



NPU虚拟化软切分参考实践
发表于: 2026/03/10
非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考文档构建自己的软件,产品化方案需进行安全、可靠性加固,不能直接将相关Demo或镜像文件集成到商用产品中。
1 方案介绍
1.1 背景
在教育AI实训场景中,学生通过各类模型训练和推理实验,掌握NLP、CV、LLM等模型知识。在该场景下,对性能要求相对较低,但是对硬件成本比较敏感。需要同时支持多个学生进行上机操作,通常单卡需要同时运行不少于8个实训任务。
针对该场景,采用软切分方案,基于时分复用的算力分配方案实现更细粒度的算力分配,可支持单卡同时运行≥8个实训任务,大幅降低AI教学的成本,并显著提升硬件资源利用率。
1.2 方案简介
本软切分方案主要基于时间片轮转实现算力资源控制,支持多种资源调度模式。方案示意图如下:
图1 软切分方案示意图
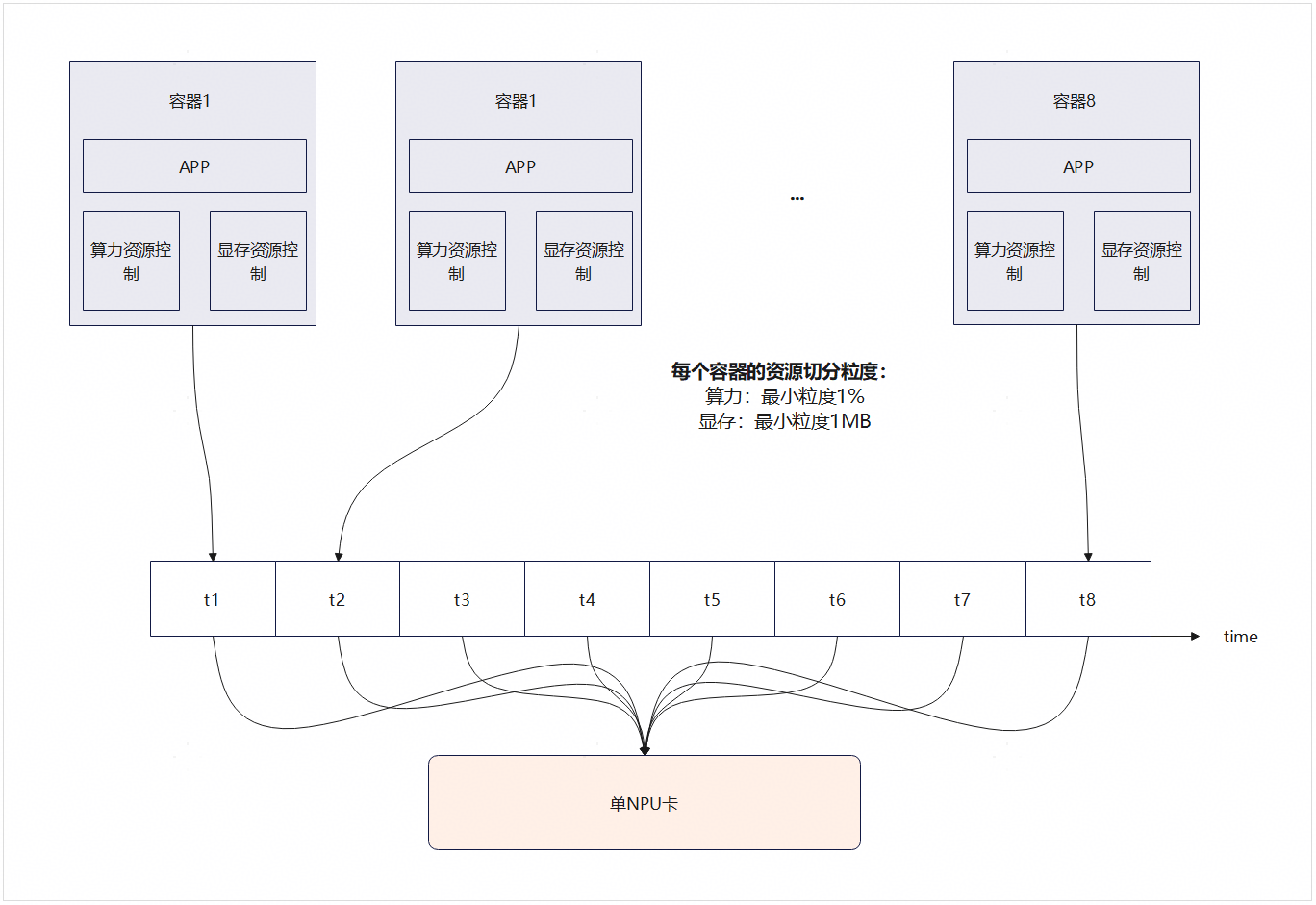
1.3 关键规格
1、支持硬件:本切分方案支持Atlas 300I A2、Atlas 800I A2。
2、支持场景:软切分特性支持推理、训练场景。
3、AI Core切分粒度不低于1%。
4、显存切分最小粒度1MB。
5、支持模型:已验证模型支持情况(支持模型不限于下表,如超出本表范围,可按需自行验证)。
模型 | 类型 | Atlas 300I A2 | Atlas 800I A2 |
|---|---|---|---|
YOLOv8 | 训练、推理 | √ | √ |
YOLOv12 | 训练、推理 | √ | √ |
ResNet50 | 训练、推理 | √ | √ |
Bert+ERNIE | 训练、推理 | √ | √ |
BiLstm+Crf | 训练、推理 | √ | √ |
TextRCNN | 训练、推理 | √ | √ |
FaceNet | 训练、推理 | √ | √ |
Transformer | 训练、推理 | √ | √ |
U-Net | 训练、推理 | √ | √ |
BERT | 训练、推理 | √ | √ |
MobileNet | 训练、推理 | √ | √ |
Qwen3-VL-8B | 推理 | √ | √ |
DeepSeek-R1-Distill-Qwen-7B | 推理 | √ | √ |
bge-m3 | 推理 | √ | √ |
Qwen3-32B-w8a8 | 推理 | √ | √ |
Qwen3-0.6B | 推理 | √ | √ |
DeepSeek-R1-1.5B | 推理 | √ | √ |
2 使用指导
2.1 软件配置
本参考实践使用的软件配套版本如下:
软件/镜像 | 版本 | 说明 |
|---|---|---|
Ascend HDK | 25.5.0 | NPU驱动固件 |
CANN | 8.5.0 | 昇腾异构计算架构 |
Docker | 18.09.0 | 用于部署容器,支持18.09.x及以上版本 |
Kubernetes | 1.17.x~1.34.x,推荐使用1.19.x及以上版本。 | 用于容器调度、管理(使用Docker部署则不需要) |
OS | openEuler release 22.03 (LTS-SP4) | 物理机操作系统(请使用昇腾官方兼容的OS) |
vCANN-RT | ubs-virt/ubs-virt-enpu/README.md · openEuler/ubs-virt - AtomGit | GitCode | 软切分相关组件,用于算力和显存资源控制 |
Volcano | 26.0.0 | 用于在Kubernetes集群场景下将容器调度到合适的计算节点(使用Docker部署则不需要) |
Ascend Device Plugin | 26.0.0 | 用于在Kubernetes集群场景下采集NPU资源信息,生成资源配置文件(使用Docker部署则不需要) |
Ascend Operator | 26.0.0 | 用于在Kubernetes集群场景下做任务下发(使用Docker部署则不需要) |
| ClusterD | 26.0.0 | 用于在Kubernetes集群场景下做NPU资源调度(使用Docker部署则不需要) |
2.2 使用约束
1、每个容器分配的资源总和不能超过单卡资源。
2、一个容器最多只能使用一个物理NPU。
3、NPU需开启共享模式。
4、仅支持普通容器,不支持特权容器。
5、由于vCANN-RT解决方案使用了共享内存,需确保是可信且被授权的用户使用。
6、单个物理NPU卡支持的最大容器数量为63个。
7、若用户自己编译软切分动态库,则需要保证宿主机上CANN的版本,跟镜像中CANN版本保持一致。
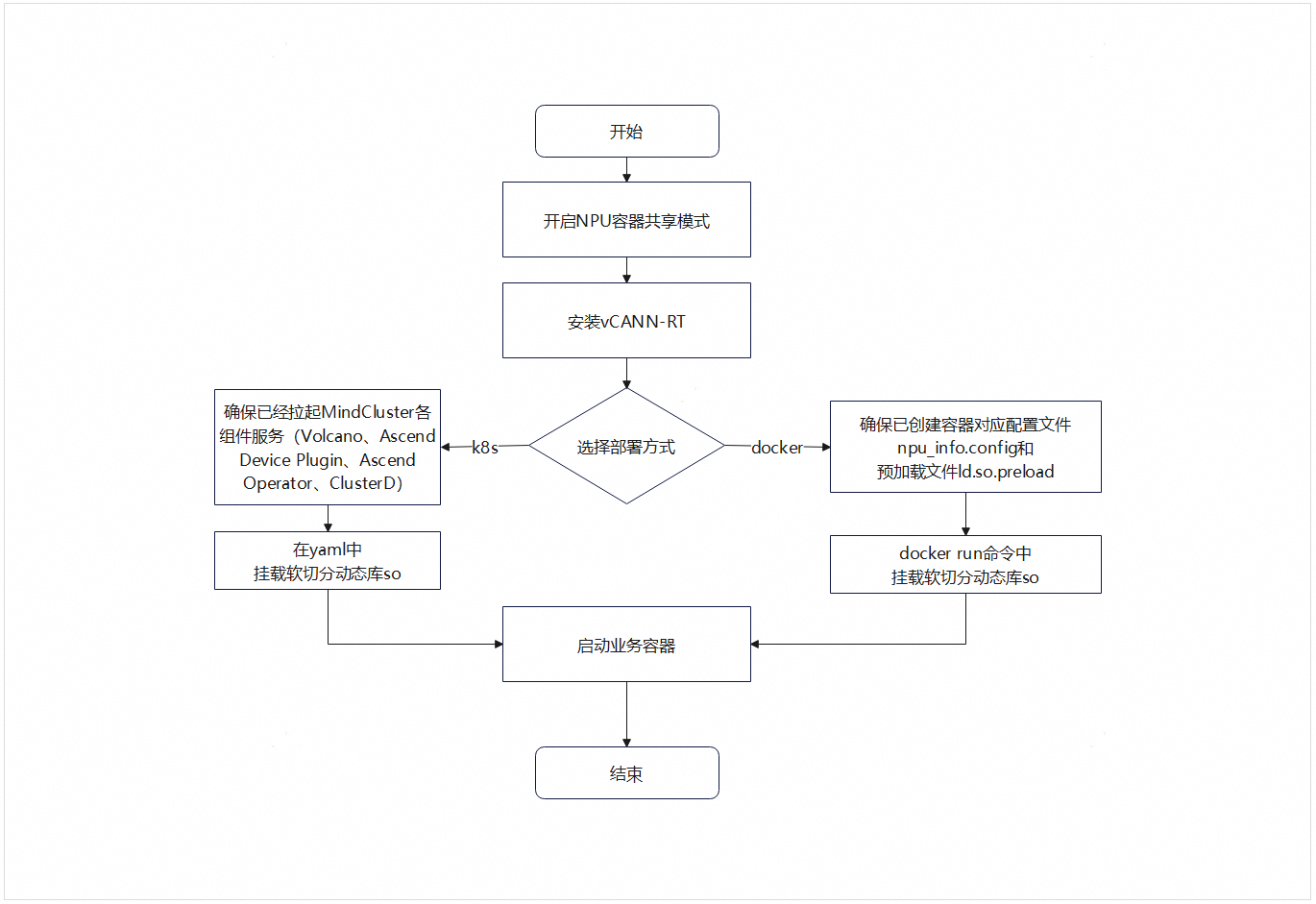
2.3 使用流程
本软切分方案使用流程图如下所示。
图1
2.3.1 准备工作
编译机:用于编译软切分库;请确保编译机与执行机的编译器版本、OS版本、系统内核保持一致,避免出现兼容性问题。
执行机:进行软切分业务的昇腾服务器。
2.3.1.1 编译机任务
请在编译机上完成以下操作:
1. 从vCANN-RT仓库拉取源码:
git clone https://gitcode.com/openeuler/ubs-virt.git2. 设置CANN环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh3. 执行编译脚本(若当前编译环境安装的CANN版本不是8.5.0,则不需要增加编译参数 “8.5.0” ):
cd ./ubs-virt/ubs-virt-enpu/vcann-rt/
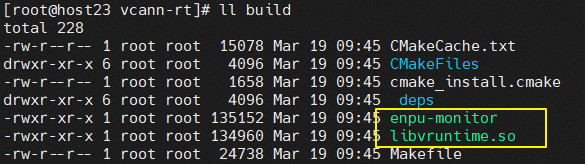
bash make_build.sh 8.5.04. 编译完成之后,会在build目录下面产生相应的编译产物
2.3.1.2 执行机任务
请在执行机上进行如下操作,安装软切分库:
1. 将编译产物拷贝到所有执行机的对应目录下。
cp libvruntime.so /opt/enpu/vcann-rt/lib/
cp enpu-monitor /opt/enpu/vcann-rt/tools/2.(k8s部署必选)创建preload文件,创建方法如下:
1)创建ld.so.preload文件。
vim ld.so.preload2)写入libvruntime.so的固定安装路径,用于后面K8s挂载vCANN-RT到容器。
/opt/enpu/vcann-rt/lib/libvruntime.so3.(可选)若编译时出现 libboundscheck 相关报错,需要先编译安装libboundscheck.so。
git clone https://gitcode.com/openeuler/libboundscheck.git
cd libboundscheck/
make CC=gcc
cp lib/libboundscheck.so /usr/lib64/libboundscheck仓库链接:libboundscheck
4. 对某张NPU卡使能软切分前,需要在执行机上开启容器共享模式,确保NPU卡上无进程占用后,执行以下命令完成开启:
#设置指定设备的所有芯片的容器共享模式
npu-smi set -t device-share -i ${id} -d ${value}
#设置指定设备的指定芯片的容器共享模式
npu-smi set -t device-share -i ${id} -c ${chip_id} -d ${value}
#查看对应设备当前容器共享状态
npu-smi info -t device-share -i ${id}若使用k8s部署,全部芯片必须开启容器共享模式:
for i in {0..7}; do npu-smi set -t device-share -i ${i} -d 1 ; done参数说明:
id | 设备id。通过npu-smi info -l 命令查出的NPU ID即为设备id。 |
chip_id | 芯片id。通过npu-smi info -m 命令查出的Chip ID即为芯片id。 |
value | 容器共享模式使能状态,默认禁用。 |
参考链接:ubs-virt/ubs-virt-enpu/README.md
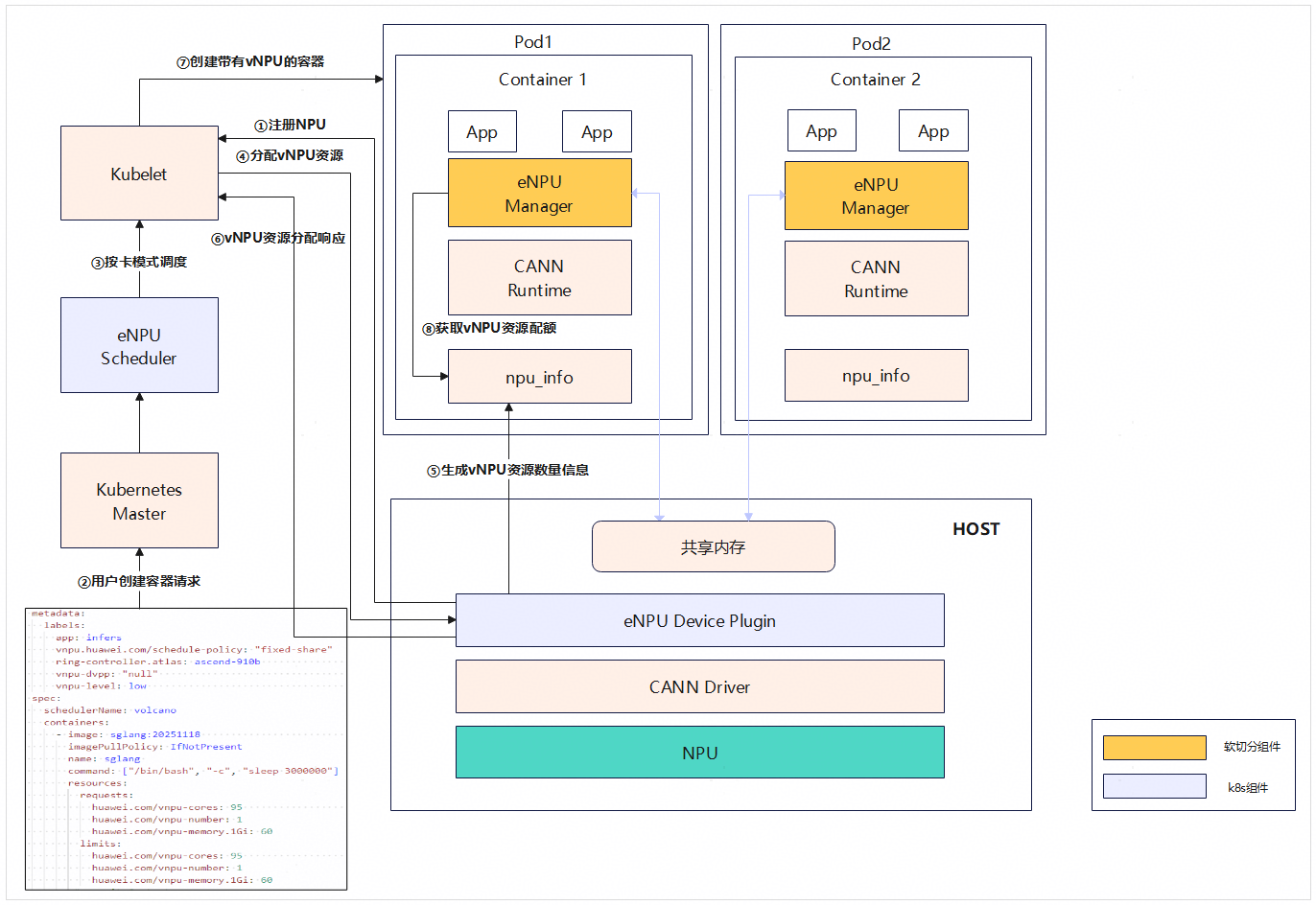
2.3.2 部署方式1:基于Kubernetes部署
Kubernetes软切分方案各组件调用流程图如下。
图1 调用流程图
2.3.2.1 前置条件
1、执行机已安装Kubernetes
2、执行机已安装Docker
3、执行机已按2.3.1章节完成准备工作。
2.3.2.2 安装MindCluster组件
1. 下载所需软件包:MindCluster 26.0.0
1)Ascend-docker-runtime_26.0.0_linux-aarch64.run
2)Ascend-mindxdl-device-plugin_26.0.0_linux-aarch64.zip
3)Ascend-mindxdl-volcano_26.0.0_linux-aarch64.zip
4)Ascend-mindxdl-ascend-operator_26.0.0_linux-aarch64.zip
5)Ascend-mindxdl-clusterd_26.0.0_linux-aarch64.zip
2. 安装部署:链接
1) 安装前准备:参考安装前准备,准备好各组件的镜像,以及安装所需的环境(节点标签、用户、日志目录、命名空间等)。
2) 给当前节点添加软切分所需标签:
kubectl label node ${host_name} huawei.com/scheduler.chip1softsharedev.enable=true --overwrite说明:
${host_name}可通过 kubectl get node -A命令查询;
之后可通过 kubectl get node --show-labels 命令查询标签是否添加成功。
3) 安装Ascend Docker Runtime:参考安装Ascend Docker Runtime。
4) 安装device-plugin:参考安装device-plugin,启动device-plugin组件服务。
注意:必须下边的device-plugin-volcano-v26.0.0.yaml文件来启动device-plugin组件。
apiVersion: v1
kind: ServiceAccount
metadata:
name: ascend-device-plugin-sa-910
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pods-node-ascend-device-plugin-role-910
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "update", "watch", "patch"]
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "patch"]
- apiGroups: [ "" ]
resources: [ "nodes/proxy" ]
verbs: [ "get" ]
- apiGroups: [""]
resources: ["nodes/status"]
verbs: ["get", "patch", "update"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "create", "update", "list", "watch"]
- apiGroups: [ "" ]
resources: [ "events" ]
verbs: [ "create" ]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pods-node-ascend-device-plugin-rolebinding-910
subjects:
- kind: ServiceAccount
name: ascend-device-plugin-sa-910
namespace: kube-system
roleRef:
kind: ClusterRole
name: pods-node-ascend-device-plugin-role-910
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: ascend-device-plugin-daemonset-910
namespace: kube-system
spec:
selector:
matchLabels:
name: ascend-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
##### For Kubernetes versions lower than 1.19, seccomp is used with annotations.
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ""
seccomp.security.alpha.kubernetes.io/pod: runtime/default
labels:
name: ascend-device-plugin-ds
spec:
##### For Kubernetes version 1.19 and above, seccomp is used with securityContext:seccompProfile
# securityContext:
# seccompProfile:
# type: RuntimeDefault
tolerations:
- key: CriticalAddonsOnly
operator: Exists
- key: huawei.com/Ascend910
operator: Exists
effect: NoSchedule
- key: "device-plugin"
operator: "Equal"
value: "v2"
effect: NoSchedule
priorityClassName: "system-node-critical"
nodeSelector:
accelerator: huawei-Ascend910
serviceAccountName: ascend-device-plugin-sa-910
containers:
- image: ascend-k8sdeviceplugin:v26.0.0
name: device-plugin-01
resources:
requests:
memory: 500Mi
cpu: 500m
limits:
memory: 500Mi
cpu: 500m
command: [ "/bin/bash", "-c", "--"]
args: [ "device-plugin -useAscendDocker=true -volcanoType=true -presetVirtualDevice=true
-logFile=/var/log/mindx-dl/devicePlugin/devicePlugin.log -logLevel=0 -shareDevCount=100 -softShareDevConfigDir=/share_device/" ]
securityContext:
privileged: true
readOnlyRootFilesystem: true
imagePullPolicy: Never
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
- name: vnpucfg
mountPath: /etc/vnpu.cfg
- name: vnpu-cut
mountPath: /run/vnpu_cfg_lock
- name: pod-resource
mountPath: /var/lib/kubelet/pod-resources
- name: hiai-driver
mountPath: /usr/local/Ascend/driver
readOnly: true
- name: log-path
mountPath: /var/log/mindx-dl/devicePlugin
- name: tmp
mountPath: /tmp
- name: reset-config-dir
mountPath: /user/restore/reset
- name: lingqu-log
mountPath: /var/log/lingqu
- name: data-trace-file-dir
mountPath: /user/cluster-info/datatrace-config
- name: dpu-config # dpu config for A5
mountPath: /user/mindx-dl/dpu
- name: localtime
mountPath: /etc/localtime
readOnly: true
- name: enpu-config-dir
mountPath: /etc/enpu/
- name: share-device-config-dir
mountPath: /share_device/
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: HOST_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
- name: pod-resource
hostPath:
path: /var/lib/kubelet/pod-resources
- name: hiai-driver
hostPath:
path: /usr/local/Ascend/driver
- name: log-path
hostPath:
path: /var/log/mindx-dl/devicePlugin
type: Directory
- name: reset-config-dir
hostPath:
path: /user/restore/reset
type: DirectoryOrCreate
- name: data-trace-file-dir
hostPath:
path: /user/cluster-info/datatrace-config
type: DirectoryOrCreate
- name: vnpu-cut
hostPath:
path: /run/vnpu_cfg_lock
type: DirectoryOrCreate
- name: tmp
hostPath:
path: /tmp
- name: vnpucfg
hostPath:
path: /etc/vnpu.cfg
type: File
- name: lingqu-log
hostPath:
path: /var/log/lingqu
type: DirectoryOrCreate
- name: dpu-config # dpu config for A5
hostPath:
path: /user/mindx-dl/dpu-config
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtime
- name: enpu-config-dir
hostPath:
path: /etc/enpu/
- name: share-device-config-dir
hostPath:
path: /share_device/
type: DirectoryOrCreate其中这三部分代码为该文件涉及修改处。
args: [ "device-plugin -useAscendDocker=true -volcanoType=true -presetVirtualDevice=true
-logFile=/var/log/mindx-dl/devicePlugin/devicePlugin.log -logLevel=0 -shareDevCount=100 -softShareDevConfigDir=/share_device/" ] - name: enpu-config-dir
mountPath: /etc/enpu/
- name: share-device-config-dir
mountPath: /share_device/ - name: enpu-config-dir
hostPath:
path: /etc/enpu/
- name: share-device-config-dir
hostPath:
path: /share_device/
type: DirectoryOrCreate5) 安装volcano:参考安装volcano,启动volcano组件服务。
6) 安装clusterd:参考 安装clusterd ,启动clusterd组件服务。
7) 安装ascend-operator:参考安装ascend-operator,启动ascend-operator组件服务。
警告:
建议严格按照 上述顺序来启动MindCluster组件,否则可能会导致k8s出现异常。
2.3.2.3 启动业务容器
1. 创建vnpu-base.yaml文件。yaml文件内容可从 README 处获取。
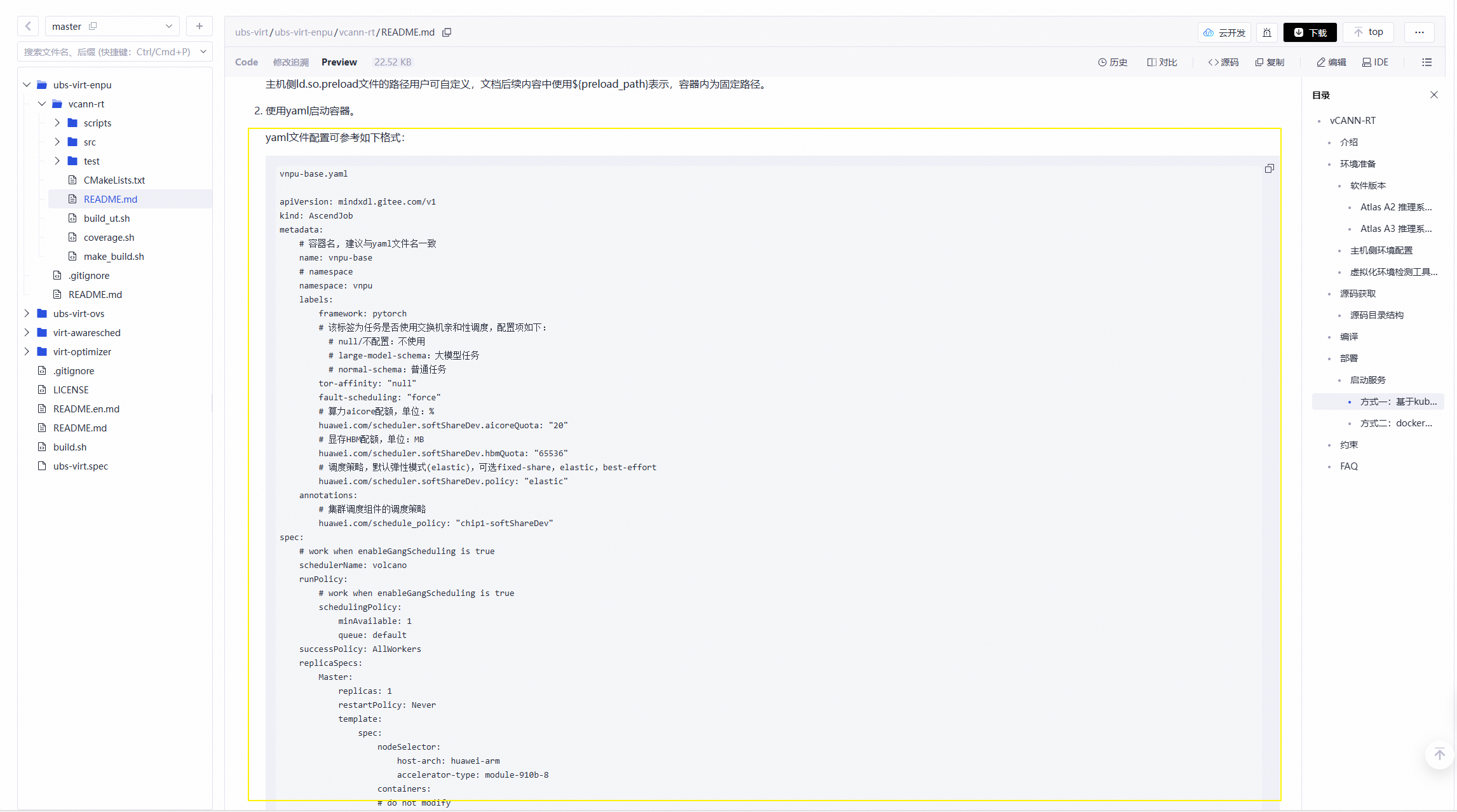
说明
可根据实际业务进行参数配置:
1)name: 容器名
2)namespace: 命名空间名称
3) huawei.com/scheduler.softShareDev.policy: 调度策略,默认为弹性模式。1:固定配额模式(fixed-share), 2: 弹性模式(elastic), 3: 争抢模式(best-effort)。
- 固定配额模式(fixed-shared mode):各容器按配比严格执行时间片。
a)若有暂未分配的NPU资源,则在最后一个容器分配到的时间片消耗完后,睡眠一段时间。此时NPU将闲置空转。
b)某容器无任务运行,仍会给定比例消耗完该分配的时间片。
- 弹性模式(elastic mode):由于固定配额模式可能出现NPU资源浪费,在弹性模式下,在各容器按配比执行时间片的基础上,优化了调度逻辑。
a)最后一个容器分配的时间片消耗完,马上将NPU使用权释放给下一个容器,跳过睡眠逻辑。
b)若某容器无任务运行,则直接跳过未消耗完的时间片,切换至另一个容器。
- 争抢模式(best-effort mode):容器之间自行争抢NPU资源,该模式的资源利用率最高,但无法保证容器的QoS。
4)huawei.com/scheduler.softShareDev.aicoreQuota:算力AI Core配额,取值必须为1~100之间的整数。单位:(%)(注意:单卡绑定的所有容器分配的资源之和不能超过单卡的总资源)
5)huawei.com/scheduler.softShareDev.hbmQuota:显存配额,取值必须为1的整数倍。单位:(GB)(注意:单卡绑定的所有容器分配的资源之和不能超过单卡的总资源)
6)image: 镜像名
7)resources.limits.huawei.com/Ascend910:与aicoreQuota保持一致
8)resources.requests.huawei.com/Ascend910:与aicoreQuota保持一致
注意:
a) 虚拟化环境检测工具准备:用户需要保证使用的镜像中/usr/bin目录内包含systemd-detect-virt命令行工具。
该工具用于检测系统的运行环境是否为虚拟化环境和虚拟化方式。若容器内未安装systemd-detect-virt工具,软切分动态库在调用dcmi接口时会出现故障。
b)
若在使用mindie镜像时出现如下报错:

请在vnpu-base.yaml中添加以下mindie相关挂载目录:
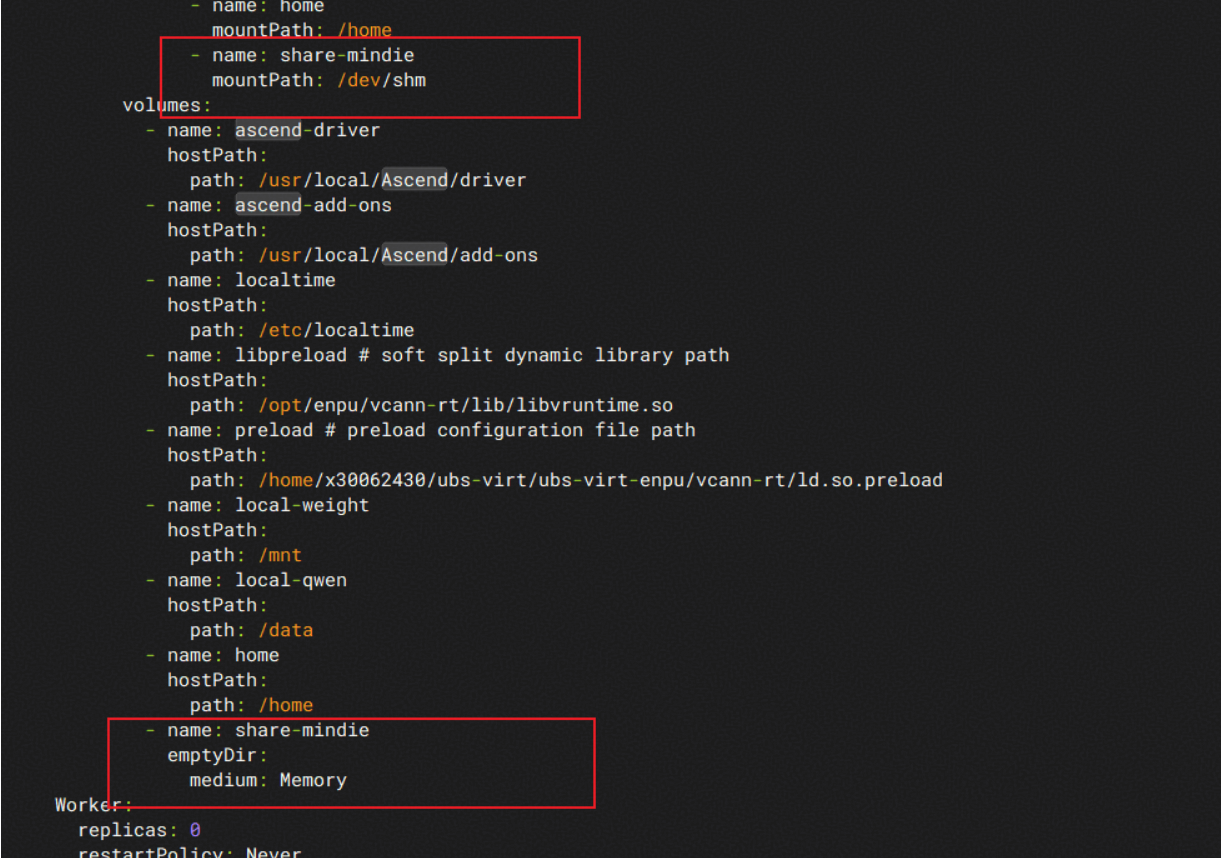
2. 根据上述yaml文件的metadata.namespace值,创建命名空间vnpu。
kubectl create namespace vnpu3. 启动容器。
kubectl apply -f vnpu-base.yaml4. 启动AI任务前,可通过环境变量配置日志级别:
export ENPU_LOG_LEVEL=1说明:
日志级别由高到低分别是FATAL(0), ERROR(1), WARN(2), INFO(3), DEBUG(4)。
默认日志级别为INFO。
为获得良好使用体验,避免使用过程中大量日志打屏,推荐先设为ERROR。
AI任务启动时,会自动拉起软切分算力控制和显存控制服务。回显内容“global init Success”,表示软切分相关服务启动成功。
5. k8s拉起容器后,进入容器运行AI任务。
# 查看容器
kubectl get pods -n ${namespace}6. 此外,在容器内可通过查询配置文件获取NPU资源配额等信息:
cat /etc/enpu/npu_info.config7. 在容器内可通过监测工具查询NPU资源配额和内存使用情况等信息:
/opt/enpu/vcann-rt/tools/enpu-monitor2.3.3 部署方式2:基于纯Docker部署
Docker软切分方案架构图如下所示:
图1 Docker软切分方案架构图
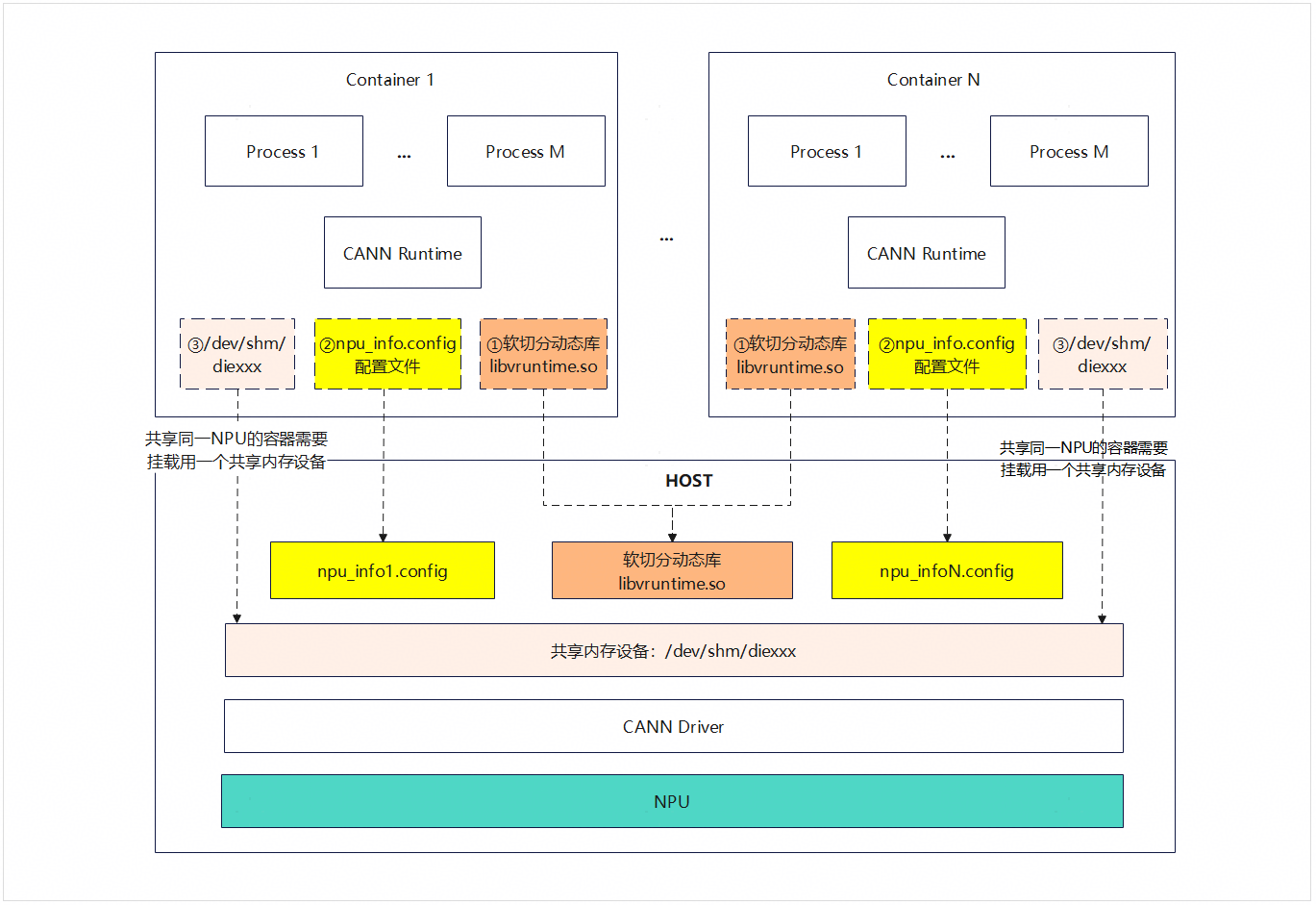
当不依赖k8s组件使用vCANN-RT时,需要用户在启动容器时自行挂载软切分相关动态库、文件和设备。例如软件分动态库、配置文件、共享内存设备和物理NPU设备。具体步骤见下文。
2.3.3.1 前置条件
1、执行机已安装Docker
2、执行机已安装软切分库
3、执行机已按2.3.1章节完成准备工作
2.3.3.2 创建npu_info配置文件
针对每个容器,在主机侧任意处创建一个配置文件npu_info.config,用于映射到容器中。
mkdir -p /data/vnpu1
vim /data/vnpu1/npu_info.config说明:
由于不同容器的配置内容不同,需确保每个容器的配置文件在主机侧独立存储并明确区分。
可通过文件名后缀或路径区分,例如:/data/vnpu1/npu_info.config,/data/vnpu2/npu_info.config
配置文件npu_info.config的格式和字段示例如下:
physical-npu-id=0
virtual-npu-id=0
aicore-quota=20memory-quota=1024
shm-id=7426Exx-xxxxxxx-xxxxxxx-xxxxxxx-x00301E3
scheduling-policy=1最后,设置文件为644权限:
chmod 644 ./npu_info.config注意:
当用户错误配置文件时,只有在容器业务拉起后才会报错。例如,若用户配置aicore-quota=120,算力资源配额已经超出100%。在拉起容器时不会报错,只有当容器内使用NPU的进程启动后,才会返回报错。此时,用户需要在宿主机上修改配置文件,并重新拉起容器。
说明:
1. physical-npu-id:物理NPU id。physical-npu-id=0 表示当前容器使用第0张物理NPU。
- 可通过执行ls /dev/davinci*命令获取芯片的物理id。/dev/davinci0,表示芯片的物理id为0。

2. virtual-npu-id:vNPU id。vNPU id需要从0开始配置。且同一个物理NPU下的vNPU id不允许重复,若多个容器配置相同的vNPU id,代表着这几个容器将抢占同一个时间片。virtual-npu-id=0 表示当前容器使用的是第1个NPU时间片。vNPU id取值范围为0-99。
3. aicore-quota:AI Core资源配额,单位为 %,表示算力使用时间比例。当前每个time slice默认为100ms,暂不支持动态配置。假设用户申请了20%的算力资源,那么该用户有20ms的NPU使用权。
4. memory-quota:显存资源配额,单位为 MB,表示显存资源使用容量。当前容器内所有进程使用的显存数量不能超过显存资源配额。
5. shm-id:共享内存文件名称。该文件名称采用物理NPU对应的VDie ID,每个物理NPU的VDie ID可保证全局唯一。
- 通过npu-smi info -t board -i ${id} -c ${chip_id}命令,查询VDie ID。每个NPU对应不同的id和chip_id。获取方式参考2.3.1.2节的 参数说明。
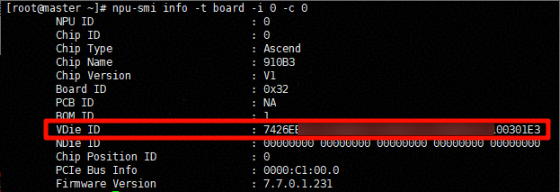
- 配置共享内存文件名称:查询到VDie ID后,使用"-"连接数字。例如,shm-id=7426Exx-xxxxxxx-xxxxxxx-xxxxxxx-x00301E3。

6. scheduling-policy:调度策略,推荐配置为2。1 表示 fixed-share mode,2 表示 elastic mode,3 表示 best-effort mode。三种模式的具体含义参考 2.3.1.5节 的说明。
2.3.3.3 启动业务容器
1 .创建docker容器,挂载相关路径。加粗部分为涉及修改处
docker run -it --name=container_name \
--device=/dev/davinci0:/dev/davinci0 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc:/dev/hisi_hdc \
-v /usr/local/sbin:/usr/local/sbin \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /dev/shm:/dev/shm \
-v /opt/enpu/vcann-rt/lib/libvruntime.so:/opt/enpu/vcann-rt/lib/libvruntime.so \
-v /opt/enpu/vcann-rt/tools/enpu-monitor:/opt/enpu/vcann-rt/tools/enpu-monitor \
-v ${config_path}/npu_info.config:/etc/enpu/vcann-rt/npu_info.config \
-v ${preload_path}/ld.so.preload:/etc/ld.so.preload \
image_name /bin/bash说明:
${config_path}: 主机侧npu_info配置文件所在路径,可存放在自定义路径。容器内为固定路径。
${preload_path}:主机侧预加载动态库文件所在路径,可存放在自定义路径。容器内为固定路径。
注意:
虚拟化环境检测工具准备:用户需要保证使用的镜像中/usr/bin目录内包含systemd-detect-virt命令行工具。
该工具用于检测系统的运行环境是否为虚拟化环境和虚拟化方式。若容器内未安装systemd-detect-virt工具,软切分动态库在调用dcmi接口时会出现故障。
2. 拉起容器后,进入容器运行AI任务。启动任务前,可通过环境变量配置日志级别,例如:
export ENPU_LOG_LEVEL=1说明:
日志级别由高到低分别是FATAL(0), ERROR(1), WARN(2), INFO(3), DEBUG(4)。
默认日志级别为INFO。
为获得良好使用体验,避免使用过程中大量日志打屏,推荐先设为ERROR(1)。
AI任务启动时,会自动拉起vCANN-RT算力控制和显存控制服务。回显内容“global init Success”,表示vCANN-RT服务启动成功。
3. 此外,在容器内可通过查询配置文件获取NPU资源配额等信息:
cat /etc/enpu/npu_info.config4. 在容器内可通过监测工具查询NPU资源配额和内存使用情况等信息:
/opt/enpu/vcann-rt/tools/enpu-monitor3 典型场景参考实践
当前的高校AI教学实训课程一个班有数十名学生同时上实验课,通过虚拟化软切分方案,只需一台4卡 Atlas 300I A2(64G)的服务器即可满足该实训要求。
以医疗命名实体识别实验这一典型实训场景为例,本章将围绕该场景下的典型实践,从场景介绍、部署方案及部署步骤三个部分展开,以说明切分和部署的设计思路和操作方法。通过采用软切分方案满足实训场景下的多模型同时训练的需求。该AI教学实训课程场景具备一定的通用性,也可为其他场景提供参考;用户可根据自身模型需求,对部署方案进行相应调整和验证。
3.1 场景介绍
医疗文本通常包含大量临床案例与医学知识,蕴含丰富的医学价值,但多以非结构化形式存在(即无固定格式、无统一字段的自然语言文本,如门诊病历、出院小结、医学文献等纯文字内容,无法被计算机直接识别、解析与利用)。为高效挖掘其中的医学知识,命名实体识别(NER)是从非结构化文本中提取疾病、症状、药物等关键医学实体的核心基础技术。
本实验基于医疗相关教科书和研究论文,利用已标注的医学语料,构建并训练 BiLstm+Crf 模型,实现对医疗命名实体的自动识别。
本实验所需文件获取方式如下:
表1 文件下载方式表
文件目录名称 | 下载地址 | 作用 |
|---|---|---|
dataset | wget https://staticfile.eduplus.net/dataSet/systemLib/5f9714775ecd4854bedea362f4dd4e0d.zip | 实验数据集 |
scripts | wget https://staticfile.eduplus.net/dataSet/systemLib/81c5f0240e4d48ffb9ad899b6a4913b0.zip | conlleval_rev.pl:该文件为perl语言脚本文件,其功能是对模型预测的实体结果与真实结果进行统计,并得到分类报告。 eval.py:该文件为调用conlleval_rev.pl脚本的代码。 const.py:该文件中保存的是本实验中涉及的所有实体标注标签类别字典,由于内容较多,所以预先给出。 |
best_checkpoints | wget https://staticfile.eduplus.net/dataSet/systemLib/33057dc817344334a00f2277d5ec8fa1.zip | 模型的预训练参数文件lstm_crf.pth和训练完的模型文件lstm_crf_model.pth。 |
checkpoints | 用户自行创建该文件夹 | 用于保存训练好的模型文件 |
result | 用户自行创建该文件夹 | 用于保存模型训练过程中的验证结果 |
data.py | 从【附录文件】获取 | 数据预处理脚本 |
data_loader.py | 从【附录文件】获取 | 数据加载脚本 |
model.py | 从【附录文件】获取 | BiLSTM+CRF模型文件 |
main.py | 从【附录文件】获取 | 模型训练脚本 |
predict.py | 从【附录文件】获取 | 推理脚本 |
3.2 部署方案
使用一张300I A2(64G)单卡,通过软切分控制每个容器分配到10%的AICORE资源和6GB的显存资源。
每名学生使用一个容器,完成BiLstm+Crf 模型的训练,最后使用模型实现对医疗实体的自动识别。达成单卡满足十名学生同时进行AI教学实训任务的目标。
3.3 部署步骤
3.3.1 部署方式1:Kubernetes部署
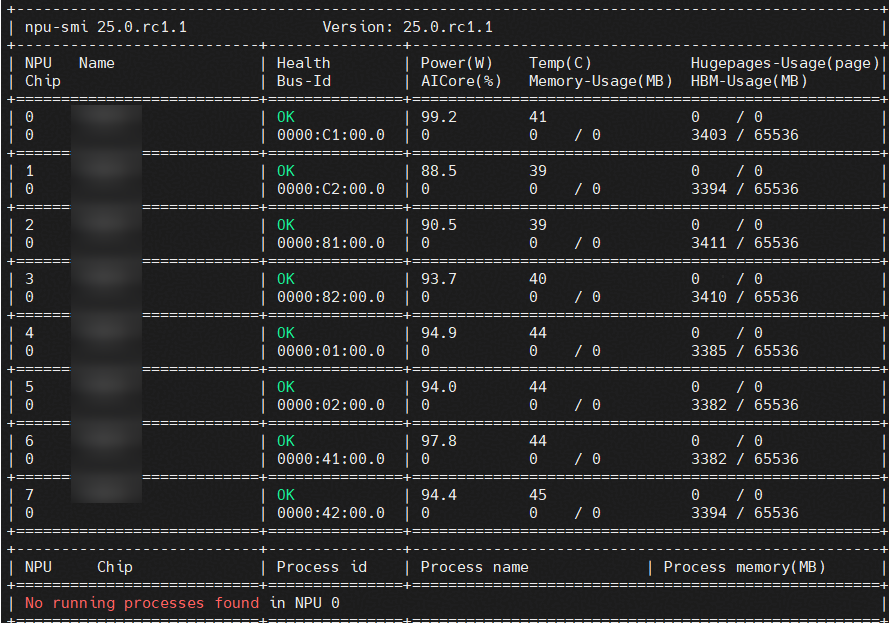
- 执行命令 npu-smi info 确认服务器上所有NPU卡空闲(如下图所示0号卡上无任何进程)。
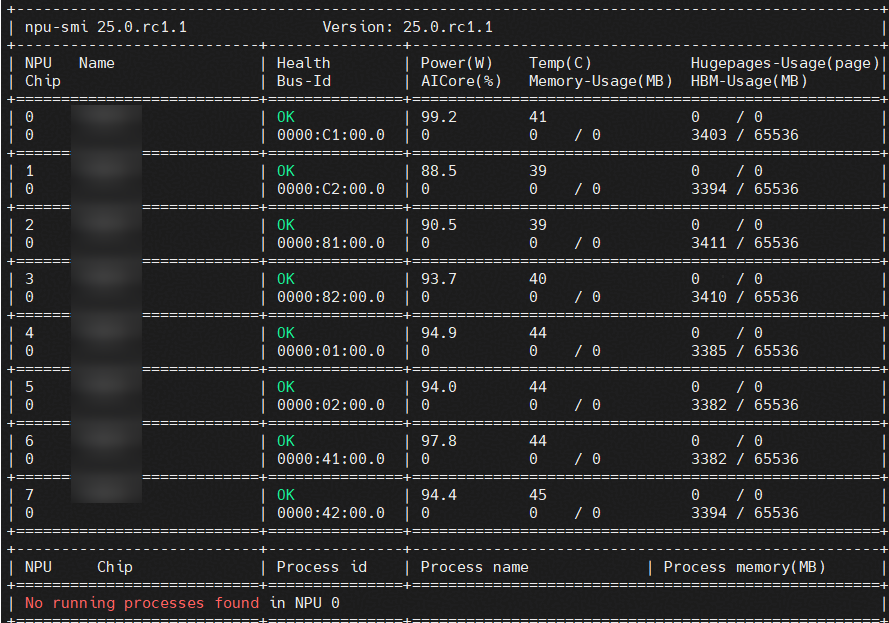
执行以下命令,开启所有NPU卡的容器共享模式。
for i in {0..7}; do npu-smi set -t device-share -i ${i} -d 1 ; done看到回显如下,代表开启成功。

2. 安装vCANN-RT:参考2.3.1节,完成vCANN-RT安装。
3. 参考2.3.2.2节,确保三个k8s组件完成安装。
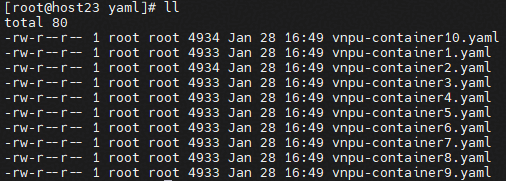
4. 在当前路径下创建yaml目录, 进入该目录并创建vnpu-container1.yaml 文件,该yaml文件内容可参考2.3.2.3节获取,并根据实际需求做相应修改。
5. 参考上述步骤,创建其余九个容器的yaml文件(vnpu-container1.yaml ~ vnpu-container10.yaml)。
6. 根据vnpu-container1.yaml 中 metadata.namespace 的值 ,执行 kubectl create namespace vnpu 创建命名空间。
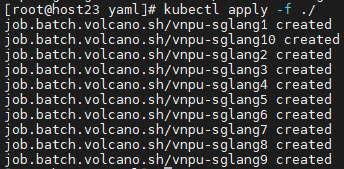
7. 执行命令 kubectl apply -f ./ ,拉起所有的pod。
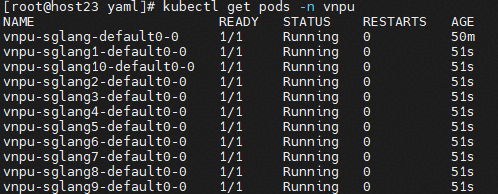
执行 kubectl get pods -n vnpu 查看到命名空间中创建的pod。
执行 kubectl exec -it vnpu-sglang1-default0-0 -n vnpu bash 进入容器。
在容器中执行 cat /etc/enpu/npu_info.config 查看npu_info.config的内容是否符合对应yaml的预设值。

执行 /opt/enpu/vcann-rt/tools/enpu-monitor 查询NPU资源配额和内存使用情况等信息。
8. 参考 3.1节中的文件下载方式表。下载所有实验文件到当前容器中同一目录下。
9. 在容器中执行训练脚本main.py,待训练完成后,可在checkpoints文件夹下得到训练好的模型文件lstm_crf_model.pth。注意调整合适的batchsize,保证训练最大显存占用始终不超过预设值6GB上限。若batchsize设置的过大,显存占用可能会超过预设值6GB上限,从而导致训练终止。
10. 修改推理脚本predict.py中的model_path为训练好的模型文件路径。
11. 执行推理脚本predict.py,完成推理。
3.3.2 部署方式2:Docker部署
- 执行命令 npu-smi info 查询空闲NPU卡(如下图所示0号卡上无任何进程),可对其进行切分。
2. 执行命令 npu-smi set -t device-share -i 0 -d 1 开启该设备的容器共享模式。看到回显如下,设置成功。

3. 参考2.3.1节,完成vCANN-RT安装。
4. 参考2.3.3.2节,准备好每个容器的配置文件npu_info.config。
5. 参考2.3.3.3节, 拉起并进入容器。
执行 cat /etc/enpu/npu_info.config 查看 npu_info.config 是否符合预设值。

执行 /opt/enpu/vcann-rt/tools/enpu-monitor 查询NPU资源配额和内存使用情况等信息。
6. 参考 3.1节中的文件下载方式表。下载所有实验文件到当前容器中同一目录下。
7. 在容器中执行训练脚本main.py,待训练完成后,可在checkpoints文件夹下得到训练好的模型文件lstm_crf_model.pth。注意调整合适的batchsize,保证训练最大显存占用始终不超过预设值6GB上限。若batchsize设置的过大,显存占用可能会超过预设值6GB上限,从而导致训练终止。
8. 修改推理脚本predict.py中的model_path为之前训练得到的模型文件路径。
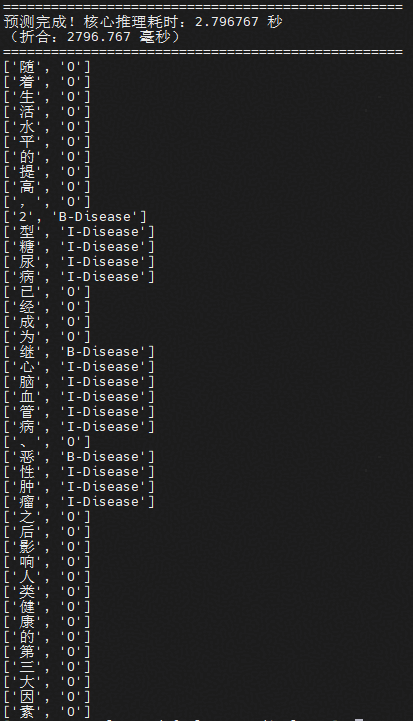
9. 在容器中执行推理脚本 predict.py,完成推理。
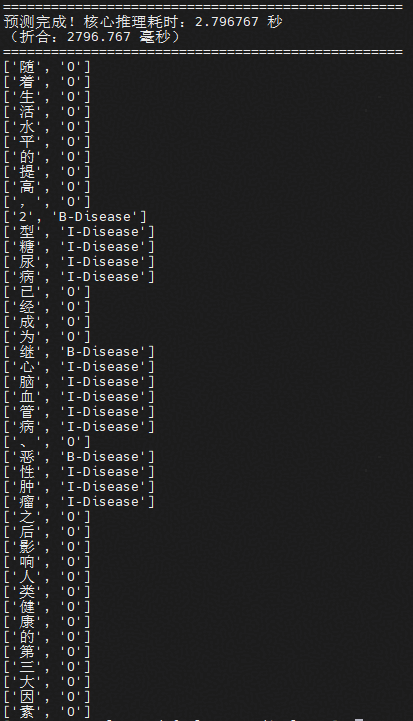
4 附录
4.1 data.py
import pickle, os
from scripts.const import *
def read_corpus(corpus_path, label_path, is_train=True):
sents = []#保存所有句子
labels = []#保存所有标签
data = []#保存所有数据
with open(corpus_path, encoding='utf-8') as fr:#打开文本数据文件
lines_co = fr.readlines()#读取所有行
with open(label_path) as fl:#打开标签文件
lines_lb = fl.readlines()#读取所有行
if not is_train:#如果不是训练,就加载已经创建好的词典文件
word2id = read_dictionary('./dataset/vocab.pkl')
else:#如果是训练,则需要重新创建词典文件
word2id = {}
for line_co, line_lb in zip(lines_co, lines_lb):
sent_,tag_ = line_co.strip().split(),line_lb.strip().split()#去空格
if len(sent_)==0:#句子长度为0 就不处理
continue
data.append((sent_, tag_))#原数据放入data
sentence_id,label_ = [],[]#保存词id构成的序列和标签id构成的序列
for word in sent_:
word = word.lower()
if word.isdigit():#判断是数字就转换成<NUM>
word = '<NUM>'
if is_train:
if word not in word2id:
word2id[word] = len(word2id)+1#加入词典
else:
if word not in word2id:#不在词典内就是未知词
word = '<UNK>'
sentence_id.append(word2id[word])#转换成id加入列表
for tag in tag_:
label = tag2label[tag]
label_.append(label)
sents.append(sentence_id)#保存到所有句子中
labels.append(label_)#保存到所有标签序列中
if is_train:
word2id['<UNK>'] = len(word2id)+1
word2id['<PAD>'] = PAD
print('vocabulary length:', len(word2id))
with open('./dataset/vocab.pkl', 'wb') as fw:
pickle.dump(word2id, fw)
return sents, labels, data
def read_dictionary(vocab_path):
vocab_path = os.path.join(vocab_path)#拼接路径
with open(vocab_path, 'rb') as fr:
word2id = pickle.load(fr)#加载词典
return word2id#返回词典
def get_vector(path):
with open(path,'r',encoding='utf-8') as f:
vectors={}#空字典 用来保存读取的词向量
for line in f.readlines():
line=line.strip().split(' ')#空格分隔
word,vector = line[0],line[1:]#第一个是字,后面的是向量的值
vector=[float(i) for i in vector]#将数值字符串转换成小数
if len(vector)==100:#长度为100才对
vectors[word]=vector#放入字典
return vectors#返回4.2 data_loader.py
import numpy as np
import torch
from scripts.const import *
# 先尝试导入torch_npu(与main.py保持一致,确保NPU环境可用)
try:
import torch_npu
except ImportError:
raise ImportError("未找到torch_npu依赖,请安装匹配版本的昇腾PyTorch适配包")
class DataLoader(object):
# 1. 修改初始化参数:cuda → npu,默认值适配main.py的NPU配置
def __init__(self, sents,labels, npu=True, batch_size=64, shuffle=False, evaluation=False):
self.npu = npu # 替换原self.cuda为self.npu,记录是否使用NPU
self.sents = sents
self.labels = labels
self.evaluation = evaluation
self._batch_size = batch_size
if not evaluation:
self._augment()#实现数据增强
self.sents,self.labels = np.asarray(self.sents),np.asarray(self.labels)
if not evaluation:
self._clean()#实现数据清理
self.sents_size = len(self.sents)
self._step = 0#用来记录迭代时的批次下标
self.num_batchs = self.sents_size // batch_size#计算批次数量
self.divided = True#记录是否整除
if self.sents_size % batch_size != 0:#不能整除
self.divided = False
self.num_batchs += 1#批次数量+1
if shuffle:
self._shuffle()#打乱数据
elif not evaluation:
self._sorted()#排序数据
def _augment(self):
# 前后两句拼接成一个句子(原有逻辑不变,无需修改)
self.sents = self.sents + [self.sents[i] + self.sents[i+1] for i in range(len(self.sents)-1)]
self.labels = self.labels + [self.labels[i] + self.labels[i + 1] for i in range(len(self.labels) - 1)]
def _clean(self):
# 删除标签全部是O的句子,就是没有实体的句子(原有逻辑不变,无需修改)
sums = [len(set(item))>1 for item in self.labels]#计算句子中非O的个数
indices = np.where(sums)[0]#筛选出非全O的句子(修正原注释表述误差)
self.sents = self.sents[indices]#布尔索引实现文本筛选
self.labels = self.labels[indices]#对应的标签也要去掉
def _shuffle(self):
# 打乱数据(原有逻辑不变,无需修改)
indices = np.random.permutation(self.sents_size)#获取乱序下标
self.sents = self.sents[indices]#文本数据重新索引
self.labels = self.labels[indices]#标签数据重新索引
def _sorted(self):
# 按句子长度排序(原有逻辑不变,无需修改)
lens = np.array([len(sent) for sent in self.sents])#计算句子长度
indices = np.argsort(lens)#排序
self.sents = self.sents[indices]#重新索引
self.labels = self.labels[indices]#重新索引
def __iter__(self):
return self
def __next__(self):
# 批次迭代逻辑(原有逻辑不变,无需修改)
if self._step == self.num_batchs:
self._step = 0
raise StopIteration()
_start = self._step * self._batch_size
if (self._step == self.num_batchs-1 and self.divided == False):
_sp = self.sents_size % self._batch_size
else:
_sp = self._batch_size
self._step += 1
if not self.evaluation:
indices = np.random.permutation(_sp)
else:
indices = np.arange(_sp)
word, seq_len_list = self._pad_to_longest(self.sents[_start:_start + _sp][indices])
label, _ = self._pad_to_longest(self.labels[_start:_start + _sp][indices])
return word, label, seq_len_list
def _pad_to_longest(self, insts):
# 2. 仅修改张量设备迁移逻辑:cuda() → npu(),适配NPU环境
seq_len_list = [len(inst) for inst in insts]
max_len = max(len(inst) for inst in insts)
inst_data = np.array(
[inst + [PAD] * (max_len - len(inst)) for inst in insts])
if self.evaluation:
with torch.no_grad():
inst_data_tensor = torch.from_numpy(inst_data)
else:
inst_data_tensor = torch.from_numpy(inst_data)
# 替换原CUDA设备迁移为NPU设备迁移,与self.npu参数联动
if self.npu:
inst_data_tensor = inst_data_tensor.npu() # 等价于inst_data_tensor.to('npu')
return inst_data_tensor, seq_len_list4.3 model.py
import torch
import torch.nn as nn
from torch.nn import init
import numpy as np
from scripts.const import *
# 补充:导入torch_npu(与其他文件保持一致,确保NPU环境完整性,避免导入异常)
try:
import torch_npu
except ImportError:
raise ImportError("未找到torch_npu依赖,请安装匹配版本的昇腾PyTorch适配包")
class CRF(nn.Module):
def __init__(self, label_size, device):
super().__init__()
self.label_size = label_size
self.device=device
self.transitions = nn.Parameter(
torch.randn(label_size, label_size)) # 定义转移矩阵
init.xavier_uniform_(self.transitions) # 初始化
self.transitions.data[START, :].fill_(-10000.) # 起始行全部设为-1000
self.transitions.data[:, STOP].fill_(-10000.) # 终止列全部设为-1000
def _log_sum_exp(self,input, keepdim=False):
assert input.dim() == 2
max_scores, _ = input.max(dim=-1, keepdim=True)# max_score维度是1
output = input - max_scores#减去最大值,目的是防止指数运算上溢
return max_scores + torch.log(torch.sum(torch.exp(output), dim=-1, keepdim=keepdim))
def _score_sentence(self, feats, tags):
score = torch.zeros(tags.shape[0]).to(self.device)
s_score = torch.LongTensor([[START]] * tags.shape[0]).to(self.device)#初始化分值
tags = torch.cat([s_score, tags], dim=-1)
for i in range(feats.shape[1]):#遍历每一个token
feat=feats[:,i,:]#获取当前token的发射概率
#加上转移概率和发射概率
score = score + self.transitions[tags[:,i + 1], tags[:,i]] + feat[range(feat.shape[0]),tags[:,i + 1]]
score = score + self.transitions[STOP, tags[:,-1]]
return score
def forward(self,input):
# 初始化路径分值
init_vvars = torch.full((1, self.label_size), -10000.).to(self.device)
init_vvars[0][START] = 0
forward_var_list = []
forward_var_list.append(torch.stack([init_vvars] * input.shape[0]).squeeze(1)) # 第一个时刻
for feat_index in range(input.shape[1]):
gamar_r_l = forward_var_list[feat_index].unsqueeze(1) # [128,1,33]
next_tag_var = gamar_r_l + self.transitions # 128,33,33 加上转移概率
t_r1_k = torch.unsqueeze(input[:, feat_index, :], -1) # 128,33,1 发射概率
forward_var_new = next_tag_var + t_r1_k # 128,33,33 加上发射概率
forward_var_list.append(torch.logsumexp(forward_var_new, dim=2))#求和
terminal_var = forward_var_list[-1] + self.transitions[STOP].repeat([input.shape[0], 1])
return torch.logsumexp(terminal_var, dim=1)
def _viterbi_decode(self, feats):
backpointers = []
#初始化路径分值
init_vvars = torch.full((1, self.label_size), -10000.).to(self.device)
init_vvars[0][START] = 0
forward_var_list = []
forward_var_list.append(torch.stack([init_vvars] * feats.shape[0]))#第一个时刻
for feat_index in range(feats.shape[1]):
gamar_r_l = forward_var_list[feat_index]#[128,1,33]
next_tag_var = gamar_r_l + self.transitions#128,33,33 加上转移概率
t_r1_k = torch.unsqueeze(feats[:,feat_index,:], -1)#128,33,1 发射概率
forward_var_new = next_tag_var + t_r1_k#128,33,33 加上发射概率
#取出当前时刻的最大分值状态集状态下标
viterbivars_t, bptrs_t = torch.max(forward_var_new, dim=-1) # 128,33 128,33
forward_var_list.append(viterbivars_t.unsqueeze(1))
backpointers.append(bptrs_t)
#转移到最后的stop
terminal_var = forward_var_list[-1] + self.transitions[STOP]
# 找到最大路径终止时刻tag下标
path_score,best_tag_id = torch.max(terminal_var.squeeze(1), dim=-1)
#回溯解码
best_tag_id=best_tag_id.unsqueeze(1)
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = torch.gather(bptrs_t,1,best_tag_id)#获取上一时刻路径状态
best_path.append(best_tag_id)
best_path.pop()#START不要
best_path.reverse()#逆转
return path_score, torch.cat(best_path, dim=-1)
class BiLSTM(nn.Module):
def __init__(self, word_ebd_dim, lstm_hsz, lstm_layers, dropout, batch_size,vec,word2id,device):
super().__init__()
self.lstm_layers = lstm_layers
self.lstm_hsz = lstm_hsz
self.batch_size = batch_size
self.word2id=word2id
self.word_size=len(word2id)
self.word_ebd_dim=word_ebd_dim
self.device=device
self.scope=1
self.vec=vec
if vec:#如果预训练字向量存在
vecs =self._get_vec()#获取字向量
self.word_ebd = nn.Embedding.from_pretrained(vecs)#使用预训练的字向量实例化嵌入层
else:
self.word_ebd = nn.Embedding(self.word_size, self.word_ebd_dim)#随机初始化嵌入层
self.word_ebd.weight.data.uniform_(self.scope, self.scope)
self.lstm = nn.LSTM(word_ebd_dim,
hidden_size=lstm_hsz // 2,
num_layers=lstm_layers,
batch_first=True,
dropout=dropout,
bidirectional=True)#实现BiLstm层
def _get_vec(self):
weight = torch.Tensor(self.word_size, self.word_ebd_dim).uniform_(-self.scope,self.scope)
for k,v in self.vec.items():
if k in self.word2id.keys():
index = self.word2id[k]#获取词对应的id
weight[index, :] = torch.from_numpy(np.array(v))#将该词对应的嵌入向量修改为预训练向量
return weight
def forward(self, words):
encode = self.word_ebd(words)#嵌入计算
# 初始化状态
hidden=self.init_hidden(words.shape[0])
output, hidden = self.lstm(encode,hidden)#sltm计算
return output, hidden
def init_hidden(self,batch_size):
return (torch.zeros(self.lstm_layers * 2, batch_size, self.lstm_hsz // 2).to(self.device),
torch.zeros(self.lstm_layers * 2, batch_size, self.lstm_hsz // 2).to(self.device))
class Model(nn.Module):
def __init__(self, args):
super().__init__()
for k, v in args.__dict__.items():#参数赋值
self.__setattr__(k, v)
self.bilstm = BiLSTM(self.word_ebd_dim,
self.lstm_hsz, self.lstm_layers,
self.dropout, self.batch_size,
self.pre_trained_vec,self.word2id,self.device
)# bilstm层
self.logistic = nn.Linear(self.lstm_hsz, self.label_size)#Linear层
self.crf = CRF(self.label_size, self.device)#crf层
torch.nn.init.xavier_normal_(self.logistic.weight)#初始化linear参数
self.logistic.bias.data.fill_(0)
def forward(self, words, labels, hidden=None):
output, _ = self.bilstm(words)# bilstm计算
output = self.logistic(output)# linear层计算
pre_score = self.crf.forward(output)#所有路径分值和
label_score = self.crf._score_sentence(output, labels)
return (pre_score - label_score).mean(), None
def predict(self, word):
lstm_out, _ = self.bilstm(word)
out = self.logistic(lstm_out)
return self.crf._viterbi_decode(out)4.4 main.py
import argparse # 补充缺失的argparse导入
import torch
import numpy as np # 可选:保留潜在需要的numpy支持
# 1. 导入并初始化NPU相关依赖(在torch之后导入,避免NameError)
try:
import torch_npu
torch.npu.init() # 初始化NPU环境,启用PyTorch对昇腾NPU的支持
except ImportError:
raise ImportError("未找到torch_npu依赖,请安装匹配版本的昇腾PyTorch适配包")
from model import Model
from data_loader import DataLoader
from data import read_corpus, tag2label, read_dictionary, get_vector
import os
from scripts.eval import conlleval
import time
parser = argparse.ArgumentParser(description='LSTM_CRF')
parser.add_argument('--epochs', type=int, default=100,
help='number of epochs for train')
parser.add_argument('--batch-size', type=int, default=64,
help='batch size for training')
parser.add_argument('--test-size', type=int, default=64,
help='batch size for testing')
parser.add_argument('--seed', type=int, default=1111,
help='random seed')
# 2. 适配NPU:将use-cuda改为use-npu,保持参数格式一致性(兼容data_loader)
parser.add_argument('--use-npu', action='store_true', default=True,
help='enables npu (replace use-cuda for ascend NPU)')
parser.add_argument('--lr', type=float, default=0.005,
help='learning rate')
parser.add_argument('--use-crf', action='store_true',
help='use crf')
parser.add_argument('--mode', type=str, default='train',
help='train mode or test mode')
parser.add_argument('--save', type=str, default='./checkpoints/lstm_crf.pth',
help='path to save the final parameters of model')
parser.add_argument('--save-model', type=str, default='./checkpoints/lstm_crf_model.pth',
help='path to save the final model')
parser.add_argument('--save-epoch', action='store_true',
help='save every epoch')
parser.add_argument('--data', type=str, default='dataset',
help='location of the data corpus')
parser.add_argument('--word-ebd-dim', type=int, default=100,
help='number of word embedding dimension')
parser.add_argument('--dropout', type=float, default=0.5,
help='the probability for dropout')
parser.add_argument('--lstm-hsz', type=int, default=256,
help='BiLSTM hidden size')
parser.add_argument('--lstm-layers', type=int, default=2,
help='biLSTM layer numbers')
parser.add_argument('--l2', type=float, default=0.002,
help='l2 regularization')
parser.add_argument('--clip', type=float, default=5,
help='gradient clipping')
parser.add_argument('--result_path', type=str, default='./result',
help='result-path')
parser.add_argument('--vocab-path', type=str, default='./dataset/vocab.pkl',
help='vocab-path')
parser.add_argument('--vec-path', type=str, default='./dataset/vec.txt',
help='vec-path')
args = parser.parse_args()
torch.manual_seed(args.seed)
# 3. 设备选择逻辑:从CUDA切换为NPU,保持参数逻辑一致性
args.device = torch.device("npu" if args.use_npu else "cpu")
# 补充:若需指定具体NPU卡号,可修改为 torch.device("npu:0" if args.use_npu else "cpu")
def train(epoch):
model.train()
total_loss = 0
for word, label, _ in train_data:
optimizer.zero_grad()
loss, _ = model(word, label)
loss.backward()
# 4. 适配NPU:梯度裁剪(torch原生接口,已被torch_npu兼容,保留原逻辑)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
optimizer.step()
print("epoch:{},step:{}/{},loss:{}".format(epoch, train_data._step, train_data.num_batchs, loss.item()))
total_loss += loss.detach()
return total_loss / train_data.num_batchs
def evaluate(epoch, current_test_data): # 新增参数:接收每个epoch全新的test_data,解决迭代器耗尽
model.eval()
eval_loss = 0
model_predict = []
label2tag = {}
for tag, lb in tag2label.items():
label2tag[lb] = tag if lb!=0 else lb
label_list = []
with torch.no_grad():
for word, label, seq_len_list in current_test_data:
loss, _ = model(word, label)
_,pred = model.predict(word) # 模型预测
for i, seq_len in enumerate(seq_len_list):
# 5. 适配NPU:NPU张量需先转CPU再转numpy(numpy不支持NPU张量,保留原逻辑)
pred_ = list(pred[i][:seq_len].cpu().numpy())
label_list.append(pred_)
eval_loss += loss.detach().item()
# 保持原逻辑:构建评估数据格式
for label_, (sent, tag) in zip(label_list, data_origin):
tag_ = [label2tag[label__] for label__ in label_]
sent_res = []
if len(label_) != len(sent):
print(sent)
print(len(label_))
print(tag)
for i in range(len(sent)):
sent_res.append([sent[i], tag[i], tag_[i]])
model_predict.append(sent_res)
# 确保结果目录存在(原逻辑补充,避免报错)
os.makedirs(args.result_path, exist_ok=True)
label_path = os.path.join(args.result_path, 'label_' + str(epoch))
metric_path = os.path.join(args.result_path, 'result_metric_' + str(epoch))
# 保持原逻辑:输出完整评估指标
for line in conlleval(model_predict, label_path, metric_path):
print(line)
return eval_loss / current_test_data.num_batchs
# 加载数据(保留原逻辑,不修改数据读取流程)
sents_train, labels_train,_ = read_corpus(os.path.join('.', args.data, 'train_data.txt'), os.path.join('.', args.data, 'train_label.txt'))
sents_test, labels_test, data_origin = read_corpus(os.path.join('.', args.data, 'test_data.txt'), os.path.join('.', args.data, 'test_label.txt'), is_train=False)
args.label_size = len(tag2label)
# 6. 适配NPU:将cuda参数改为npu(兼容data_loader.py的参数格式),初始化训练数据Loader
train_data = DataLoader(sents_train, labels_train, npu=args.use_npu, batch_size=args.batch_size)
# 加载预训练词向量和词典(保留原逻辑)
args.pre_trained_vec = get_vector(args.vec_path)
args.word2id = read_dictionary(args.vocab_path)
# 实例化模型并迁移至NPU设备(保留原逻辑,适配NPU设备)
model = Model(args)
model = model.to(args.device)
# 7. 适配NPU:加载模型参数,map_location指定为NPU设备,避免设备不匹配
if os.path.exists(args.save):
# 优化:避免重复加载模型参数(原代码重复调用torch.load,此处修正)
state_dict = torch.load(args.save, map_location=args.device)
model.load_state_dict(state_dict)
print(f"已成功加载预训练模型参数:{args.save}")
else:
print(f"未找到预训练模型参数:{args.save},将从头开始训练")
# 定义优化器(保留原逻辑,torch.optim原生接口已被torch_npu兼容)
optimizer = torch.optim.Adam(model.parameters(), lr=args.lr) # betas=(0.9, 0.98), eps=1e-9, weight_decay=args.l2)
train_loss = []
if args.mode == 'train':
print('-' * 90)
# 确保模型保存目录存在(原逻辑补充,避免报错)
os.makedirs(os.path.dirname(args.save), exist_ok=True)
for epoch in range(1, args.epochs + 1):
epoch_start_time = time.time()
loss = train(epoch) # 训练(保留原逻辑)
# 保留原格式输出:epoch开始信息、耗时、损失
print('| start of epoch {:3d} | time: {:2.2f}s | loss {:5.6f}'.format(epoch, time.time() - epoch_start_time, loss))
# 8. 关键修复:每个epoch重新初始化test_data(解决迭代器耗尽),兼容NPU参数
current_test_data = DataLoader(
sents_test,
labels_test,
npu=args.use_npu, # 适配data_loader的npu参数
evaluation=True,
batch_size=args.test_size
)
# 模型评估(传入全新的test_data,保留原逻辑)
eval_loss = evaluate(epoch, current_test_data)
# 保存模型参数和模型对象(保留原逻辑,适配NPU设备)
torch.save(model.state_dict(), args.save)
torch.save(model, args.save_model)4.5 predict.py
from data import tag2label, read_dictionary
import torch
import numpy as np
import time # 1. 导入time模块,用于时间统计
# 导入所有自定义类
from model import Model, BiLSTM, CRF
# 导入所有需要信任的PyTorch原生组件
from torch.nn import Embedding, LSTM, Linear
# 导入并初始化NPU相关依赖
try:
import torch_npu
torch.npu.init() # 初始化NPU环境
except ImportError:
raise ImportError("未找到torch_npu依赖,请安装匹配版本的昇腾PyTorch适配包")
# 模型与词典路径
model_path='checkpoints/lstm_crf_model.pth'#模型路径
vocab_path='dataset/vocab.pkl'#词典路径
# 加载词典并构建标签映射
word2id=read_dictionary(vocab_path)#加载词典
label2tag={v:k for k,v in tag2label.items()}#构建tag词典
# 待预测文本
text='随着生活水平的提高,2型糖尿病已经成为继心脑血管病、恶性肿瘤之后影响人类健康的第三大因素'
# 数据处理
raw_chars = [char for char in text.strip()] # 保留原始字符列表
processed_chars = ['<NUM>' if char.isdigit() else char for char in text.strip()]
words=[word2id[char] if char in word2id.keys() else word2id['<UNK>'] for char in processed_chars]
# 设备切换:NPU
device = torch.device('npu')
# 加载模型
with torch.serialization.safe_globals([Model, BiLSTM, CRF, Embedding, LSTM, Linear]):
model = torch.load(model_path, map_location='npu').to(device)
# 同步更新模型内部组件设备属性
model.crf.device = device
model.bilstm.device = device
# 准备模型输入张量
input_tensor = torch.from_numpy(np.array([words])).to(device)
# ========== 核心:预测耗时计算(关键步骤) ==========
# 2. 记录推理前的时间戳(可选:使用time.perf_counter(),精度更高)
start_time = time.time() # 简易统计,单位:秒
# start_time = time.perf_counter() # 高精度统计,适合短时间间隔(推荐)
# 模型预测(核心推理步骤)
_, pred = model.predict(input_tensor)
# 3. 记录推理后的时间戳
end_time = time.time()
# end_time = time.perf_counter()
# 4. 计算预测耗时(差值即为耗时)
predict_duration = end_time - start_time
# 结果处理:转换为[字符, 标签]的键值对形式
pred_labels = [label2tag[p] for p in pred[0].cpu().numpy()]
result_pairs = [[char, label] for char, label in zip(raw_chars, pred_labels)]
# ========== 打印耗时结果(格式化输出,更易读) ==========
print("="*50)
print(f"预测完成!核心推理耗时:{predict_duration:.6f} 秒")
print(f"(折合:{predict_duration * 1000:.3f} 毫秒)")
print("="*50)
# 按行打印键值对结果
for pair in result_pairs:
print(pair)
# ========== 可选:统计完整流程耗时(从程序启动到结果输出) ==========
# 若需统计完整流程,可在程序开头添加 `total_start = time.time()`,此处计算:
# total_end = time.time()
# total_duration = total_end - total_start
# print(f"完整流程(含加载、处理、推理、结果格式化)耗时:{total_duration:.6f} 秒")