



昇腾小模型迁移方案(part2/2)
发表于: 2026/02/28
模型推理及应用
ais_bench推理工具使用指南
通过ais-bench工具验证om模型是否可以正常推理;用来针对指定的推理模型运行推理程序,并能够测试推理模型的性能(包括吞吐率、时延);
ais_bench推理工具的使用方法主要分为命令行使用和API调用;
ais-bench工具接口开放:
ais_bench推理工具inferface推理Python接口。接口文档见 https://gitee.com/ascend/tools/blob/master/ais-bench_workload/tool/ais_bench/API_GUIDE.md
aclruntime API。接口文档见 https://gitee.com/ascend/tools/blob/master/ais-bench_workload/tool/ais_bench/aclruntime_API_GUIDE.md
ais_bench推理命令介绍
端到端推理流程一般包括:预处理、模型推理和后处理三个步骤
预处理:将推理脚本中预处理代码保存为预处理文件,并将预处理后的数据保存为BIN文件或NPY文件;
模型推理:使用命令行执行推理,保存为BIN/NPY/TXT格式;
后处理:将推理脚本中后处理代码保存为后处理文件,并读取模型输出数据进行后处理操作;
注意:多个输入可保存在不同的文件夹下,同一个数据对应的多个输入使用相同命名方式,可直接按顺序传入输入文件夹执行推理;
使用ais_bench进行推理验证,参考命令:
python -m ais_bench --model /path/to/model.om --input /path/to/input --output /path/to/output--model: 昇腾离线模型OM的路径
--input: 指定模型需要的输入数据路径。如果模型有多个输入节点,则指定多个输入路径,用“,”隔开。路径可以是文件或者目录,若为文件则执行单样本推理,若为目录,则对该目录下的所有样本进行推理。
--output: 推理结果保存目录。配置后会创建“日期+时间”的子目录,保存输出结果。
ais_bench推理接口参考示例
推理流程:
1)将推理脚本中model的加载代码替换为OM模型加载代码
2)将推理脚本中model的推理代码替换为使用OM模型执行推理的代码
注意: 输入输出在List中的顺序与OM模型的输入输出顺序相同
示例:继承已改写的PytorchInferencer类,增加OM加载代码、重写model_inference函数
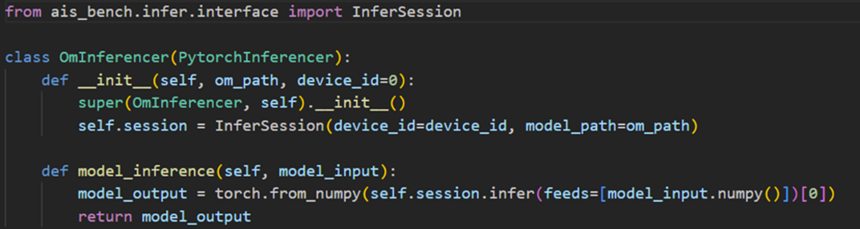
主要步骤:
① 创建session实例:
from ais_bench.infer.interface import InferSession
session = InferSession(device_id=0,model_path="/path/to/model.om")② 使用session实例进行推理
model_output = session.infer(feeds=model_input)[0]通过python调用aisbench使用指南参考
ais_bench提供的python API可供使能基于昇腾硬件的离线模型(.om模型)推理;在这里重点展开进行说明。
onnx为常见的模型格式,通常通过onnx转om模型实现在昇腾硬件上的推理加速,而ais_bench则是om模型推理工具,支持多Device推理、支持动态Batch参数、多线程推理等。
使用ais_bench工具,通常是通过命令行进行调用,每次模型均需要重复初始化和释放,不适合模型的服务化部署,但ais_bench工具也可以通过python进行调用,通过拆分ais_bench工具的处理逻辑,分为模型初始化、模型推理、获取模型性能数据、模型释放几个部分。
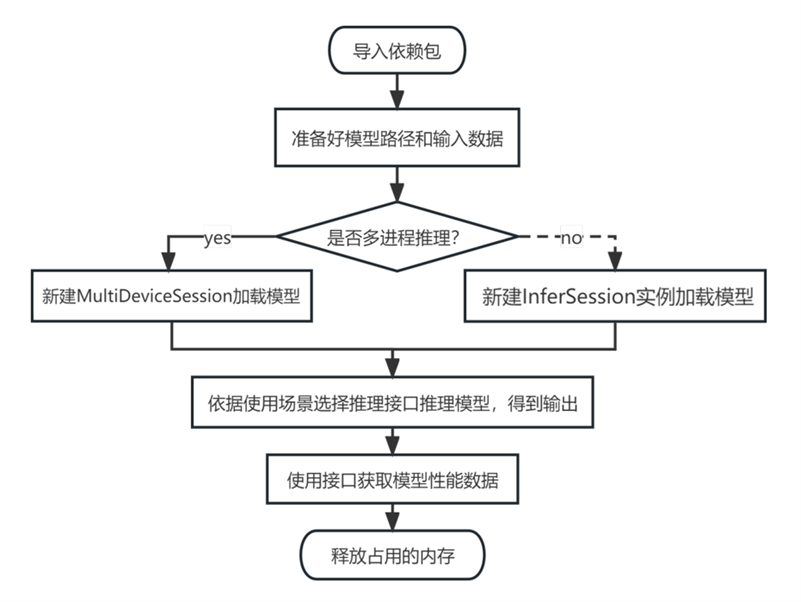
#导入依赖包
from ais_bench.infer.interface import InferSession
#加载模型,InferSession的初始化表示在device id为0的npu芯片上加载模型model.om
session = InferSession(device_id=0, model_path="model.om")
#调用接口推理模型得到输出;feeds传入一组输入数据;mode选择模型类型,static表示输入节点shape固定的静态模型
#outputs 为ndarray格式的tensor
outputs = session.infer(feeds=inputs, mode="static")
#获取模型数据性能
#exec_time_list 按先后顺序保留了所有session在执行推理的时间。
exec_time = session.summary().exec_time_list[-1]
#释放模型占用的内存
session.free_resource()aclruntime API使用指南参考
用户可以通过命令行以及Python API接口执行模型的推理过程。这两种方法主要使用了Python端封装的类InferSession,调用其中封装的参数设置、模型推理函数,获得推理结果和性能测试情况。
aclruntime绑定了Python前端InferSession类和C++后端PyInferenceSession类,直接开放aclruntime推理API,使用户可以直接调用aclruntime模块,用Python函数代码直接调用模型推理后端的C++函数,减少了在Python端的一些操作,提升模型推理和开发的效率。
01导入依赖包
使用aclruntime API前需要导入如下依赖:
import aclruntime02加载模型
aclruntime.InferenceSession 是运行模型推理aclruntime API的主要类,用于加载om模型和执行om模型的推理,模型推理前需要初始化一个InferenceSession的实例。
# session_options()构建了一个包含:log_level、loop、aclJsonPath的实例,存储模型信息
options = aclruntime.session_options()
# 该初始化表示在device_id的npu芯片上加载模型,并将options作为参数传入
session = aclruntime.InferenceSession(model_path, device_id, options)03数据迁移至device
aclruntime API直接调用后端C++函数,在该过程中需要数据在npu上,所以需要将模型的输入数据提前放在device侧。
# 利用aclruntime.Tensor将数据转化为适合模型推理的类型
tensor = aclruntime.Tensor(ndata)
# 将数据放至device上
tensor.to_device(device_id)04执行模型推理
建立好模型推理的实例session后,准备outnames,表示模型输出结果的名称。在npu芯片上的数据和配置都已经设定完成,调用session的成员函数接口进行模型推理,接口返回值就是推理结果。
# outnames表示模型推理结果输出的名称
outnames = [meta.name for meta in session.get_outputs()]
# feeds数据类型是list,存放着一组模型推理的Tensor类型的数据。outputs是ndarray格式的tensor,表示模型推理的输出。
outputs = session.run(outnames, feeds)05获取模型数据性能
推理结束,推理的性能数据也保存在session中,可以通过session的接口获取性能数据。
# exec_time_list 按先后顺序保留了所有session在执行推理的时间。
ssession.sumary().exec_time_listMxvision(Vision SDK)应用开发
Mxvision背景介绍
Vision SDK是MindSDK中面向图片和视频视觉分析的SDK,致力于视频图像处理算法加速,提升视频图像处理性能,降低CV应用的开发复杂度,加速CV应用开发部署。提供了基本的视频、图像智能分析能力及编程框架。简化昇腾芯片推理业务开发过程,降低使用昇腾芯片开发的门槛。
计算机视觉(Computer Vision,以下简称“CV”)最初是为了实现计算机对数字图片的简单处理而产生的,研究内容主要包括图像处理、模式识别、机器学习、深度学习等方面。在智能视频分析(Intelligent Video Analytics,以下简称“IVA”)行业中,传统计算常见算法的应用领域有很多,例如目标识别、视频结构化、动作行为识别等。随着硬件技术和算法的不断进步,视频与图像已逐渐成为全球互联网流量的主要组成部分。随着媒体服务的快速增长,AI图像算法基础的视频图像处理,逐渐成为计算流程中的成本壁垒和性能瓶颈。
相关的开发流程及API参考等更多细节请查看Vision SDK官方链接: https://www.hiascend.com/document/detail/zh/mindsdk/730/vision/visionug/mxvisionug_0002.html
Vision SDK主要有以下两种调用方式。
通过API接口方式开发:提供原生的推理API以及算子加速库,用户可通过调用API接口的方式开发应用。对于有固定应用开发流程的用户,建议采用此方式,借用Vision SDK提供算法加速能力构建CV应用。
通过流程编排方式开发:采用模块化的设计理念,将业务流程中的各个功能单元封装成独立的插件。用户可以用流程编排的方式,通过插件的串接快速构建业务,进行应用开发。此方式提供常用功能插件,具备流程编排能力,提供插件自定义开发功能。
API接口开发方式(C++)及样例
以Atlas 推理系列产品为例,使用Vision SDK C++接口开发图像目标检测应用进行演示,图像目标检测模型推理流程如下图所示。
目标检测模型推理流程图:

样例取用TensorFlow框架YoloV3模型,具体实现过程参考: https://www.hiascend.com/document/detail/zh/mindsdk/730/vision/visionug/mxvisionug_0014.html
API接口开发方式(Python)及样例
以Atlas 推理系列产品为例,使用Vision SDK Python接口开发图像分类应用进行演示,图像分类模型推理流程如下图所示。

样例取用Caffe框架ResNet-50模型,具体实现过程参考: https://www.hiascend.com/document/detail/zh/mindsdk/730/vision/visionug/mxvisionug_0015.html
流程编排开发方式及样例
以Atlas 推理系列产品为例,通过Vision SDK图像分类案例,介绍如何使用Vision SDK流程编排方式开发推理应用。案例使用YoloV3模型对图片进行分类并最后输出分类结果。
样例取用TensorFlow框架YoloV3模型,具体实现过程参考: https://www.hiascend.com/document/detail/zh/mindsdk/730/vision/visionug/mxvisionug_0016.html
pyACL使用说明(可选)
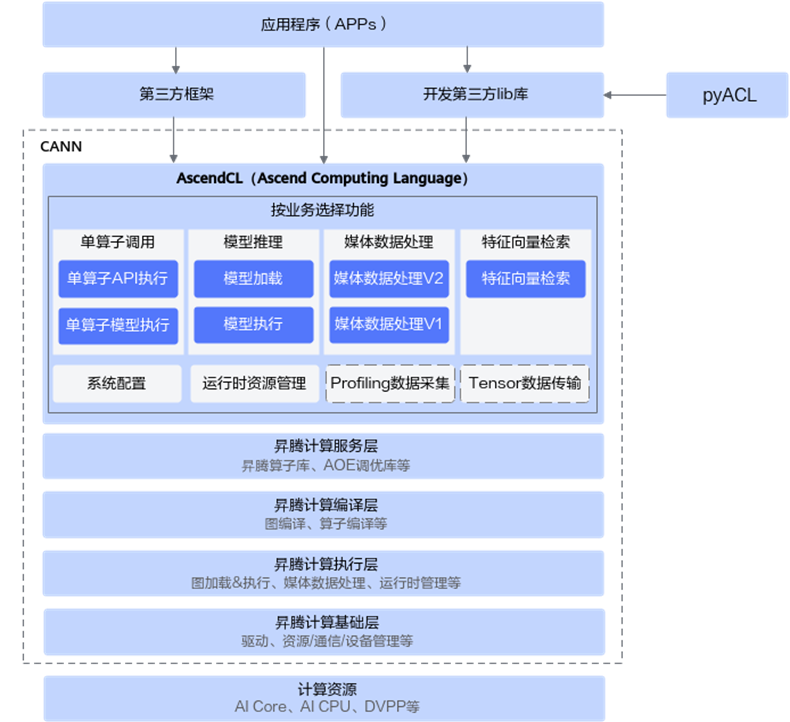
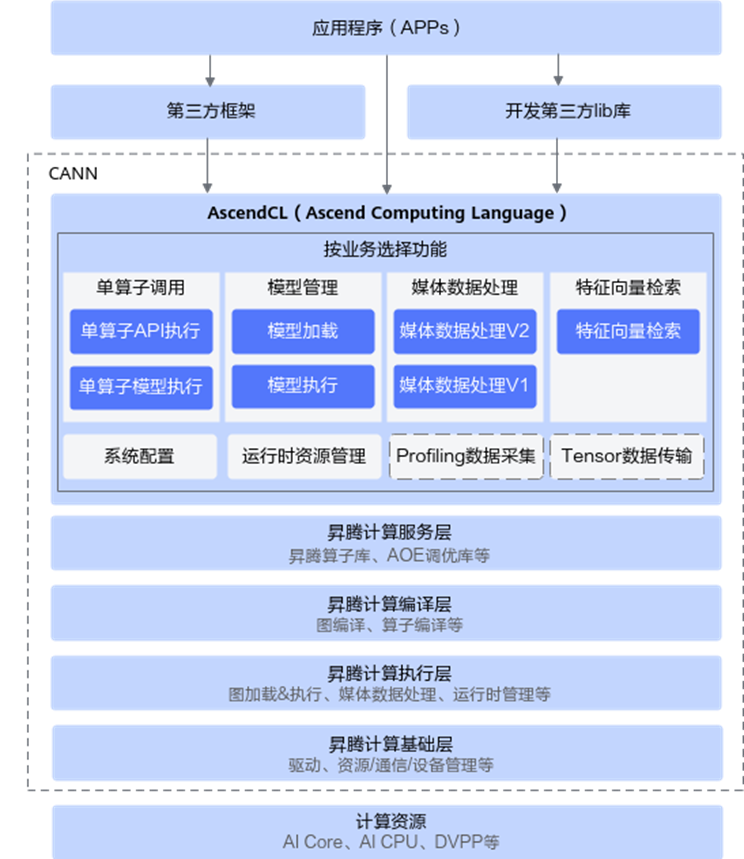
pyACL(Python Ascend Computing Language)就是在AscendCL的基础上使用CPython封装得到的Python API库,提供运行时管理、模型推理、媒体数据处理等API,单算子执行,使用户可以通过Python语言进行昇腾AI处理器的运行管理、资源管理等。
ACL使用说明(可选)
AscendCL(Ascend Computing Language)是一套开发深度神经网络应用的C语言API库,能够实现利用底层硬件计算资源,在CANN平台上进行深度学习推理计算、图形图像预处理、单算子加速计算等。简单来说,就是统一的API框架,实现对所有资源的调用。计算资源层是昇腾AI处理器的硬件算力基础,主要完成神经网络的矩阵相关计算、完成控制算子/标量/向量等通用计算和执行控制功能、完成图像和视频数据的预处理,为深度神经网络计算提供了执行上的保障。
ACL应用开发指南: https://www.hiascend.com/document/detail/zh/canncommercial/82RC1/appdevg/acldevg/acldevg_0001.html
高阶案例: https://gitee.com/ascend/samples/tree/master/inference/modelInference/sampleYOLOV7MultiInput