



极速响应!MindSpeed LLM无缝适配Step-3.5-Flash,解锁大规模MOE模型落地新可能
发表于: 2026/02/10
开源大模型进入“高参高效”追逐时代,适配速度直接决定落地节奏。2月2日,搭载稀疏MoE架构、总参量达196B的Agent级旗舰模型Step-3.5-Flash正式开源,凭借优异性能迅速成为开发者焦点。MindSpeed LLM(大语言模型套件)快速完成全流程适配,结合专家并行(EP)优化、FSDP2后端支持及meta-device虚拟初始化等特性,让这款大参数量模型高效训练、一键部署。
1、开源即适配+FSDP2后端,一键拉起无需预处理
MindSpeed LLM始终以“快速响应、易用高效”为核心,此前已支持120+主流大模型。此次Step-3.5-Flash开源后,团队第一时间完成适配,更依托FSDP2后端特性,实现模型“一键拉起”:
· 无需权重转换
· 无需额外数据预处理
· 无需手动切分参数
· 无需深入底层调试
调用框架即可直接开展预训练,大幅缩短开发周期,真正实现“拿来就用、快速迭代”。
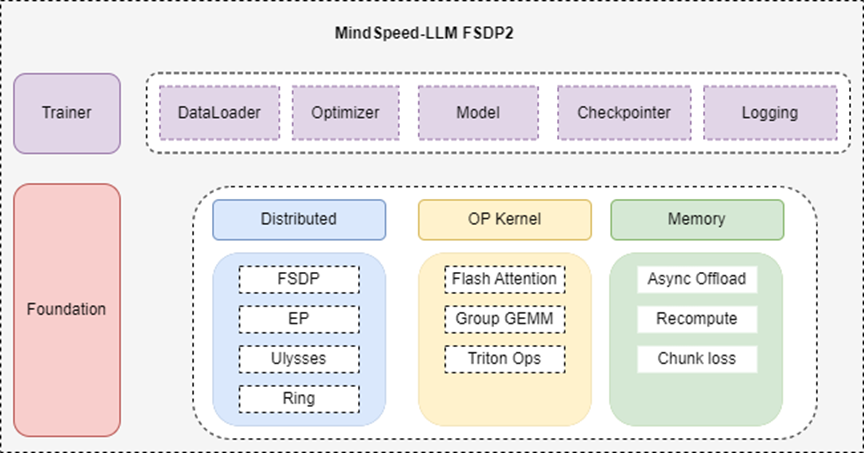
2、基于MindSpeed LLM的Step-3.5-Flash模型训练优化特性
MoE 模型因海量专家参数与稀疏激活的特性,面临单卡显存爆炸、计算负载失衡、传统并行通信冗余的痛点,存在训练扩展性差、算力利用率低、大规模训练难落地的挑战,同时大规模参数量的模型在训练时易出现OOM内存溢出问题。Step-3.5-Flash 196B同样面临此类问题,昇腾团队在首次部署该模型时遇到OOM内存溢出和训练任务卡死等问题,通过引入专家并行(EP)技术,并结合使用meta-device虚拟初始化技术,从而模型得以正常训练,同时训练过程设备还能有22%的可用内存。
专家并行(EP)+MoE优化,释放大参数量模型潜能
Step-3.5-Flash作为稀疏MoE模型,对并行能力和内存管理提出了极高要求。针对这一特性,MindSpeed LLM 进行了针对性优化:
- 专家并行(EP):显著降低单卡显存压力
- FSDP 混合并行策略:将 196B 参数高效切分至多设备
- 内存深度优化:整体显存占用降低 30%+,训练更加稳定
依托EP能力,MindSpeed LLM 充分发挥 Step-3.5-Flash「总参数量大、激活参数量小」的架构优势,解决单设备承载难、训练效率低的痛点,同时通过内存优化降低30%+占用,保障训练稳定,实现“大参量能力+轻量化训练”。
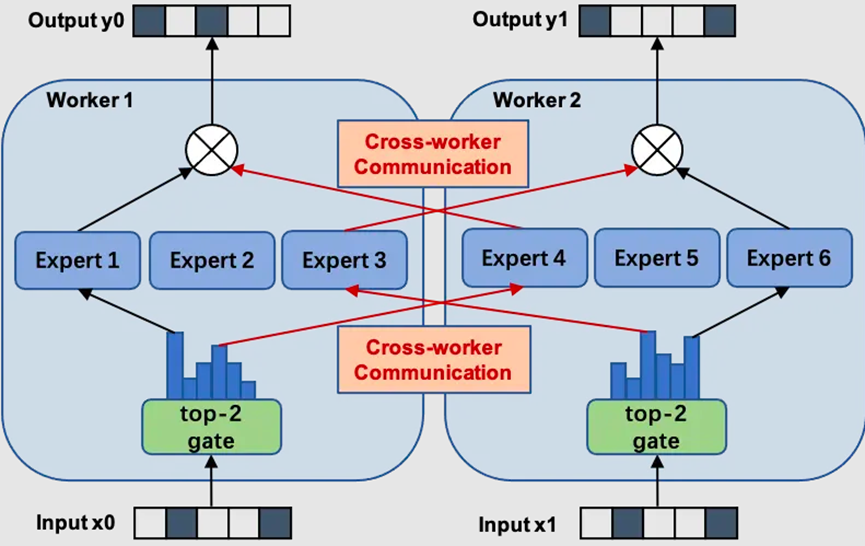
图1 专家并行(EP)切分示意图
(图源https://github.com/wdndev/llm_interview_note)
meta-device虚拟初始化,从根源规避大参量模型OOM
针对Step-3.5-Flash 196B超大参量训练中的内存溢出(OOM)核心痛点,MindSpeed LLM通过meta-device深度适配给出高效解决方案:
- meta-device 仅承载模型结构与参数形状信息
- 不加载真实权重数据
- 不占用显存或内存资源
在训练初始化阶段,框架将基于 meta-device:
- 完成空模型构建
- 自动规划权重切分策略
- 启用分片权重 延迟加载机制
无需一次性加载 196B 全量参数,即可从根源规避 OOM 风险,同时完全免去开发者对参数初始化与切分的手动干预,兼顾稳定性与易用性,满足超大参数量模型训练需求。
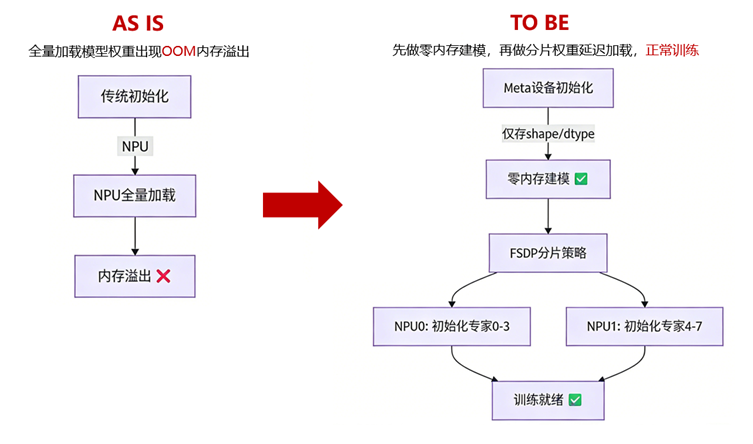
图2 meta-device使用前后的内存资源使用对比
3、一键部署Step-3.5-Flash 训练,赋能开发者高效开发
作为昇腾生态核心训练框架,MindSpeed LLM此次快速适配Step-3.5-Flash,不仅充分验证了自身在大参数量模型适配领域的硬实力,更通过FSDP2后端、专家并行(EP)、meta-device虚拟初始化等多重优化,彻底补齐大模型“难训练、难落地”的行业短板,让196B参量MOE模型的训练门槛大幅降低。框架已同步提供 Step-3.5-Flash 在 MindSpeed LLM 中的适配说明与一键训练示例,相关配置与使用方法详见:https://modelers.cn/models/MindSpeed/Step-3.5-Flash
开发者可直接通过框架内置脚本快速启动训练,无需复杂配置,仅需运行指定训练脚本:
1)环境搭建
请参考MindSpeed LLM安装指导文档:https://gitcode.com/Ascend/MindSpeed-LLM/blob/master/docs/pytorch/install_guide.md
git clone https://gitcode.com/Ascend/MindSpeed_LLM.git
# 安装mindspeed及依赖
git clone https://gitcode.com/Ascend/MindSpeed.git
cd MindSpeed
cp -r mindspeed ../MindSpeed_LLM/
cd ../MindSpeed_LLM
pip install -e .
# 安装其它依赖
pip3 install -r requirements.txt2)权重下载
从HuggingFace或魔乐社区下载权重和配置文件
huggingface | https://huggingface.co/stepfun-ai/Step-3.5-Flash |
魔乐社区 | https://modelers.cn/models/StepFun/Step-3.5-Flash |
3)运行训练脚本
cd MindSpeed-LLM
bash examples/fsdp2/step35/pretrain_step_3p5_flash_196b_4K_fsdp2.sh经过上述简单步骤即可一键调用FSDP2后端、专家并行等优化特性,自动完成meta-device初始化与权重分片加载,轻松开启Step-3.5-Flash高效训练,解锁大参数量MOE模型的无限创新可能,奔赴AI训练技术创新风口!
4、结语
本期为大家介绍了基于MindSpeed LLM部署高效部署Step-3.5-Flash模型训练,更多关于大语言模型训练的能力和技术,欢迎开发者体验、贡献与共建!
· MindSpeed LLM开源仓库:https://gitcode.com/Ascend/MindSpeed-LLM
· 昇腾开源微信小助手:ascendosc