



MindSpeed MM全新支持FSDP训练后端,开启多模态模型训练敏捷创新
发表于: 2026/02/03
随着多模态AI应用日渐普及,大模型的高效训练已成为技术发展的核心挑战。然而,现有训练框架在扩展性、易用性和效率上均有不足,制约了模型开发效率和算法创新。为此,昇腾MindSpeed MM多模态模型套件正式支持FSDP训练后端,以直观设计、灵活扩展和高效部署为核心优势,致力于显著降低多模态模型的开发与调优门槛,助力AI技术更广泛、更深入地赋能千行百业。本文将以近期刚开源的先进语音大模型Qwen3-TTS为例,展示MindSpeed MM基于新FSDP训练后端对新模型的高效适配和快速迁移。
1 MindSpeed MM全新支持FSDP训练后端的核心亮点
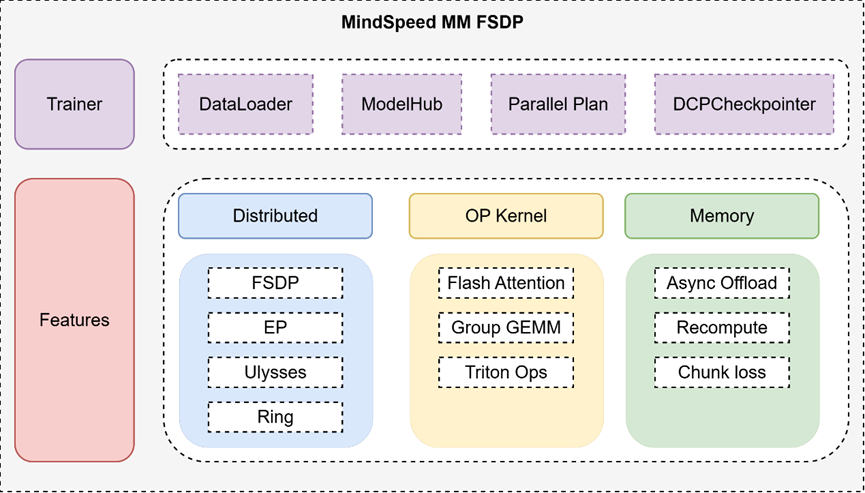
图1 MindSpeed MM FSDP训练后端介绍
MindSpeed MM构建了一套基于FSDP训练后端的全新分布式多模态模型训练套件,区别于Megatron训练后端,该框架通过解耦并行策略与模型结构的设计,支持FSDP、EP、CP三维并行能力的灵活组合,显著降低了大模型训练的工程复杂性与配置成本。框架具备跨硬件平台支持能力,可高效运行于多种计算设备,确保在不同硬件环境下的训练效率。在性能优化方面,MindSpeed MM通过融合算子与显存管理技术,大幅提升了训练吞吐与资源利用效率。
相比较原有框架,全新FSDP训练后端的MindSpeed MM套件具有以下核心优势:
1)轻量化:解耦模型结构与并行策略,支持Hugging Face等三方模型,通过简单YAML配置即可启用分布式训练,大幅降低工程门槛;
2)多维并行:支持FSDP、EP、CP三维并行能力的灵活组合,支撑长序列、千亿参数规模大模型高效训练;
3)极致性能:提供昇腾亲和算子库、chunk loss、异步offload等计算优化、内存优化、通信加速等能力,大幅提升训练效率;
4)直观代码设计:提供端到端的预训练/微调功能,消减复杂臃肿的权重转换和环境依赖,提高二次开发和算法创新效率。
2 基于FSDP训练后端,MindSpeed MM套件针对新模型适配周期从周级降到天级
前不久,Qwen开源发布语音功能强大的Qwen3-TTS系列语音模型,凭借Qwen3-TTS-Tokenizer-12Hz多码本语音编码器,实现高效声学压缩与高维语义建模,完整保留环境特征,并采用轻量级非DiT架构,达成端到端流式生成仅97ms的低延迟,支持实时交互。该模型通过离散多码本语言模型实现全信息端到端语音建模,突破传统“LM+DiT”架构的信息瓶颈。支持10种主流语言及方言,具备强大的上下文理解与抗噪鲁棒性,能够通过自然语言指令灵活控制音色、情感与语调,真正实现“你所想象的,便是你所听到的”。
图2 Qwen3-TTS模型结构图
MindSpeed MM多模态套件首次实现对该模型进行高效适配,直接导入开源模型数据和模型,通过YAML文件配置训练流程和使能并行方式,快速支持模型训练功能,相较原有基于Megatron训练后端的周级开发周期,基于FSDP训练后端的新版套件两天内即可完成功能适配和效果对齐,充分验证MindSpeed MM全新FSDP训练后端的多模态套件在新模型支持上的高易用性和扩展性。
3 快速上手-基于新FSDP训练后端的MindSpeed MM套件完成Qwen3-TTS模型训练
3.1 环境安装
1)环境准备
模型开发时推荐使用配套的环境版本,请参考安装指南:https://gitcode.com/Ascend/MindSpeed-MM/blob/master/docs/user-guide/installation.md
2)环境搭建
详细信息可参考文档:环境搭建
git clone --branch fsdp2_dev https://gitcode.com/Ascend/MindSpeed-MM.git
# 安装mindspeed及依赖
git clone https://gitcode.com/Ascend/MindSpeed.git
cd MindSpeed
cp -r mindspeed ../MindSpeed-MM/
# 安装mindspeed mm及依赖
cd ../MindSpeed-MM
pip install -e .
# 安装其它依赖
pip install -r examples/fsdp2/qwen3tts/requirements.txt3.2 数据预处理
1)分词器准备
从Hugging Face库或ModelScope库下载对应的Tokenizer文件:
社区 | 下载地址 |
Hugging Face | https://huggingface.co/Qwen/Qwen3-TTS-Tokenizer-12Hz |
ModelScope | https://modelscope.cn/models/Qwen/Qwen3-TTS-Tokenizer-12Hz |
下载后将Tokenizer文件保存到本地目录下。
2)数据准备
以KAN-TTS数据集为例,下载KAN-TTS开源数据集文件,下载地址:https://modelscope.cn/datasets/modelscope/DAMO.NLS.KAN-TTS.OpenDataset/files
运行以下解压和数据格式转换脚本:
# 执行解压命令
unzip -o opentts_data.zip -d opentts_data
# 执行数据格式转换脚本
python examples/fsdp2/qwen3tts/process_data.py \
--opentts_data_path opentts_data \
--output_jsonl_path train_raw.jsonl \
--ref_audio_path ref_audio.wav \
# 其中:
# opentts_data_path: tts数据集路径
# output_jsonl_path:转换后数据文件的保存路径
# ref_audio_path:参考音频文件路径,若参数不存在或参考音频不存在,则从数据集中随机选择一条数据作为参考音频通过上述转换脚本将原始数据文件处理为JSONL格式的train_raw.jsonl文件,每行为一个JSON对象,包含以下字段:
字段 | 内容 |
audio | 目标训练音频文件路径,支持wav格式,频率仅支持24kHz |
text | 目标训练音频对应的文本内容 |
ref_audio | 参考音频文件路径,支持wav格式 |
转换后示例如下:
{"audio":"/opentts_data/000001.wav","text":"有一回来个参观团,是县文物局组织的。","ref_audio":"/opentts_data/ref.wav"}
{"audio":"/opentts_data/000002.wav","text":"基础设施是产业发展的前提。","ref_audio":"/opentts_data/ref.wav"}3)数据转换
运行以下脚本将 train_raw.jsonl 转换为包含音频编码audio_codes的训练集JSONL文件train_with_codes.jsonl :
# 设置环境变量
export NON_MEGATRON=true
source /usr/local/Ascend/ascend-toolkit/set_env.sh
python examples/fsdp2/qwen3tts/prepare_data.py \
--device npu:0 \
--tokenizer_model_path /Qwen3-TTS-Tokenizer-12Hz \
--input_jsonl train_raw.jsonl \
--output_jsonl train_with_codes.jsonl \
# 其中:
# device:数据转换的设备
# tokenizer_model_path:tokenizer文件路径
# input_jsonl:包含训练音频文件路径、对应文本内容和参考音频文件路径的JSONL文件路径
# output_jsonl:转换后数据文件的保存路径处理后示例如下:
{"audio":"/opentts_data/000001.wav","text": "有一回来个参观团,是县文物局组织的。","ref_audio": "/opentts_data/ref.wav","audio_codes": [[1995, ..., 901]]}
{"audio":"/opentts_data/000002.wav","text": "基础设施是产业发展的前提。","ref_audio": "/opentts_data/ref.wav","audio_codes": [[1995, ..., 901]]}3.3 开始训练
1)权重准备
从Hugging Face库下载Qwen3-TTS-12Hz-1.7B-Base模型文件,下载地址: https://huggingface.co/Qwen/Qwen3-TTS-12Hz-1.7B-Base
下载后将模型文件保存到本地目录下。
2)启动训练
在qwen3tts_config.yaml文件中配置好数据集和权重之后,使用如下命令,即可实现Qwen3-TTS的训练:
bash examples/fsdp2/qwen3tts/finetune_qwen3tts.sh4 结语
大模型向大参数量、多模态、长上下文持续演进,分布式训练也从专家技术逐步成为普惠工具。面向未来的训练框架,需平衡极致性能与易用性,既支撑千亿级参数高效扩展,也让算法工程师摆脱并行技术细节,专注模型创新。MindSpeed MM多模态模型套件正在落地这一理念,轻量、通用且亲和兼容PyTorch生态,让模型研发回归本质。我们将融合前沿并行策略、智能显存优化与硬件加速能力,在昇腾平台打造敏捷流畅的大模型训练基座,赋能开发者轻松拥抱智能未来。
欢迎开发者体验、贡献与共建!
· MindSpeed MM开源仓库:https://gitcode.com/Ascend/MindSpeed-MM
· 昇腾开源微信小助手:ascendosc