PaddleOCR优化参考实践
发表于: 2026/03/13
1 非商用声明
本参考实践中提供的代码和调优方法仅供用户参考使用,用户可基于参考实践自行验证方案可行性,对比性能和精度,参考构建自己的软件。
2 方案介绍
2.1 背景
PaddleOCR是基于飞桨框架的文字识别、文档解析的开发套件,能精准识别图像与文档中的印刷文本、手写汉字、表格、公式、图表等元素,PaddleX是基于飞桨框架构建的低代码开发工具,通过PaddleOCR和PaddleX,可以快速构建OCR产线。
基于PaddleX部署通用OCR产线可使用多种推理后端,默认为Paddle推理后端,该推理后端支持动态shape,能适配不同大小的检测与识别框,适用范围广,但无法充分发挥昇腾硬件的性能;此外PaddleX还支持通过高性能推理插件使用om推理后端,在昇腾上采用经过编译的om格式模型进行离线推理,能大幅提升推理速度,但当前om推理后端仅支持静态shape,当检测和识别框与固定的输入shape差异较大时,由于resize等处理可能导致精度出现偏差。
本参考实践基于PaddleX高性能推理插件适配om推理后端的动态shape功能,结合鲲鹏能力使能KPCV等调优手段,在满足精度要求的前提下大幅提升OCR产线在昇腾硬件上的推理性能。
2.2 方案简介
本参考实践通过适配PaddleX代码的方式自动根据传入的om文件并判断该om模型是否为动态模型,来选择不同分支代码,从而同时支持动态shape和静态shape模型的离线推理。另外针对鲲鹏处理器做了OpenCV的相关优化。
本参考实践将以PP-OCRv5为例,端到端介绍该方案的修改适配和部署过程。
2.3 硬件环境
硬件 | 型号 |
|---|---|
AI服务器 | Atlas 800I A2 / 搭载Atlas 300I A2的 服务器 |
CPU | 鲲鹏920系列处理器 |
2.4 调优手段
调优手段 | 作用 |
|---|---|
设置CPU高性能模式 | 有效提升CPU性能,减少CPU运行空泡。模型前后处理部分主要使用CPU处理,该方式可提升模型前后处理速度 |
| 开启透明大页 | 推理时,CPU与NPU之间有大量的内存数据拷贝,开启透明大页可以提升这部分的性能 |
绑核优化 | 通过绑定NPU亲和的NUMA节点,减少调度时间,避免不同核间切换线程导致的性能抖动。提升前后处理性能 |
使用KPCV库编译优化OpenCV性能 | KPCV集成了OpenCV图算子优化,通过算法优化、向量指令优化和并行优化等手段,主要优化模型前处理时调用OpenCV对图片操作耗时。 |
onnxsim优化模型 | 使用onnxsim工具,对onnx模型结构进行优化,减少冗余算子,小幅度提升性能 |
om离线推理及适配动态shape | 将模型通过编译优化转为om模型进行离线推理,会对模型进行进一步的调优,有效提升推理性能。同时适配动态shape。保证模型在不同尺寸图片下的推理精度。 |
3 部署指导
3.1 开启CPU高性能模式
通常服务器在能耗菜单(Power Policy)提供Efficiency和Performance两种配置。出厂默认配置为Efficiency。在推理场景下,打开性能模式,可以有效提升CPU性能,减少CPU运行空泡,从而提升模型性能。
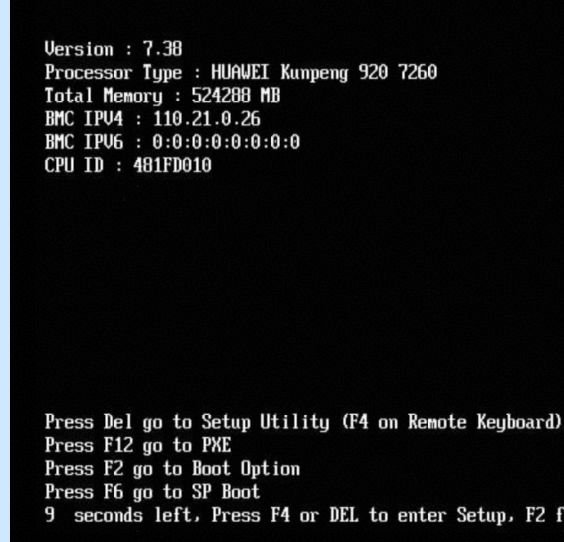
1.在BMC中,重启服务器,当处于下图界面时,通过Del键进入BIOS配置。
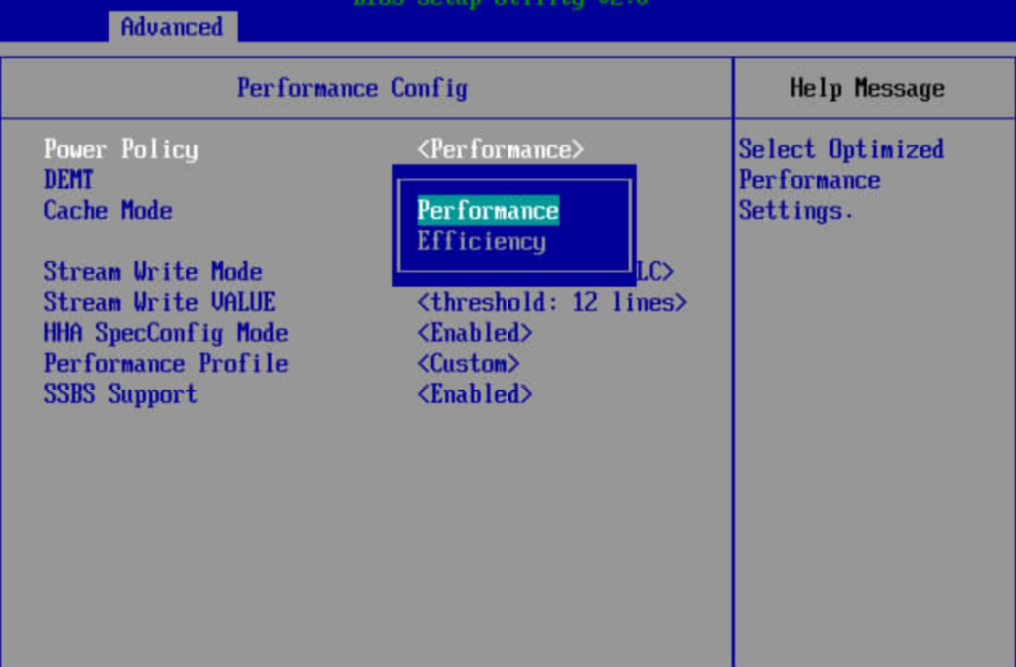
2.如下图所示,将配置项“PowerPolicy”的值设置为“Performance”,配置路径为“Advanced->Performance Config->Power Policy”。
3.2 开启透明大页
执行以下命令可开启透明大页:
echo always > /sys/kernel/mm/transparent_hugepage/enabled
echo always > /sys/kernel/mm/transparent_hugepage/defrag执行以下命令查看开启状态:
cat /sys/kernel/mm/transparent_hugepage/enabled
cat /sys/kernel/mm/transparent_hugepage/defrag如下图所示,显示为always表示成功开启透明大页:

3.3 构建推理环境
3.3.1 获取软件
通过下表中的链接下载相关软件或源码,其中OpenCV源码与KPCV用于鲲鹏处理器相关优化,可根据处理器类型选择下载。
软件名 | 版本 | 下载地址 | 简介 |
|---|---|---|---|
OS镜像 | openEuler-24.03-LTS-SP3 | 用于制作推理镜像的基础镜像。 | |
PaddleX源码 | 3.4.2 | 用于编译安装高性能推理插件。 | |
OpenCV源码(可选) | 4.10.0 | OpenCV源码,用于编译安装OpenCV。 | |
KPCV(可选) | 1.3.0 | KPCV是专为鲲鹏平台设计的图像处理优化库,用于优化OpenCV在鲲鹏处理器上的性能。 | |
CANN Toolkit | 8.5.0 | CANN Toolkit开发套件包,主要用于训练和推理业务、模型转换、算子/应用/模型的开发和编译。 | |
CANN OPS | 8.5.0 | CANN算子包,集成一系列算子包。 |
注:该版本下的CANN Toolkit要求驱动版本不低于25.0.0。
3.3.2 创建patch文件
3.3.2.1 创建paddlex.patch
创建paddlex.patch文件,主要用于适配动态shape推理,主要在模型加载,模型推理,资源释放模块做了修改,内容如下:
diff --git a/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.cc b/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.cc
index f8a87e2a2..83dcd4654 100644
--- a/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.cc
+++ b/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.cc
@@ -21,6 +21,7 @@
namespace ultra_infer {
bool OmBackend::aclInitFlag = false;
+uint32_t OmBackend::initCount = 0;
OmBackend::~OmBackend() {
FreeInputBuffer();
@@ -124,6 +125,15 @@ bool OmBackend::Infer(std::vector<FDTensor> &inputs,
<< ", errorCode is " << static_cast<int32_t>(aclRet);
return false;
}
+ aclDataType dtype = aclmdlGetInputDataType(modelDesc_, i);
+ aclTensorDesc *inputDesc =
+ aclCreateTensorDesc(dtype, inputs[i].Shape().size(), inputs[i].Shape().data(), ACL_FORMAT_NCHW);
+ aclRet = aclmdlSetDatasetTensorDesc(input_, inputDesc, i);
+ if (aclRet != ACL_SUCCESS) {
+ FDERROR << "SetDatasetTensorDesc failed."
+ << ", errorCode is " << static_cast<int32_t>(aclRet);
+ return false;
+ }
}
bool ret = Execute();
@@ -138,20 +148,18 @@ bool OmBackend::Infer(std::vector<FDTensor> &inputs,
// cp outputbuffer to outputs
outputs->resize(outputs_desc_.size());
std::vector<int64_t> temp_shape(4);
+ aclTensorDesc *outputDesc;
for (size_t i = 0; i < outputs_desc_.size(); ++i) {
temp_shape.resize(outputs_desc_[i].shape.size());
+ outputDesc = aclmdlGetDatasetTensorDesc(output_, i);
for (int j = 0; j < outputs_desc_[i].shape.size(); ++j) {
temp_shape[j] = outputs_desc_[i].shape[j];
+ if (temp_shape[j] <= 0) {
+ aclGetTensorDescDimV2(outputDesc, j, &temp_shape[j]);
+ }
}
(*outputs)[i].Resize(temp_shape, outputs_desc_[i].dtype,
outputs_desc_[i].name);
- size_t modelOutputSize = aclmdlGetOutputSizeByIndex(modelDesc_, i);
- if (modelOutputSize != (*outputs)[i].Nbytes()) {
- FDERROR << "output size is not match, index: " << i
- << ", modelOutputSize:" << modelOutputSize
- << ", (*outputs)[i].Nbytes():" << (*outputs)[i].Nbytes();
- return false;
- }
aclError aclRet = aclrtMemcpy(
(*outputs)[i].MutableData(), (*outputs)[i].Nbytes(), outputBuffer[i],
(*outputs)[i].Nbytes(), ACL_MEMCPY_DEVICE_TO_HOST);
@@ -168,6 +176,7 @@ bool OmBackend::Infer(std::vector<FDTensor> &inputs,
bool OmBackend::InitResource() {
// ACL init
aclError ret;
+ initCount += 1;
if (aclInitFlag == false) {
ret = aclInit(NULL);
if (ret != ACL_SUCCESS) {
@@ -219,35 +228,8 @@ bool OmBackend::LoadModel(const char *modelPath) {
FDERROR << "model has already been loaded";
return false;
}
- aclError ret = aclmdlQuerySize(modelPath, &modelWorkSize_, &modelWeightSize_);
- if (ret != ACL_SUCCESS) {
- FDERROR << "query model false, model file is" << modelPath
- << ", errorCode is " << static_cast<int32_t>(ret);
- return false;
- }
- // using ACL_MEM_MALLOC_HUGE_FIRST to malloc memory, huge memory is preferred
- // to use and huge memory can improve performance.
- ret = aclrtMalloc(&modelWorkPtr_, modelWorkSize_, ACL_MEM_MALLOC_HUGE_FIRST);
- if (ret != ACL_SUCCESS) {
- FDERROR << "malloc buffer for work failed, require size is "
- << modelWorkSize_ << ", errorCode is " << static_cast<int32_t>(ret);
- return false;
- }
- // using ACL_MEM_MALLOC_HUGE_FIRST to malloc memory, huge memory is preferred
- // to use and huge memory can improve performance.
- ret = aclrtMalloc(&modelWeightPtr_, modelWeightSize_,
- ACL_MEM_MALLOC_HUGE_FIRST);
- if (ret != ACL_SUCCESS) {
- FDERROR << "malloc buffer for weight failed, require size is "
- << modelWeightSize_ << ", errorCode is "
- << static_cast<int32_t>(ret);
- return false;
- }
-
- ret = aclmdlLoadFromFileWithMem(modelPath, &modelId_, modelWorkPtr_,
- modelWorkSize_, modelWeightPtr_,
- modelWeightSize_);
+ aclError ret = aclmdlLoadFromFile(modelPath, &modelId_);
if (ret != ACL_SUCCESS) {
FDERROR << "load model from file failed, model file is " << modelPath
<< ", errorCode is " << static_cast<int32_t>(ret);
@@ -264,6 +246,13 @@ bool OmBackend::Execute() {
if (ret != ACL_SUCCESS) {
FDERROR << "execute model failed, modelId is " << modelId_
<< ", errorCode is " << static_cast<int32_t>(ret);
+ if(outputSize_ != 0) {
+ FDERROR << "Model infer failed with dynamic shape, Possible reasons:\n"
+ << "1.Insufficient memory allocated for output. Current value:"
+ << outputSize_ << "Please estimate the required output memory size"
+ << "and configure it via the environment variable ASCEND_OM_OUTPUTSIZE\n"
+ << "2.Some other reasons. Please analyze the error logs at ~/ascend/log\n";
+ }
return false;
}
return true;
@@ -390,6 +379,22 @@ bool OmBackend::CreateInput() {
return true;
}
+size_t OmBackend::GetOutputSizeFromENV() {
+ const char *outputSize = std::getenv("ASCEND_OM_OUTPUTSIZE");
+ size_t defaultOutputSize = 64; // 64MB
+ try {
+ size_t size = static_cast<size_t>(std::stoul(std::string(outputSize)));
+ if (size <= 0 || size >= 32000) {
+ FDWARNING << "ASCEND_OM_OUTPUTSIZE is invalid, use default outputSize";
+ size = defaultOutputSize;
+ }
+ return size;
+ } catch (const std::exception &e) {
+ return defaultOutputSize;
+ }
+ return defaultOutputSize;
+}
+
bool OmBackend::CreateOutput() {
if (modelDesc_ == nullptr) {
FDERROR << "no model description, create output failed";
@@ -407,6 +412,10 @@ bool OmBackend::CreateOutput() {
outputBuffer.resize(outputSize, nullptr);
for (size_t i = 0; i < outputSize; ++i) {
size_t modelOutputSize = aclmdlGetOutputSizeByIndex(modelDesc_, i);
+ if (modelOutputSize == 0) {
+ outputSize_ = GetOutputSizeFromENV();
+ modelOutputSize = outputSize_ * 1024 * 1024;
+ }
aclError ret = aclrtMalloc(&outputBuffer[i], modelOutputSize,
ACL_MEM_MALLOC_HUGE_FIRST);
if (ret != ACL_SUCCESS) {
@@ -525,8 +534,6 @@ void OmBackend::DestroyOutput() {
for (size_t i = 0; i < aclmdlGetDatasetNumBuffers(output_); ++i) {
aclDataBuffer *dataBuffer = aclmdlGetDatasetBuffer(output_, i);
- void *data = aclGetDataBufferAddr(dataBuffer);
- (void)aclrtFree(data);
(void)aclDestroyDataBuffer(dataBuffer);
}
@@ -542,6 +549,15 @@ void OmBackend::DestroyResource() {
<< ", errorCode is " << static_cast<int32_t>(ret);
return;
}
+
+ ret = aclmdlUnload(modelId_);
+ if (ret != ACL_SUCCESS) {
+ FDERROR << "aclmdlUnload failed"
+ << ", errorCode is " << static_cast<int32_t>(ret);
+ return;
+ }
+ loadFlag_ = false;
+
if (stream_ != nullptr) {
ret = aclrtDestroyStream(stream_);
if (ret != ACL_SUCCESS) {
@@ -566,14 +582,17 @@ void OmBackend::DestroyResource() {
<< " failed, errorCode = " << static_cast<int32_t>(ret);
}
- if (aclInitFlag == true) {
+ if (initCount == 1) {
ret = aclFinalize();
if (ret != ACL_SUCCESS) {
FDERROR << "finalize acl failed, errorCode = "
<< static_cast<int32_t>(ret);
}
aclInitFlag = false;
+ } else {
+ initCount -= 1;
}
}
} // namespace ultra_infer
+
diff --git a/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.h b/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.h
index 5a31b21b8..61a8f29da 100644
--- a/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.h
+++ b/deploy/ultra-infer/ultra_infer/runtime/backends/om/om_backend.h
@@ -59,6 +59,7 @@ private:
uint32_t modelId_;
size_t modelWorkSize_; // model work memory buffer size
size_t modelWeightSize_; // model weight memory buffer size
+ size_t outputSize_ = 0;
void *modelWorkPtr_; // model work memory buffer
void *modelWeightPtr_; // model weight memory buffer
aclmdlDesc *modelDesc_;
@@ -66,6 +67,7 @@ private:
aclmdlDataset *output_;
aclrtContext context_;
aclrtStream stream_;
+ static uint32_t initCount;
bool LoadModel(const char *modelPath);
bool Execute();
@@ -78,5 +80,7 @@ private:
void FreeInputBuffer();
void FreeOutputBuffer();
bool InitResource();
+ size_t GetOutputSizeFromENV();
};
} // namespace ultra_infer
+
diff --git a/paddlex/inference/models/text_recognition/processors.py b/paddlex/inference/models/text_recognition/processors.py
index 3b7ec44d7..1ef2cd08e 100644
--- a/paddlex/inference/models/text_recognition/processors.py
+++ b/paddlex/inference/models/text_recognition/processors.py
@@ -276,7 +276,9 @@ class CTCLabelDecode(BaseRecLabelDecode):
"""apply"""
preds = np.array(pred[0])
preds_idx = preds.argmax(axis=-1)
- preds_prob = preds.max(axis=-1)
+ indices_exp = np.expand_dims(preds_idx, axis=-1)
+ preds_prob = np.take_along_axis(preds, indices_exp, axis=-1)
+ preds_prob = np.squeeze(preds_prob, axis=-1)
text = self.decode(
preds_idx,
preds_prob,
3.3.2.2 (可选)修改kcv.patch
执行以下命令解压已下载的KPCV软件,得到rpm包与kcv.patch。
unzip BoostKit-boostmedia-kp_cv-1.3.0.zip在当前PaddleOCR场景下,kcv.patch需做适当删改,该patch主要用于优化OpenCV的resize等接口性能,修改后内容如下:
diff --git a/modules/core/CMakeLists.txt b/modules/core/CMakeLists.txt
index 16f32c9..efa71ff 100644
--- a/modules/core/CMakeLists.txt
+++ b/modules/core/CMakeLists.txt
@@ -242,3 +242,4 @@ endif()
if(NOT OPENCV_DATA_CONFIG_STR STREQUAL "${__content}")
file(WRITE "${OPENCV_DATA_CONFIG_FILE}" "${OPENCV_DATA_CONFIG_STR}")
endif()
+target_link_libraries(${PROJECT_NAME} PRIVATE kp_cv)
\ No newline at end of file
diff --git a/modules/imgproc/CMakeLists.txt b/modules/imgproc/CMakeLists.txt
index 10aed6b..2179fcd 100644
--- a/modules/imgproc/CMakeLists.txt
+++ b/modules/imgproc/CMakeLists.txt
@@ -19,3 +19,5 @@ if(HAVE_IPP)
ocv_append_source_file_compile_definitions(${CMAKE_CURRENT_SOURCE_DIR}/src/smooth.dispatch.cpp "ENABLE_IPP_GAUSSIAN_BLUR=1")
endif()
endif()
+
+target_link_libraries(${PROJECT_NAME} PRIVATE kp_cv)
\ No newline at end of file
diff --git a/modules/imgproc/src/color.cpp b/modules/imgproc/src/color.cpp
index dde8e13..32df74d 100644
--- a/modules/imgproc/src/color.cpp
+++ b/modules/imgproc/src/color.cpp
@@ -5,7 +5,7 @@
#include "precomp.hpp"
#include "opencl_kernels_imgproc.hpp"
#include "color.hpp"
-
+#include "kcv.h"
namespace cv
{
@@ -191,6 +191,10 @@ void cvtColorTwoPlane( InputArray _ysrc, InputArray _uvsrc, OutputArray _dst, in
void cvtColor( InputArray _src, OutputArray _dst, int code, int dcn )
{
+
+ int retcode = kcv_cvtColor(_src, _dst, code, dcn);
+ if(retcode == 0 || retcode == 1)
+ return;
CV_INSTRUMENT_REGION();
CV_Assert(!_src.empty());
diff --git a/modules/imgproc/src/morph.dispatch.cpp b/modules/imgproc/src/morph.dispatch.cpp
index 0cb50ec..a59fb75 100644
--- a/modules/imgproc/src/morph.dispatch.cpp
+++ b/modules/imgproc/src/morph.dispatch.cpp
@@ -50,7 +50,7 @@
#include "morph.simd.hpp"
#include "morph.simd_declarations.hpp" // defines CV_CPU_DISPATCH_MODES_ALL=AVX2,...,BASELINE based on CMakeLists.txt content
-
+#include "kcv.h"
/****************************************************************************************\
Basic Morphological Operations: Erosion & Dilation
@@ -1017,6 +1017,9 @@ void dilate( InputArray src, OutputArray dst, InputArray kernel,
Point anchor, int iterations,
int borderType, const Scalar& borderValue )
{
+ int retcode = kcv_dilate(src,dst,kernel,anchor,iterations,borderType,borderValue);
+ if(retcode == 0 || retcode == 1)
+ return;
CV_INSTRUMENT_REGION();
CV_Assert(!src.empty());
diff --git a/modules/imgproc/src/resize.cpp b/modules/imgproc/src/resize.cpp
index 7e45f1e..dfe7a5e 100644
--- a/modules/imgproc/src/resize.cpp
+++ b/modules/imgproc/src/resize.cpp
@@ -58,7 +58,7 @@
#include "opencv2/core/softfloat.hpp"
#include "fixedpoint.inl.hpp"
-
+#include "kcv.h"
using namespace cv;
namespace
@@ -4145,6 +4145,10 @@ void resize(int src_type,
void cv::resize( InputArray _src, OutputArray _dst, Size dsize,
double inv_scale_x, double inv_scale_y, int interpolation )
{
+
+ int retcode = cv::kcv_resize(_src,_dst,dsize,inv_scale_x,inv_scale_y,interpolation);
+ if(retcode == 0 || retcode == 1)
+ return;
CV_INSTRUMENT_REGION();
Size ssize = _src.size();
diff --git a/modules/imgproc/src/smooth.dispatch.cpp b/modules/imgproc/src/smooth.dispatch.cpp
index d0f50a7..2d06d70 100644
--- a/modules/imgproc/src/smooth.dispatch.cpp
+++ b/modules/imgproc/src/smooth.dispatch.cpp
@@ -65,7 +65,7 @@ namespace cv {
#include "smooth.simd.hpp"
#include "smooth.simd_declarations.hpp" // defines CV_CPU_DISPATCH_MODES_ALL=AVX2,...,BASELINE based on CMakeLists.txt content
-
+#include "kcv.h"
namespace cv {
/****************************************************************************************\
@@ -612,6 +612,9 @@ void GaussianBlur(InputArray _src, OutputArray _dst, Size ksize,
double sigma1, double sigma2,
int borderType)
{
+ int retcode = kcv_GaussianBlur(_src, _dst, ksize, sigma1, sigma2, borderType);
+ if(retcode == 0 || retcode == 1)
+ return;
CV_INSTRUMENT_REGION();
CV_Assert(!_src.empty());
注:编译安装OpenCV为针对鲲鹏处理器的相关优化,若不适用则本步骤可不进行操作。
3.3.3 准备Dockerfile
创建名为Dockerfile的文件,用于构建paddlex镜像,内容如下:
FROM openeuler-24.03-lts-sp3
ARG SSL_VERIFY=true
WORKDIR /tmp
COPY . ./
# 安装编译环境
RUN echo "sslverify=${SSL_VERIFY}" >> /etc/yum.conf && \
yum install -y bc wget gcc gcc-c++ make cmake git python3-pip shadow-utils wget vim \
util-linux findutils python3-devel pciutils mesa-libGL unzip \
binutils pkgconfig lapack ffmpeg ffmpeg-devel libjpeg-* python3-numpy && \
ln -sf /usr/bin/pip3.11 /usr/bin/pip && \
ln -sf /usr/bin/python3.11 /usr/bin/python && \
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ && \
pip config set global.trusted-host mirrors.aliyun.com && \
yum clean all && \
rm -rf /var/cache/yum
ENV LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/driver:/usr/local/Ascend/driver/lib64/common:/usr/local/lib/KPCV \
PATH=/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin \
ENABLE_OM_BACKEND=ON ENABLE_ORT_BACKEND=ON ENABLE_PADDLE_BACKEND=OFF WITH_GPU=OFF DEVICE_TYPE=NPU \
NPU_HOST_LIB=/usr/local/Ascend/ascend-toolkit/latest/aarch64-linux/lib64 \
C_INCLUDE_PATH=/usr/local/include/KPCV \
CPLUS_INCLUDE_PATH=/usr/local/include/KPCV \
PYTHONPATH=/usr/local/include/KPCV \
LIBRARY_PATH=/usr/local/lib/KPCV
# Toolkit envs
ENV ASCEND_TOOLKIT_HOME=/usr/local/Ascend/ascend-toolkit/latest
ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/lib64:${ASCEND_TOOLKIT_HOME}/lib64/plugin/opskernel:$LD_LIBRARY_PATH
ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/lib64/plugin/nnengine:${ASCEND_TOOLKIT_HOME}/opp/built-in/op_impl/ai_core/tbe/op_tiling/lib/linux/${ARCH}:$LD_LIBRARY_PATH
ENV LD_LIBRARY_PATH=${ASCEND_TOOLKIT_HOME}/tools/aml/lib64:${ASCEND_TOOLKIT_HOME}/tools/aml/lib64/plugin:$LD_LIBRARY_PATH
ENV PYTHONPATH=${ASCEND_TOOLKIT_HOME}/python/site-packages:${ASCEND_TOOLKIT_HOME}/opp/built-in/op_impl/ai_core/tbe:$PYTHONPATH
ENV PATH=${ASCEND_TOOLKIT_HOME}/bin:${ASCEND_TOOLKIT_HOME}/compiler/ccec_compiler/bin:${ASCEND_TOOLKIT_HOME}/tools/ccec_compiler/bin:$PATH
ENV ASCEND_AICPU_PATH=${ASCEND_TOOLKIT_HOME} \
ASCEND_OPP_PATH=${ASCEND_TOOLKIT_HOME}/opp \
TOOLCHAIN_HOME=${ASCEND_TOOLKIT_HOME}/toolkit \
ASCEND_HOME_PATH=${ASCEND_TOOLKIT_HOME}
# python包
RUN tar -xvf PaddleX*.tar.gz -C /opt && \
cd /opt/PaddleX* && git apply /tmp/paddlex.patch && \
pip install -e ".[base]" && \
pip install wheel && \
pip install onnxsim && \
pip install paddle2onnx==2.1.0 && \
pip install paddlepaddle==3.2.2 && \
pip install colored && \
pip install "onnxruntime>=1.10.0" && \
pip install "onnx_graphsurgeon>=0.3.27" && \
pip install decorator && \
paddlex --install serving && \
rm -rf /root/.cache/pip
RUN chmod +x *.run && \
./Ascend-cann-toolkit*.run --full --quiet && \
./Ascend-cann-910*-ops*.run --install --quiet && \
cd /opt/PaddleX*/deploy/ultra-infer/python && \
python setup.py build && \
python setup.py bdist_wheel && \
pip install dist/ultra_infer_npu*.whl
# 编译安装OpenCV
RUN rpm -ivh boostkit-boostmedia-kp_cv*.rpm && \
unzip opencv-4.10.0.zip && cd opencv-4.10.0 && \
git apply /tmp/kcv.patch && mkdir build && \
cmake -S . -B build \
-D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D CMAKE_CXX_FLAGS="-O3 -march=armv8-a" \
-D CMAKE_C_FLAGS="-O3 -march=armv8-a" \
-D BUILD_opencv_python3=ON\
-D OPENCV_GENERATE_PKGCONFIG=ON \
-D PYTHON3_EXECUTABLE=$(which python3) \
-D OPENCV_PYTHON3_INSTALL_PATH=/usr/local/lib64/python3.11/site-packages/ && \
cd build && make -j8 && make install && \
rm -rf /tmp/*注:编译安装OpenCV为针对鲲鹏处理器相关优化,若不适用可自行从Dockerfile去删去。
3.3.4 构建镜像
执行以下命令加载基础镜像。
docker load -i openEuler-docker.aarch64.tar.xz将Dockerfile与下载软件包放在同一目录下,如下图所示:

在Dockerfile的同级目录下,执行以下命令构建paddlex镜像:
docker build -t paddlex .构建镜像依赖网络,如需配置代理可使用以下命令,将${http_proxy}与${https_proxy}替换为实际代理地址。
docker build -t paddlex --build-arg http_proxy=${http_proxy} --build-arg https_proxy=${https_proxy} .构建镜像时默认开启SSL验证,如需关闭可使用以下命令:
docker build -t paddlex \
--build-arg http_proxy=${http_proxy} \
--build-arg https_proxy=${https_proxy} \
--build-arg SSL_VERIFY=false \
.3.3.5 启动容器
执行以下命令启动paddlex容器:
docker run -itd -u root --name=paddlex --ipc=host --net=host \
--device=/dev/davinci0 \
--device=/dev/davinci1 \
--device=/dev/davinci2 \
--device=/dev/davinci3 \
--device=/dev/davinci4 \
--device=/dev/davinci5 \
--device=/dev/davinci6 \
--device=/dev/davinci7 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/Ascend/add-ons/:/usr/local/Ascend/add-ons/ \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu/slog/:/var/log/npu/slog \
-v /var/log/npu/profiling/:/var/log/npu/profiling \
-v /var/log/npu/dump/:/var/log/npu/dump \
-v /var/log/npu/:/usr/slog \
-v /data:/data \
paddlex \
/bin/bash其中-v /data:/data为模型权重所在路径,可替换为实际路径。
执行以下命令进入paddlex容器:
docker exec -it paddlex bash3.4 准备om模型
3.4.1 下载原始模型
模型 | 下载链接 |
|---|---|
PP-OCRv5_server_det | |
PP-OCRv5_server_rec |
3.4.2 导出onnx模型
paddlex --paddle2onnx --paddle_model_dir /path/to/PP-OCRv5_server_det/ --onnx_model_dir /path/to/PP-OCRv5_server_det/
paddlex --paddle2onnx --paddle_model_dir /path/to/PP-OCRv5_server_rec/ --onnx_model_dir /path/to/PP-OCRv5_server_rec/参数名 | 简介 |
|---|---|
paddle_model_dir | PaddlePaddle模型存储目录 |
onnx_model_dir | onnx模型存储目录 |
3.4.3 生成om模型
# 使用动态shape,通过参数input_shape指定输入shape范围
cd /path/to/PP-OCRv5_server_det/
atc --framework=5 --model=inference.onnx --output=inference --input_format=ND --input_shape=x:1,3,32~4000,32~4000 --log=error --precision_mode_v2=origin --soc_version=Ascend910B4
cd /path/to/PP-OCRv5_server_rec/
onnxsim inference.onnx inference_sim.onnx
atc --framework=5 --model=inference_sim.onnx --output=inference --input_format=ND --input_shape=x:1~8,3,48,160~3200 --log=error --soc_version=Ascend910B4参数名 | 简介 |
|---|---|
framework | 原始模型类型,5表示为onnx模型 |
model | 原始模型路径 |
output | om文件名,结尾会自动加上.om后缀 |
input_format | 模型输入数据的格式,支持NCHW、NCDHW、ND(表示支持任意维度格式,N<=4)三种格式 |
input_shape | 指定模型输入数据的shape |
某些场景下生成的om模型名称可能不是inference.om,需要重命名为inference.om
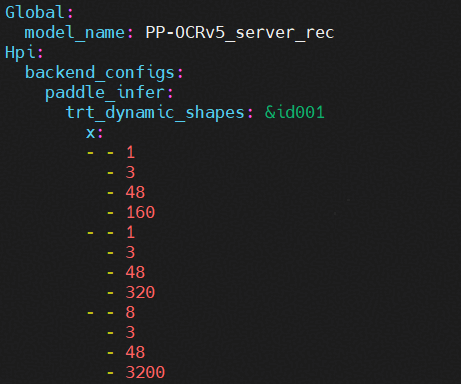
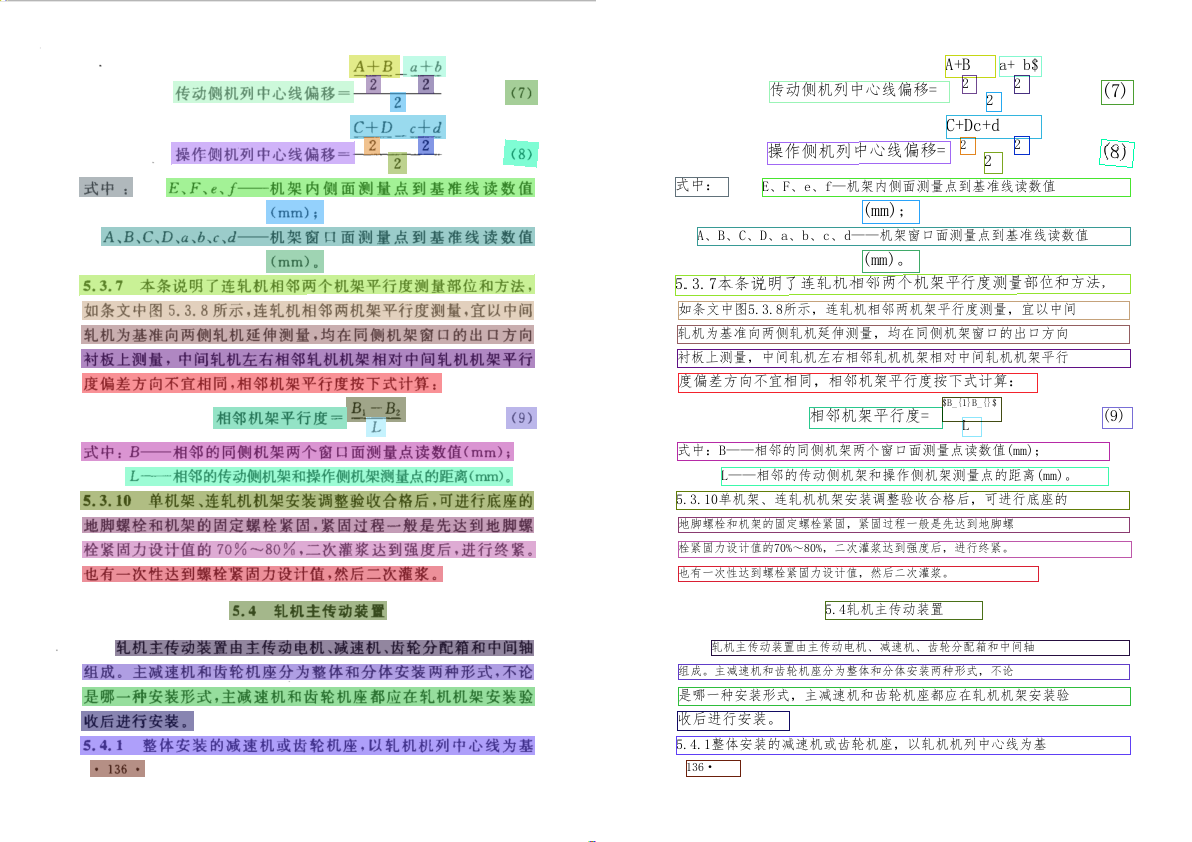
mv xxx.om inference.om其中input_shape参数可参考模型的inference.yml文件,如下图所示,图中1,3,48,160为最小shape,8,3,48,3200为最大shape,所以input_shape参数设置为x:1~8,3,48,160~3200
3.5 绑核优化
1.执行以下命令查询每张卡对应Bus-Id:
npu-smi info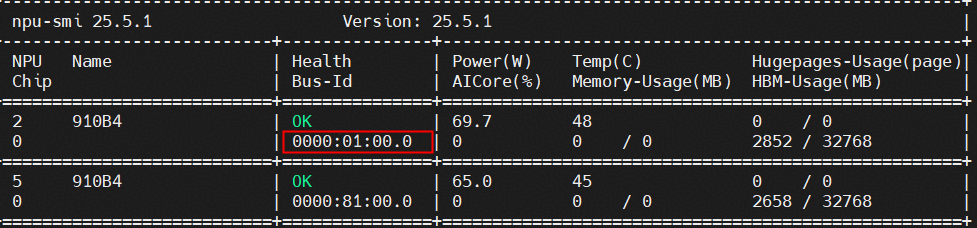
2.执行以下命令查看每张卡亲和的NUMA节点:
lspci -vs Bus-Id
3.执行以下命令查询NUMA node对应的cpu:
lscpu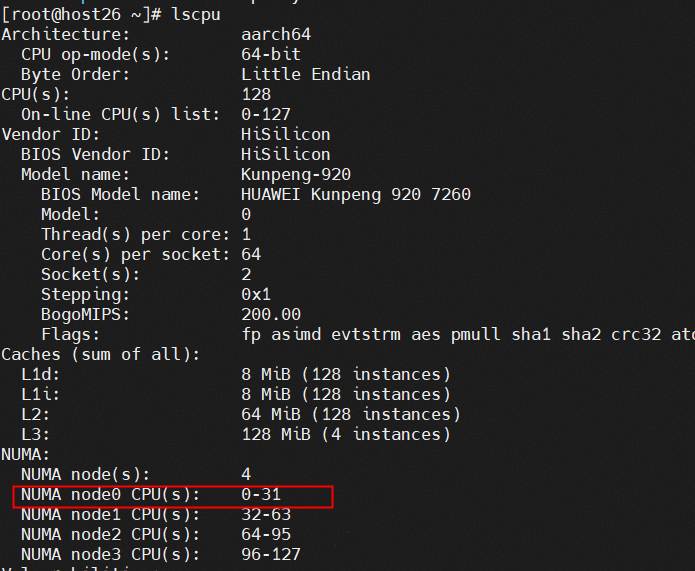
4.在执行推理任务时使用绑核优化性能,参考命令如下,注意绑核建议避开0号(避免与操作系统内核线程争抢资源):
taskset -c 1-31 python infer.py3.6 离线推理部署指导
1.创建产线配置文件 OCR.yml
pipeline_name: OCR
text_type: general
# 未使用的模型配置为False
use_doc_preprocessor: False
use_textline_orientation: False
# 高性能插件配置
hpi_config:
auto_config: False
backend: om
device_type: npu
SubPipelines:
DocPreprocessor:
pipeline_name: doc_preprocessor
use_doc_orientation_classify: False
use_doc_unwarping: False
SubModules:
DocOrientationClassify:
module_name: doc_text_orientation
model_name: PP-LCNet_x1_0_doc_ori
model_dir: null
DocUnwarping:
module_name: image_unwarping
model_name: UVDoc
model_dir: null
SubModules:
TextDetection:
# 配置模型名称及路径
module_name: text_detection
model_name: PP-OCRv5_server_det
model_dir: /path/to/paddleocr/models/PP-OCRv5_server_det
limit_type: max
limit_side_len: 960
TextLineOrientation:
module_name: textline_orientation
model_name: PP-LCNet_x0_25_textline_ori
model_dir: null
TextRecognition:
module_name: text_recognition
model_name: PP-OCRv5_server_rec
model_dir: /path/to/paddleocr/models/PP-OCRv5_server_rec
batch_size: 42.创建推理脚本infer.py,其中推理图片的长宽需满足在3.3章节生成det模型配置的范围内,在本文使用的模型输入shape范围为32-3200。
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./OCR.yml", device="npu", use_hpip=True)
image = "./test.png" # 图片路径
output = pipeline.predict(image)
for res in output:
res.print()
res.save_to_img("./output/")3.参考3.5章节,通过绑核的方式执行推理脚本:
taskset -c 1-31 python infer.py4.推理验证,以下面图片作为示例进行推理:

推理结果会保存在output目录下:
下图为原始静态shape下的推理结果,由于需要对图片进行缩放以满足静态shape要求,导致精度有损失:

3.7 服务化推理部署指导
1.安装服务化插件。
paddlex --install serving2.参考3.5章节,通过绑核的方式拉起服务:
taskset -c 1-31 paddlex --serve --pipeline OCR.yml --use_hpip3.调用服务:参考使用教程 - PaddleOCR 文档开发集成部署的多语言调用服务示例,以下为python调用示例:
import base64
import requests
API_URL = "http://localhost:8080/ocr"
file_path = "./demo.jpg"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["ocrResults"]):
print(res["prunedResult"])
ocr_img_path = f"ocr_{i}.jpg"
with open(ocr_img_path, "wb") as f:
f.write(base64.b64decode(res["ocrImage"]))
print(f"Output image saved at {ocr_img_path}")4.推理验证,输入输出同3.6章节推理验证。
4 常见问题
4.1 缺少字体库
推理时遇到如下日志,且推理生成图片无法看到识别的文字,则可能是字体库下载失败导致,可自行下载该字体库文件并拷贝到~/.paddlex/fonts/目录下。
cp simfang.ttf ~/.paddlex/fonts/