



基于openJiuwen的自然语言生成Agent功能尝鲜
发表于: 2026/03/23
1 非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
2 基于openJiuwen的Agent自动生成系统
2.1 简介
VibeAgent是基于openJiuwen框架的智能Agent自动生成系统,该系统采用多Agent协作架构,支持三种生成模式:ReAct Agent、Workflow 和 Multi-Agent,并且提供了独立的前端界面方便用户快速构建Agent应用,其系统架构图如下所示:
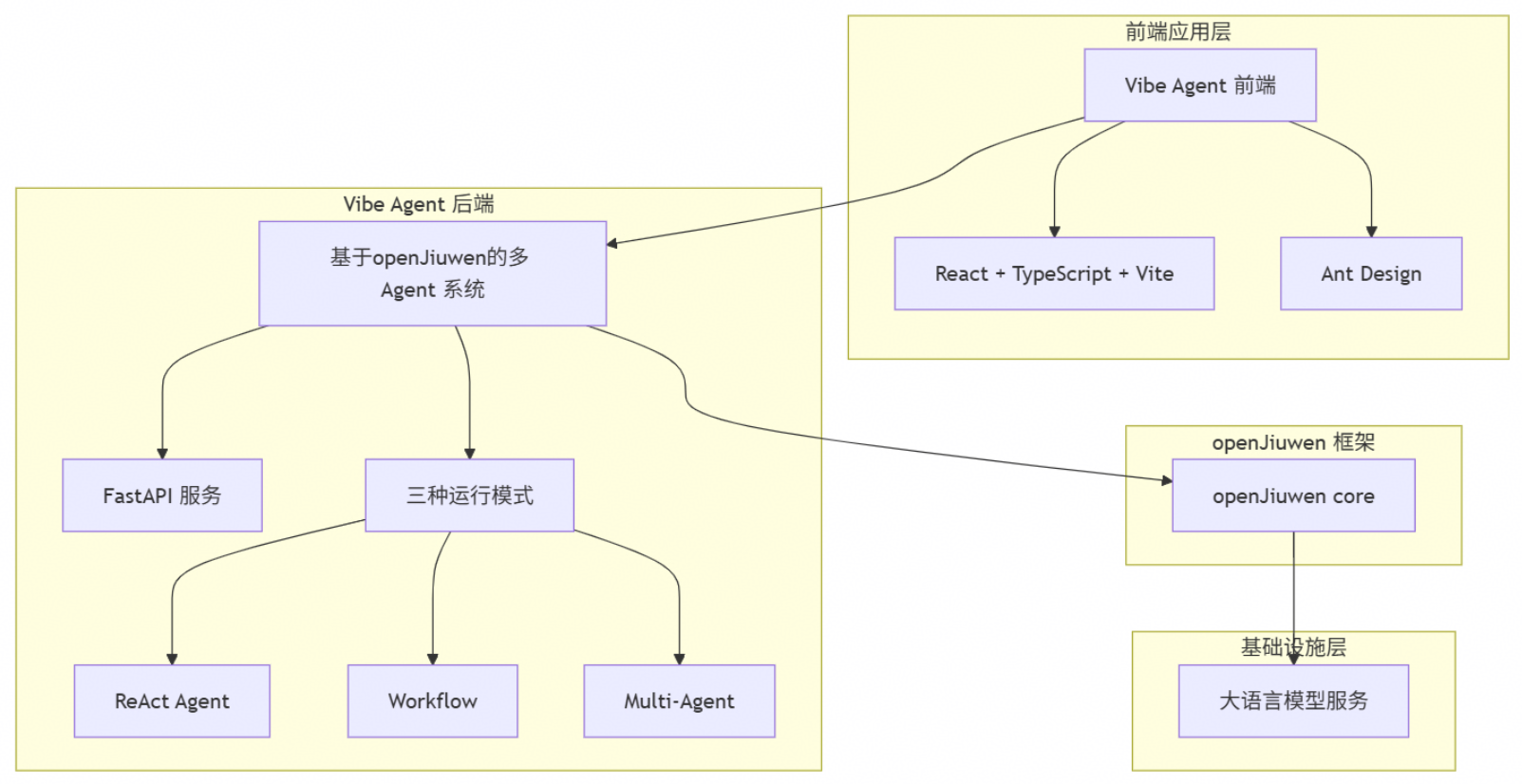
用户可以通过自然语言描述自动生成完整的、可运行的基于openJiuwen框架的代码来构建智能体,降低智能体开发技术门槛的同时提升了开发效率。

2.2 安装部署
1、conda 创建环境
conda create --name vibe_agent python=3.11
conda activate vibe_agent如未安装conda可参考如下命令安装:
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
chmod +x Miniconda3-latest-Linux-aarch64.sh
bash Miniconda3-latest-Linux-aarch64.sh2、克隆仓库并进入相应目录
仓库地址:openJiuwen-vibeCoding - AtomGit | GitCode
git clone https://gitcode.com/taojianjun/openJiuwen-vibeCoding.git3、安装后端依赖
#进入./backend目录
pip install -r requirements.txt4、安装前端依赖
#前端依赖Node.js 18+,如未安装,可参考如下命令安装Node.js 18.x,已安装可跳过
conda install -c conda-forge nodejs=18 -y
#进入./frontend目录
npm install5、配置 LLM 服务
进入 /backend/ 目录,在 .env中配置API Key、模型服务地址和模型名称等,由于自然语言构建Agent依赖LLM能力,建议使用编程能力较强的模型,如Qwen3-Coder系列或其他旗舰模型。
# 模型提供商:openai / dashscope / others
MODEL_PROVIDER=dashscope
# API 服务地址
API_BASE=https://dashscope.aliyuncs.com/compatible-mode/v1
# API Key(请替换为你的实际密钥)
API_KEY=your_api_key_here
# 默认使用的模型名称
MODEL_NAME=qwen3-coder-plus6、修改/backend目录下的start.sh脚本
将"#加载 .env 文件(如果存在)"后的代码做如下修改,否则不能成功加载环境变量
# 加载 .env 文件(如果存在)
if [ -f ".env" ]; then
echo "发现 .env 文件,将加载环境变量"
while IFS= read -r line; do
# 跳过注释行(以 # 开头)和空行
if [[ "$line" =~ ^# || -z "$line" ]]; then
continue
fi
# 导出变量到当前环境
export "$line"
done < ".env"
else
echo "警告: 未找到 .env 文件,请复制 .env.example 为 .env 并配置"
exit 1
fi7、启动后端服务
#进入/backend目录
bash start.sh8、另起一个终端启动前端服务
#进入/frontend目录
npm run dev启动成功后可以看到如下输出:
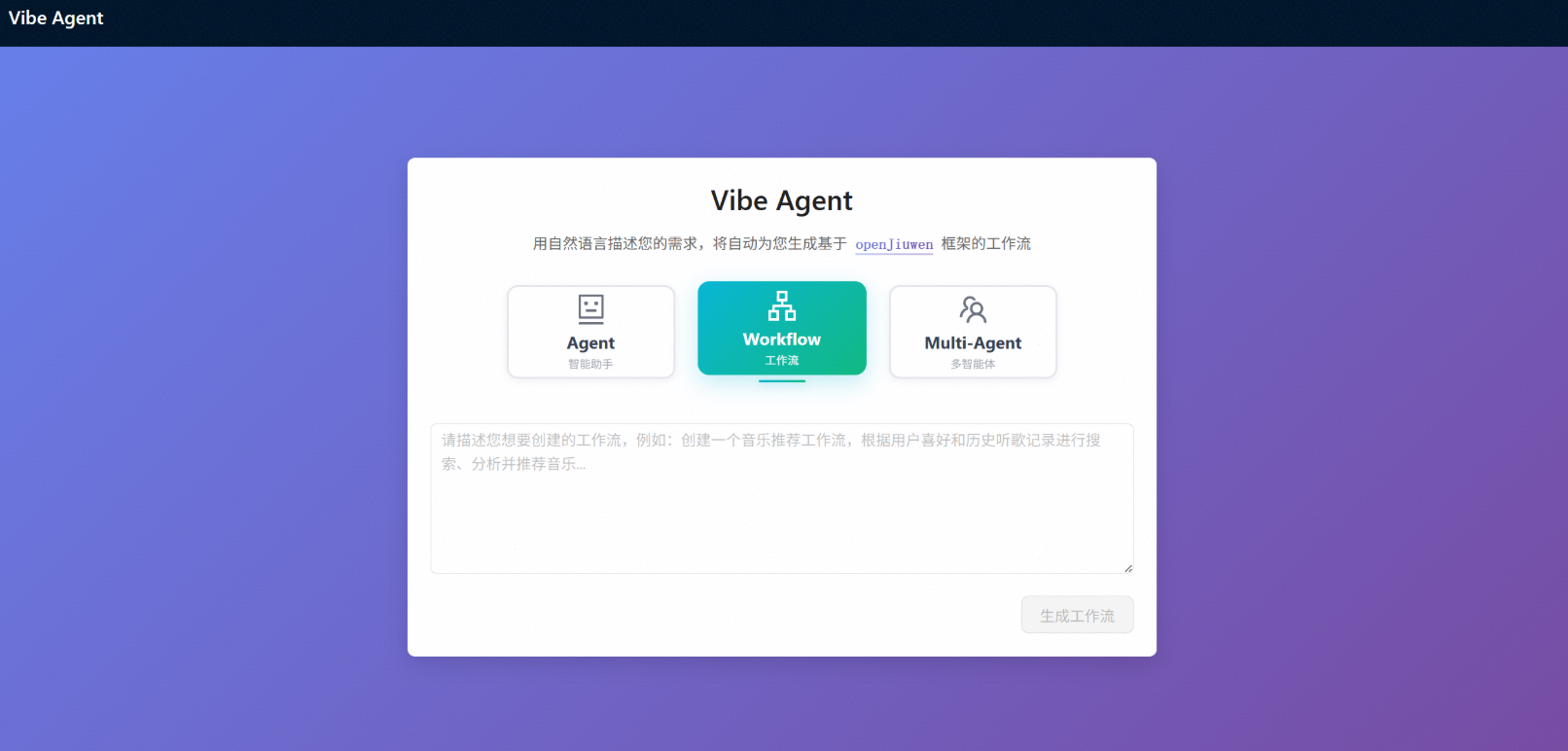
访问Network相应地址地址后可见如下可视化界面:
注意:如果端口被占用可修改前后端的端口
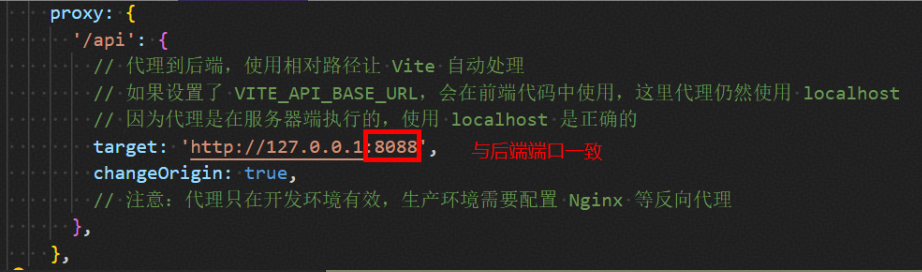
1、后端:修改 vibeAgent/backend/.env 中的 PORT=8000 ,修改端口后需修改 vibeAgent/frontend/vite.config.ts中target参数的端口,与后端端口保持一致。
2、前端:修改 vibeAgent/frontend/vite.config.ts 中的 port: 3000。如前端访问失败可将vibeAgent/frontend/vite.config.ts中target参数的 http://localhost:8000 改为 http://127.0.0.1:8000 。
2.3 添加自定义工具
vibeAgent/backend/app/config/available_tools_info.json文件中定义了系统可以使用的工具,系统默认包括了MockWeatherQuery、MovieQuery、MovieList三个工具。
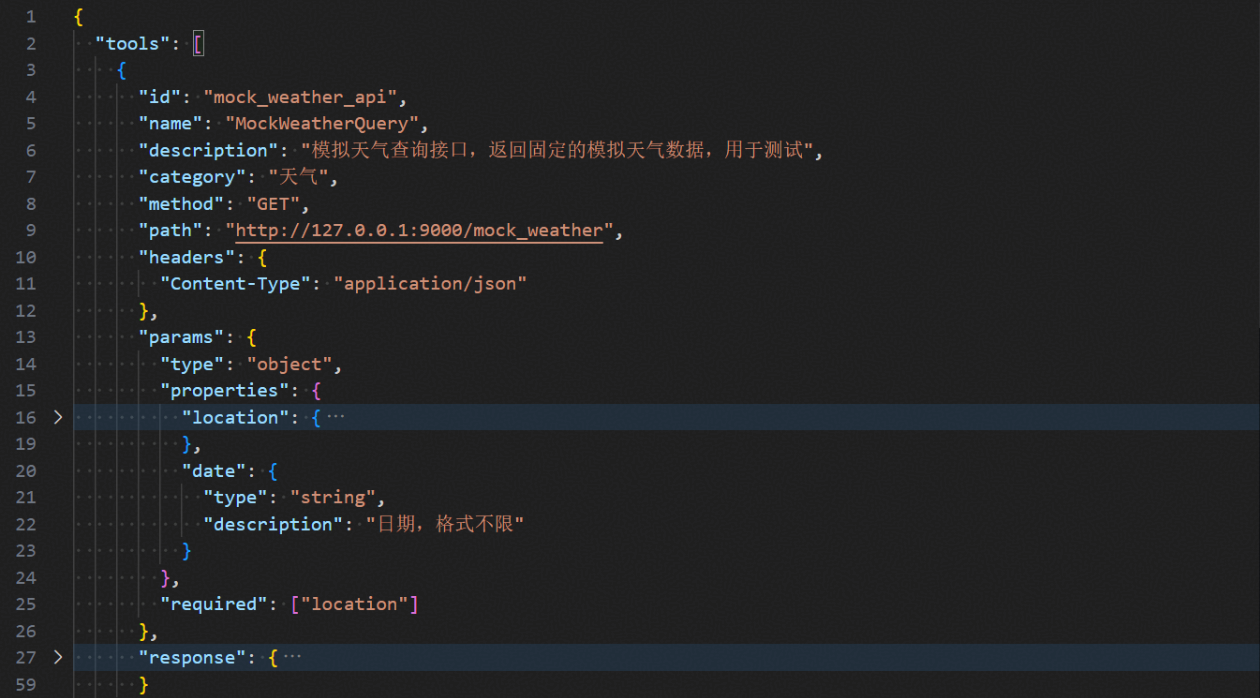
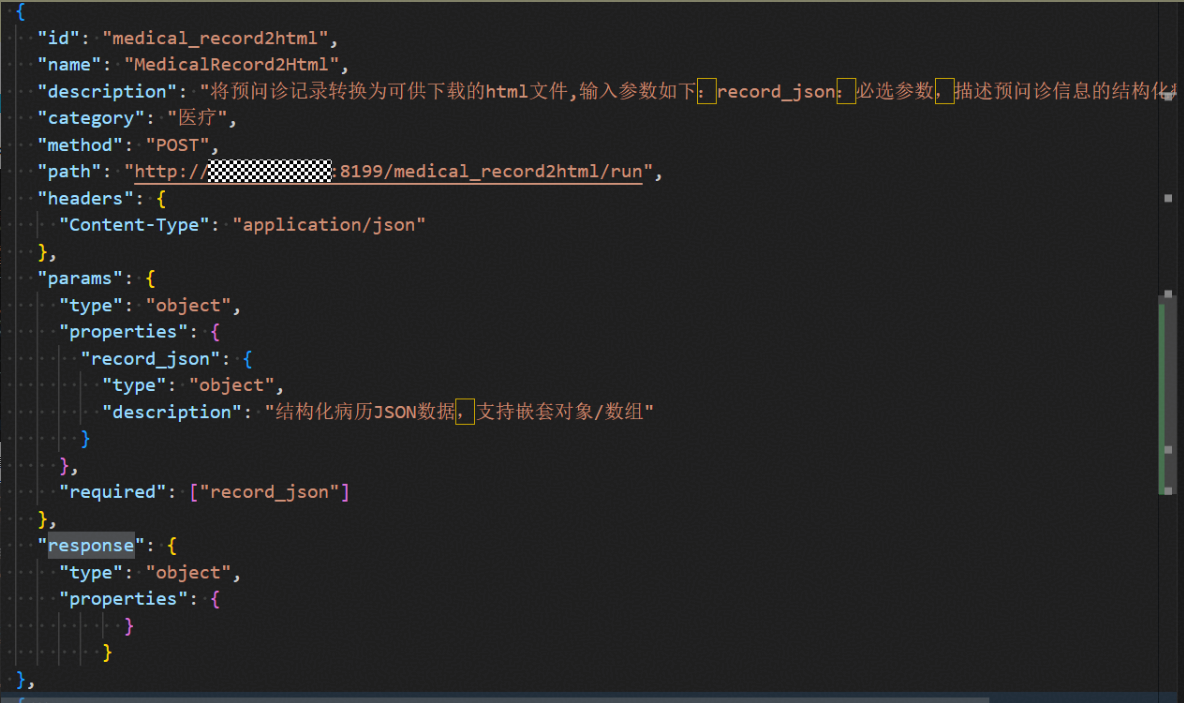
可以参照默认工具的格式来添加自定义工具,扩充VibeAgent系统生成Agent时的可用工具列表,例如可添加自定义的搜索与预问诊报告生成工具,response可为空。
2.4 自然语言生成ReAct Agent
构建提示词
以构建的预问诊助手智能体为例,可将智能体规划阶段设计的智能体主要功能、核心能力、可用工具等组装成提示词用于生成Agent,参考提示词如下所示:
Agent名称:
预问诊助手Agent
主要功能:
面向普通用户提供健康咨询、症状初步自查与就医流程指引,仅做健康指引/辅助参考,不替代临床面诊、不提供确诊结论、不开具处方。
核心能力:
1、精准识别用户症状描述,对模糊的症状描述主动追问关键信息;
2、结合用户问题与网络搜索结果给出科学、合规的解答;
3、根据用户基础信息、症状信息等给出就诊建议,最终输出预问诊报告指导用户就医。
可以使用如下工具:
1、用于联网检索专业知识的搜索工具、
2、用于根据用户信息输出预问诊报告的工具。生成Agent
选择Agent智能助手模式,输入相应提示词后点击生成Agent即可一键式自动生成指定Agent。
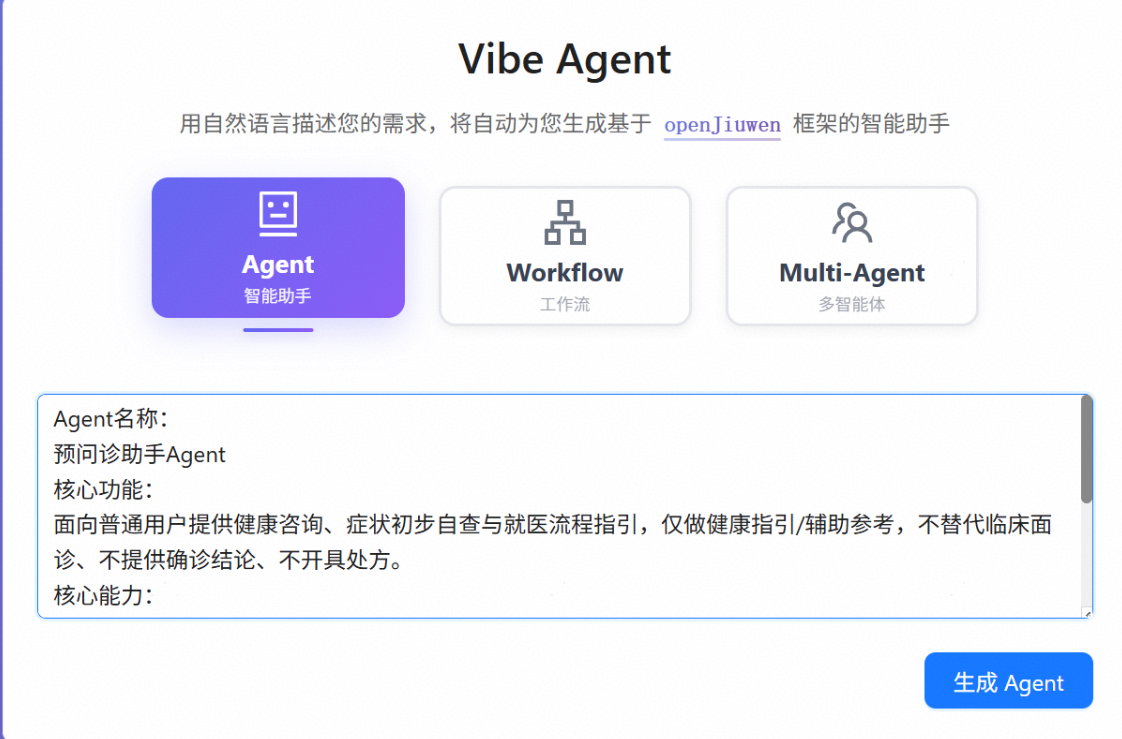
接收生成Agent指令后,VibeAgent系统首先会进行任务规划,之后按照规划的步骤依次生成配置文件、 tools_analysis 文件、Agent逻辑文件、主执行文件,在页面中代码文件部分可以查看生成的相应代码,其中:
1、config.py主要为相应LLM的配置信息;
2、tools_analysis.py定义ReAct Agent使用的工具;
3、local_agent.py为ReAct Agent实现,核心为工具绑定和思考执行逻辑;
4、main.py为主执行文件,作为整个ReAct Agent的入口;
生成完相应的代码文件后会自动进行测试,测试通过后即完成智能体的构建。
查看tools_analysis.py文件,可以看到VibeAgent成功定义了我们自行添加的搜索工具和预问诊报告生成工具。
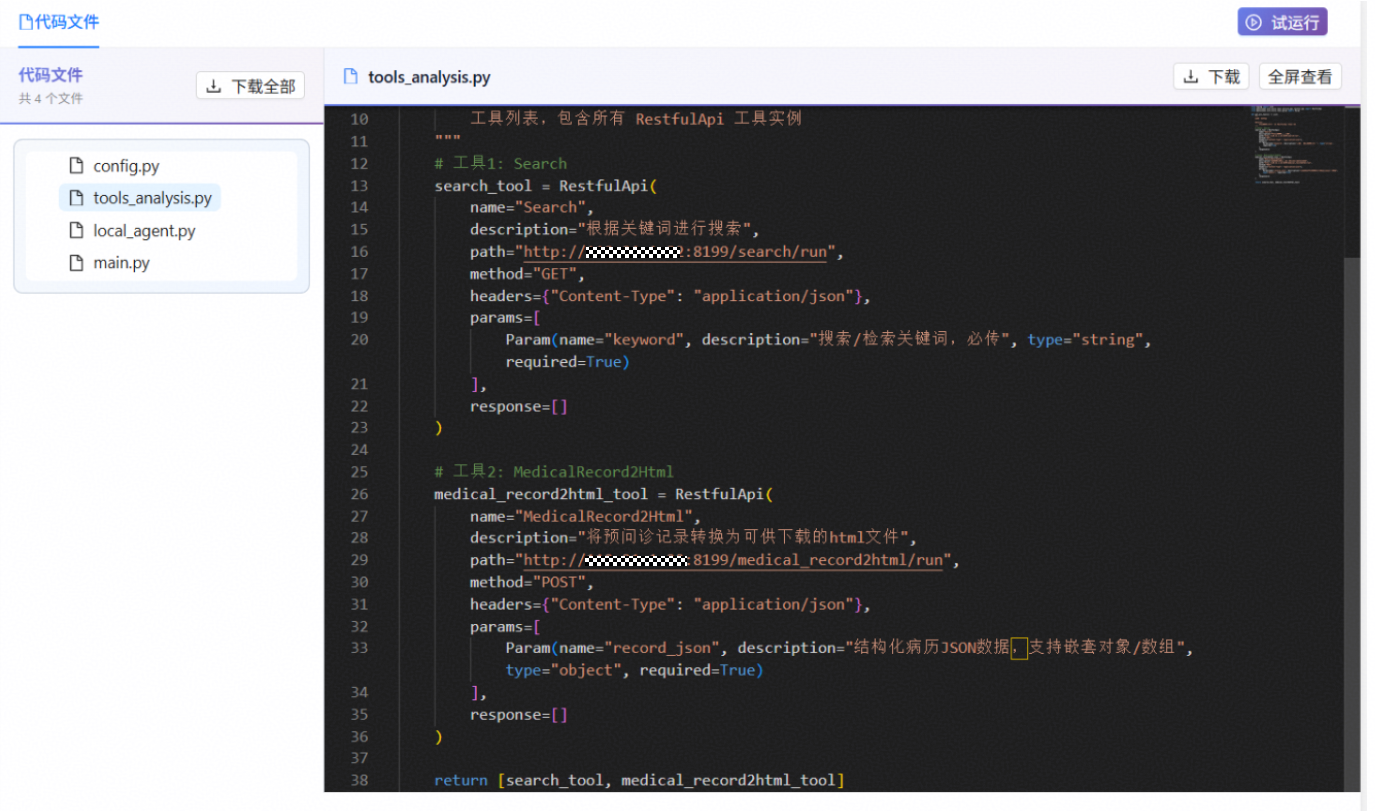
试运行
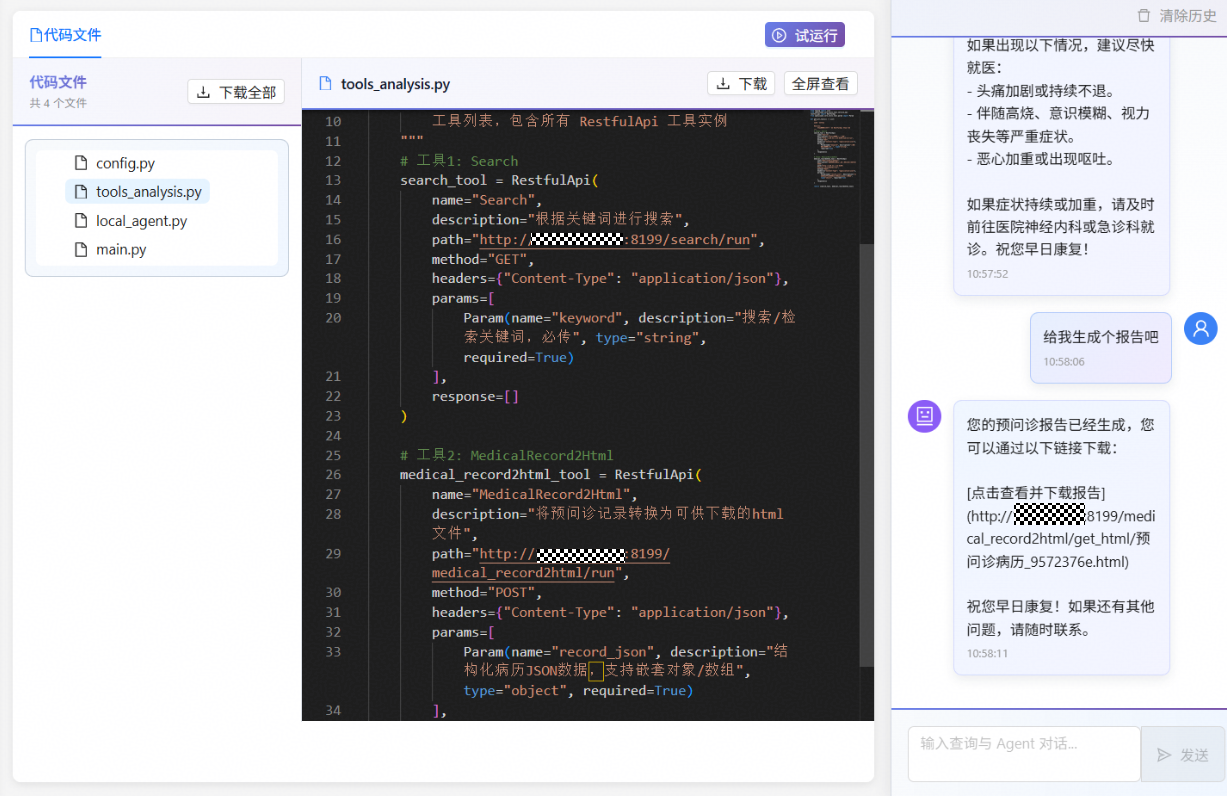
点击试运行按钮即可与Agent进行对话,Agent按预期引导用户描述详细症状信息。
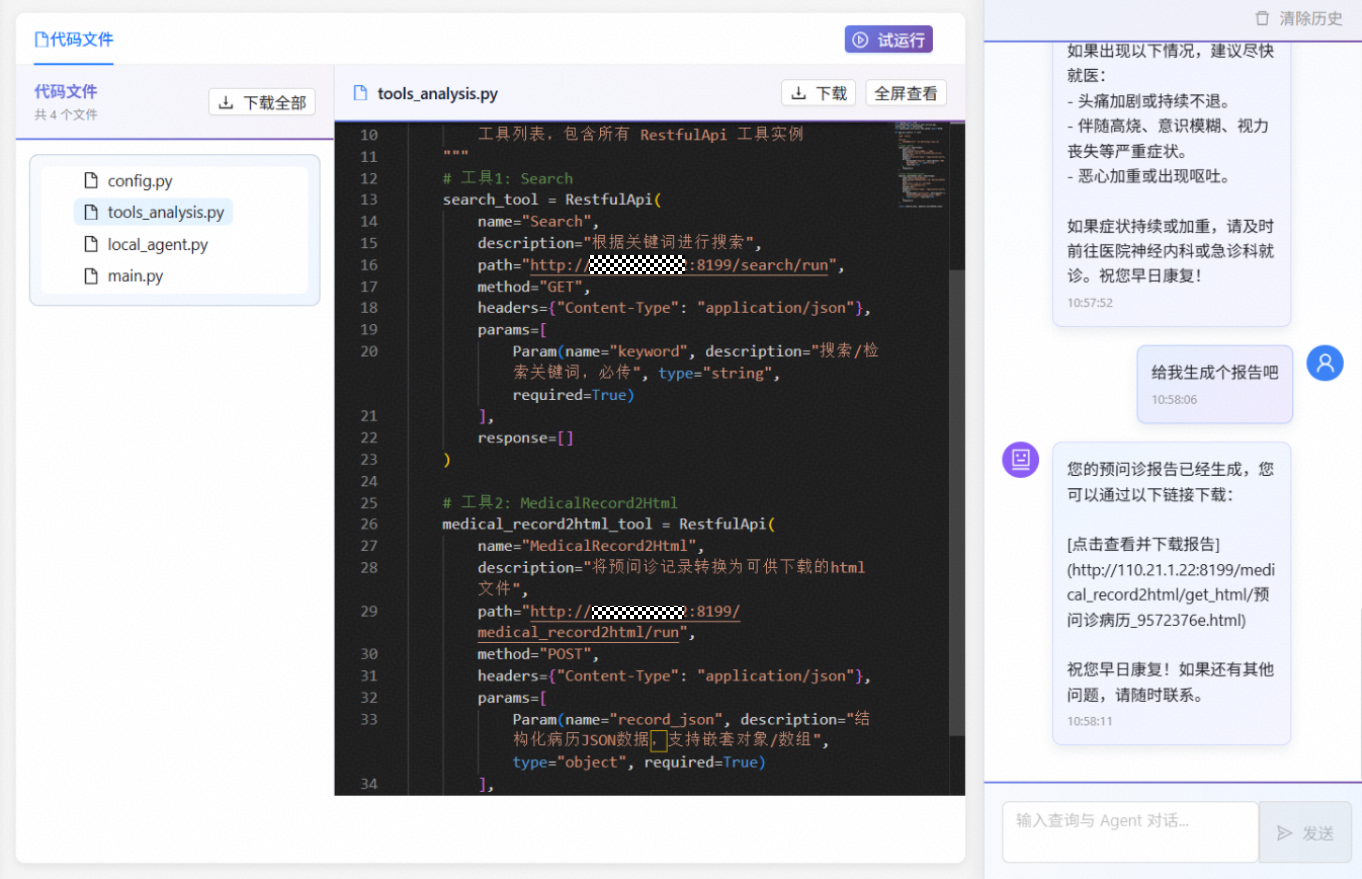
收到报告生成指令后可正常调用工具生成预问诊报告。
2.5 自然语言生成工作流
2.5.1 工作流生成与修改
构建提示词
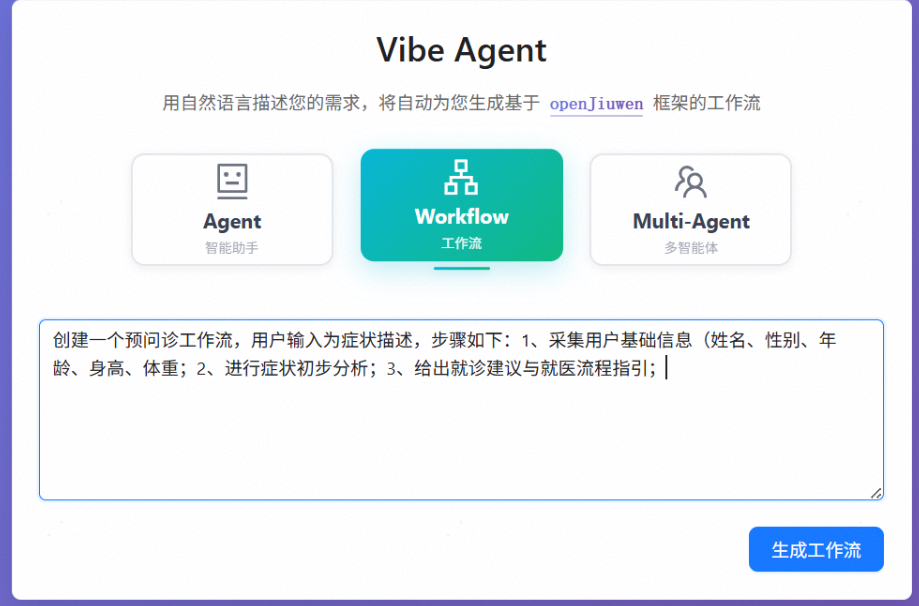
以预问诊报告生成工作流为例,提示词中建议描述工作流包含的具体步骤,参考提示词如下所示:
创建一个预问诊工作流,用户输入为症状描述,步骤如下:
1、采集用户基础信息(姓名、性别、年龄、身高、体重);
2、进行症状初步分析;
3、给出就诊建议与就医流程指引;生成工作流
选择Workflow工作流模式,输入相应提示词后点击生成工作流即可一键式自动生成指定工作流。
接收生成工作流指令后,VibeAgent系统首先会进行任务规划,之后按照规划的步骤依次生成配置文件、组件文件、工作流连接文件、主执行文件,在页面中代码文件部分可以查看生成的相应代码,其中:
1、config.py主要为相应LLM、工作流的配置信息;
2、components.py实现所有组件的创建函数;
3、workflow_builder.py为工作流构建器,用于组装和连接工作流组件;
4、main.py执行和测试工作流;
生成完相应的代码文件后会自动进行测试,若测试不通过则自动进入修复阶段,修复完成并测试通过后即完成工作流的构建。
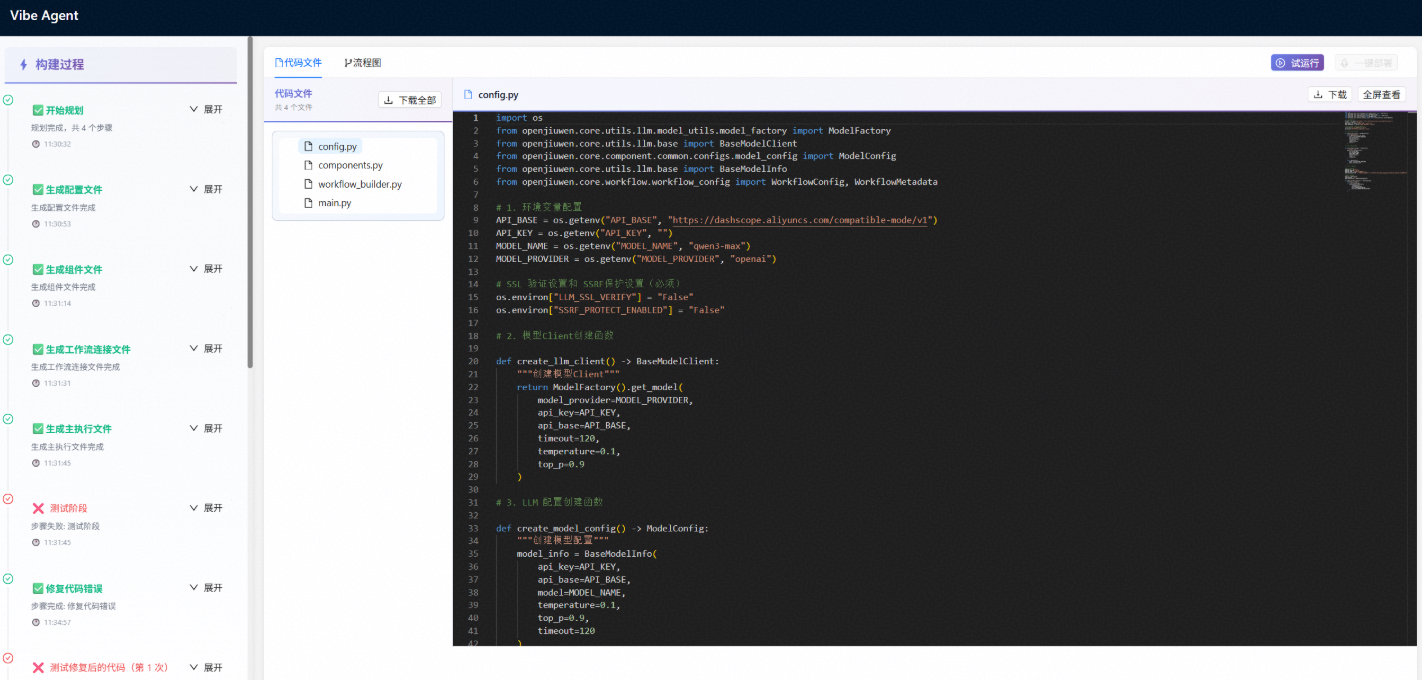
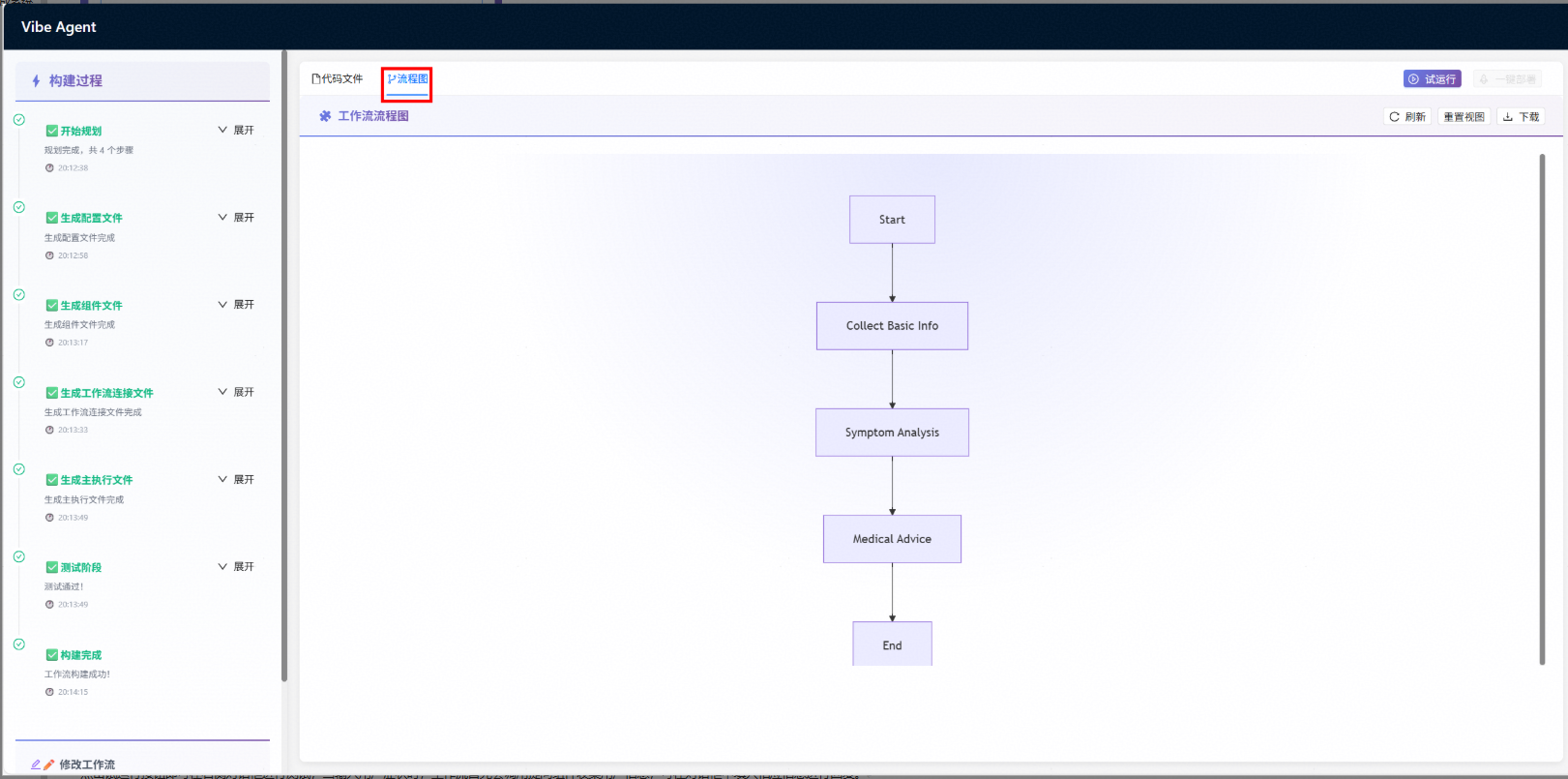
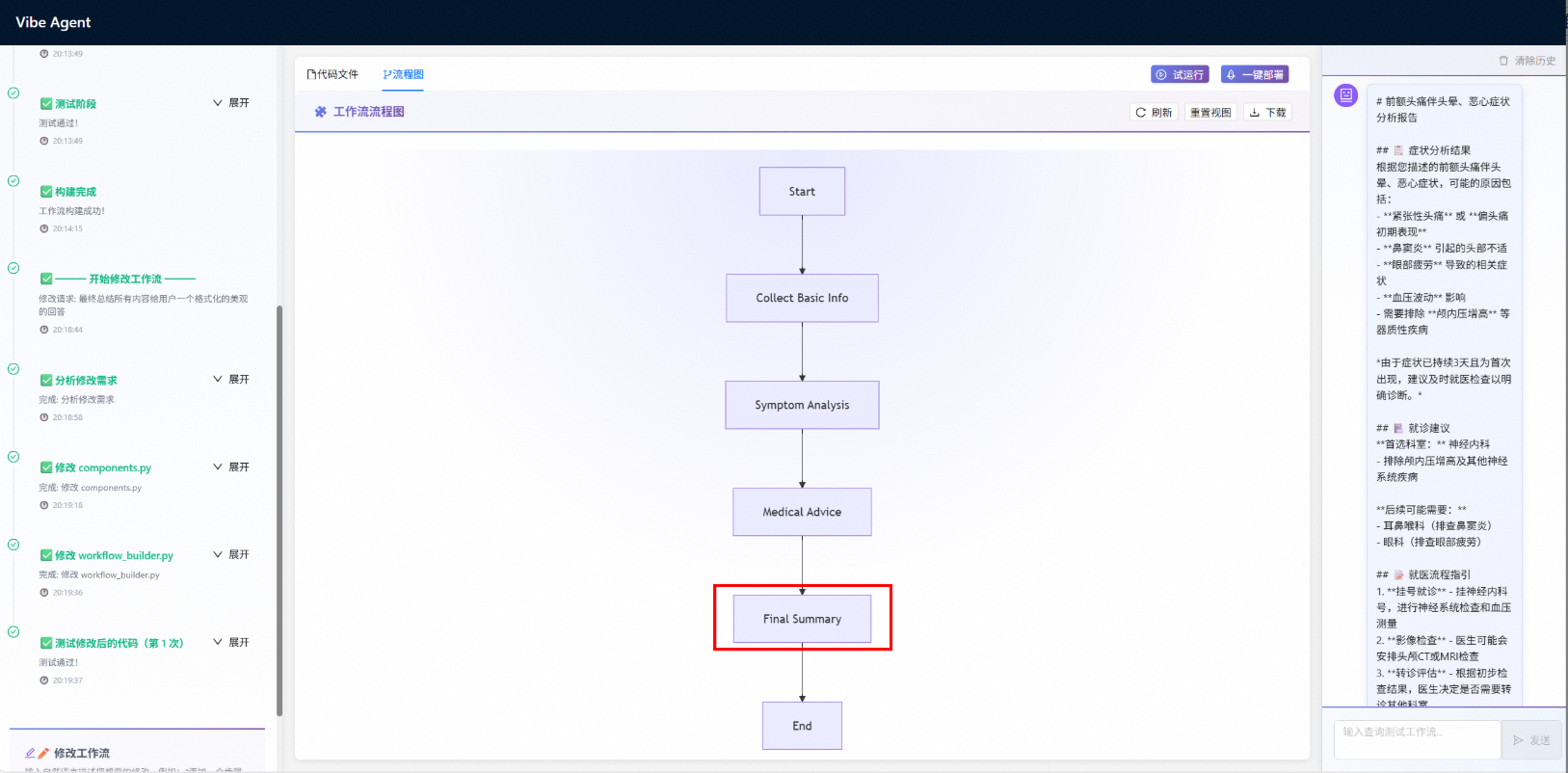
点击流程图按钮即可查看工作流对应的流程图,显示了各个组件的链接关系,如未显示可点击刷新按钮,亦可点击下载按钮下载流程图。
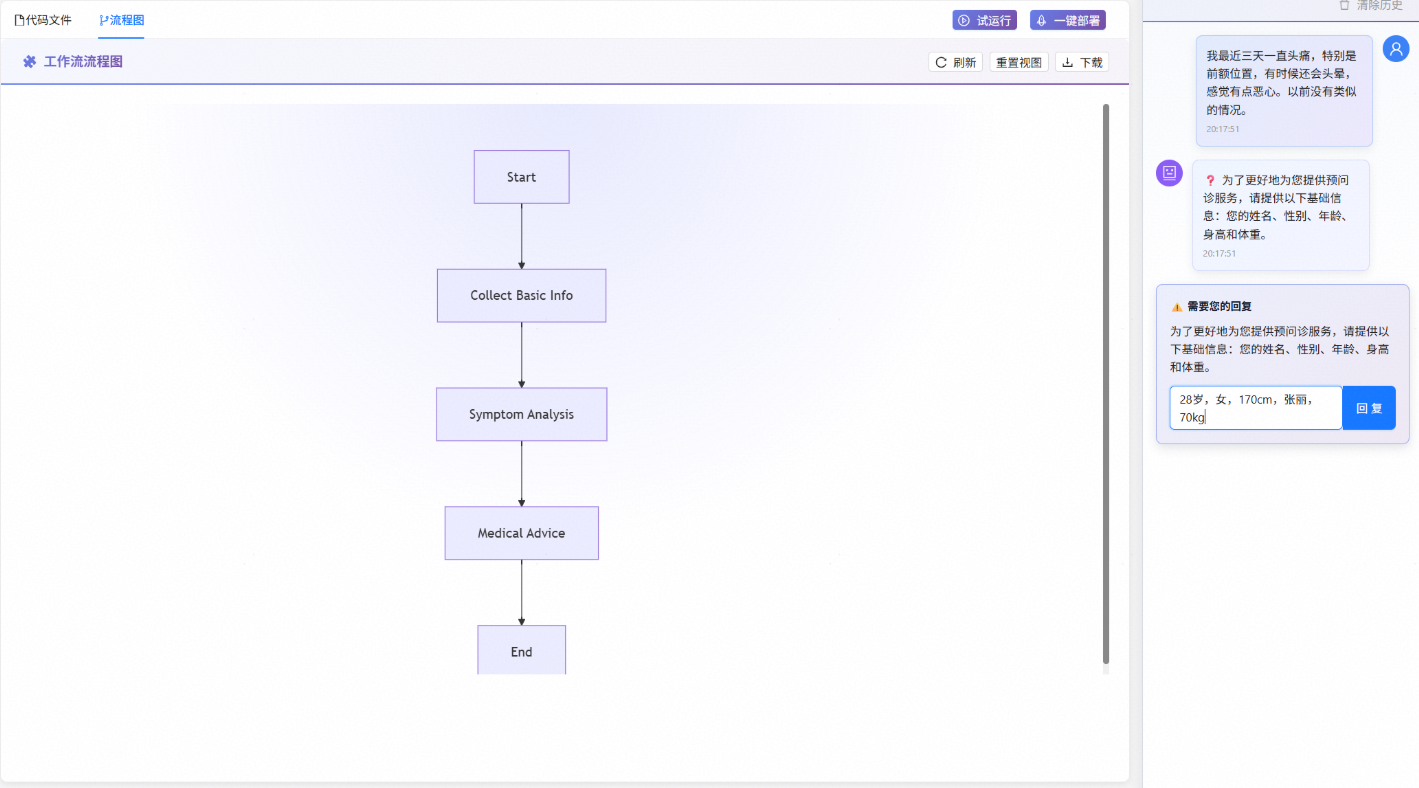
试运行
点击试运行按钮即可在右侧对话框进行测试,当输入用户症状时,工作流首先会调用提问组件收集用户信息,可在对话框中填入相应信息进行回复。
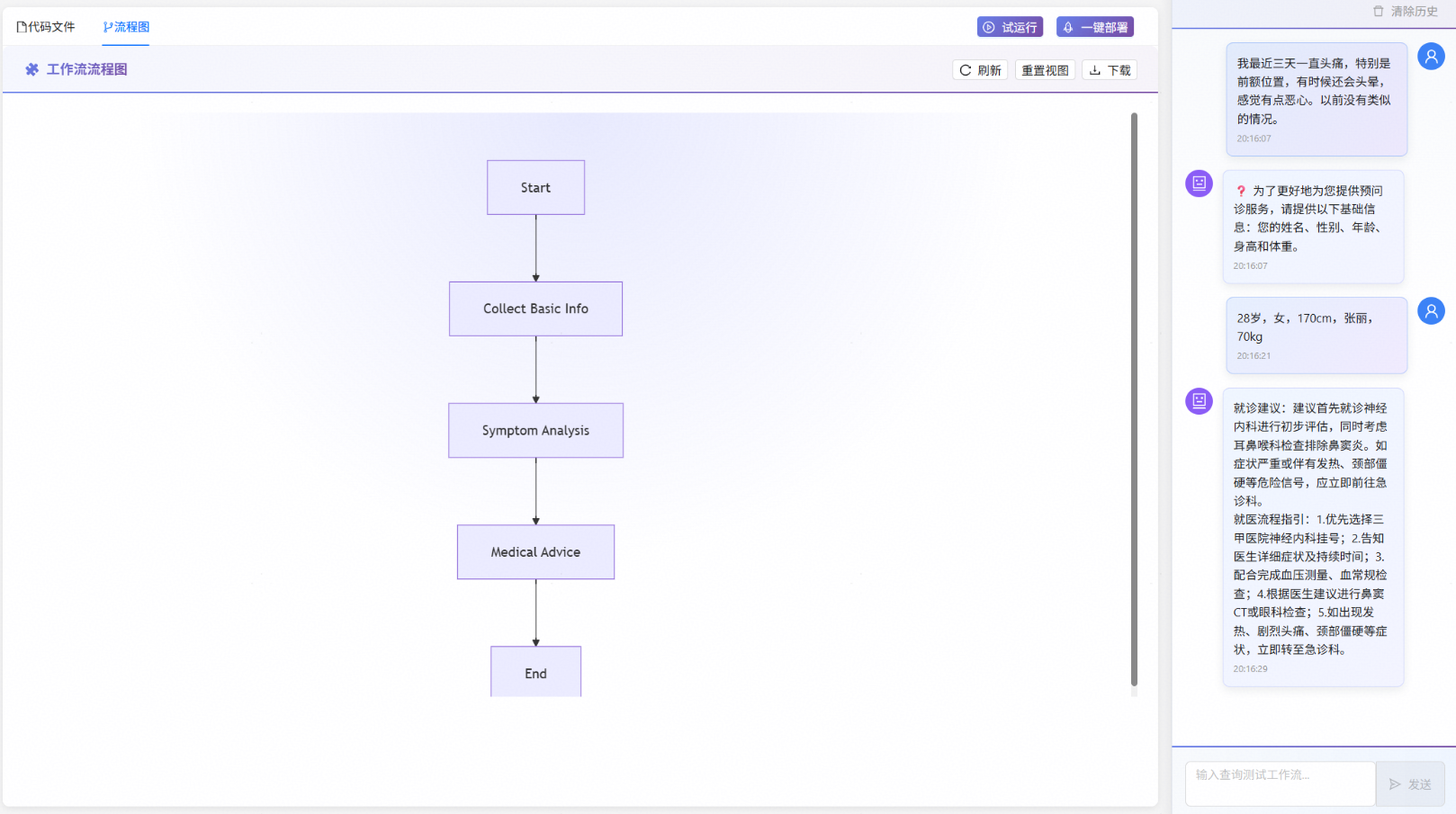
工作流完成后给出相应的就诊建议与就医流程指引。
修改工作流
VibeAgent支持通过自然语言对工作流进行修改,可在左侧对话框中输入自然语言描述想要的修改,系统会自动进行修改与测试,如输入“最终总结所有内容给用户一个格式化的美观的回答“优化工作流回复的格式。
修改完成后可以看到流程图上新增一个节点用于格式化最终回答,试运行后可看到工作流回复格式更加美观。
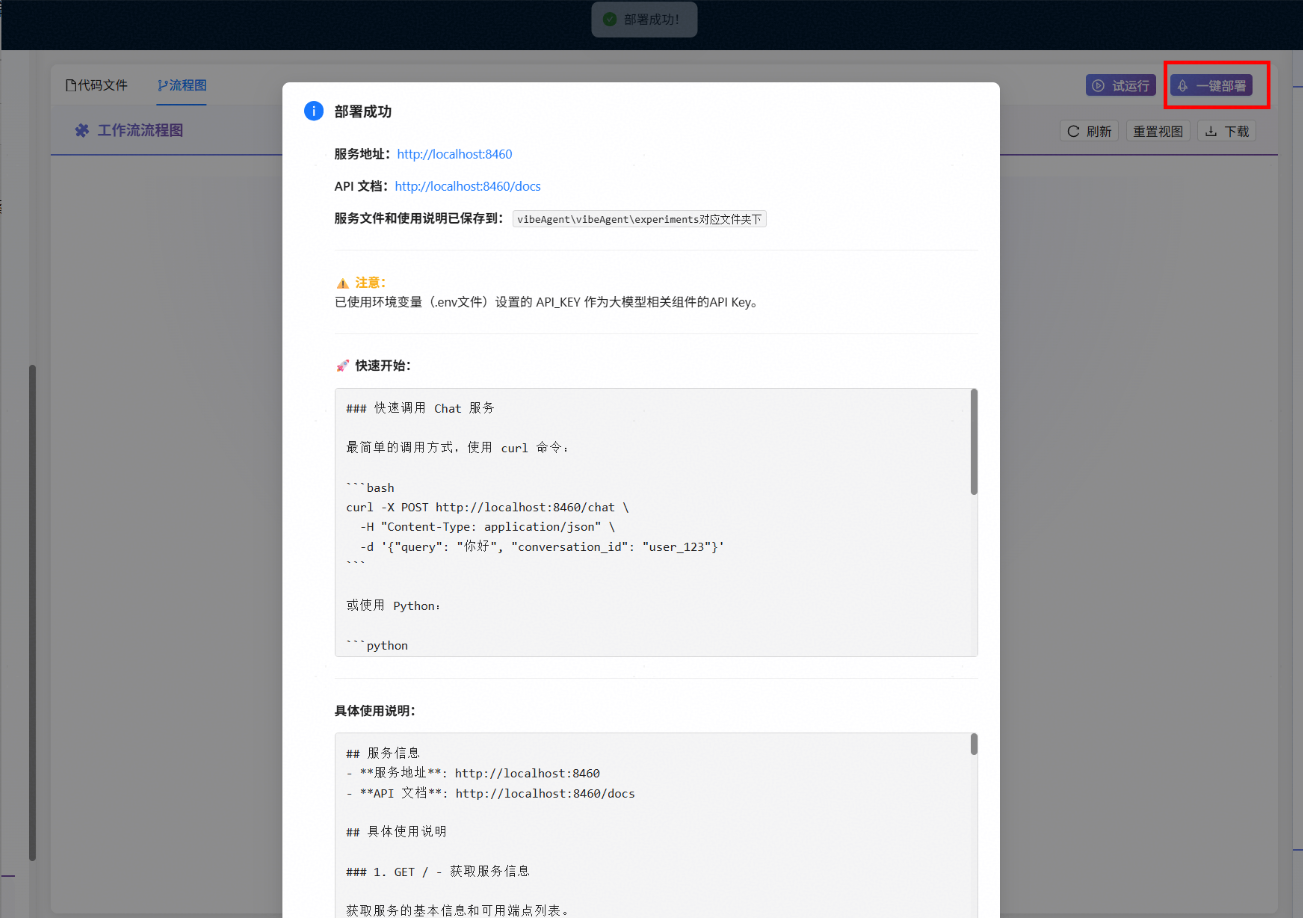
2.5.2 工作流部署与调用
工作流试运行通过后可点击一键部署按钮进行部署,可通过相应接口进行访问,系统提供了详细的使用文档。
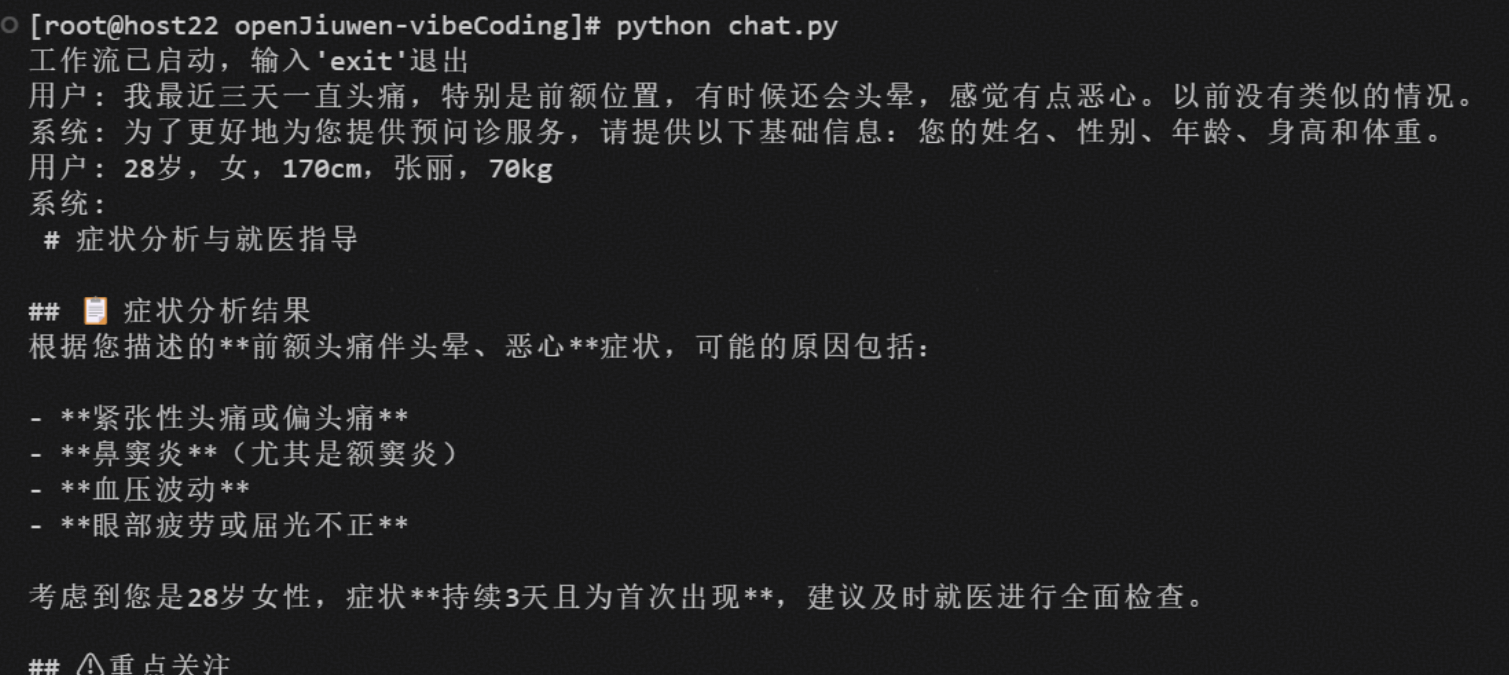
根据使用文档可以编写简单的python脚本在本地服务器上调用工作流,如下所示,参考python脚本见3.1-工作流服务化调用参考脚本。
2.6 自然语言生成Multi-Agent
构建提示词
构建一个医疗多Agent系统,参考提示词如下所示:
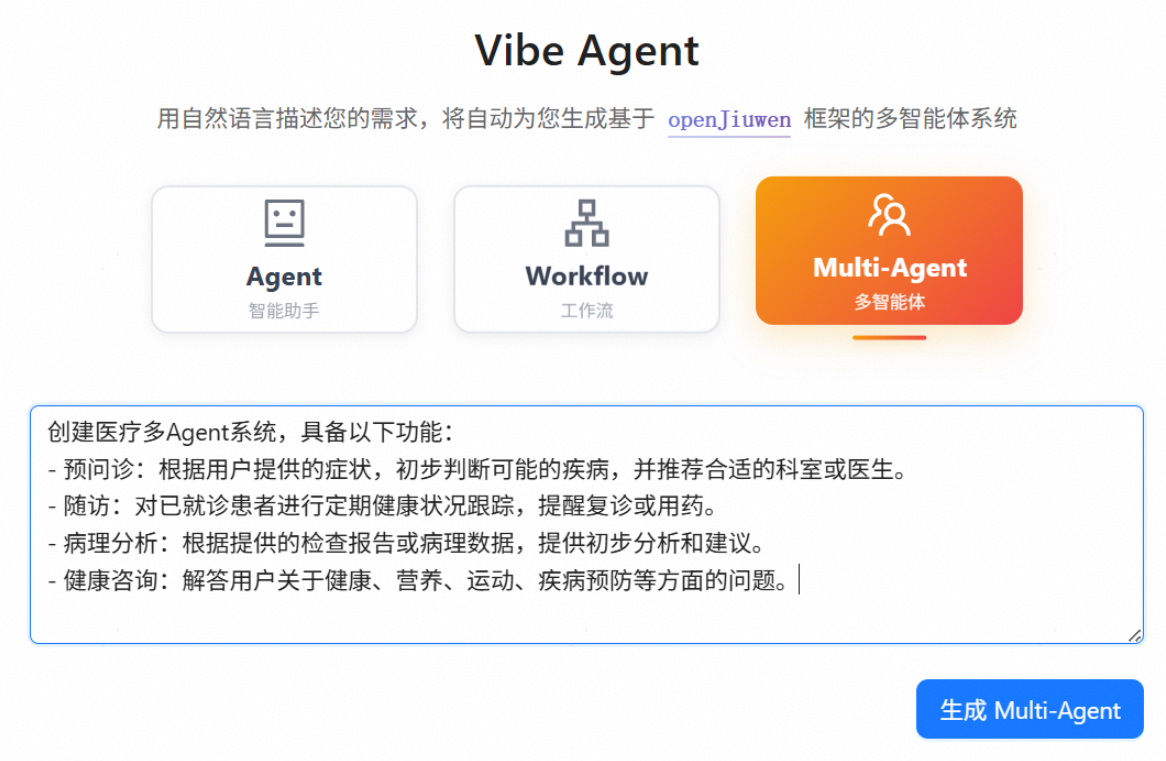
创建医疗多Agent系统,具备以下功能:
- 预问诊:根据用户提供的症状,初步判断可能的疾病,并推荐合适的科室或医生。
- 随访:对已就诊患者进行定期健康状况跟踪,提醒复诊或用药。
- 病理分析:根据提供的检查报告或病理数据,提供初步分析和建议。
- 健康咨询:解答用户关于健康、营养、运动、疾病预防等方面的问题。生成Multi-Agent
选择Multi-Agent多智能体模式,输入相应提示词后点击生成Agent即可一键式自动生成指定Agent,我们使用与上文中相似的提示词,由于当前Multi-Agent不支持使用工具,因此提示词中去掉了工具的相应描述。
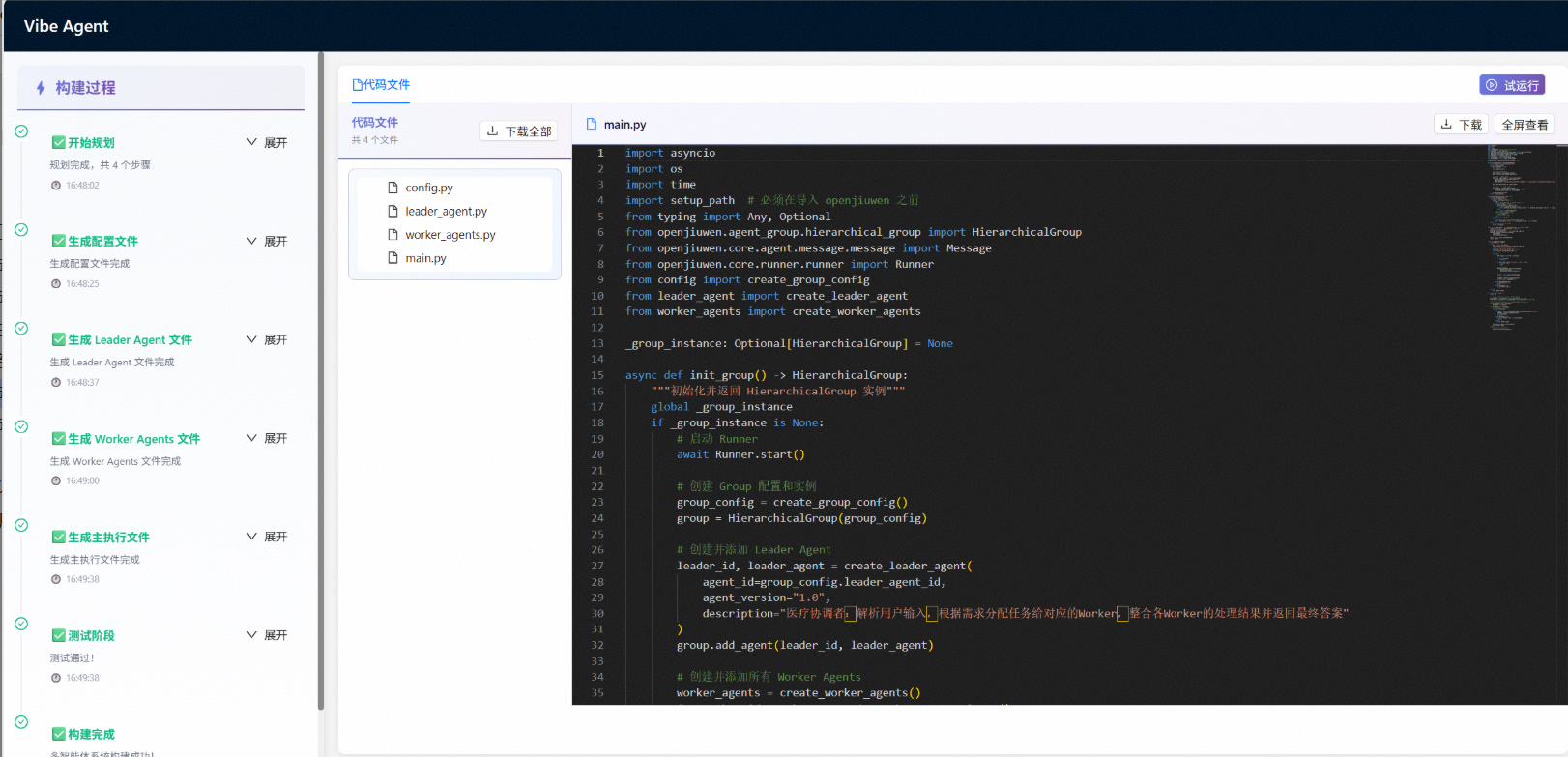
接收生成Agent指令后,VibeAgent系统首先会进行任务规划,之后按照规划的步骤依次生成配置文件、Leader Agent文件、Worker Agents文件、主执行文件,在页面中代码文件部分可以查看生成的相应代码,其中:
1、config.py主要为相应LLM模型配置和Group 配置;
2、leader_agent.py定义了Leader Agent,负责任务分解和协调Worker;
3、worker_agents.py定义多个Worker Agents,每个专注特定任务;
4、main.py为主执行文件,作为整个MultiAgent的入口;
生成完相应的代码文件后会自动进行测试,测试通过后即完成智能体的构建。
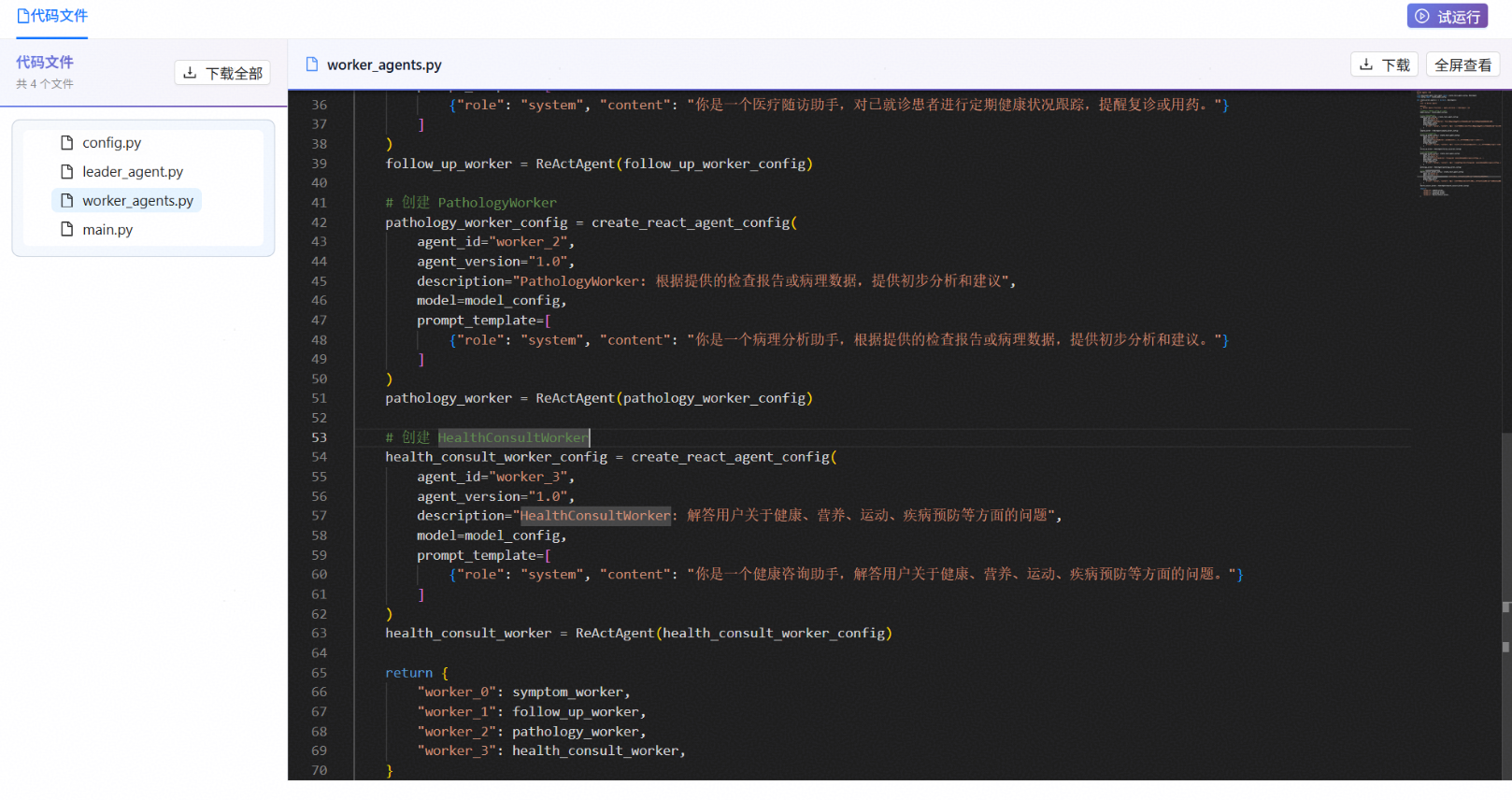
查看worker_agents.py文件可以看到系统创建了四个worker agents,分别对应我们定义的四个功能。
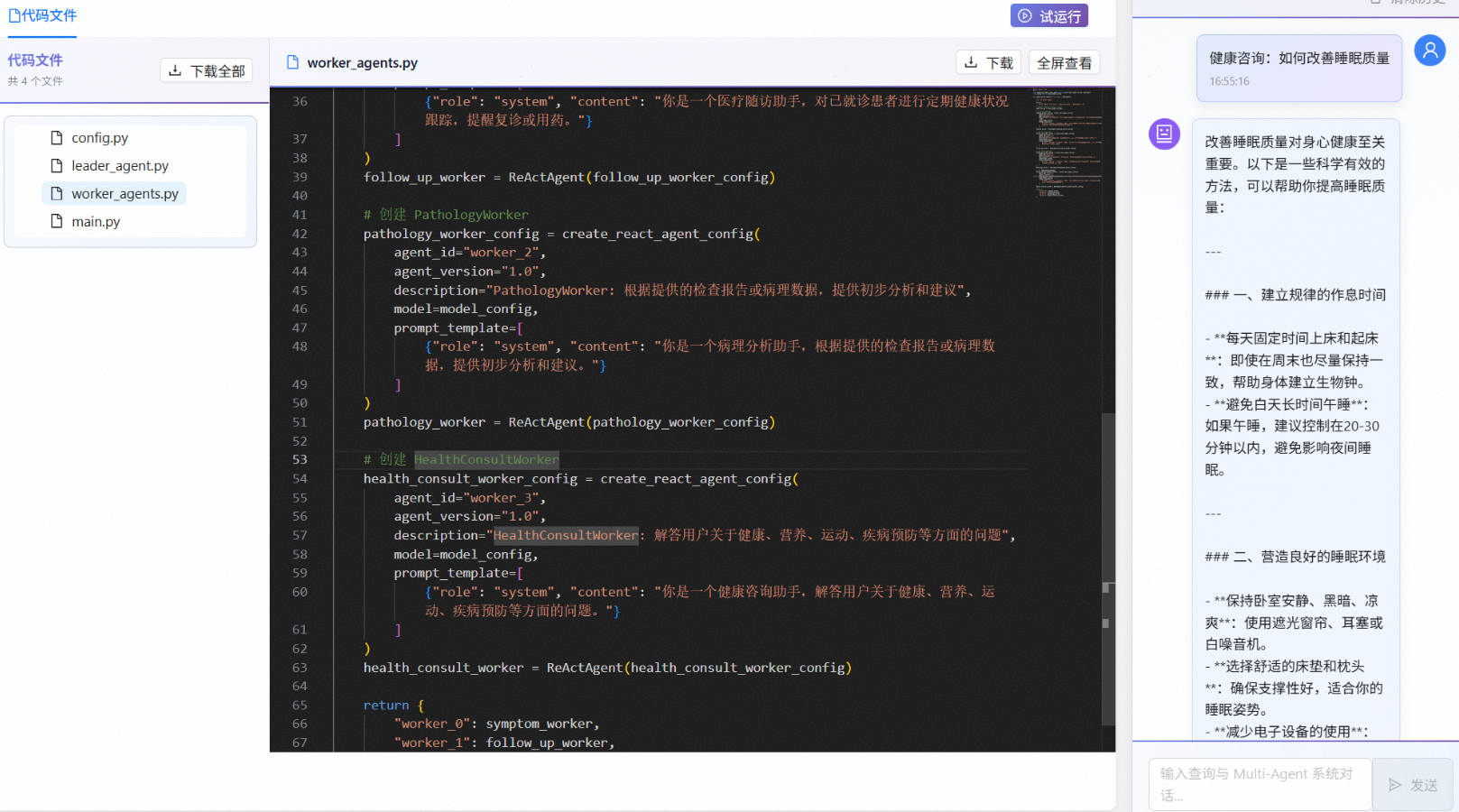
试运行
点击试运行按钮即可与Agent进行对话,Agent按预期进行回复。
2.7 调用系统生成的Agent
VibeAgent系统生成的代码保存在./experiments文件夹下,experiments文件夹下的每个文件夹对应一个生成的Agent/工作流,可以直接使用相应的代码来调用相应的Agent/工作流。
以新闻推荐工作流为例:
1、在相应Agent/工作流目录内新增python脚本用于调用工作流
直接执行main.py文件仅会进行测试,需自行编写脚本调用工作流,参考脚本test_workflow.py见附录3.2-工作流本地调用参考脚本
2、修改config.py文件
在import os后添加如下加载环境变量的代码
from dotenv import load_dotenv
# 加载 .env 文件(如果存在)
load_dotenv()3、复制/backend目录中的.env文件到/experiments文件夹下目标Agent/工作流文件夹内
复制.env文件后的参考目录结构如下所示:
4、执行工作流调用脚本
#可直接在上文创建的vibe_agent环境中执行测试
#或者可自行安装相应依赖包后进行测试
conda activate vibe_agent
python test_workflow.py执行结果如下所示:


可以参考上述流程自行编写相应脚本来调用系统生成的ReAct Agent或Multi-Agent。
3 附录
3.1 工作流服务化调用参考脚本
该脚本可用于调用服务化部署的工作流,实现在终端中与工作流进行交互,注意需修改base_url为实际的服务地址。
import requests
import json
import os
class WorkflowClient:
def __init__(self, base_url):
self.base_url = base_url
self.conversation_id = f"user_{os.getpid()}"
self.execution_id = None
self.component_id = None
self.auto_reply = False # 默认自动回复
def start_chat(self, query):
"""发送初始请求"""
payload = {
"query": query,
"conversation_id": self.conversation_id,
"auto_reply": self.auto_reply
}
response = requests.post(f"{self.base_url}/chat", json=payload)
return response.json()
def continue_execution(self, reply_value):
"""继续执行(人机交互)"""
payload = {
"execution_id": self.execution_id,
"reply_value": reply_value,
"component_id": self.component_id,
"auto_reply": self.auto_reply
}
response = requests.post(f"{self.base_url}/chat", json=payload)
return response.json()
def format_response(self, response):
"""精确提取混合格式响应中的JSON内容"""
if "content" not in response:
return "无返回内容"
content = response["content"]
try:
# 查找result={开头的部分
result_start = content.find("result={")
if result_start == -1:
return content # 如果没有result=,返回原始内容
# 提取大括号内的JSON部分
json_str = content[result_start + len("result="):]
json_end = json_str.find(" ", json_str.find("}")) # 找到第一个}后的空格
json_str = json_str[:json_end] if json_end != -1 else json_str
# 安全解析JSON字符串
import ast
result_dict = ast.literal_eval(json_str)
if isinstance(result_dict, dict) and "responseContent" in result_dict:
return result_dict["responseContent"]
return content # 如果没有responseContent,返回原始内容
except (SyntaxError, ValueError):
return content # 解析失败返回原始内容
def chat_with_user(self):
"""与用户交互的主循环"""
print("工作流已启动,输入'exit'退出")
while True:
user_input = input("用户: ")
if user_input.lower() == 'exit':
print("退出工作流")
break
if not self.execution_id:
# 初始请求
response = self.start_chat(user_input)
else:
# 继续执行
response = self.continue_execution(user_input)
# 处理响应
if response.get("interaction_required"):
# 需要用户输入
self.execution_id = response["execution_id"]
self.component_id = response["component_id"]
print(f"系统: {response['question']}")
if response["success"]:
formatted = self.format_response(response)
print(f"系统: \n {formatted}")
self.execution_id = None
self.component_id = None
if not response["success"] and not response.get("interaction_required"):
print(f"错误: {response.get('error', '未知错误')}")
continue
if __name__ == "__main__":
# 需修改base_url为实际的服务地址
base_url="http://localhost:8460"
client = WorkflowClient(base_url)
client.chat_with_user()3.2 工作流本地调用参考脚本
该脚本可用于本地调用工作流,实现在终端中与工作流进行交互,test_workflow.py代码如下所示:
import asyncio
import os
import sys
import io
from typing import List
# 设置标准输出编码(解决Windows控制台乱码)
if sys.platform == "win32":
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8', errors='replace')
from config import create_llm_client
from workflow_builder import build_workflow_agent
from openjiuwen.core.runtime.interaction.interactive_input import InteractiveInput
from openjiuwen.core.stream.base import OutputSchema
# 配置工作流超时(5分钟)
os.environ["WORKFLOW_EXECUTE_TIMEOUT"] = "300"
llm_client = create_llm_client()
async def handle_user_input(user_query: str, conversation_id: str):
"""处理用户输入的主逻辑"""
workflow_agent = build_workflow_agent()
response = await workflow_agent.invoke({"query": user_query, "conversation_id": conversation_id})
# 处理人机交互循环
while isinstance(response, List):
interactive_input = InteractiveInput()
for item in response:
if isinstance(item, OutputSchema) and item.type == '__interaction__':
component_id = item.payload.id
question = item.payload.value
# 显示问题并获取用户输入
print(f"系统问题: {question}")
user_reply = input("您的回答: ")
interactive_input.update(component_id, user_reply)
response = await workflow_agent.invoke({"conversation_id": conversation_id, "query": interactive_input})
print(f"执行结果: {response}")
return response
async def interactive_mode():
"""交互式主循环"""
print("工作流交互模式已启动(输入 'exit' 退出)")
conversation_id = f"user_{id(asyncio.get_event_loop())}" # 生成唯一会话ID
while True:
user_input = input("\n请输入您的问题(或 'exit' 退出): ")
if user_input.lower() == 'exit':
print("工作流结束")
break
await handle_user_input(user_input, conversation_id)
if __name__ == "__main__":
asyncio.run(interactive_mode())