



昇腾小模型迁移方案(part1/2)
发表于: 2026/02/28
背景
当前在各行各业中,小模型的应用越来越广泛;比如在金融行业票据、证件、报表等会使用到OCR或者VLM类的模型,智能坐席语音会使用ASR/TTS类的模型;能源交通涉及目标检测任务,会使用CV类的模型;RAG场景会使用embedding类的模型等等;随着业务逐渐深入,大小模型的协同应用逐渐形成趋势;
本文通过小模型迁移指导文档帮助开发人员了解小模型迁移至NPU的整体方案架构,引导入门独立完成小模型迁移工作;对于模型迁移后的性能调优、精度调试等方面内容属于进阶内容,需要熟悉使用相关开发工具如性能调试工具、精度调试工具、profiling工具等辅助完成;本文也提供了迁移最佳实践的链接供参考学习;
模型迁移说明
什么是模型迁移
将原本设计用于GPU或其他三方平台的深度学习模型代码,经过模型代码修改等适配操作,来适应NPU的架构和编程,让模型能在NPU上进行高性能运行。
为什么要做模型迁移
在将模型从其他三方平台迁移到NPU时,由于硬件架构和库的不同,涉及到一系列底层到上层的适配操作。以GPU为例,模型迁移至NPU需要适配的原因可分为三方面:
硬件特性和性能特点差异,由于NPU和GPU的硬件特性和性能特点不同,模型在NPU上可能需要进一步的性能调试和优化,以充分发挥NPU的潜力。
计算架构差异,CUDA(Compute Unified Device Architecture)+ CuDNN是NVIDIA GPU的并行计算框架,而CANN(Compute Architecture for Neural Networks)是华为NPU的异构计算架构。
深度学习框架差异,为了支持NPU硬件,需要对PyTorch框架进行适配:包括适配张量运算、自动微分等功能,以便在NPU上高效执行。PyTorch正在原生支持NPU,以提供给用户更好的模型体验,实现迁移修改最小化。
模型迁移具备的能力及工具
熟练使用模型迁移分析、精度数据采集、性能数据采集、精度调优、性能调优等工具,具备精度和性能数据的分析能力。
MindStudio是华为面向昇腾AI开发者提供的全流程工具链,致力于提供端到端的昇腾AI应用开发解决方案,使能开发者高效完成训练开发、推理开发和算子开发。更多信息见链接:https://www.hiascend.com/document/detail/zh/mindstudio/830/index/index.html
这里主要介绍了常见的支持度分析、ATC、mist分析等工具。
支持度分析工具- PyTorch Analyse
模型是否可以迁移成功主要取决于模型算子是否支持昇腾AI处理器。支持度分析主要包括以下工作:
借助迁移分析工具识别当前昇腾平台对待迁移模型算子、API的支持情况;如果模型原始代码中调用了模型套件或第三方库,需要关注NPU对其的支持情况:
1、如果该三方库原生支持NPU,用户需要关注NPU目前对库中特性的支持情况;
2、如果是昇腾适配的第三方库,用户需要额外安装该库的昇腾适配版本,并关注其适配情况。详细昇腾第三方库支持情况请参考《套件与三方库支持清单》(三方库清单列表-Ascend Extension for PyTorch7.2.0-昇腾社区)。
如果用户希望以上第三方库和模型套件在适配昇腾设备后能达到更高的性能,可以自行调优。
PyTorch Analyse工具提供分析脚本,帮助用户在执行迁移操作前,分析基于GPU平台的PyTorch训练脚本中API、三方库套件、亲和API分析以及动态shape的支持情况。
启动分析任务
1. 进入工具目录
cd cd Ascend-cann-toolkit安装目录/ascend-toolkit/latest/tools/ms_fmk_transplt/2. 启动分析任务
./pytorch_analyse.sh -i 待分析脚本路径 -o 分析结果输出路径 -v 待分析脚本框架版本 [-m 分析模式]3. 解析分析结果
分析报告简介:
分析模式为“torch_apis”时,分析结果如下所示:
• ├── xxxx_analysis // 分析结果输出目录
• │ ├── cuda_op_list.csv //CUDA API列表
• │ ├── unknown_api.csv //支持存疑的API列表
• │ ├── unsupported_api.csv //不支持的API列表
• │ ├── api_precision_advice.csv //API精度调优的专家建议
• │ ├── api_performance_advice.csv //API性能调优的专家建议
• │ ├── pytorch_analysis.txt // 分析过程日志不支持的API列表示例:

备注:
如果自动迁移法迁移到NPU之后,若出现明确打印算子不支持,记录该算子,可以通过to cpu计算后继续跑。
算子不支持报错举例:
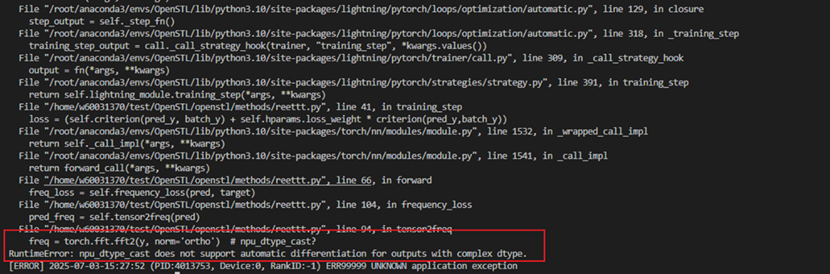
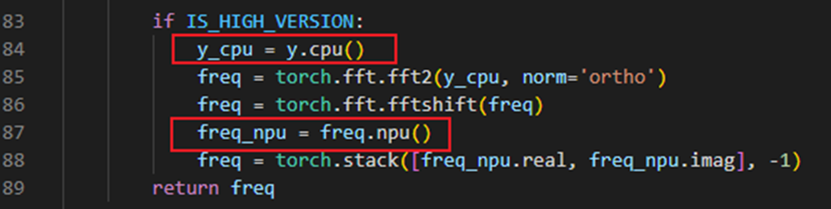
转CPU执行:
ATC工具
昇腾张量编译器(Ascend Tensor Compiler,简称ATC)是异构计算架构CANN体系下的模型转换工具,它可以将开源框架的网络模型以及Ascend IR定义的单算子描述文件(JSON格式)转换为昇腾AI处理器支持的.om格式离线模型。
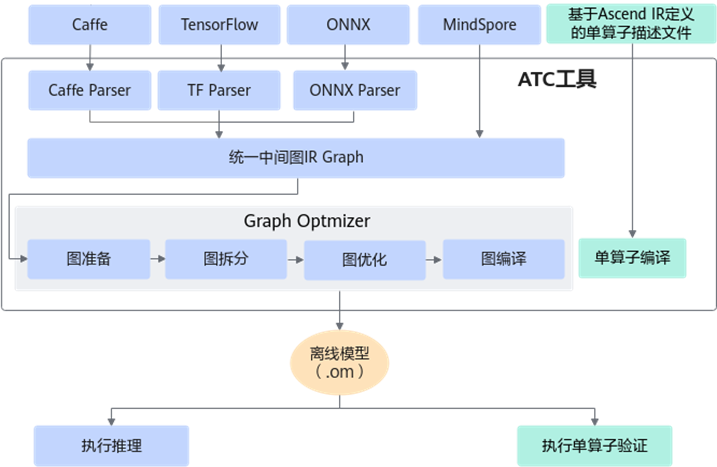
开源框架网络模型场景:
- 开源框架网络模型经过Parser解析后,转换为中间态IR Graph。
- 中间态IR经过图准备、图拆分、图优化、图编译等一系列操作后,转成适配昇腾AI处理器的离线模型(此处图指网络模型拓扑图)。
- 转换后的离线模型上传到板端环境,通过acl接口加载模型文件实现推理过程。
运行流程如下:
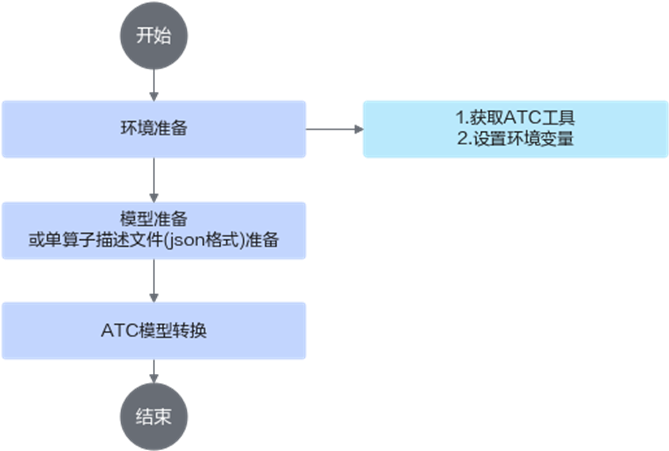
1. 使用ATC工具之前,请先在开发环境安装CANN软件包,获取相关路径下的ATC工具,然后设置环境变量,详细说明请参见准备环境章节。
2. 准备要进行转换的模型或单算子描述文件,并上传到开发环境。单算子描述文件相关配置请参见单算子模型转换。
3. 使用ATC工具进行模型转换,模型转换过程中使用的参数请参见参数说明。
MIST调试工具
MIST(MindStudio Inference Tools)作为昇腾统一推理工具,提供一体化开发功能,帮助用户进行模型迁移以及性能与精度的调试调优。目前,该工具包括 benchmark、debug、analyze、convert、profile、llm、tensor-view 等组件;使用指导见: https://gitcode.com/Ascend/msit/tree/master/msit
相比于业界标杆算子,昇腾自研算子在昇腾AI处理器上的运算结果可能存在差异:
模型迁移:原始模型(基于GPU)在迁移到昇腾环境进行训练或在线推理时,昇腾自研算子的运算结果与业界标杆算子存在差异。
模型转换:ATC工具转换模型时,会对模型进行算子消除、算子融合、算子拆分等优化,这些操作可能会造成自研算子运算结果与业界标杆算子存在差异。
模型兼容:ATC工具转换的离线模型,由于CANN软件版本迭代、模型版本迭代、模型优化、硬件升级或ATC转换前开启或关闭了算子融合功能,可能会造成升级或优化后的离线模型存在精度下降问题。
NPU推理精度与标杆精度(官方精度/GPU离线/cpu在线推理)下降不超过1%则认为精度达标
昇腾环境准备
当小模型在GPU环境上成功运行之后,就可以尝试在昇腾上进行模型迁移了。
建议使用官方CANN镜像配合安装模型依赖库,镜像下载链接: https://www.hiascend.com/developer/ascendhub/detail/17da20d1c2b6493cb38765adeba85884
整体流程如下图所示,安装基础CANN包后,根据不用的框架安装相关依赖;
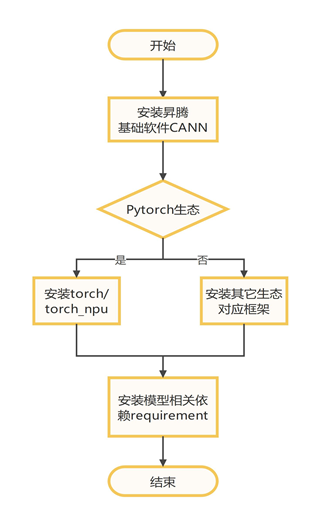
整体方案介绍
迁移适配方案架构
小模型迁移方案方案框架如下:
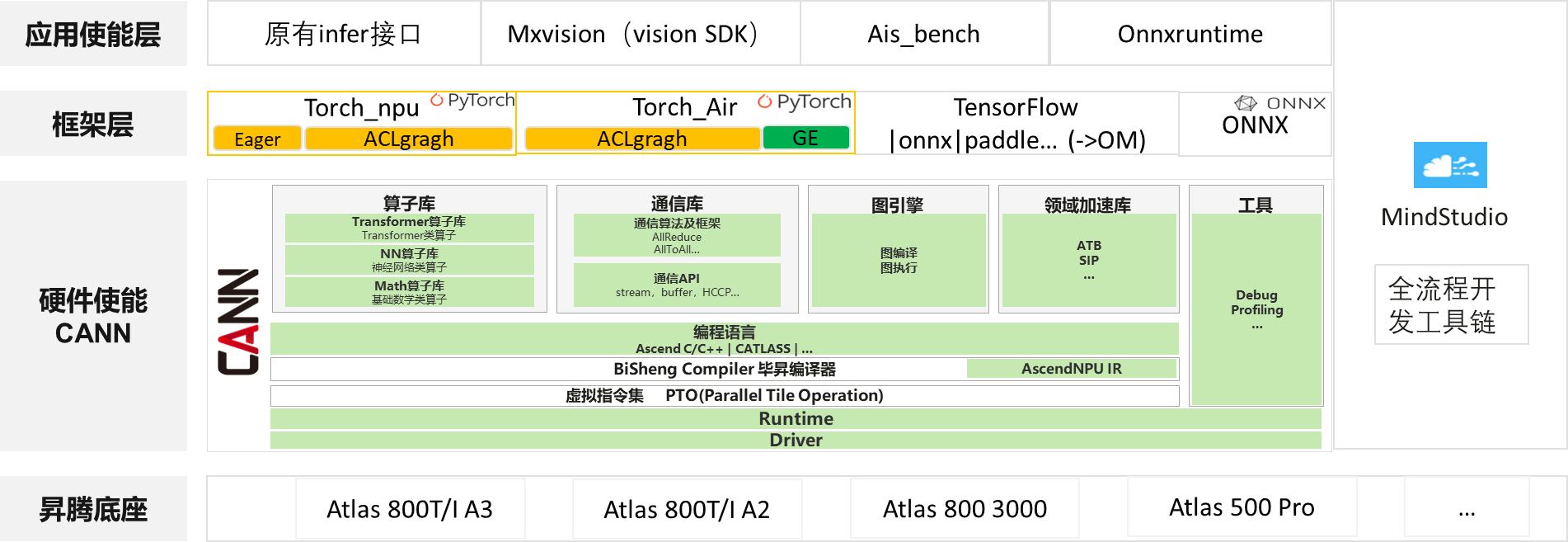
昇腾底座:主要包括昇腾主流服务器,比如Atlas A3 、A2系列;Atlas 800 推理服务器、Atlas 500 Pro 智能边缘服务器等等。
异构计算架构CANN(Compute Architecture for Neural Networks):是昇腾针对AI场景推出的异构计算架构,向上支持多种AI框架,包括MindSpore、PyTorch、TensorFlow等,向下服务AI处理器与编程,发挥承上启下的关键作用,是提升昇腾AI处理器计算效率的关键平台;
框架层说明:
非pytorch生态:可使用ONNX进行推理(复用onnxruntime生态);也可用ATC工具转成OM文件格式进行推理;
pytorch生态:支持torch_npu模式(torch_npu支持单算子模式,也可以通过aclgragh实现图模式);torchair(图模式)。torchAir可通过调优适配获得极致性能,但整体调优门槛较高;
应用使能:迁移适配后,可在NPU上对模型进行正常部署推理应用,可以通过调用ais_bench,Mxvision(针对CV类模型,面向图片和视频视觉分析的SDK),自有的infer接口等方式推理;
MindStudio:提供开发全流程工具,包括迁移过程中的精度、性能调优等等;
推理路线说明:
ais_bench,Mxvision是基于CANN的ACL、pyACL应用开发接口进行封装实现,当前只支持om格式的推理;
TorchAir及torch_npu可使用pytorch原生的infer接口;
onnxruntime只针对onnx格式进行推理,复用onnxruntime社区生态能力;
小模型迁移路线说明
下图是针对各框架总结的迁移路线。
性能方面整体上图模式(GE、ACLgragh等)优于单算子eager模式。
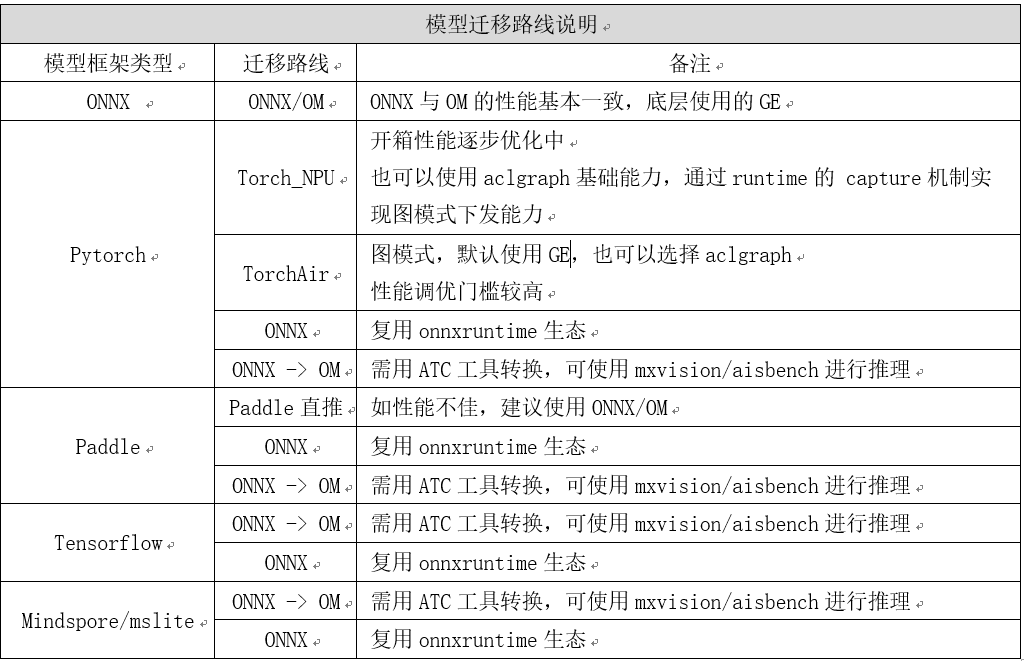
对于不同的昇腾设备建议如下:

迁移整体流程如下:
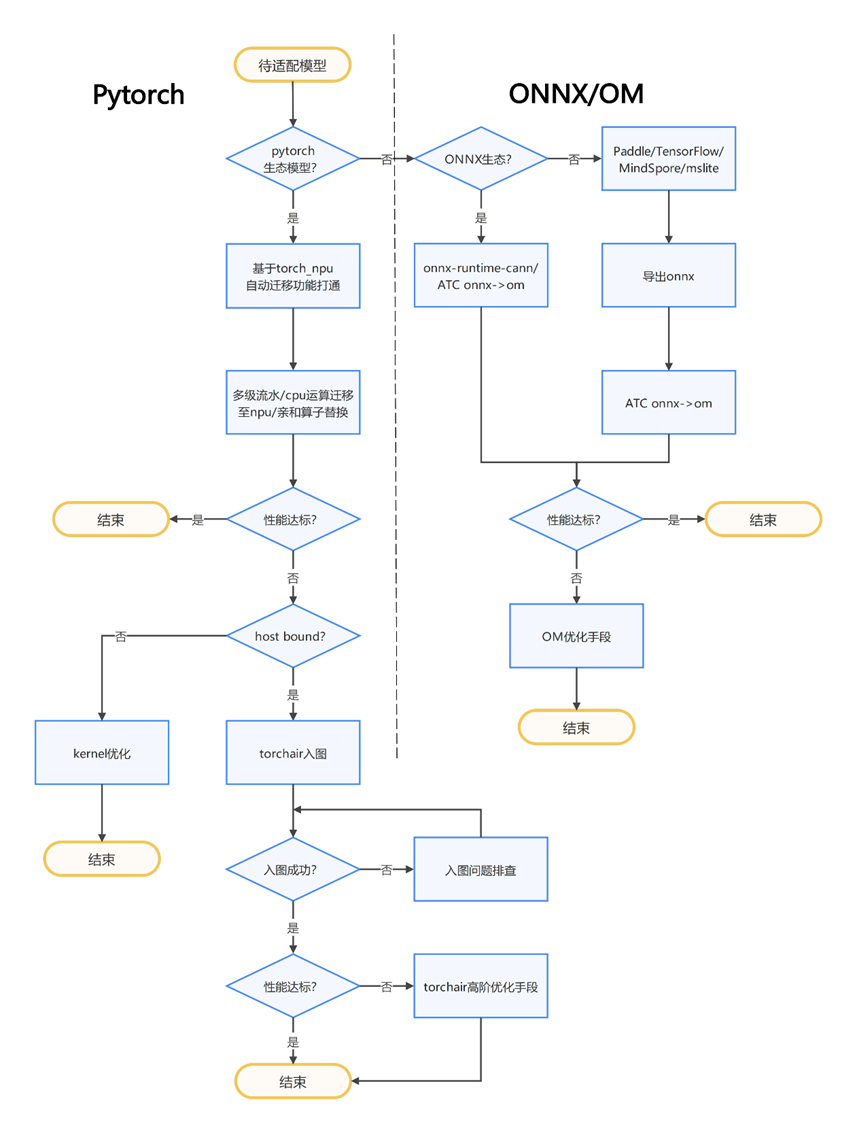
迁移适配全流程介绍
通用模型迁移适配方法,可以分为四个阶段:迁移分析、迁移适配、精度调试与性能调优、推理部署验证。
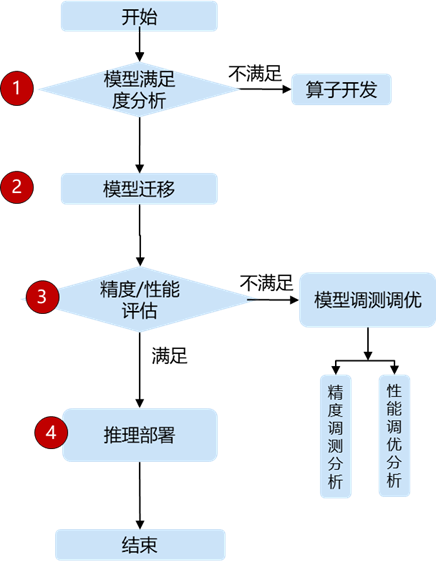
模型满足度分析:基于原始模型代码及结构,分析是否存在缺失算子;
适配迁移:将原始GPU上运行的脚本迁移至NPU上;
精度评估:基于数据集评测模型精度,精度指标与GPU相差1%以内;
性能评估:基于数据集测试、分析、优化推理端到端性能否是满足预期;
推理部署:对模型进行推理部署上线验证;
满足度分析、精度、性能调试可以通过开发全流程工具MindStudio辅助分析;
小模型迁移适配库说明
当前小模型主要会放置ModelZoo、SACT、vllm-ascend库。
ModelZoo涉及模型迁移适配主要是三个库:
https://gitcode.com/Ascend/ModelZoo-PyTorch
https://gitcode.com/Ascend/modelzoo-GPL
https://gitee.com/ascend/ModelZoo-TensorFlow
ModelZoo-PyTorch、ModelZoo-GPL是昇腾旗下的开源AI模型平台,涵盖计算机视觉、自然语言处理、语音、推荐、多模态、大语言模型等方向的AI模型及其基于昇腾机器实操案例。平台的每个模型都有详细的使用指导,为方便更多开发者使用。
SACT仓也会放置模型案例: https://gitcode.com/Ascend-SACT 。
使用vllm服务化部署的小模型案例会逐步迁移至vllm-ascend: https://docs.vllm.ai/projects/ascend/en/latest/ 。
Torch/ONNX/OM迁移操作指导
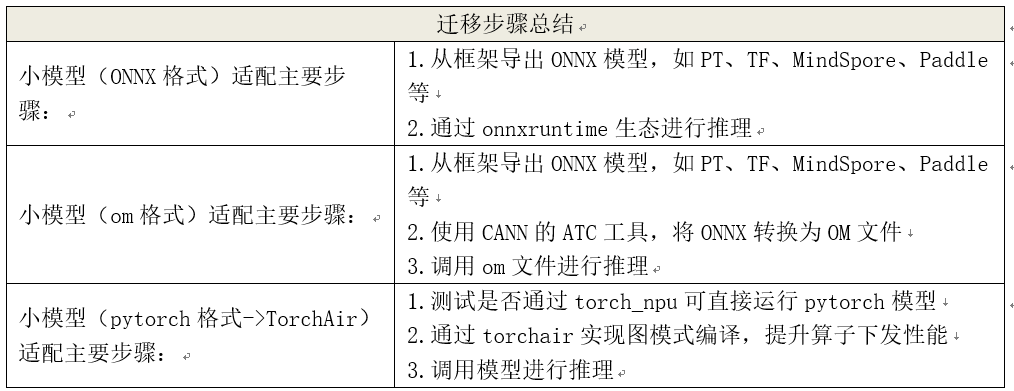
Torch_npu技术路线及案例
torch_npu
torch_npu 是专为昇腾(Ascend)NPU开发的 PyTorch 扩展插件,旨在让 PyTorch 开发者能够利用昇腾 AI 处理器的强大算力进行模型训练和推理。torch适配npu需安装torch_npu插件,插件安装需适配pytorch版本;详细内容可参考官方代码库: https://gitcode.com/Ascend/pytorch
torch_npu使用参考:
在脚本开头加上
import torch
import torch_npu /# PyTorch 2.5.1及之后版本支持设备插件自动加载,无需执行import torch_npu即可使用NPU设备
from torch_npu.contrib import transfer_to_npu /# 该命令自动把torch.cuda系列api替换成torch.npu的底层实现;即可自动将脚本中涉及cuda、nccl等算子替换成npu、hccl等华为昇腾支持的算子
01 导入NPU相关库
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu02 指定NPU作为运行设备
.to(device)方式
迁移前:
device = torch.device('cuda:{})'.format(local_rank))
model.to(device)
data.to(device)迁移后:
device = torch.device('npu:{}'.format(local_rank))
model.to(device)
data.to(device)03 set_device方式
迁移前:
torch.cuda.set_device(local_rank)迁移后:
torch_npu.npu.set_device(local_rank)04 运行模型,确保迁移后可以正确运行。
paraformer语音识别迁移案例-torch_npu方式
本案例为通过torch_npu路线对paraformer模型进行迁移适配,整体流程下图所示,使用torch_npu迁移需要引入相关头文件;使用torch_npu如果性能不满足业务诉求,可尝试使用图模型进行优化。更多案例可参考小模型库。
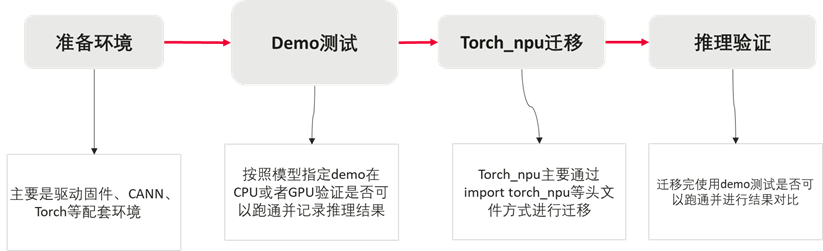
关键代码分析:torch_npu迁移适配
官方提供的demo如下:
from funasr import AutoModel
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc",
# spk_model="cam++"
)
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
batch_size_s=300,
hotword='魔搭')
print(res)使用torch_npu迁移后即可在npu上运行:
from funasr import AutoModel
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
print("Torch npu available: ", torch_npu.npu.is_available())
torch_npu.npu.set_compile_mode(jit_compile=False)// 设置是否开启二进制
torch_npu.npu.set_device("npu:0")//指定npu device
# paraformer-zh is a multi-functional asr model
# use vad, punc, spk or not as you need
model = AutoModel(model="paraformer-zh", vad_model="fsmn-vad", punc_model="ct-punc",
# spk_model="cam++"
)
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
batch_size_s=300,
hotword='魔搭')
print(res)torchAir技术路线及案例
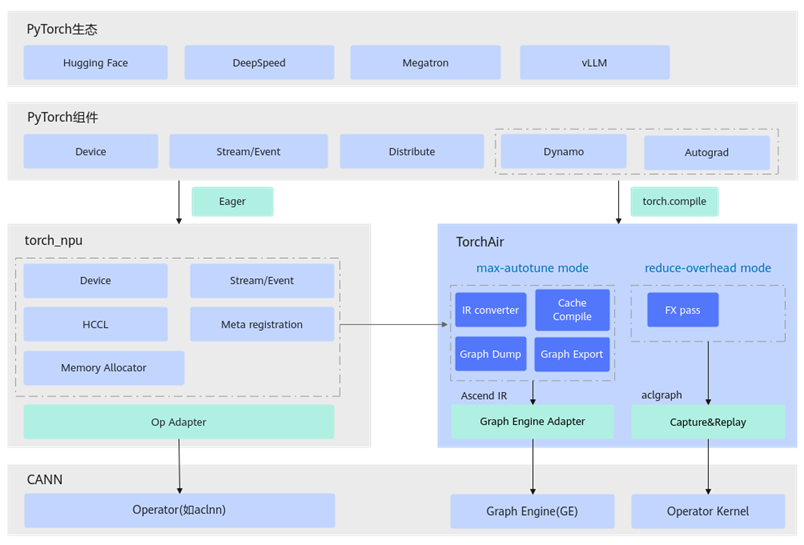
torchAir
TorchAir(Torch Ascend Intermediate Representation)是昇腾Ascend Extension for PyTorch(torch_npu)的图模式能力扩展库,提供了昇腾设备亲和的torch.compile图模式后端,实现了PyTorch网络在昇腾NPU上的图模式推理加速以及性能优化。
开源仓链接: https://gitcode.com/Ascend/torchair
名称 | 说明 |
Eager模式 | PyTorch支持的单算子执行模式(未使用torch.compile)。Eager模式执行特点如下,1. 即时执行:每个计算操作在定义后立即执行,无需构建计算图;2. 动态计算图:每次运行可能生成不同的计算图。 |
图模式 | 一般指使用torch.compile加速的模型执行方式。图模式执行特点如下,1. 延迟执行:所有计算操作先构成一张计算图,再在会话中下发执行;2. 静态计算图:计算图在运行前固定。 |
模型适配及性能调优流程:
torch_npu迁移适配: 用户使能图模式之前,请先将模型迁移至昇腾NPU上,确保能够在单算子模式(Eager)下正确执行
torch_npu性能优化: 模型性能涉及包括算法在内的多个模块,因此模型性能的优化的关键在于找到当前性能瓶颈,找到关键问题后再针对性优化。
图优化: 当Host侧任务下发耗时超过Device侧任务执行耗时,Device会因等待新任务而处于空闲状态,形成性能瓶颈,即Host Bound问题。图模式具备"延迟执行"和"静态计算图"两个特点,可以有效优化算子下发,解决Host Bound问题。
TorchAir实现图模式的方式有如下两种,可通过config.mode切换模式。
max-autotune模式(Ascend IR):将PyTorch的FX计算图转换为昇腾中间表示(IR,Intermediate Representation),即Ascend IR计算图,并通过GE(Graph Engine,图引擎)实现计算图的编译和执行。
reduce-overhead模式(aclgraph):采用Capture&Replay方式实现任务一次捕获多次执行,Capture阶段捕获Stream任务到Device侧,暂不执行;Replay阶段从Host侧发出执行指令,Device侧再执行已捕获的任务,从而减少Host调度开销,提升性能。
TorchAir架构图:
YOLOv11迁移案例-torchAir方式
本案例为通过torchair路线对yolo11模型进行迁移适配,整体流程下图所示,需要注意的是使用torch compile进行图编译后会涉及多处代码修改,主要原因是eager模式执行下,与Dynamo的逻辑存在差别。更多案例可参考小模型库。
YOLOv11已合入modelzoo仓: https://gitcode.com/Ascend/modelzoo-GPL/blob/master/built-in/ACL_Pytorch/Yolov11_for_PyTorch/README.md
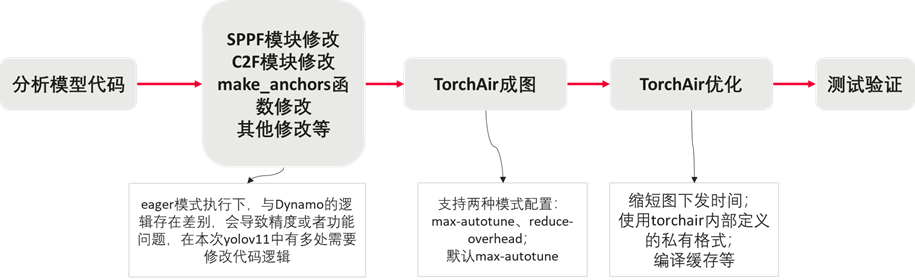
TorchAir相关的代码如下:
关键代码分析:torch compile成图
模型设置在setup_model函数中,通过调用AutoBackend完成对模型的初始化,AutoBackend会自动选择如PT、ONNX、TensorRT等后端;
def setup_model(self, model, verbose=True):
"""Initialize YOLO model with given parameters and set it to evaluation mode."""
self.model = AutoBackend(
weights=model or self.args.model,
device=select_device(self.args.device, verbose=verbose),
dnn=self.args.dnn,
data=self.args.data,
fp16=self.args.half,
batch=self.args.batch,
fuse=True,
verbose=verbose,
)
self.device = self.model.device # update device
self.args.half = self.model.fp16 # update half
self.model.eval()在self.model初始化后增加torch compile相关逻辑:
import torch_npu
import torchair
from torchair.configs.compiler_config import CompilerConfig
config = CompilerConfig()
npu_backbend = torchair.get_npu_backend(compiler_config=config)
self.model = torch.compile(self.model, dynamic=False, fullgraph=True, backend=npu_backbend)这里选择整图编译和静态模式,以获极致性能
关键代码分析:torchair优化
开启固定权重类输入地址功能,缩短图下发时间,提升下发性能
config.experimental_config.frozen_parameter = True使用torchair内部定义的私有格式以提升性能
torchair.use_internal_format_weight(self.model)编译缓存优化:
在执行脚本和等待第一张图片的结果过程中,需要等待大概20-30s,这个时间是成图编译的耗时,通常包括两部分,一段是Dynamo的编译耗时,一段是Ascend IR计算图的编译耗时,可以通过编译缓存来解决。torchair.inference.cache_compile接口可以将首次编译结果落盘,默认开启Dynamo的编译缓存,增加ge_cache=True开启Ascend IR编译缓存,修改如下
#self.model = torch.compile(self.model, dynamic=False, fullgraph=True, backend=npu_backbend)
self.model.forward = torchair.inference.cache_compile(self.model.forward, dynamic=False, fullgraph=True, backend=npu_backbend, cache_dir="/home/w00936509/cache", ge_cache=True)修改后,推理阶段device空泡消除,且直接调用缓存。
ONNX/OM技术路线及案例
ONNX转换
说明:ONNX转换完成后可复用onnxruntime生态进行推理;可参考官方链接: https://github.com/microsoft/onnxruntime
本示例主要将PyTorch模型(*.py)和权重(*.pth)转换成ONNX文件(*.onnx)。其他框架模型可参照ONNX官方文档。
ONNX转换方法: 借助torch.onnx.export接口编写转换脚本实现
torch.onnx.export参数说明: https://docs.pytorch.org/docs/2.0/onnx.html
import sys
import torch
import torch.onnx
import torchvision.models as models
def convert(pthfile):
model = models.resnet50(pretrained=False)
resnet50 = torch.load(pthfile, map_location='cpu')
model.load_state_dict(resnet50)
print(model)
input_names = ["actual_input_1"]
output_names = ["output1"]
dummy_input = torch.randn(16, 3, 224, 224)
torch.onnx.export(
model,
dummy_input,
"resnet50_official.onnx",
input_names=input_names,
output_names=output_names,
opset_version=11)
if __name__ == "__main__":
pth_path = sys.argv[1]
convert(pth_path)对于超大(大于2GB)的ONNX模型,模型结构与权重往往都是分开存放;如将所有节点的权重合并成一个大文件存放,参考下面的代码
import onnx
model = onnx.load(input_model_path)
onnx.save(
model,
output_onnx_path,
save_as_external_data=False, # 将权重数据与模型结构不分开保存
all_tensors_to_one_file=True # 将所有节点的权重合并成一个大文件保存
)如需对ONNX文件可视化;参考以下链接: https://netron.app/
ONNX -> OM转换
本文将ONNX模型文件(.onnx)编译成昇腾推理芯片上可以运行的文件格式(*.om);其他框架模型转换参考见链接: https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850/devaids/atctool/atlasatc_16_0003.html
方法: 借助ATC工具(Ascend Tensor Compiler,简称ATC)和文档编写转换命令,ATC转换工具参数说明见链接: https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/850/devaids/atctool/atlasatc_16_0039.html
静态om的导出说明:
atc \
--framework=5 \
--model=XXX \
--output=XXX \
--input_format=XXX \
--input_shape=model_input_name:model_input_shape \
--log=error \
--soc_version=Ascend${chip_name}参数说明:
framework : 5代表ONNX模型
model : ONNX模型文件路径与文件名
output : 输出的OM模型文件路径与文件名
input_format : 可以选NCHW or ND
input_shape : 模型输入的shape
log : log日志有debug/info/warning/error/null级别
soc_version : 指定模型转换时昇腾AI处理器的版本
动态om的导出说明:
动态BatchSize转OM | 动态分辨率转OM | 动态维度转OM |
--input_shape="Placeholder:-1,224,224,3" --dynamic_batch_size="1,2,4,8" | --input_shape="Placeholder:1,-1,-1,3" --dynamic_image_size="224,224;448,448" | --input_shape="Placeholder:-1,-1,-1,3" --dynamic_dims="1,224,224;8,448,448" |
相关input_shape、dynamic_batch_size等使用方式可参考社区文档
Resnet50迁移案例-OM方式
本案例为通过om路线对resnet50模型进行迁移适配,整体流程下图所示;关键部分为模型转onnx->om的过程。整体迁移过程比较流程比较固定,易操作。
完整适配过程可访问链接: https://gitee.com/ascend/ModelZoo-PyTorch/blob/master/ACL_PyTorch/built-in/cv/Resnet50_Pytorch_Infer/README.md
更多案例可参考小模型库。
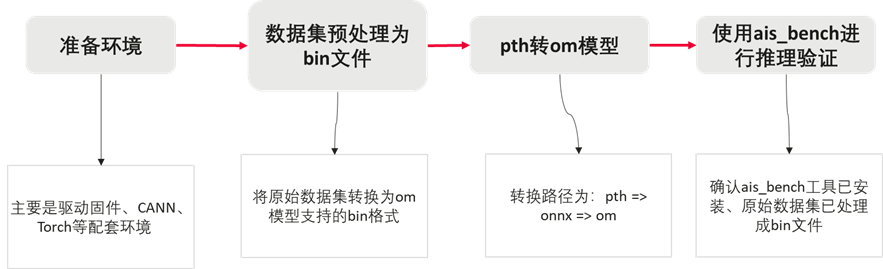
关键代码分析:om迁移适配
pth => onnx
使用pth2onnx.py导出onnx文件。
python3 pth2onnx.py ./resnet50-0676ba61.pth执行此命令后,在当前路径生成resnet50_official.onnx文件。
onnx => om(使用ATC工具)
# batch_size变量赋值.atc命令中使用了此变量。
bs=1
atc --model=./resnet50_official.onnx --framework=5 --output=resnet50_bs${bs} --input_format=NCHW --input_shape="input:${bs},3,224,224" --enable_small_channel=1 --log=error --soc_version=Ascend310P3 --insert_op_conf=aipp_resnet50.config注意:--soc_version根据npu-smi info实际查询到的芯片名称填写。
参数说明:
--model:pth2onnx.py生成的ONNX模型文件。
--framework:5代表ONNX模型。
--output:输出的OM模型。
--input_format:输入数据的格式。
--input_shape:输入数据的shape。
--log:日志级别。
--soc_version:处理器型号。
--enable_small_channel:是否使能small channel的优化,使能后在channel<=4的卷积层会有性能收益。
--insert_op_conf: AIPP插入节点,通过config文件配置算子信息,功能包括图片色域转换、裁剪、归一化,主要用于处理原图输入数据。
运行成功后生成resnet50_bs${bs}.om模型文件。
关键代码分析:aisbench推理验证
执行推理前,请确认ais_bench工具已安装、原始数据集已处理成bin文件。
python3 -m ais_bench --model ./resnet50_bs1.om --input ./prep_dataset/ --output ./ --output_dirname result参数说明:
--model:模型地址,前文中使用atc命令转换得到的om模型
--input:预处理完的数据集文件夹
--output:推理结果保存地址
--output_dirname: 推理结果保存文件夹
运行成功后会在./result下生成推理输出的bin文件。
运行成功时的输出内容示意:
[INFO] acl init success
[INFO] open device 0 success
[INFO] create new context
[INFO] load model ./resnet50_bs1.om success
[INFO] create model description success
[INFO] try get model batchsize:1
[INFO] output path:./result
[INFO] get filesperbatch files0 size:150528 tensor0size:150528 filesperbatch:1 runcount:10
[INFO] warm up 1 done
Inference array Processing: 100%|██████████████| 10/10 [00:00<00:00, 763.75it/s]
[INFO] -----------------Performance Summary------------------
[INFO] NPU_compute_time (ms): min = 0.5100002288818359, max = 0.5789999961853027, mean = 0.5191998958587647, median = 0.5124998092651367, percentile(99%) = 0.5735099649429322
[INFO] throughput 1000*batchsize.mean(1)/NPU_compute_time.mean(0.5191998958587647): 1926.0404479588435
[INFO] ------------------------------------------------------
[INFO] unload model success, model Id is 1
[INFO] end to reset device 0
[INFO] end to finalize acl