



昇腾小模型服务化方案
发表于: 2026/03/03
编写目的
当前在各行各业中,小模型的应用越来越广泛;服务化是业务落地刚需,凭借其高效、低成本等优势,已成为数字化规模化落地的关键保障;在审核、智能检测、语音识别等场景应用广泛。小模型也常与大模型分工协同构建“专+全”场景化体系,已成为AI规模落地的主流路径。
小模型类别较多,业界没有统一的服务化产品。本文通过该指导文档帮助开发人员了解基于NPU实现小模型服务化方案及路线指导,重点介绍了Triton Server的服务化实现;也简单介绍了FastAPI/Flask、vLLM、vLLM-Omni等服务化方案;同时也提供了服务化实践案例及对应链接供参考学习;
小模型服务化方案总览
小模型服务化说明
小模型服务化是将参数规模通常在十亿级以下、专注特定任务的轻量化 AI 模型(如OCR、语音、文本嵌入、意图识别等推理模型),封装为标准化、可复用的微服务单元,通过 API 接口对外提供推理能力的部署与管理范式;目前主流的服务化产品有Triton Inference Server、FastAPI/Flask、vLLM、vLLM-Omni、FunASR、TEI等等;可根据模型类型与部署需求灵活选型。
服务化路线适合场景说明:
| 服务化框架 | 通用性 | 适合场景 |
|---|---|---|
| Triton Server | 强 | 面向规模化、高可用的生产级业务场景,支持多框架、多模型的统一部署与调度,能够承载高并发请求压力。需开发者自行实现完整推理链路,在模型集群管理、动态负载均衡等规模化运维能力上优势显著。 |
| Flask/FastAPI | 强 | 适配快速业务落地验证的轻量场景,可灵活实现端到端的完整推理逻辑,开发成本低、部署流程简洁。但原生不支持高并发请求处理,更适合小规模、低流量的原型验证或内部工具服务化。 |
| vLLM | 较强 | 聚焦LLM与多模态理解类模型的高性能推理场景,凭借高效KV缓存、PagedAttention等核心加速技术,可大幅提升模型吞吐率与响应速度。天然支持高并发请求,是模型推理服务化的优选方案 |
| vLLM-Omni | 较强 | 专门针对多模态生成类模型的加速推理需求,当前重点支持DIT(Diffusion Transformer)架构模型。继承vLLM的核心加速特性,可高效处理多模态生成任务的并发请求,为文生图、文生视频等场景提供高性能服务化支撑。是模型推理服务化的优选方案 |
| TEI | 一般 | 是文本嵌入(Embedding)类模型的专用推理服务框架,深度优化了向量生成的速度与资源利用率,支持高并发的嵌入计算请求。适用于检索增强生成(RAG)、语义检索等依赖大规模向量生成的业务场景。 |
| FunASR | 一般 | 面向语音类模型的全链路解决方案,覆盖语音识别、语音合成、语音理解等端到端语音任务。无需额外搭建复杂的语音处理链路,原生支持高并发请求,虽无显著的推理加速优化,但胜在功能完整、开箱即用,适配语音业务的快速规模化落地。 |
小模型服务化方案整体架构
小模型服务化方案整体架构设计如下:
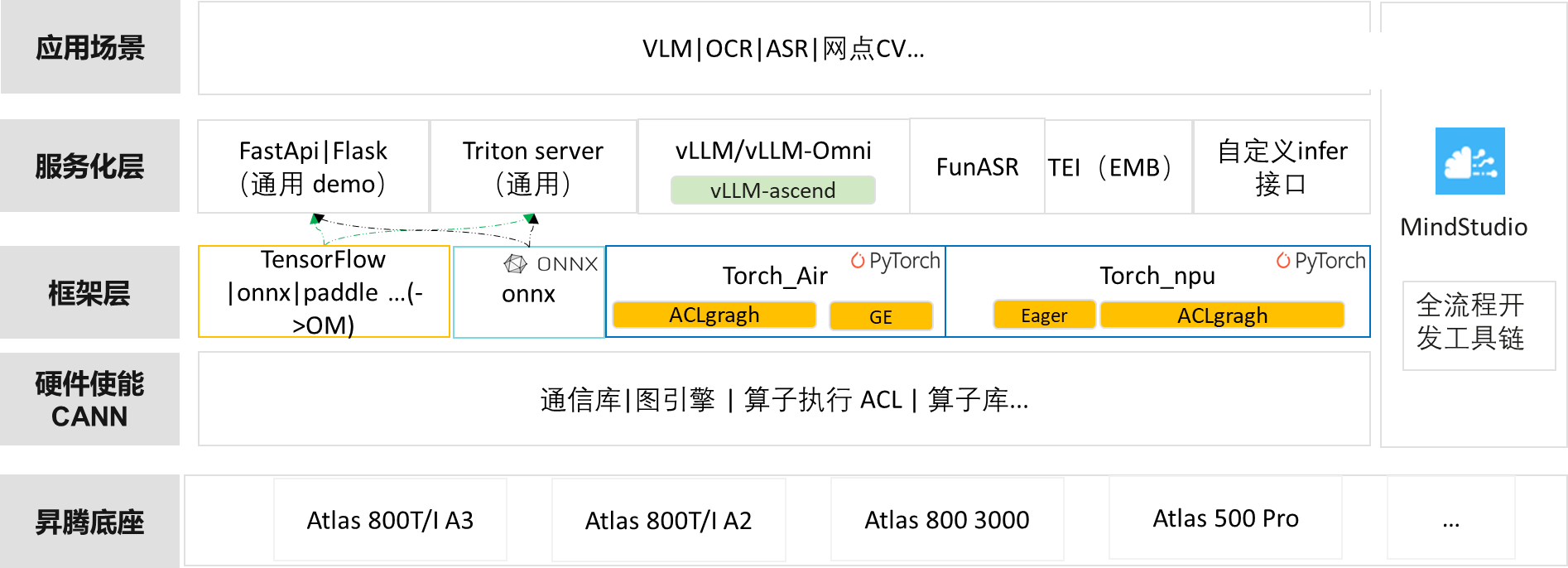
昇腾底座:主要包括昇腾主流服务器,比如Atlas A3 、A2系列;Atlas 800 推理服务器、Atlas 500 Pro 智能边缘服务器等等。
异构计算架构CANN(Compute Architecture for Neural Networks):是昇腾针对AI场景推出的异构计算架构,向上支持多种AI框架,包括MindSpore、PyTorch、TensorFlow等,向下服务AI处理器与编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台;
框架层说明:
非pytorch生态:tensorflow,MindSpore,paddle等导出ONNX中间格式,用ATC工具转成OM (图模式)文件进行推理;或者直接导出ONNX配合onnxruntime生态进行推理。
pytorch生态:支持单算子模式torch-npu 或者ACLgragh;torchair(图模式)后端;torchAir需要进行调优适配来获得极致性能,整体门槛较高。
MindStudio:提供开发全流程工具,包括迁移过程中的精度、性能调优等等;
服务化层说明:
主要有Triton Inference Server、FastAPI/Flask、vLLM、vLLM-Omni、FunASR、TEI等,根据业务场景可选择合适的框架;
① OM的服务化可支持FastApi|Flask、Triton server等通用方案;
② 当前ONNX的服务化推荐结合triton server的路线使用,备选FastApi|Flask;
③ Torch框架模型灵活性较好,除了支持FastApi|Flask、Triton server通用服务化外,也可以使用模型推荐的服务化接口,比如vLLM(for large language models)/ vLLM-Omni (for omni-modality model )、TEI、FunASR(语音类模型)、自定义的infer服务接口等等;
④ 对于vLLM支持的模型列表,服务化优选vLLM。需要注意的是:目前vLLM针对 Atlas 300I 系列推理卡还处于Experimental阶段;
⑤ TEI服务化是Embedding&Rerank模型专用的服务化接口;
⑥ 如果模型没有官方推荐的服务化接口,建议优先选择Triton server;如业务需要快速上线demo可优先选择FastApi|Flask;
备注:
vLLM-Omni扩展到了多模态和非自回归推理领域,主要针对Diffusion Transformer结构
推荐使用场景及特点:
| 服务化框架 | 特点 |
|---|---|
| Triton Server | 业务规模化部署可使用该服务化方式,具有标准化推理接口; 提供批处理能力; 需自定义API逻辑(如预处理 / 后处理)的场景; |
| Flask/FastAPI | 对于快速业务上线的局点可以使用该服务化方式; 需自定义API逻辑(如预处理 / 后处理)的场景; 批处理需手动实现; |
| vLLM | 优先使用该服务化方式,具有标准化推理接口; vLLM主要支持纯文本自回归生成的Transformer 架构的模型; 提供批处理、加速能力; |
| vLLM-Omni | 优先使用该服务化方式,具有标准化推理接口; vLLM-Omni支持全模态模型,但是目前只局限于DIT结构; 提供批处理、加速能力; |
| TEI | EMB类模型可使用该服务化方式,提供完整的服务化方案,开箱即用; 部分EMB类模型后续vLLM也会逐步支持; |
| FunASR | 语音类模型可使用该服务化方式,提供完整的服务化方案,开箱即用; 语音类模型后续vLLM-Omni也会逐步支持; 在NPU上部署时无加速特性,性能要求较高时,可尝试TorchAir; |
需要注意的是昇腾NPU基于Triton Server定义了GE backend https://gitcode.com/cann/triton-inference-server-ge-backend 。可实现模型通过onnx+ge_backend的方式进行服务化部署。
Triton Inference Server服务化方案
Triton Inference Server总览
简介
Triton Inference Server是 NVIDIA 开发的开源高性能推理服务框架,专为生产环境中的 AI 模型部署设计,作为一个服务化框架,客户端可以通过http/gRPC请求给triton server发送请求,triton server底层可以用tensorRT,pytorch,onnxruntime等不同的后端做具体的模型推理,并将推理后的结果返回给客户端。
官方GitHub仓: https://github.com/triton-inference-server
核心模块
triton server主要分为以下几个主要的模块
| 模块名 | 功能 |
|---|---|
| server | Triton服务主程序 |
| core | 核心组件,Triton核心逻辑和调度 |
| common | 公共工具和基础设施 |
| backend | 后端统一接口定义 |
| ***backend | onnxruntime_backend、tensorrt_backend等具体backend实现 |
核心流程
推理请求通过HTTP/REST、GRPC或C API到达服务器,然后被路由到相应的模型调度器。Triton Inference Server实现了多种调度和批处理算法,这些算法可以根据模型进行配置。每个模型的调度器可选择地对推理请求进行批处理,然后将请求传递给与模型类型对应的后端。后端使用批处理请求中提供的输入进行推理,以生成所需的输出,并将输出返回。
Backend详解
简介
backend是triton中的核心推理部件,是triton中用来进行具体的模型推理的模块,backend可以是由一些推理框架比如onnxruntime/tensorRT等封装得到,也可以按照backend要求的api格式自己写一个backend,每个backend对应一个.so动态库,库文件的名字必须遵循libtriton_<backend-name>.so的命名格式,在config.pbtxt配置文件中配置backend:"mybackend",则对应为libtriton_mybackend.so。
Backend机制
Triton Server启动时,会扫描默认后端目录下的子目录,每个子目录对应一个后端,通过目录名称和其中的配置文件确定后端信息,读取并解析 config.pbtxt 配置文件,选择对应的后端,通过dlopen接口动态加载后端动态库libtriton_<backend-name>.so,加载成功后,后端相关的代码与资源被映射到进程空间。Triton通过dlsym等机制获取后端动态库库必须实现暴露的一组标准接口函数,并保存到后端管理结构中,执行后续调用。
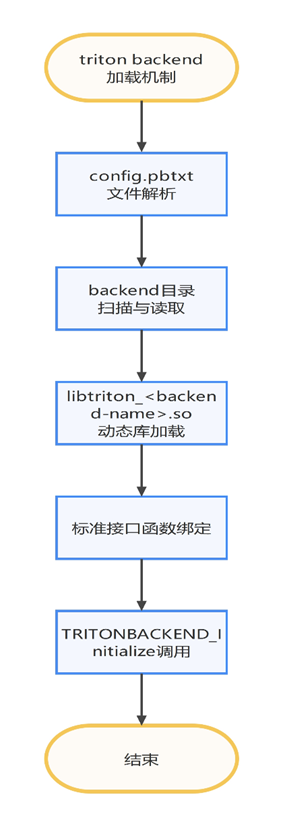
其中libtriton_<backend-name>.so动态库搜索路径,优先在模型版本路径搜索,依次会搜索:
<model_repository>/model/<version_directory>/libtriton_<backend-name>.so
<model_repository>/model/libtriton_<backend-name>.so
<global_backend_directory>/backends/libtriton_<backend-name>.soBackend选择推荐
triton server原生不支持NPU,但得益于服务化与推理后端的解耦,通过扩展推理后端,即可在NPU上运行triton server。本方案中,可选三种不同的backend,分别是Python backend、GE custom backend和ONNX-RUNTIME backend。
简要对比Python backend和GE custom backend,
1. triton service是基于C++开发,调用python性能无法达到性能最优
2. Python backend涉及适配model.py文件的三个接口,支持接入推理路线种类最多,有一定适配工作量,而GE backend只针对onnx格式,代码开发量较少
3. GE backend基于图进行深度优化,提供了图下沉、多流并行、锁核等方法;Python backend中,通常使用aisbench工具的Python api进行om模型的推理,且不支持异步推理
以下是基于NPU支持的Triton Inference Server方案架构图
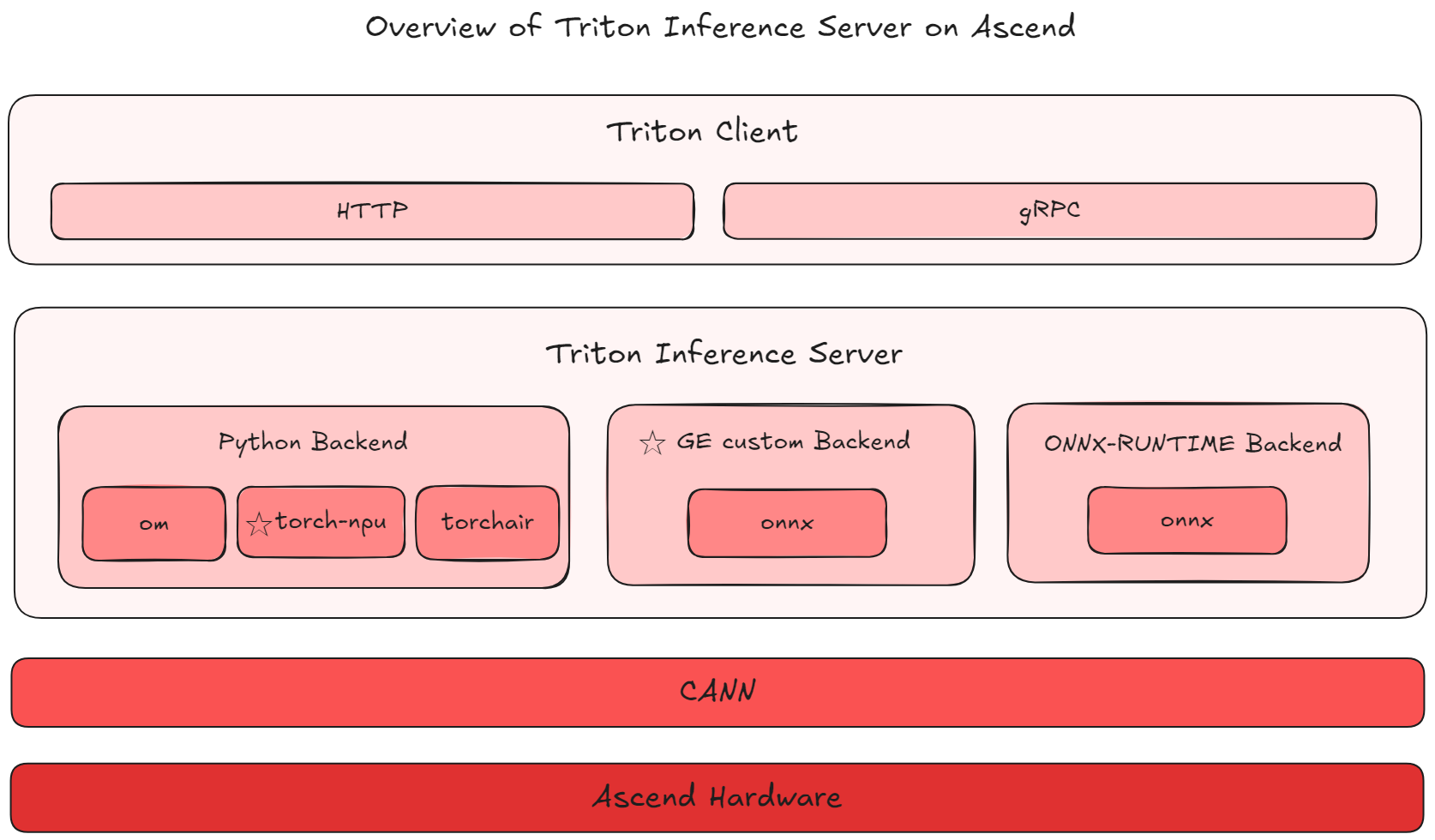
(1)ONNX
路线一:通过onnx+ge_backend的方式进行服务化
路线二:通过onnx+onnxruntime_backend的方式进行服务化
对于pytorch、paddle、tensorflow、mindspore等框架下的模型均可转换为onnx后接入使用该方案
(2)OM/torch
路线一:通过om +python backend的方式进行服务化
路线二:通过torch_npu +python backend的方式进行服务化
路线三:通过torchAir+python backend的方式进行服务化
Triton Inference Server特性
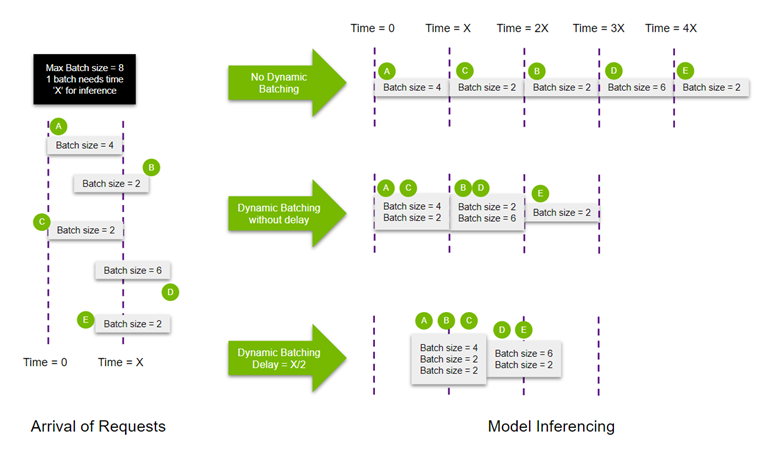
动态批处理
动态批处理 (Dynamic batching) 允许将一个或多个推理请求合并成一个batch,批量处理请求,提高资源利用率,提高吞吐,在config.pbtxt文件中添加下面即可开启该特性:
dynamic_batching {
max_batch_size: 32
max_queue_delay_microseconds: 10000
preferred_batch_size: [4, 8, 16]
}max_batch_size:最大的batch大小
preferred_batch_size:期望达到的batchsize大小,可以是一个数,也可以是一个数组
max_queue_delay_microseconds:单位是微秒,组batch的时间限制,超过该时间会停止组batch。
详情查看官方说明:
以下示例展示了不使能动态批处理、使能动态批处理、使能动态批处理并设置延迟三种场景下的差异
多实例
在模型服务化部署中,单实例推理容易成为性能瓶颈,尤其是在小模型高QPS或多NPU场景下。Triton通过 Instance Group 提供多实例部署能力:
多实例特性支持生成单模型的多个副本,允许并行处理,以提高资源利用率,提高模型吞吐,在config.pbtxt文件中添加下面即可开启该特性:
count: 每个设备上的实例数量
kind: 设备类型(GPU/CPU)
gpus: 指定GPU设备 ID(默认使用所有GPU)
instance_group [
{
count: 2
kind: KIND_CPU
}
]结合动态批处理和模型并行,以下示例展示了两个模型示例并行执行下,不使能动态批处理、使能动态批处理、使能动态批处理并设置延迟三种场景下的差异
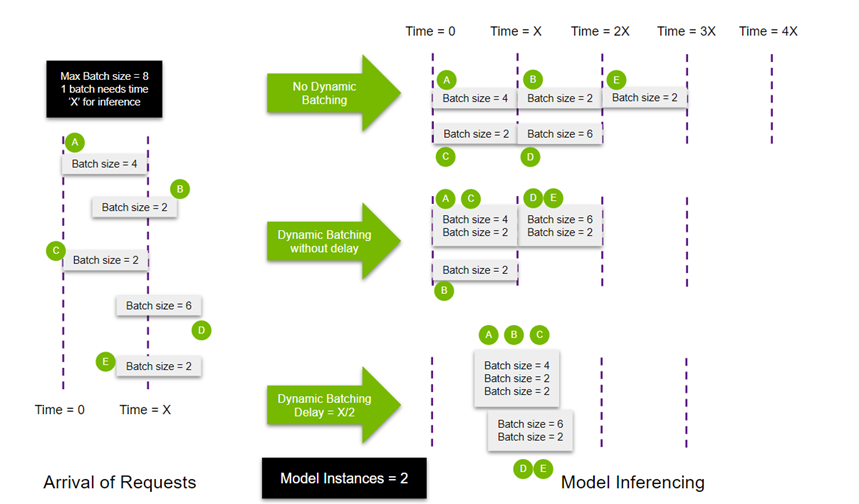
模型组合
可以将多个模型,如 预处理模型、中间模型、后处理串联组合,由Triton统一调用并且进行内部的数据流转控制,简化复杂的流水线部署(tokenizer -> encoder -> decoder)。
Python backend方案
环境说明
对于Python backend,在NPU上使用triton service的环境可以基于两种方式
1. 官方triton service镜像适配昇腾(推荐)
21.09版本之后自带Python Backend,镜像标签中以-py3 结束,基于已经安装编译triton service的官方镜像,安装昇腾底层软件栈CANN,torch_npu等组件
triton service官方镜像: https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags
2. 昇腾官方镜像编译triton service
基于昇腾基础CANN镜像,编译triton service仓库,该方式涉及的编译情况比较复杂
仓库整体结构
triton service规定了model_repository实现时的目录结构,以如下形式
<model-repository-path>/
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
<model-name>/
[config.pbtxt]
[<output-labels-file> ...]
<version>/
<model-definition-file>
<version>/
<model-definition-file>
...
...简单的例子
model_repository/
├── model1
│ ├── 1
│ │ └── model.py
│ └── config.pbtxt
└── model2
├── 1
│ └── model.py
└── config.pbtxtmodel_repository是模型仓库根目录,可以包含多个模型
model*表示一个模型,文件夹名即为模型名称
1 表示版本信息,一个模型可以有多个版本,triton service可以同时管理多个版本(官方规定,需要单纯的数字命名)
model.py是Python backend推理实现文件,放在对应的版本目录下
config.pbtxt是每个模型的配置文件
model.py结构
model.py是Python backend对应的核心推理文件,实现模型的初始化,推理,释放等流程,具体需要实现TritonPythonModel类,包含initialize、execute、finalize方法,execute是核心推理逻辑,用户可以最大程度的自定义推理方法,这也是Python backend灵活的原因
initialize(可选)
在模型首次加载到 Triton 后端进程时执行,用于完成一次性的初始化操作,例如权重加载、缓存结构构建、设备资源绑定等。通常这里完成所有需要在请求处理前准备好的工作。
execute(必选)
每次收到推理请求时由 Triton 调用,是模型的核心入口。在此方法中读取输入张量、执行前向计算、生成输出并返回响应。该方法必须实现,因为它直接承载模型的推理逻辑。
finalize(可选)
当模型实例从后台卸载或进程退出时调用,用于释放资源、关闭句柄、清理缓存等收尾任务。此阶段只执行一次,以确保不会遗留系统资源或内存泄露。
import triton_python_backend_utils as pb_utils
class TritonPythonModel:
def initialize(self, args):
"""
模型初始化逻辑(类似构造函数)
- args: dict,包含 model_repository 路径、model 名称、version 等信息
- 这里可以加载模型权重、初始化依赖库等
"""
pass
def execute(self, requests):
"""
推理核心函数
- requests: list,包含多个 inference request(可能是 batch)
- 必须返回 list of pb_utils.InferenceResponse
"""
responses = []
for request in requests:
# 获取输入张量
in_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT_NAME")
in_numpy = in_tensor.as_numpy()
# 模型计算逻辑(这里可以调用 PyTorch、TensorFlow、NumPy)
out_numpy = in_numpy + 1 # 示例逻辑
# 构造输出
out_tensor = pb_utils.Tensor("OUTPUT_NAME", out_numpy)
responses.append(pb_utils.InferenceResponse(output_tensors=[out_tensor]))
return responses
def finalize(self):
"""
资源清理逻辑(类似析构函数)
- 在模型卸载时调用
- 可以释放 GPU/CPU 资源,关闭文件句柄
"""
pass
config.pbtxt结构
config.pbtxt是一个protobuf格式的配置文件,定义了模型的名称、输入、输出等参数。
name: "model1" # 模型名称,必须与文件夹名一致
backend: "python" # 后端类型(Python 模型用 python)
max_batch_size: 8 # 最大 batch 大小(0 表示不支持 batching)
input [
{
name: "INPUT_NAME"
data_type: TYPE_FP32 # 输入数据类型 (FP32, INT64 等)
dims: [ -1, 224, 224, 3 ] # 输入维度,-1 表示动态维度
}
]
output [
{
name: "OUTPUT_NAME"
data_type: TYPE_FP32
dims: [ -1, 1000 ] # 输出维度
}
]推理方式
由于推理执行的解耦,triton service的Python backend下的推理方式即为NPU上模型推理的方式,总共分为三种,在线推理,即基于pytorch框架下的推理,直接基于torch_npu推理或者使用torchair成图,分别对应pytorch下的eager和图模式推理方式;离线推理,即基于OM的推理方式,可以使用aisbench提供的infer interface或直接基于pyacl api来写推理逻辑。
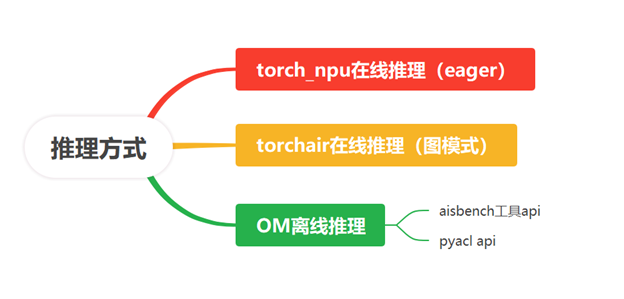
例如,对于yolo模型,我们使用两种推理方式接入Python backed:

GE Custom backend方案
自定义backend实现流程
Triton Inference Server提供了自定义backend的接入方式,对于NPU上使用,除了使用自带的Python backend,还可以使用自定义的NPU专属backend,此方案就是使用的GE图引擎,直接对onnx模型进行服务化。
开源仓链接: https://gitcode.com/cann/triton-inference-server-ge-backend
通过对TRITONBACKEND_Backend类的实现,我们就可以自动定义backend,具体需要实现8个接口函数:
| 接口 | 功能 |
|---|---|
| TRITONBACKEND_Initialize | backend初始化,资源分配、配置加载 |
| TRITONBACKEND_Finalize | backend收尾工作,资源释放、状态清理 |
| TRITONBACKEND_ModelInitialize | 解析并存储模型配置信息,如模型名称、输入输出shape、config.pbtxt 中的参数等 |
| TRITONBACKEND_ModelFinalize | 模型级别的收尾清理函数 |
| TRITONBACKEND_ModelInstanceInitialize | 模型实例初始化,解析实例的配置、初始化实例的运行环境 |
| TRITONBACKEND_ModelInstanceFinalize | 清理实例初始化时分配的资源 |
| TRITONBACKEND_ModelInstanceExecute | 真正执行模型推理的核心函数 |
| TRITONBACKEND_BackendControl (可选) | 封装后端的配置、资源管理、生命周期交互 |
其中,triton对于模型管理分为了层次抽象的四层六类:
ModelRepositoryManager负责扫描模型仓库目录,解析模型配置(config.pbtxt),识别模型版本,并触发模型加载流程;ModelLifeCycle是模型生命周期调度管理,负责模型的真正加载/卸载/更新;TritonModel类对应一个具体模型,管理该模型的所有推理实例TritonModelInstance,ModelState是与TritonModel紧密关联的状态管理类,一个TritonModel对象会对应一个唯一的ModelState,通过TRITONBACKEND_ModelSetState绑定在一起,后续后端的推理调用、资源分配、状态查询等操作,都由ModelState来承担;TritonModelInstance是实际执行推理的最小调度单元,拥有自己的线程上下文、device绑定、batch策略等,对应instance_group中设置的实例数;ModelInstanceState同样对应一个TritonModelInstance,掌控了单个推理实例的执行状态和资源细节,聚焦于实例级的运行时管理。
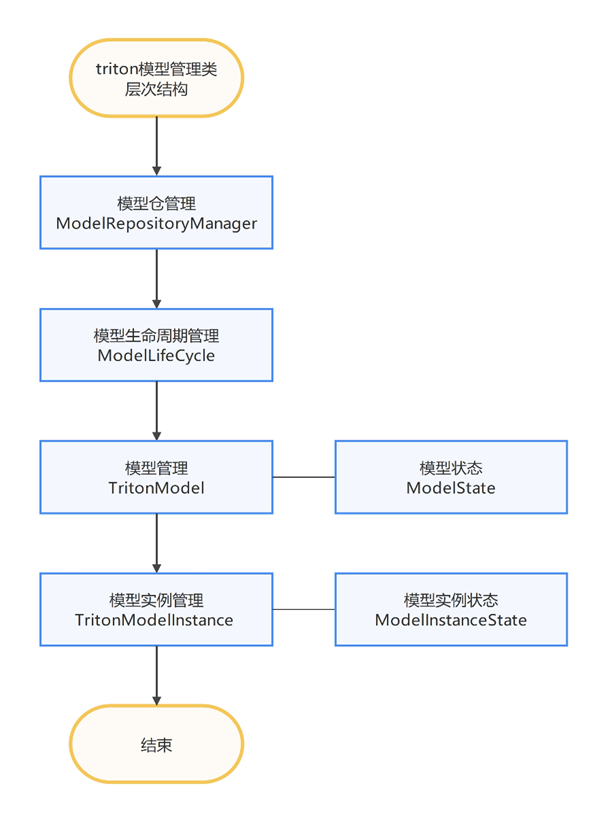
GE backend具体实现
ge_backend实现主要有以下几个文件:
npu_ge.cpp 对应Triton 的7个Custom backend规范接口;
model_state.cpp 完成 ModelState创建、以及均衡器Scheduler的初始化;
scheduler.cpp 实现了执行块的计算、分配过程;
model_instance_state.cpp实现了Instance的初始化以及推理接口。
通过cmake 编译后,会生成相应.so 动态链接库,即GE backend的动态库
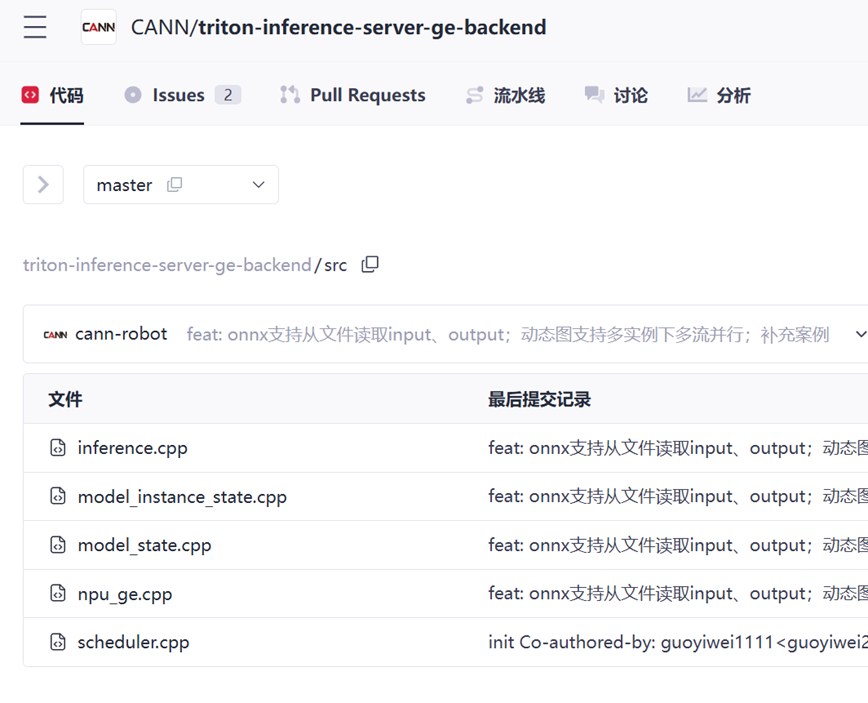
核心调用函数如下:
ONNX图解析,通过Parser接口将原始ONNX模型解析为图,可参考链接: https://www.hiascend.com/document/detail/zh/canncommercial/850/graph/graphdevg/atlasag_25_0024.html
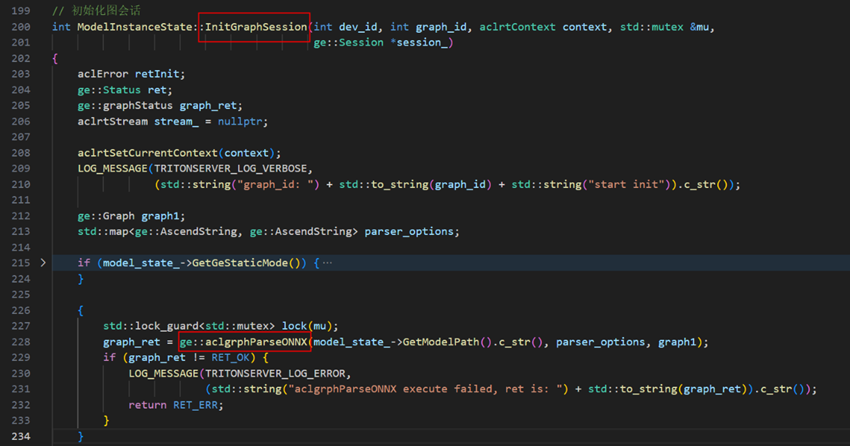
异步图执行,通过GE提供的图开发C++接口ExecuteGraphWithStreamAsync实现,可参考链接: https://www.hiascend.com/document/detail/zh/canncommercial/850/graph/graphdevg/atlasag_25_0035.html
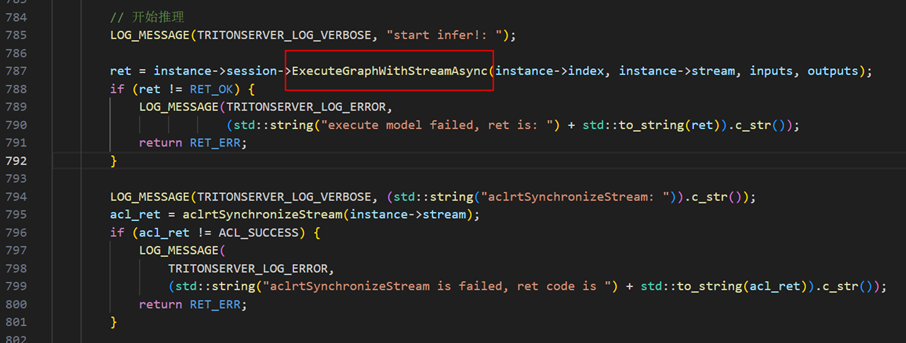
调用流程如下:
1.调用GEInitialize进行系统初始化(也可在Graph构建前调用),申请系统资源
2.调用Session构造函数创建Session类对象,申请Session资源
3.调用AddGraph在Session类对象中添加定义好的图
4.调用aclInit接口,初始化acl
5.调用CompileGraph完成图编译
6.调用aclrtSetDevice指定运行的Device,调用aclrtCreateStream创建Stream,然后调用aclrtMallocHost、aclrtMalloc分别申请Host和Device内存
7.调用LoadGraph(异步执行Graph场景),加载图模型到6创建的Stream上
8.调用ExecuteGraphWithStreamAsync异步执行接口,运行Graph
9.调用aclrtSynchronizeStream阻塞程序运行,直到指定Stream中的所有任务都完成
10.调用aclrtFree、aclrtFreeHost释放内存;调用GEFinalize,释放系统资源;调用aclFinalize释放acl相关资源

模型适配流程
模型接入GE backend的流程如下:
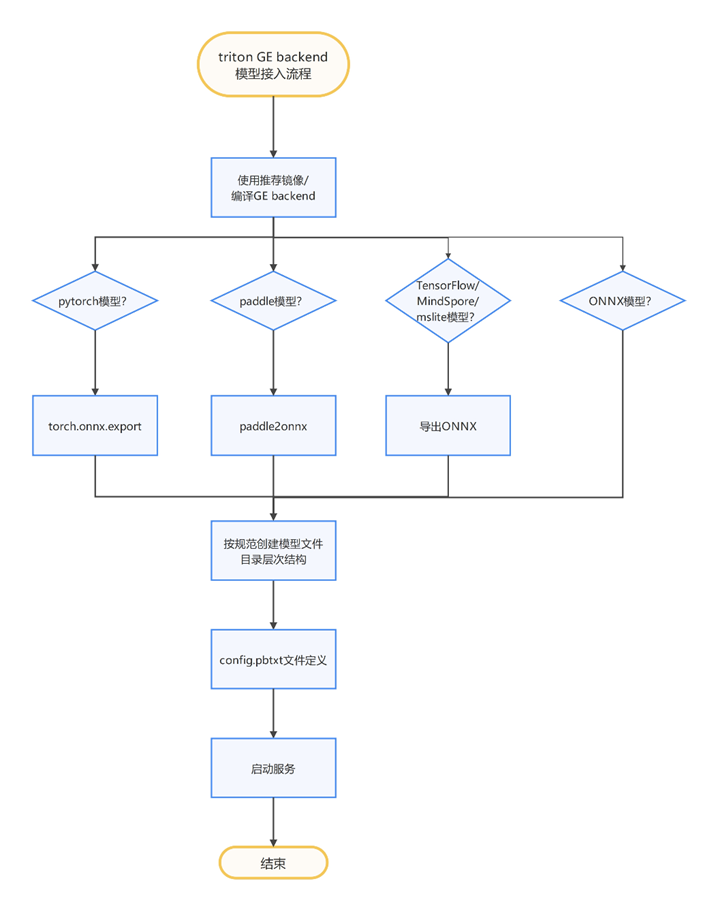
仓库目录结构如下:
models
└── cnclip
├── 1
│ └── model.onnx # 或 model.pb
└── config.pbtxt在config.pbtxt文件中,backend要填写我们自己的backend:npu_ge,并填写onnx对应的输入输出信息
name: "cnclip"
backend: "npu_ge"
max_batch_size: 128
input [
{
name: "image"
data_type: TYPE_FP32
dims: [3, 224, 224 ]
}
]
output [
{
name: "unnorm_image_features"
data_type: TYPE_FP32
dims: [512 ]
}
]
instance_group [{
count: 1
}
]
parameters: [
{
key: "device_ids",
value: {string_value: "2"}
}
]案例
Triton+Python backend+om部署案例
Triton Inference Server部署SenseVoice模型推理服务化指导
设备是Atlas 800I A2推理服务器,参考Sensevoice模型;基于已经安装编译triton service的NV官方镜像,triton inference service作为服务框架,使用python backend后端,aisbench+OM进行推理。
Triton+GE Backend+onnx部署案例
Triton Inference Server 部署Resnet模型推理服务化指导
triton inference service作为服务框架,使用GE backend+ONNX进行推理。
FastAPI服务化方案
使用ONNX/OM或者Torch框架模型均可使用FastAPI服务化(Flask实现方式与FastAPI类似,本文重点介绍FastAPI)。
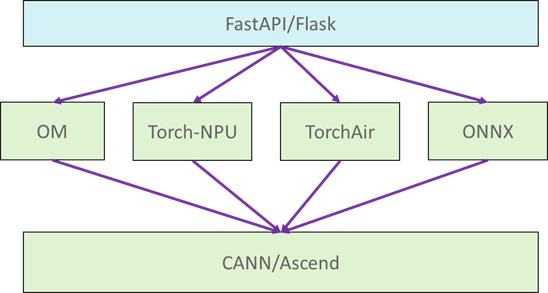
FastAPI/Flask整体实现相对简单,主要是通过使用装饰器(如 @app.get("/items/{item_id}"))将普通Python函数直接标记为API端点。框架自动处理HTTP协议细节(方法、路径、状态码),开发者只需关注核心业务逻辑。
FastAPI介绍
FastAPI 是一个用于构建 API 的现代、快速(高性能)的 web 框架,FastAPI主要具有以下特点:
高性能: 基于Starlette和Pydantic,利用异步(asynchronous)编程,提供出色的性能。
自动文档生成: 自动生成交互式API文档,支持Swagger UI和ReDoc,让API的理解和测试更加直观。
类型注解支持: 利用Python的类型提示,提供更严格的输入验证和更好的代码提示。
异步支持: 支持异步请求处理,使得处理IO密集型任务更加高效。
FastAPI 非常适合构建微服务、后端 API 以及任何需要高性能和快速开发的 Web 应用程序
FastAPI同时支持HTTP和WebSocket,两者各有特点:
HTTP:适合传统的请求-响应模式,无状态,易于扩展
WebSocket:适合实时双向通信,有状态连接,主动推送
FastAPI代码示例参考-cosyvioce
本案例以cosyvoice模型为例,通过fastapi服务化封装映射推理接口(如果模型支持多种推理接口,以此类推通过装饰器进行封装映射)。具体实现细节参考见链接: https://github.com/FunAudioLLM/CosyVoice/blob/main/runtime/python/fastapi/server.py
调用流程如下图所示。
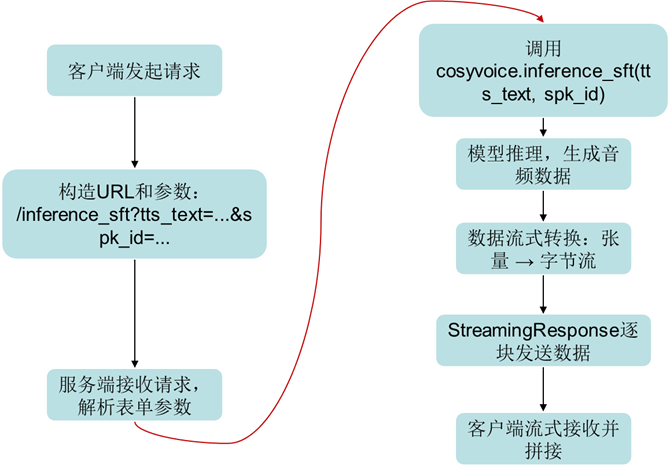
Server端inference执行接口
#映射推理接口参考
@app.get("/inference_sft")
@app.post("/inference_sft")
async def inference_sft(tts_text: str = Form(), spk_id: str = Form()):
model_output = cosyvoice.inference_sft(tts_text, spk_id)
return StreamingResponse(generate_data(model_output))
备注:
1)通过客户端访问url http://host:port/ inference_sft时,会重定向调用inference_sft函数接口;
2)访问时,由Client端传入TTS_TEXT及SPK_ID两个参数;
3)根据传入的参数进行推理返回结果vLLM服务化方案介绍
使用vLLM服务化,需要安装vLLM-Ascend插件(NPU后端插件用于适配vLLM)。
当前vLLM-Ascend支持Atlas 800I A2 inference、Atlas A2 training、Atlas A3 training、Atlas 800I A3 inference系列服务器;Atlas 300I inference 系列还在完善中(目前还在验证适配中)。
vllm-ascend支持torch_npu的eager及Aclgragh模式;也支持Torch_Air方式;目前主流使用torch_npu方式;
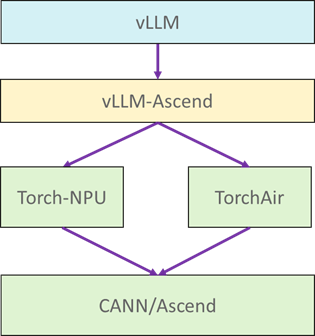
vLLM-Ascend插件是通过改写Executor、Worker、Runner等NPU Backend来实现vLLM对NPU的硬件扩展;
vLLM-Ascend支持的模型列表可在下面链接进行查询: https://docs.vllm.ai/projects/ascend/en/v0.13.0/user_guide/support_matrix/supported_models.html
vLLM介绍
vLLM是易用、高性能的开源全栈大语言模型(LLM)推理服务框架;是由加州大学伯克利分校开发的高效大语言模型推理框架,通过创新的PagedAttention技术优化注意力机制内存管理,显著提升模型吞吐量和内存利用率,尤其擅长处理长序列和批量推理任务。
同时vLLM兼容支持OpenAI REST API,并扩展了OpenAI不支持的beamsearch等差异化功能;广泛支持业界主流模型,同时支持快速集成自定义模型;广泛支持主流硬件,方便拥有不同硬件的用户使用。
更多信息查看vLLM官方链接:vLLM
Qwen3-Embedding + vLLM-Ascend +vLLM参考示例
本案例使用Qwen3-Embedding模型,安装部署细节可参照开源社区链接: https://docs.vllm.ai/projects/ascend/en/v0.13.0/tutorials/Qwen3_embedding.html
vLLM-Omni服务化方案介绍
vLLM-Omni服务化主要是针对多模态的模型(for omni-modality model), 昇腾NPU要使用该服务化同样需要安装vLLM-Ascend插件(NPU后端插件用于适配vLLM)。
趋势:后续生成语音、视频、图片类的模型服务化会逐步迁移到vLLM-Omni,实现归一。
注意:目前官方vLLM-Omni主要针对处理Diffusion Transformer结构的多模态,其他CNN、RNN等传统结构暂不支持。
vLLM-Omni支持的模型列表可在下面链接进行查询:
https://docs.vllm.ai/projects/vllm-omni/en/latest/models/supported_models/
vLLM-Omni介绍
vLLM-Omni 是最早一批支持 “omni-modality” 模型推理的开源框架之一,它把 vLLM 在文本推理上的性能优势,扩展到了多模态和非自回归推理领域。
vLLM-Omni 针对性解决了模型架构演进中的三大核心能力:
原生全模态支持:无缝处理并生成文本、图像、视频、音频等多模态数据,打破单一模态局限;
突破自回归边界:将 vLLM 高效的内存管理技术,拓展至Diffusion扩散模型等并行生成模型,覆盖更多模型类型;
异构模型流水线调度:支持单请求触发多异构模型组件的复杂工作流编排,例如多模态编码、自回归推理、扩散式多模态生成等场景。
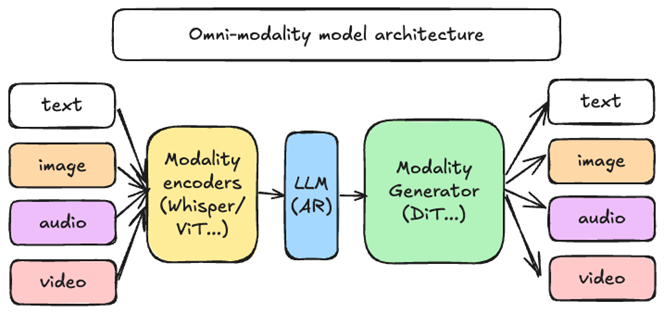
vLLM-Omni 不是在 vLLM 外面再包一层,而是从数据流(data flow)的角度重新拆解了整个推理路径。它引入了一个完全解耦的流水线架构,让不同阶段可以按需分配资源,并通过统一调度衔接起来。
Qwen2.5-Omni +vLLM-Ascend +vLLM+vLLM-Omni参考实现
本案例使用Qwen2.5-Omni模型,安装部署细节可参照开源社区链接: https://docs.vllm.ai/projects/ascend/en/latest/tutorials/models/Qwen2.5-Omni.html
FunASR服务化方案介绍
FunASR服务化支持WebSocket和 HTTP调用方式。官方支持Torch框架及ONNX格式模型。在项目实践中,昇腾NPU上建议使用Torch方式接入服务化。
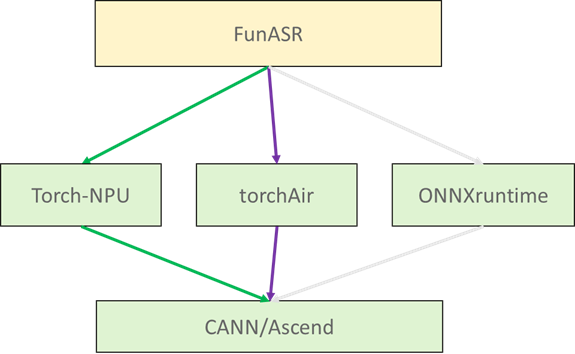
优先使用Torch_npu方式迁移,如果性能要求较高可尝试使用TorchAir;
备注:目前FunASR的开源库更新较慢,后续DIT结构的语音模型,可尝试使用vLLM-Omni服务化;
FunASR 官方支持的模型可查看链接: https://github.com/modelscope/FunASR/tree/main/funasr/models
注意:如果在昇腾上使用这些模型,需迁移适配至NPU。
FunASR介绍
FUNASR(Functional Universal Neural Architecture for Speech Recognition)是一个开源的端到端语音识别框架,由中国科学院自动化研究所(CASIA)的研究团队开发。该框架旨在提供一个高效、灵活、可扩展的语音识别解决方案。提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。

FunASR针对语音识别场景做了全链路封装、语音专属优化、开箱即用的能力集成。幅降低开发 / 部署成本。
FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。
语音模型+FunASR参考案例
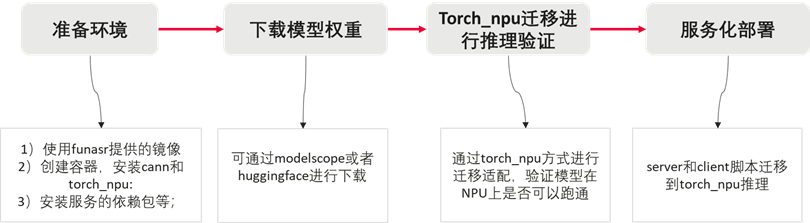
整体FunASR部署流程可参照官方文档: https://github.com/modelscope/FunASR/blob/main/runtime/quick_start.md 。
注意点:使用FunASR服务化前需要验证模型是否可以迁移到NPU上正常运行,可参考Torch_npu迁移指导;
本案例是通过websocket服务化方式,服务拉起前在funasr_wss_server.py和funasr_wss_client.py脚本添加如下代码,迁移到torch_npu上进行推理
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
print("Torch npu available: ", torch_npu.npu.is_available())
torch_npu.npu.set_compile_mode(jit_compile=False)
torch_npu.npu.set_device("npu:0")funasr_wss_server.py服务化拉起命令:
python3 funasr_wss_server.py \
> --asr_model "/home/w00463915/models/iic/para" \
> --asr_model_online "/home/w00463915/models/iic/para_online" \
> --vad_model "/home/w00463915/models/iic/vad" \
> --punc_model "/home/w00463915/models/iic/punc"出现如下提示即表示拉起成功:
/usr/local/lib/python3.8/site-packages/torch_npu/contrib/transfer_to_npu.py:301: ImportWarning:
*************************************************************************************************************
warnings.warn(msg, ImportWarning)
/usr/local/lib/python3.8/site-packages/torch_npu/contrib/transfer_to_npu.py:260: RuntimeWarning: torch.jit.script and torch.jit.script_method will be disabled by transfer_to_npu, which currently does not support them, if you need to enable them, please do not use transfer_to_npu.
warnings.warn(msg, RuntimeWarning)
Torch npu available: True
[W compiler_depend.ts:615] Warning: expandable_segments currently defaults to false. You can enable this feature by `export PYTORCH_NPU_ALLOC_CONF = expandable_segments:True`. (function operator())
model loading
model loaded! only support one client at the same time now!!!!funasr_wss_client.py客户端执行命令:
python funasr_wss_client.py --host "0.0.0.0" --port 10095 --mode offline --audio_in "/home/w00463915/data/asr_example.wav" --output_dir "./results"执行完会向服务端建立链接并返回结果,保存至当前results目录下:
warnings.warn(msg, ImportWarning)
/usr/local/lib/python3.8/site-packages/torch_npu/contrib/transfer_to_npu.py:260: RuntimeWarning: torch.jit.script and torch.jit.script_method will be disabled by transfer_to_npu, which currently does not support them, if you need to enable them, please do not use transfer_to_npu.
warnings.warn(msg, RuntimeWarning)
Torch npu available: True
[W compiler_depend.ts:615] Warning: expandable_segments currently defaults to false. You can enable this feature by `export PYTORCH_NPU_ALLOC_CONF = expandable_segments:True`. (function operator())
Namespace(audio_fs=16000, audio_in='/home/w00463915/data/asr_example.wav', chunk_interval=10, chunk_size=[5, 10, 5], decoder_chunk_look_back=0, encoder_chunk_look_back=4, host='0.0.0.0', hotword='', mode='offline', output_dir='./results', port=10095, send_without_sleep=True, ssl=1, thread_num=1, use_itn=1, words_max_print=10000)
connect to wss://0.0.0.0:10095
pid0_0: demo: 欢迎大家来到么哒社区进行体验
Exception: sent 1000 (OK); then received 1000 (OK)运行期间可以通过npu-smi info可以看到server的进程:

TEI服务化方案介绍
TEI是专门针对EMB模型的服务化框架,当前适配TEI主要有两条路线:Torch_npu、ATB;部分bge模型通过ATB进行加速优化,其他模型通过Torch_npu(Eager)模式。
昇腾基于TEI 仓库适配的镜像已验证的模型:
| 模型名 | 说明 | 是否支持加速 |
|---|---|---|
| BAAI/bge-large-zh-v1.5 | 稠密向量模型 | 是 |
| BAAI/bge-m3 | 稠密和稀疏向量模型 | 是 |
| aspire/acge_text_embedding | 稠密向量模型 | 是 |
| BAAI/bge-reranker-large | 排序模型 | 是 |
| BAAI/bge-reranker-v2-m3 | 排序模型 | 是 |
| jinaai/jina-embeddings-v2-base-zh | 稠密向量模型 | 是 |
| Alibaba-NLP/gte-Qwen2-1.5B-instruct | 稠密向量模型 | 否 |
| Alibaba-NLP/gte-Qwen2-7B-instruct | 稠密向量模型 | 否 |
| Qwen/Qwen3-Embedding-0.6B | 稠密向量模型 | 否 |
| Qwen/Qwen3-Reranker-0.6B | 排序模型 | 否 |
| microsoft/unixcoder-base | 稠密向量模型 | 否 |
其他支持sentence-transformer拉起模型通常都支持运行,涉及模型多,未逐一测试。
TEI介绍
TEI 是 Hugging Face 推出的专为文本嵌入(Text Embeddings)模型设计的高性能推理服务框架,核心定位是解决嵌入模型部署中的 “低延迟、高吞吐量、易用性” 问题,支持主流嵌入模型(如 BERT、Sentence-BERT、E5、BGE 等)的快速服务化部署,广泛应用于检索增强生成(RAG)、语义搜索、文本聚类等场景。
TEI支持的官方模型列表可查看链接: https://github.com/huggingface/text-embeddings-inference
Torch+TEI参考案例
昇腾提供了基于 TEI 仓库适配昇腾显卡的镜像mis-tei下载、测试步骤、验证支持的模型可参考官方链接: https://www.hiascend.com/developer/ascendhub/detail/07a016975cc341f3a5ae131f2b52399d
该镜像基于text embedding inference 适配昇腾NPU卡提供embedding、reranker等服务化接口,接口兼容开源text embedding inference, 该镜像支持embedding和reranker、Sequence Classification等模型,该镜像默认以普通用户HwHiAiUser用户运行FAQ