



MindSpeed全面支持FSDP训练后端,让昇腾训练“轻装上阵”更高效
发表于: 2026/01/31
当前,超大规模模型训练中,分布式框架易用性与性能往往难以兼顾。Megatron 3D并行性能强劲,但需侵入式修改代码、调参繁琐,让开发者陷入底层工程细节,开源生态对轻量化、低适配成本的方案需求迫切。昇腾MindSpeed训练加速库全面支持FSDP训练后端,以模型无感知设计破局,无缝亲和PyTorch生态,依托FSDP、专家并行、上下文并行、显存优化等技术,兼顾低显存与高效能,灵活适配多场景,开发者专注模型创新,使能昇腾训练好用易用。
1 大模型分布式训练框架从“模型侵入式+精细调优”走向“模型无感+轻量化”
当前开源大模型生态以 Hugging Face Transformers 为核心,训练聚焦微调与强化学习,对框架的易用性、泛化能力与适配成本提出更高要求。Megatron 虽性能优异,但依赖复杂的 3D 并行策略,需深度侵入式改造与精细调参,显著抬高使用门槛,制约算法创新效率。相比之下,基于 ZeRO-3 的 PyTorch FSDP 以“低侵入、高兼容”脱颖而出:仅需简单封装即可启用分布式训练,自动分片参数、梯度与优化器状态,显著降低显存占用,同时保持单卡代码结构。
随着 FSDP2的技术演进,FSDP已成为 LlamaFactory、TorchTitan 等主流项目的首选。构建轻量、灵活且兼容 HF 生态的 FSDP 训练后端,正成为提升大模型研发效率的关键路径。
Megatron 3D并行和FSDP对比
Megatron 3D并行 | FSDP | |
开发难度 | 需要进入模型代码修改 | 开箱即用 |
通信量 | 通信量正比于bsh,一般TP走高速通信域HCCS/NCCL,PP、EP走RoCE | 在DP域内Allgather所有参数,通信量随参数量增大,通信耗时受节点间带宽约束 |
负载不均衡的影响 | EP打开后专家间负载分配不均衡,对显存和计算的影响大 | 只要求DP域负载均衡,专家间负载均衡只影响GMM效率 |
多模态场景 | ViT和LLM组PP,stage间负载不均衡,空泡率大 | 只要求DP域负载均衡,不同模态之间互不影响 |
2 基于FSDP训练后端的MindSpeed训练加速库架构全景
2.1 MindSpeed FSDP:轻量、泛化、高性能三位一体的训练后端
MindSpeed作为昇腾训练加速库,长期以来提供类似 Megatron 的 3D 并行策略,有效支撑了客户的大模型训练业务。为进一步提升易用性与模型泛化能力,全新支持 FSDP 训练后端,以“模型无感知+轻量化”为核心设计,重塑分布式训练体验。
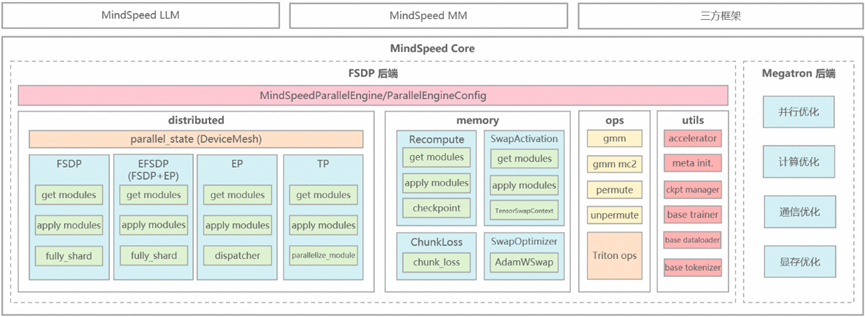
MindSpeed FSDP 训练后端并非开源 FSDP 的简单复刻,而是面向大模型全训练场景、深度亲和 PyTorch 生态的轻量化训练底座,凭借三大核心亮点打造差异化优势,精准平衡易用性、泛化性与高性能。
l 轻量无侵入:原生无缝兼容 PyTorch 生态,无需依赖 Megatron 等重型框架,开发者无需修改模型代码、无需关注底层分布式细节,仅通过 YAML 配置即可启用分布式加速,大幅降低适配与调试成本;
l 泛化强兼容:采用高内聚低耦合架构,按维度模块化拆解各类加速能力,遵循统一 “模块获取 — 模块使能” 范式,可灵活组合调用,无缝适配大语言模型、多模态、MoE 等复杂场景,单底座覆盖预训练、微调等全训练链路;
l 全维度性能优化:原子化封装 FSDP、EP、CP、显存优化、通信加速等能力,支持用户按需灵活组合,在易用性与极致性能间取得最佳平衡。
MindSpeed FSDP 无缝对接 Hugging Face、LLaMA-Factory 等主流开源生态,上层套件与后端能力深度融合,实现模型加载、训练到部署的全链路高效协同,助力大模型训练低门槛、高效率落地。
2.2 组合泛化的高性能加速引擎
MindSpeed FSDP构建了一套原子化、可组合的高性能加速引擎。开发者可根据模型规模、硬件资源和训练场景,灵活启用所需能力,无需耦合冗余逻辑。
(1)FSDP核心能力
作为MindSpeed FSDP后端的基础能力,其沿用PyTorch ZeRO-3核心思想,实现模型参数、梯度及优化器状态的自动分片存储。相较于传统DDP(Distributed Data Parallel,分布式数据并行),该特性无需手动配置分片逻辑,仅在计算时通过按需通信聚合参数,计算后立即释放资源,既大幅降低单卡显存占用,又能实现通信与计算掩盖,在保障性能的同时延续了后端易用性优势。
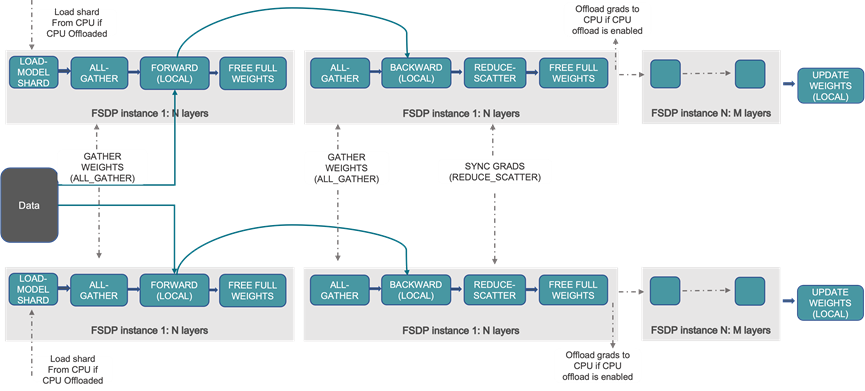
FSDP方案[1]
(2)EP专家并行优化
针对MoE模型训练的通信开销瓶颈,MindSpeed FSDP后端提供两种高效EP方案,精准解决AllToAll通信耗时过高的问题。其中EP MC2融合算子依托昇腾自研alltoallv_gmm融合算子,通过细粒度通算协同、自适应矩阵切分及均衡调度策略,打破通信与计算的耦合壁垒;Domino EP则采用批次拆分与流水并行思路,以低限制、高可操作性设计,可快速适配现有模型框架,满足不同研发场景需求。
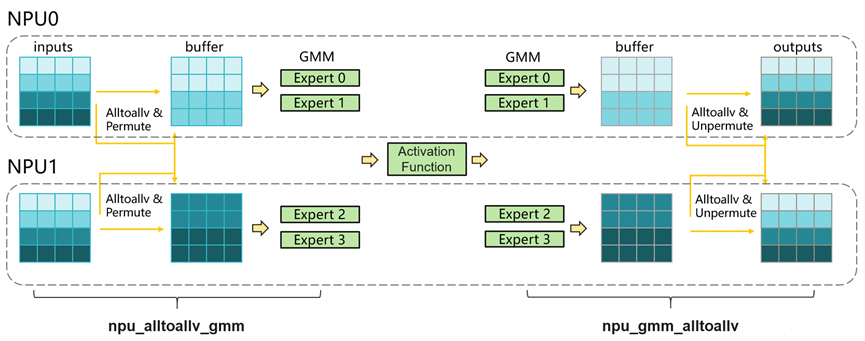
EP MC2方案
Domino EP方案[2]
(3)CP长序列优化
长序列场景下,Attention计算显存需求随序列长度呈平方级增长,极易引发单卡显存溢出,这是大模型训练的核心瓶颈之一。MindSpeed FSDP后端针对性集成三类CP策略,无需侵入式修改模型代码,即可灵活适配不同硬件配置与序列长度需求,兼顾泛化性与易用性,突破单个硬件设备对可处理序列长度的限制。
CP策略 | 通信 | 特点 |
Ulysses | All-to-All | 对切分后的query、key和value执行all-to-all通信,以便每个计算设备接收完整的序列,以并行计算不同的注意力头 |
Ring Attention | P2P | 采用环形拓扑设计,设备间通过P2P通信,按顺序传递和交换计算注意力所需的key和value块 |
KVAllGather-CP | AllGather | 对已分片的key和value执行all-gather通信操作,使每个设备都能获取完整的key和value序列 |
(4)多维显存优化
显存资源紧张是制约大模型训练规模与效率的关键瓶颈,尤其激活值堆积、优化器状态占用、大词表损失计算引发的显存峰值,易导致训练中断。MindSpeed FSDP后端针对性打造三大显存优化特性:
l SwapActivation采用异步卸载与多流并行机制,智能筛选高价值激活值跨设备调度,隐藏数据迁移开销;
l SwapOptimizer将FP32精度的优化器状态存于主机内存,通过三级流水线并行实现按需加载与回传,大幅降低显存占用;
l ChunkLoss针对多模态大词表场景,按序列分块执行损失计算并即时释放显存,有效缓解大词表与超长序列带来的显存压力和内存碎片问题。
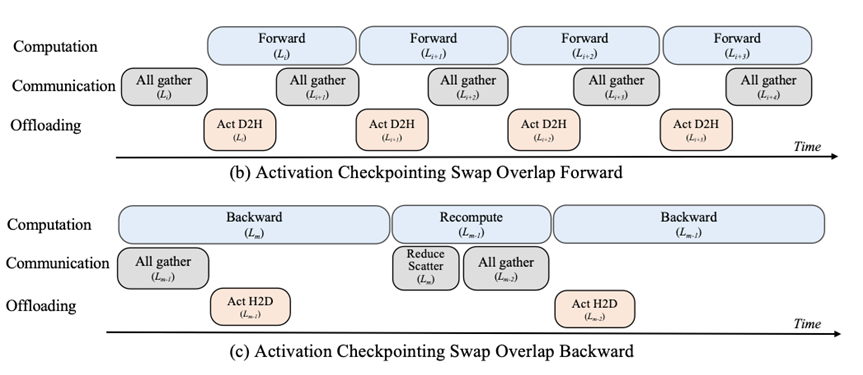
SwapActivation方案
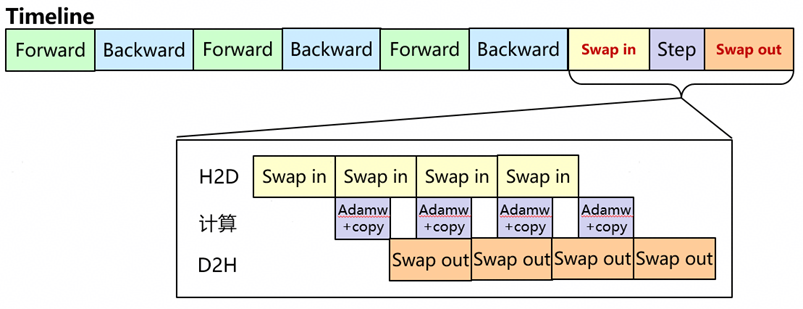
SwapOptimizer方案
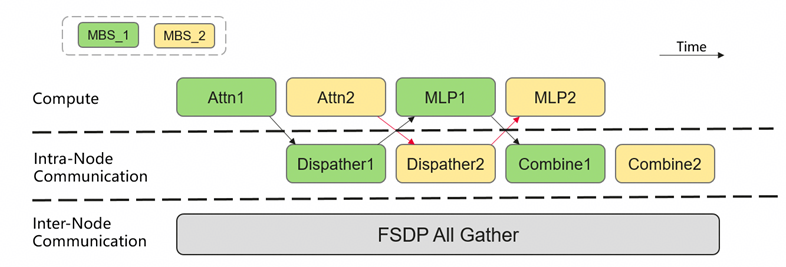
(5)通信优化增强
ChunkBatchSize特性作为通信优化的关键补充,通过微批次拆分机制提升通信性价比。该特性将输入切分为独立微批次,单次参数聚合通信即可支撑多微批次计算,同时通过即时释放激活值节省显存,既解决单层参数过大导致的显存受限问题,又强化计算对通信的掩盖能力,显著提升整体训练吞吐量。
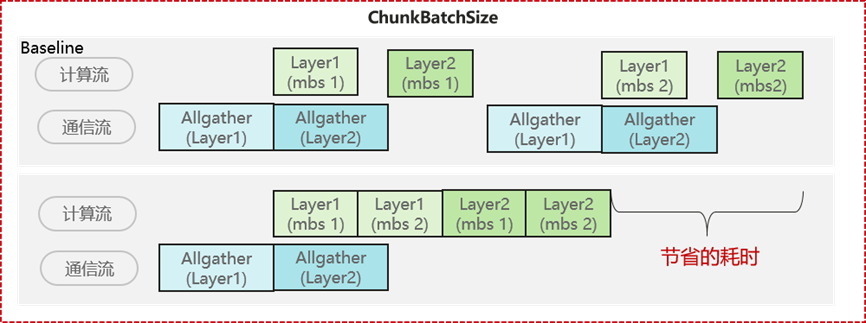
ChunkBatchSize方案
2.3 开箱即用的模型训练套件
依托 MindSpeed FSDP 轻量化训练后端,昇腾推出两大开箱即用的模型训练套件——MindSpeed LLM(大语言模型套件) 与 MindSpeed MM(多模态模型套件),全面覆盖主流大模型训练场景,真正实现“无需改码、配置即训”。
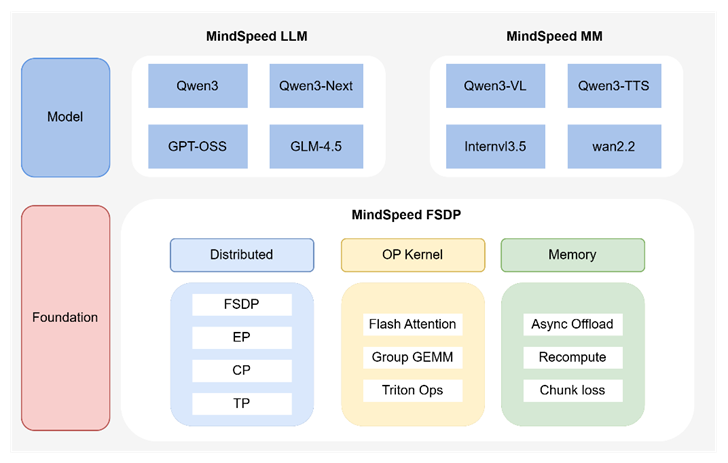
MindSpeed LLM 深度集成 Hugging Face 生态,通过 ModelFactory、DataFactory 及 OptimizerFactory 三大核心组件,实现训练全链路解耦重构。开发者仅需编写一份 YAML 配置文件,即可在不修改任何模型代码的前提下,自动注入 FSDP 分布式训练能力。
MindSpeed MM 则面向多模态大模型,构建了一套灵活高效的分布式训练框架。它解耦并行策略与模型结构,支持 FSDP、EP、CP的自由组合与动态编排,适配任意模态架构。框架具备跨硬件平台支持能力,可高效运行于多种计算设备,确保在不同硬件环境下的训练效率。
两大套件均以 MindSpeed FSDP 为统一底座,共享轻量、泛化、亲和PyTorch 的技术基因,让开发者从“调并行”回归“做模型”,加速大模型创新落地。以MindSpeed LLM模型套件库为例,其支持基于Hugging Face权重自动构建模型--用户只需配置权重路径,即可实现Hugging Face模型的开箱即用,其中模型构建部分仅需一行代码:
model = AutoModelForCausalLM.from_pretrained(
model_args.model_name_or_path,
config=hf_config,
trust_remote_code=trust_remote_code,
torch_dtype=torch.float32,
low_cpu_mem_usage=True,
device_map="cpu"
)3 MindSpeed FSDP训练后端的进展与计划
MindSpeed FSDP 训练后端已完成核心训练底座搭建,全面支持 Hugging Face 模型开箱即用,并彻底解耦 Megatron 等重型依赖。
在功能层面,当前版本已稳定支持:
l 长序列优化:Ulysses、Ring Attention、KVAllGather-CP 三种策略均已上线,灵活应对长序列训练需求;
l 显存优化:SwapActivation、SwapOptimizer、ChunkLoss特性全面启用,有效缓解显存压力。
针对FSDP的高阶特性,将在26H1优先完成全量适配与上线,使能训练高性能:
l 并行与通信优化:加速推进EP MC2、Domino EP方案的落地,实现 ChunkBatchSize 通信优化特性的集成;
l 硬件协同优化:全量接入 GMM、Permute/Unpermute 等融合算子,构建昇腾训练专属Triton算子库;
l 生态协同优化:持续拓展主流开源模型适配覆盖范围,强化与上层模型套件的联动能力,构建“后端能力完备、生态适配广泛”的大模型训练加速库方案。
4 结语
随着模型向更大规模、更多模态、更长上下文演进,MindSpeed将持续投入,不断融合前沿并行策略、显存优化与硬件加速能力,打造昇腾平台上最敏捷的大模型训练底座。
欢迎开发者体验、贡献与共建!
l 开源仓库:
https://gitcode.com/Ascend/MindSpeed
https://gitcode.com/Ascend/MindSpeed-LLM
https://gitcode.com/Ascend/MindSpeed-MM
l 昇腾开源微信小助手:ascendosc
参考资料
[1] https://docs.pytorch.org/tutorials/intermediate/FSDP_tutorial.html
[2] https://github.com/InternLM/xtuner