



VeOmni全面支持昇腾,加速全模态大模型训练创新
发表于: 2026/01/27
近来,大语言模型正从单模态向全模态统一理解与生成革命性跃迁,全模态大模型成为 AI 技术与产业落地的核心赛道,高效训练框架是撬动变革的关键基石。VeOmni 作为全模态开源训练框架,以「模型为中心」分布式设计,直击大模型训练 “并行策略与模型结构紧耦合” 行业痛点,大幅降低工程复杂度与资源开销,兼具灵活性与易用性,是全模态训练的标杆级基础设施。昇腾全面拥抱业界开源生态,高效落地 FSDP/EP/SP等多维并行能力,使能VeOmni原生支持昇腾,为全模态大模型在昇腾平台训练提供高效、可靠的保障。
知识热身-VeOmni框架和Qwen3-VL模型简介
1、VeOmni框架介绍
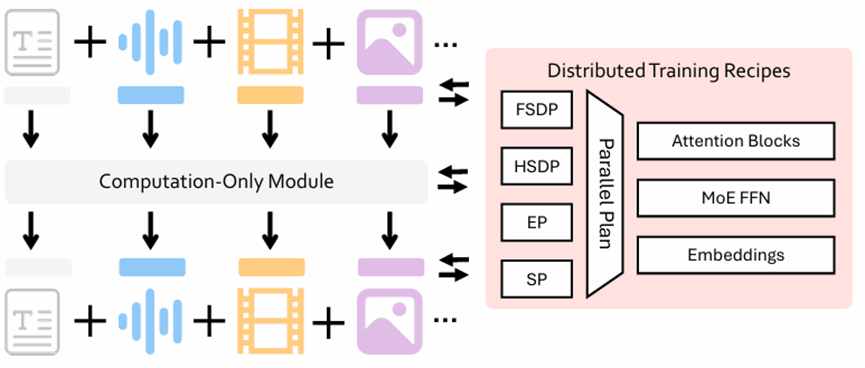
图1 VeOmni的架构图
图片来:https://arxiv.org/pdf/2508.02317
VeOmni是面向全模态大模型训练的开源框架,采用模块化即插即用架构,能够统一处理图像、音频、文本等多种模态数据,并创新性地提出将并行策略与模型结构解耦,支持FSDP、SP、EP等策略的灵活组合,帮助开发者专注于模型创新,同时保持训练过程的高效性与可扩展性。
VeOmni框架的核心特征如下:
· 灵活性和模块化:采用模块化设计,支持用户使用解耦组件,根据自身需要使用和替换组件。
· 全模态模型原生支持:用户能够轻松地跨设备和加速器扩展全模态模型。
· Torch 原生功能:充分利用 PyTorch 的原生功能,确保最大的兼容性和性能。
2、Qwen3-VL介绍
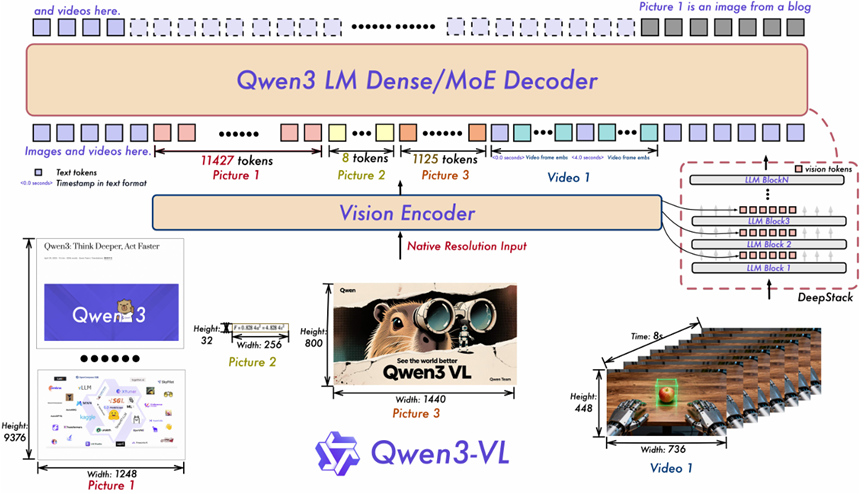
图2 Qwen3-VL模型结构图
图片来源:https://arxiv.org/pdf/2511.21631
Qwen3-VL模型沿用了Qwen2.5-VL的三组件架构:视觉编码器、视觉–语言融合器以及大语言模型,并在此基础上进行了三项关键改进:它采用动态分辨率的SigLIP-2视觉编码器增强图像适应性;通过DeepStack跨层融合机制,将多级视觉特征注入语言模型以提升细粒度理解;针对视频任务,用交错式旋转位置编码和显式文本时间戳替代传统方案,显著优化了长视频建模与时间定位能力。这些架构升级使其成为更强大的多模态基础模型。
VeOmni支持昇腾的特性进展与规划
1、已支持模型
模型列表 | 模型尺寸 |
Wan2.1 | 14B |
Qwen2.5-VL | 7B |
Qwen3 | 8B-Dense |
30B-Moe | |
Qwen3-VL | 8B-Dense |
30B-Moe |
2、已支持特性
为保证大模型训练的高效性,昇腾在VeOmni框架下已支持多项关键技术特性。下表汇总了在并行策略、内存优化、算子优化及数据策略等方面的具体实现,旨在最大化资源利用率,突破内存瓶颈,提升整体训练性能:
特性类型 | 特性名称 |
训练后端 | FSDP |
FSDP2 | |
并行策略 | EP |
Ulysses CP | |
Async Ulysses CP | |
内存优化 | FSDP offload、激活值offload、细粒度offload |
重计算 | |
算子优化 | RMS Norm、ROPE、GMM等融合算子 |
数据策略 | Dynamic batching |
Omnidata processing | |
性能监测 | profiling |
显存快照 |
3、规划中的特性
昇腾致力于提供高效的端到端解决方案,一方面紧跟前沿,确保主流模型快速可用;另一方面夯实后端,支持LoRA微调与后训练,保证模型输出更好地契合实际场景。
特性类别 | 特性名称 |
模型支持 | Qwen3 Next、Qwen3 Omni、Wan 2.2、InternVL3.5 |
微调能力支持 | LoRA微调 |
强化学习后训练支持 | veRL训练引擎 |
训练性能优化 | ViT数据负载均衡 |
快速上手-在昇腾上部署基于VeOmni框架的Qwen3-VL模型训练
为了快速体验VeOmni框架的训练流程,下面以Qwen3-VL模型为例,展示完整的端到端操作步骤。
1、环境安装
详细按照步骤见如下链接:
https://veomni.readthedocs.io/en/latest/get_started/installation/install_ascend.html
通过上述步骤安装完成后,Qwen3-VL 训练的基础环境配置如下:
软件名称 | 软件版本 |
Python | == 3.11 |
CANN | == 8.5.0 |
torch | == 2.7.1 |
torch_npu | == 2.7.1 |
transformers | == v4.57.3 |
2、数据准备
可自行下载coco数据集,并将coco数据放到VeOmni代码仓根目录下,层级如下:
VeOmni
├── coco
│ └── train2017
│ ├── 000000000009.jpg
│ ├── 000000000025.jpg
│ ├── 000000000030.jpg
│ ├── 000000000034.jpg
│ └── ........
├── sharegpt4v_instruct_gpt4-vision_cap100k.json
│ ........(原仓代码)其中,sharegpt4v_instruct_gpt4-vision_cap100k.json从ShareGPT4V下载https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/tree/main,下载后按以下脚本处理VeOmni需要的数据格式:
import json
with open('sharegpt4v_instruct_gpt4-vision_cap100k.json', 'r', encoding='utf-8') as f:
data = json.load(f)
filtered_data = []
for item in data:
if item.get('image', '').startswith('coco'):
new_item = item.copy()
image_path = new_item.pop('image')
new_item['images'] = [image_path]
filtered_data.append(new_item)
with open('sharegpt4v_instruct_gpt4-vision_cap100k_coco.json', 'w', encoding='utf-8') as f:
json.dump(filtered_data, f, ensure_ascii=False, indent=4)3、开始训练
1)权重准备
Qwen3-VL 30B的权重可通过huggingface官网获取:https://huggingface.co/Qwen/Qwen3-VL-30B-A3B-Instruct
也可通过VeOmni权重下载脚本进行下载:
python3 scripts/download_hf_model.py \
--repo_id Qwen/Qwen3-VL-30B-A3B-Instruct \
--local_dir .2)启动训练
配置好数据集和权重之后,将如下启动脚本的对应路径加以更新,即可实现Qwen3-VL的训练:
bash train.sh tasks/omni/train_qwen_vl.py configs/multimodal/qwen3_vl/qwen3_vl_moe.yaml \
--model.model_path ./Qwen3-VL-30B-A3B-Instruct \
--data.train_path ./sharegpt4v_instruct_gpt4-vision_cap100k_coco.json \
--data.dataloader_type native \
--data.datasets_type iterable \
--data.source_name sharegpt4v_sft \
--data.num_workers 8 \
--train.micro_batch_size 34、训练效果
下图为 Qwen3-VL 模型的训练损失(Loss)曲线:其中红色曲线代表基于昇腾NPU的训练结果,蓝色曲线表示业界设备的训练结果。从Loss曲线特征可见,收敛趋势跟参考曲线高度一致,损失数值也基本吻合,表明在昇腾NPU上的训练效果跟业界相持平。
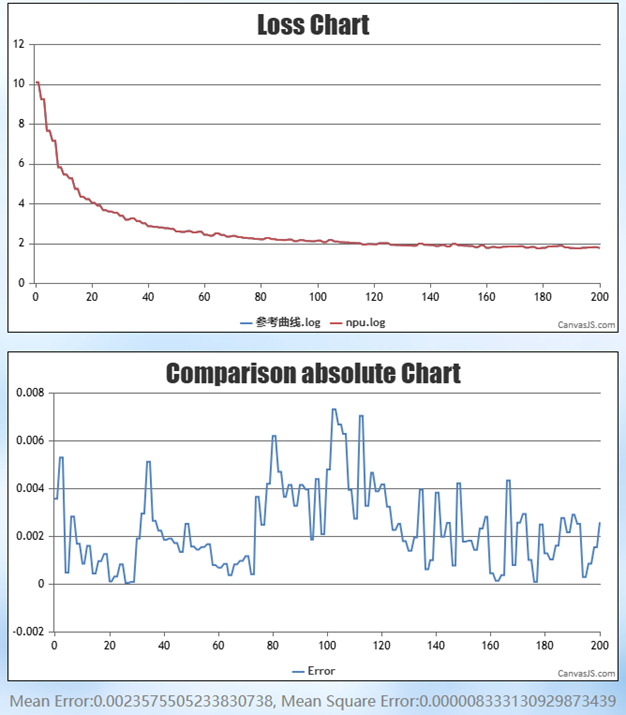
图3 训练过程Loss损失曲线
五、结语
昇腾团队跟随VeOmni社区路线规划,已构建NPU专用CI流水线与开箱即用Docker镜像,并为Qwen3-VL/Qwen3/Wan2.1等主流模型提供并行训练支持,同时实现多类昇腾优化融合算子以提升性能。未来,昇腾将持续增强VeOmni在昇腾设备上的技术竞争力,欢迎广大开发者积极参与体验。
VeOmni快速上手文档:
https://veomni.readthedocs.io/en/latest/
VeOmni昇腾开源镜像存储站点:
https://quay.io/repository/ascend/veomni
VeOmni昇腾支持:
https://veomni.readthedocs.io/en/latest/hardware_support/get_started_npu.html