



MindSpeed LLM全新升级-支持FSDP训练后端,Qwen3-Next-Coder模型天级适配
Released: 2026/02/10
当前大模型技术正加速走向普惠化,训练与应用门槛持续降低,大语言模型从技术探索迈向行业规模化落地。行业焦点已转向模型便捷部署与敏捷业务上线,企业亟需易用性强的全流程 LLM 套件,简化训练、微调、部署与迭代,加速模型创新与业务落地。MindSpeed LLM全新升级,基于FSDP 训练后端打造轻量化大语言模型套件,摒弃繁琐的配置,提供一套极简的模型适配方案,Qwen3-Next-Coder模型发布后天级完成适配,为大模型训练普惠化提供核心动力。
一、 MindSpeed LLM 正式引入全新 FSDP2 训练后端
相比原有框架,全新FSDP训练后端的MindSpeed LLM套件具有以下核心优势:
1. 极简易用:零侵入,原生适配 无需修改模型源码,彻底解耦并行策略与模型结构。无论是 Hugging Face 开源模型还是自研架构,均可直接原生支持。
2. 多维并行:FSDP + EP + CP 灵活组合 支持 FSDP(完全分片数据并行)、EP(专家并行)与 CP(上下文并行)的混合策略,轻松应对超大参数量与长序列训练挑战。
3. 性能加速:昇腾亲和,全链路优化 底层深度优化计算、内存与通信。内置高性能融合算子,引入异步 Offload 打破显存瓶颈,实现训练吞吐量的极致释放。
4. 体验重构:拒绝繁琐,直观开发 直接加载权重,免去格式转换烦恼。打通预训练到微调全流程,代码结构清晰,显著提升二次开发与算法创新效率。
5. 精度对齐:双重标尺,稳定可靠 SFT 场景对齐 LLaMA-Factory,预训练场景严格对齐 Megatron-LM。在轻量化的同时确保数值精度与收敛性,让迁移切换“零顾虑”。
二、 全链路重构,原子化模块设计
MindSpeed LLM FSDP2 后端采用了高度模块化的架构设计,将复杂的分布式训练流程拆解为标准化、可复用的原子组件。各组件之间严格遵循接口契约,最大限度降低组件间的依赖耦合,并预留了标准化的算法扩展接口,为前沿算法的快速实验与落地铺平道路。
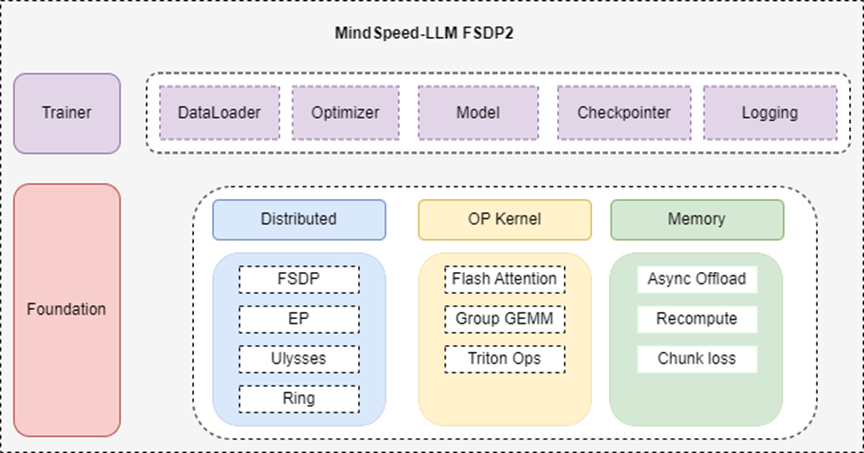
MindSpeed LLM FSDP训练后端介绍
ModelFactory(模型组件):负责加载 HuggingFace 权重,构建model实例,应用MindSpeed FSDP后端根据并行参数(FSDP/EP/CP)将模型切片。
OptimizerFactory & SchedulerFactory(优化器和学习率调度器组件):构建优化器,支持adam和muon优化器。设置Beta 和 Epsilon,以及配置 Warmup-Decay 学习率。
DataFactory(数据处理组件):加载数据集,应用 ChatTemplate,并构建支持分布式采样的 DataLoader,支持预训练和微调场景数据处理。
Checkpointer(权重管理组件):负责处理 FSDP2 的分布式 Checkpoint 保存与加载,支持后台异步写入,支持断点续训。
Logging(日志模块组件):提供纯文本日志输出(无级别/时间前缀)、一次性警告(生命周期内仅输出一次)等扩展能力,提供全局初始化接口和便捷的日志实例获取方法,默认配置开箱即用,支持动态调整日志级别和格式。
Trainer(训练组件):负责执行标准的 Epoch/Step 循环、前向/反向传播、梯度累积、梯度裁剪和参数更新。
Foundation (后端基础组件):该层汇集了训练所需的核心底层能力,采用原子化封装设计,确保各个特性模块解耦且即插即用,为开发者提供灵活的组合能力。
三、 新模型快速适配:双路径选择
对比Megatron后端与新的FSDP2后端适配新模型的步骤差异,感受从“周级适配”到“天级适配”的质变。
| Megatron后端 | FSDP2后端 | 易用性改变 |
模型代码 | 重写: 新结构需重写模型代码适配 | 原生: 直接复用 HuggingFace的开源代码 | 代码修改量减少 90% |
权重加载 | 切片转换:
| 直接加载: FSDP2 自动在运行时将完整权重 Shard 到各卡,或支持直接加载 HF 格式 | 省去权重转换步骤 |
通信逻辑 | 手动管理:
| 全自动:
| 屏蔽分布式通信细节 |
为了满足不同层次的需求,MindSpeed LLM提供了两条适配路径。
适配路径概览:
路径 | 适用场景 | 复杂度 | 优势 |
路径一:社区原生模型适配 | 标准 Hugging Face 模型,无需修改算子。 | ⭐ (低) | 零代码适配,速通训练,通过 |
路径二:自研模型适配 | 需要算子融合、修改 Attention 逻辑或 MoE 逻辑等自研模型结构。 | ⭐⭐⭐ (中) | 自研模型高性能训练优化,深度定制,支持加速特性、融合算子优化。 |
路径一:原生 Transformers 适配 (零代码)
这是最快的接入方式。只要模型在 transformers 库中受支持,即可直接训练。
操作步骤:
1. 准备权重:确保模型符合 HF 标准格式。
2. 修改配置:在 模型的yaml配置文件中,填入下载好的权重路径即可。
# ./examples/fsdp2/qwen3_next/tune_qwen3_next_fsdp2.yaml
model:
model_name_or_path: "/path/to/qwen3_next"
trust_remote_code: true框架行为:根据权重路径下配置文件config.json -> 调用 AutoModelForCausalLM创建模型-> 调用MindSpeed FSDP后端自动应用 FSDP2 策略。
路径二:自研模型适配
当需要注入 NPU 亲和算子(如 Flash Attention 融合算子)或修改模型逻辑时使用。
操作步骤:
1. 定义模型类
在 mindspeed_llm/fsdp2/models/ 下创建目录(如 qwen3_next),继承 HF 原生类或 复制源码进行二次开发。
# mindspeed_llm/fsdp2/models/qwen3_next/modeling_qwen3_next.py
from transformers import Qwen3NextForCausalLM
class Qwen3NextForCausalLM (Qwen3NextForCausalLM):
"""
自定义模型类,继承自 HF 原生类,用于注入特定逻辑。
"""
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs):
"""
[可选] 重写加载逻辑,如果需要特殊的初始化流程。
通常直接调用 super() 即可。
"""
model = super().from_pretrained(pretrained_model_name_or_path, *model_args, **kwargs)
return model
def forward(self, input_ids, ...):
"""
[可选] 如果需要完全自定义前向传播(例如修改 Loss 计算),请重写此方法。
"""
return super().forward(input_ids, ...)2. 注册模型
在 mindspeed_llm/fsdp2/models/model_registry.py的ModelRegistry 中添加映射。
# model_registry.py
from mindspeed_llm.fsdp2.models.qwen3_next.modeling_qwen3_next import Qwen3NextForCausalLM
_REGISTRY = {
"gpt_oss": GptOssForCausalLM,
# 新增注册
"qwen3_next": Qwen3NextForCausalLM,
}3. 启动配置
需要显式指定 model_id。
# ./examples/fsdp2/qwen3_next/tune_qwen3_next_fsdp2.yaml
model:
model_name_or_path: "/path/to/qwen3_next_weights"
model_id: "qwen3_next" # <--匹配注册后的自定义模型
四、 快速上手-基于FSDP2训练后端的MindSpeed LLM套件完成Qwen3-Next-Coder模型训练
环境准备
git clone https://gitcode.com/Ascend/MindSpeed-LLM.git
# 安装mindspeed及依赖
git clone https://gitcode.com/Ascend/MindSpeed.git
cd MindSpeed
cp -r mindspeed ../MindSpeed-LLM/
cd ../MindSpeed-LLM
pip install -e .
# 安装其它依赖
pip3 install -r requirements.txt数据与权重
1.下载 Hugging Face 格式的预训练权重。
2.数据集配置
支持两种配置方式,推荐使用 dataset_info.json 注册方式便于多数据集混合训练。
方式一:内联配置(适用于单数据集快速验证)
data:
dataset:
file_name: "./my_data.json" # 数据文件路径
formatting: "alpaca" # 数据格式模板,支持alpaca/sharegpt等格式
cutoff_len: 2048 # 分词后输入序列的截断长度,超过该长度的序列会被截断方式二:通过 `dataset_info.json` 注册
1. 编辑 `configs/fsdp2/data/dataset_info.json`,添加数据集条目:
{
"alpaca_full": {
"file_name": "./train-00000-of-00001.parquet"
},
"sharegpt4_zh": {
"file_name": "./sharegpt_zh.jsonl",
"formatting": "sharegpt"
}
}2. 在 YAML 配置中引用:
data:
dataset: alpaca_full, sharegpt4_zh # 训练数据集:可填写逗号分隔的数据集名称,支持多数据集混合
template: qwen3 # 训练/推理阶段构建prompt的模板名称
cutoff_len: 2048 # 分词后输入序列的截断长度,超过该长度的序列会被截断启动训练
只需一条命令即可启动。框架会根据yaml配置文件自动处理分布式环境初始化。在仓库根目录执行:
bash examples/fsdp2/qwen3_next/tune_qwen3_next_fsdp2.sh五、结语
MindSpeed LLM FSDP2让分布式训练回归简单。无论是直接复用社区生态,还是深度定制硬件优化,MindSpeed LLM都提供了最佳实践。
欢迎开发者体验、贡献与共建!
· MindSpeed LLM开源仓库:https://gitcode.com/Ascend/MindSpeed-LLM
· 昇腾开源微信小助手:ascendosc
注:FSDP2新后端已上线,欢迎尝鲜试用,框架性能仍在持续优化中。