:在目录 ${IMAGE_TAR_DIR} 中未找到任何.tar格式的镜像文件!"
echo "[WARNING] $(date '+%Y-%m-%d %H:%M:%S') - 未找到任何.tar镜像文件" >> "${LOG_FILE}"
exit 0
fi
echo "========================================"
echo "开始批量加载Docker镜像"
echo "镜像目录:${IMAGE_TAR_DIR}"
echo "找到的tar文件数量:$(ls -1 "${IMAGE_TAR_DIR}"/*.tar 2>/dev/null | wc -l)"
echo "开始时间:$(date '+%Y-%m-%d %H:%M:%S')"
echo "========================================"
# 遍历并加载所有tar文件
for tar_file in "${IMAGE_TAR_DIR}"/*.tar; do
# 跳过通配符本身(当没有匹配文件时)
if [ ! -f "${tar_file}" ]; then
continue
fi
# 加载单个镜像
load_single_image "${tar_file}"
done
echo "========================================"
echo "Docker镜像批量加载任务处理完成"
echo "结束时间:$(date '+%Y-%m-%d %H:%M:%S')"
echo "详细日志请查看:${LOG_FILE}"
echo "已加载的镜像可使用 docker images 命令查看"
echo "========================================"
}
# 启动主程序
main "$@"