



基于昇腾的“verl+Dense模型+DAPO”RL后训练性能优化实践
发表于: 2026/01/26
当前,SFT(有监督微调)与强化学习(RL)已逐渐成为大模型后训练的主流范式。其中,verl作为业界开源的大模型强化学习框架,持续受到热捧,截至发稿已在GitHub上获得15K星标和2.4K的Fork数。本文基于verl框架,针对Qwen2.5-32B稠密模型在昇腾A2硬件平台上开展DAPO强化学习后训练,并在平均回复长度为4K tokens的场景下,对推理和训练过程中的模型切分、任务下发、算子融合等关键环节进行了系统性优化。最终,端到端训练性能相较于开箱性能提升1.3倍,实现RL训练的高性能执行。
1、兼顾训练质量与效率的RL算法-DAPO
首先,我们来了解一下DAPO强化学习算法,相比GRPO,DAPO增加了一些训练优化技术,论文[1]显示取得了比GRPO更好的实验效果,为了便于理解后续的优化点,此处简单介绍DAPO算法的核心特点。
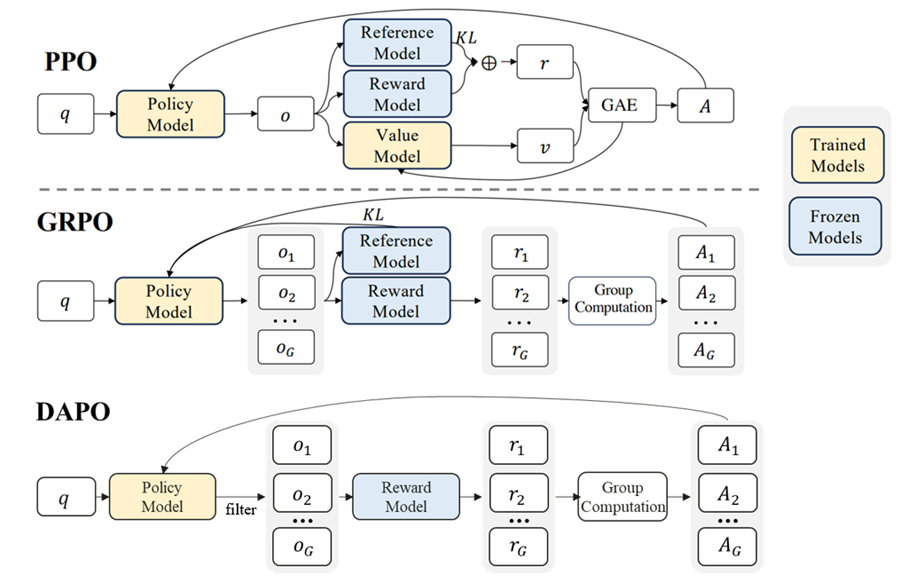
图1 PPO、GRPO、DAPO三种强化学习算法的流程对比图
DAPO算法的整体流程与GRPO基本相同,大致有如下几个步骤:
· 首先进行 rollout推理采样,采集满足训练样本数量要求的sample样本
· 动态采样筛选sample样本,去掉准确率为1和0的sample
· 对其余sample进行奖励reward计算
· 计算old logp值
· 利用reward 奖励模型计算样本组(o1,o2,…,oG)之间的优势值Adv
· 利用 Adv、old_logp 计算loss目标函数,更新模型参数。
对比 GRPO算法,DAPO算法主要作出了以下修改:
· 更高裁剪(Clip-Higher):把原本GRPO的 clip截断值进行上下阈值拆分,并提高上阈值,增加模型探索能力
· 动态采样:设定条件过滤采集的样本,筛掉模型回答太好,提高训练效率
· token级损失:计算目标函数时由对sequence序列内分别取平均改为对全局token取平均,增加长序列token对loss的影响,提升训练收敛速度
· 超长奖励塑造:重新定义对长序列训练中回答长度的奖励,避免回复过长的耗时取消了kl散度:不需要 reference参考模型来约束模型更新,节省训练资源。
· 取消了kl散度:不需要 reference参考模型来约束模型更新,节省训练资源。
2、基于DAPO RL训练的性能分析及优化结果
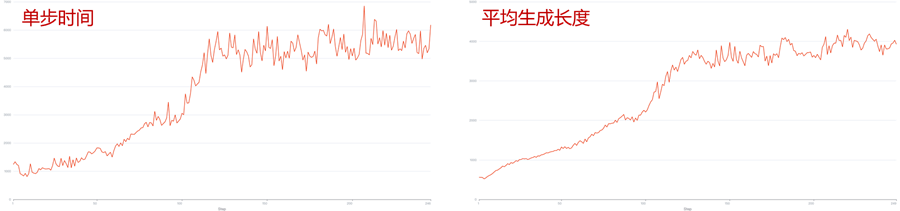
DAPO算法在收敛速度快,样本利用率高,但在实际RL训练过程中,回复长度越训越长,NPU显存容量会变成瓶颈,回复长度是1K时性能性对稳定,到了4K左右性能会劣化为业界设备的40%,需要进行性能分析和优化。下面我们将介绍优化过程:采集训练性能数据、分析性能瓶颈点、针对瓶颈点提出优化手段并验证。
2.1 性能瓶颈分析,拆解可优化点
Profiling性能数据采集和解析
由于VeRL使用Ray 分布式计算框架实现任务与资源调度,相比PyTorch 官方推出的分布式训练启动工具torchrun,verl使用的Ray无法在主循环内直接打点采集,许多人会碰到采不下来的情况,因此本节专门针对VeRL给出profiling采集方法。VeRL原仓合入了昇腾设备采集 profiling 工具,可直接参考使用说明:https://github.com/volcengine/verl/blob/main/docs/ascend_tutorial/ascend_profiling_zh.rst
准备好profiling工具后,我们进行打点采集。这里需要做一下verl 0.7.0版本前后的区分,由于verl 0.7.0版本将推理阶段的SPMD单程序多数据模式统一切换为vLLM推理引擎的acync server异步非阻塞推理服务端模式,推理由原来的单进程模式变为了多进程模式,而原本的采集方法基于单进程代码构建,这导致0.7.0版本之前对Rollout阶段进行profiling采集的功能失效。
1、verl 0.6.1及以前版本的打点采集方法
强化学习分推理和训练2个阶段,若按在主循环打点的常规思路,推理阶段会出现profiling文件过大无法解析,因此需要对训练、推理阶段分开采集数据。
verl的训推流程分别单独包装在 generate_sequence 和 update_actor 两个函数中,位于 verl/worker/fsdp_worker.py。
对于推理阶段,会逐token进行采集,如果不减少输出 token 的数量,单个profiling文件可能达到几百个G,需要调整关键参数,推荐修改的参数如下:
# 减少输出token数量,实际输出token数应该是actor_rollout_ref.rollout.n * data.gen_batch_size * data.max_response_length
data.max_response_length=16
# 减小 batchsize
data.gen_batch_size = $((train_prompt_bsz * 1))
# 关闭训前评估
trainer.val_before_train=False
# 关闭动态采样,减小token数容易触发跳过采样
algorithm.filter_groups.enable=False
# 关闭过长惩罚,该参数的一个关联参数与max_response耦合, 不关会报错
reward_model.overlong_buffer.enable=False
推理阶段打点功能在generate_sequence函数,实现如下:
def generate_sequences(self, prompts: DataProto):
······
with simple_timer("generate_sequences", timing_generate):
rollout_prof_flag = False
import torch_npu
if torch.distributed.get_rank() == 0 and rollout_prof_flag:
prof_save_path = "/path/to/prof_result/NPU_qwen25_32B_without_stack_rollout"
experimental_config = torch_npu.profiler._ExperimentalConfig(
export_type=torch_npu.profiler.ExportType.Text,
aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization,
profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
l2_cache=False,
data_simplification=False)
prof = torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU, # 采集框架侧数据开关
torch_npu.profiler.ProfilerActivity.NPU], # 采集NPU数据开关
schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=0), # 设置不同step的行
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(prof_save_path), # 将采集到的性能数据导出为TensorBoard工具支持的格式
record_shapes=False, # 算子的InputShapes和InputTypes,Bool类
profile_memory=False, # 算子的内存占用情况,Bool类型
with_stack=False, # 算子调用栈,Bool类型
experimental_config=experimental_config)
print(f"{'<' * 20} prof start {'>' * 20}")
prof.start()
output = self.rollout.generate_sequences(prompts=prompts)
if torch.distributed.get_rank() == 0 and rollout_prof_flag:
prof.stop()
rollout_prof_flag = False
print(f"{'<' * 20} rollout prof stop {'>' * 20}")
log_gpu_memory_usage("After rollout generation", logger=logger)
······
对于训练阶段,无需更改参数,如果采集数据过大可以使用离线解析或减小 data.train_batch_size,训练阶段打点功能在update_actor函数,实现如下:
def update_actor(self, data: DataProto):
actor_prof_flag = False
import torch_npu
if torch.distributed.get_rank() == 0 and actor_prof_flag:
prof_save_path = "/path/to/prof_result/NPU_qwen25_32B_without_stack_actor"
experimental_config = torch_npu.profiler._ExperimentalConfig(
export_type=torch_npu.profiler.ExportType.Text,
aic_metrics=torch_npu.profiler.AiCMetrics.PipeUtilization,
profiler_level=torch_npu.profiler.ProfilerLevel.Level1,
l2_cache=False,
data_simplification=False)
prof = torch_npu.profiler.profile(
activities=[
torch_npu.profiler.ProfilerActivity.CPU, # 采集框架侧数据开关
torch_npu.profiler.ProfilerActivity.NPU], # 采集NPU数据开关
schedule=torch_npu.profiler.schedule(wait=0, warmup=0, active=1, repeat=1, skip_first=0), # 设置不同step的行
on_trace_ready=torch_npu.profiler.tensorboard_trace_handler(prof_save_path), # 将采集到的性能数据导出为TensorBoard工具支持的格式
record_shapes=False, # 算子的InputShapes和InputTypes,Bool类
profile_memory=False, # 算子的内存占用情况,Bool类型
with_stack=False, # 算子调用栈,Bool类型
experimental_config=experimental_config)
print(f"{'<' * 20} prof start {'>' * 20}")
prof.start()
# Support all hardwares
data = data.to(get_device_id())
······
if torch.distributed.get_rank() == 0 and actor_prof_flag:
prof.stop()
actor_prof_flag = False
print(f"{'<' * 20} actor prof stop {'>' * 20}")
return output
上述方法可以完成0号卡在每个step的 profiling 采集。注意,VeRL采用RAY进行资源调度,可以关注打屏日志中打印prof信息的机器ip来找到rank0的所在的机器,采集数据只会在该机器中落盘(也可以把路径设为共享存储路径)
2、verl 0.7.0及以后版本的打点采集方法
为解决推理阶段的SPMD模式切换到vLLM acync server模式导致Rollout过程profiling采集生效的问题,目前昇腾已在verl社区发起了一个PR: https://github.com/volcengine/verl/pull/4320。截止发稿,该PR尚未合入,未合入时可以使用以下昇腾提供的临时解决方案,如下图所示:
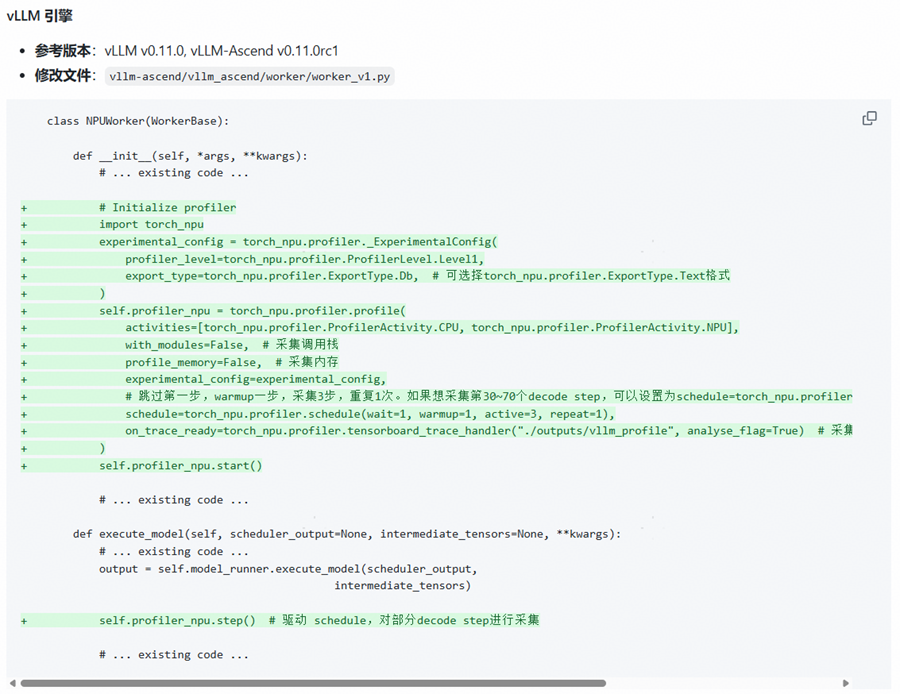
训练阶段可与0.6.1部分保持一致
profiling采集完成后进行数据解析。需要注意,NPU上 torch profiler 会在解析后会默认对采集信息进行解析,但如果文件过大或权限问题等因素有时会解析失败,这时可以使用离线解析代码:
from torch_npu.profiler.profiler import analyse
if __name__ == "__main__":
analyse(profiler_path="./result_data", max_process_number=想使用的cpu核数)性能瓶颈分析,确认优化方向
1、推理bound问题:观察性能数据,可以发现昇腾A2在 2K 场景下训推比约1:2.5,在 4K 场景下训推比约1:4.5,训练时间与竞品差距较小,推理阶段空泡时间较长。
2、vLLM新特性缺失:对比参数配置,NPU使用 vLLM-ascend 版本为 0.8.0,此版本不支持 chunked prefill 和 vLLM V1 特性,而竞品开启该两项特性,此为长序列场景下性能差异大的的主要原因之一
3、推理拖尾问题:观察显存占用,发现推理阶段由于推理随机性导致rollout样本长短不一,存在严重的拖尾现象,多数卡都已经推完的情况下仅有少数卡还在继续推理,拖尾时间达到推理部分的30%以上。
4、其他优化点分析:采集profiling分析,发现:
1)allreduce算子和matmul算子可以换用mc2融合算子
2)未开启图模式,可以尝试taskqueue level 1 + graph mode进行优化
3)拖尾部分存在严重host bound,free时间达到20%+
通过以上瓶颈点分析,我们提出通用优化、训练阶段优化和推理阶段优化三个方向,分别优化点如下:
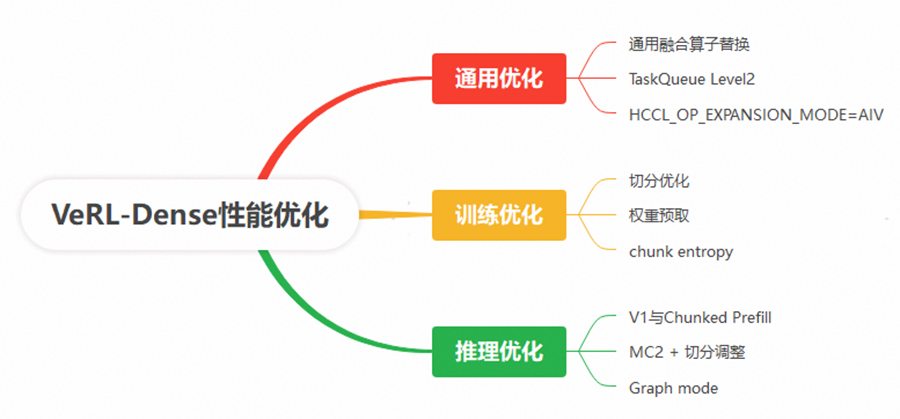
2.2 通用性能优化手段
本节主要介绍 NPU 训练的一些通用优化能力,除了目标模型其他大多数场景也可以获得可观收益。
融合算子替换:优化部分小算子实现,端到端性能提升8%
首先将常用的
RotaryMul & RotaryMulGrad、RmsNorm & RmsNormGrad、Swiglu 三个融合算子替换到对应模型的
models 文件目录中,融合算子的具体设计及实现方式见昇腾社区性能优化部分:https://www.hiascend.com/document/detail/zh/Pytorch/600/ptmoddevg/trainingmigrguide/performance_tuning_0023.html
在 verl 开源代码仓中有专门的 npu_patch 文件(verl/models/transformers/npu_patch.py),对transformers的 Qwen2 Model部分进行替换:
import torch
import torch_npu
from torch_npu import npu_rotary_mul as apply_rotary_emb
from transformers.models.qwen2 import modeling_qwen2
from transformers.models.qwen2.modeling_qwen2 import Qwen2RMSNorm as Qwen25RMSNorm
from transformers.models.qwen2.modeling_qwen2 import Qwen2MLP
def apply_rotary_pos_emb_flashatt_npu(
q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> tuple[torch.Tensor, torch.Tensor]:
cos = cos.chunk(2, dim=-1)[0].contiguous()
sin = sin.chunk(2, dim=-1)[0].contiguous()
cos = cos.repeat(1, 2)
sin = sin.repeat(1, 2)
q_embed = apply_rotary_emb(
q.float(), cos.unsqueeze(0).unsqueeze(2).float(), sin.unsqueeze(0).unsqueeze(2).float()
).type_as(q)
k_embed = apply_rotary_emb(
k.float(), cos.unsqueeze(0).unsqueeze(2).float(), sin.unsqueeze(0).unsqueeze(2).float()
).type_as(k)
return q_embed, k_embed
# This api can improve performance on ASCEND NPU
def rms_norm_forward(self, x):
return torch_npu.npu_rms_norm(x, self.weight, epsilon=self.variance_epsilon)[0]
def fused_apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = torch_npu.npu_rotary_mul(q.contiguous(), cos, sin).to(q.dtype)
k_embed = torch_npu.npu_rotary_mul(k.contiguous(), cos, sin).to(k.dtype)
return q_embed, k_embed
def qwen2_mlp_forward(self, x):
gate_up_output = torch.cat([self.gate_proj(x), self.up_proj(x)], dim=-1)
return self.down_proj(torch_npu.npu_swiglu(gate_up_output, dim=-1))
Qwen25RMSNorm.forward = rms_norm_forward
Qwen2MLP.forward = qwen2_mlp_forward
modeling_qwen2.apply_rotary_pos_emb = fused_apply_rotary_pos_emb
替换融合算子后,端到端性能提升8%。
taskqueue level2:优化算子下发瓶颈,吞吐提升10%
由于profiling中拖尾阶段存在严重host bound,设备空闲时间占比较高,因此使能taskqueue进行流水优化。Level 1优化:使能task_queue算子下发队列优化,将算子下发任务分为两段,一部分任务(主要是aclnn算子的调用)放在新增的二级流水上,一、二级流水通过算子队列传递任务,相互并行,通过部分掩盖减少整体的下发耗时,提升端到端性能。
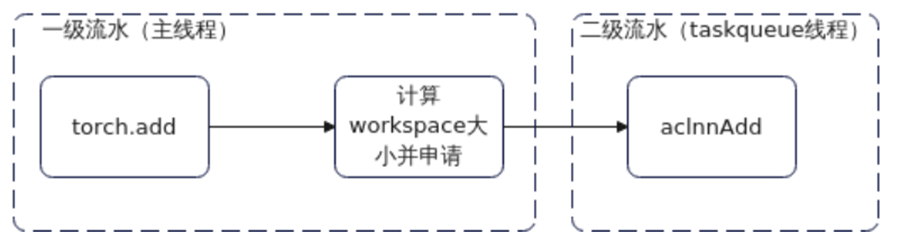
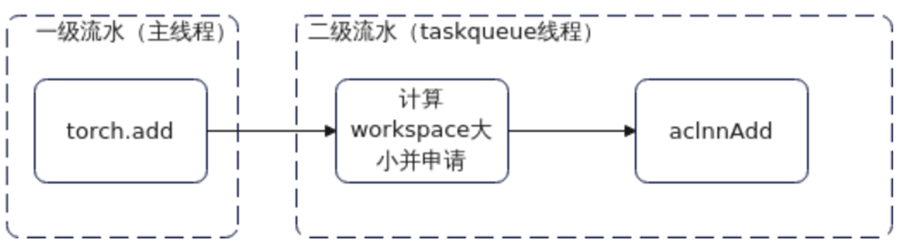
Level 2优化:包含Level 1的优化并进一步平衡了一、二级流水的任务负载,主要是将workspace相关任务迁移至二级流水,掩盖效果更好,性能收益更大。
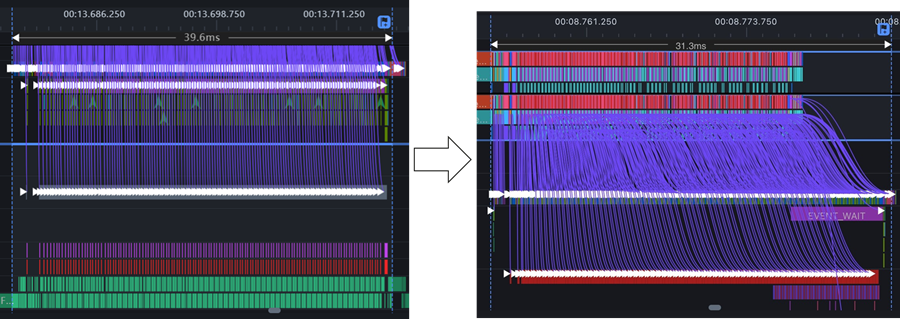
使能taskqueue level2 之后,host bound明显缓解,吞吐提升10%
taskqueue的使能方式
level1:添加环境变量 TASK_QUEUE_ENABLE=1
level2:添加环境变量 TASK_QUEUE_ENABLE=2
HCCL_OP_EXPANSION_MODE=AIV:减少通算未掩盖时间,端到端性能提升8%
通过profiling数据可以看到通算未掩盖的时间较高,通过开启AIV模式,端到端性能提升8%,值得注意的是该特性与mc2类似,在tp4下几乎无任何性能收益,仅在response length长度较长且tp8的情况下有较大的收益。
该环境变量用于配置通信算法的编排展开位置,支持如下取值:
· AI_CPU:代表通信算法的编排展开位置在Device侧的AI CPU,Device侧根据硬件型号自动选择相应的调度器。
· AIV:代表通信算法的编排展开位置在Device侧的Vector Core,执行也在Vector Core。
· HOST:代表通信算法的编排展开位置为Host侧CPU,Device侧根据硬件型号自动选择相应的调度器。
· HOST_TS:代表通信算法的编排展开位置为Host侧CPU,Host向Device的Task Scheduler下发任务,Device的Task Scheduler进行任务调度执行。
详细特性适用范围见链接:https://www.hiascend.com/document/detail/zh/canncommercial/83RC1/maintenref/envvar/envref_07_0096.html
注意,该特性与mc2特性也存在冲突,且依赖HDK版本,HDK<25.0.rc1.2 的版本可能无法成功启用。
2.3 训练任务性能优化
强化学习训练中单训练过程的时间占比较小,比竞品略高的算力在计算密集场景下只要切分得当往往不会存在太大的GAP,本节主要针对切分给出建议,并提供一些VeRL支持的训练优化方法。
切分优化:探索最优训练切分fsdp_size
通过参数 actor_rollout_ref.actor.fsdp_config.fsdp_size 在fsdp后端下可以调整 fsdp 切分的范围,由于 32B 模型无法在单机(8卡)范围内进行 fsdp 切分来减少跨机通信,共进行了fsdpsize=32、64、128三个case,在平均输出长度约4K时,fsdp_size=128 时性能最优,测试数据如下:
fsdp_size(DP域卡数) | 32 | 64 | 128 |
Throughput(吞吐量TPS) | 40 | 42 | 47 |
权重预取:通算掩盖提升训练效率
可以通过参数 actor_rollout_ref.actor.fsdp_config.forward_prefetch=True 开启前向的参数预取,在前向计算完成前,提前发起下一个前向传播所需的 all-gather 操作,通过通算掩盖提升训练效率,详细实现见FSDP前向预取:https://docs.pytorch.org/docs/stable/fsdp.html#module-torch.distributed.fsdp
反向预取由于梯度计算时序可能动态变化,导致 BACKWARD_POST无法准确预测下一次预取的时机,引发数据依赖错误,详情见 FSDP documentation:https://github.com/pytorch/torchtitan/blob/main/docs/fsdp.md?plain=1#L70;目前VeRL最新代码已禁用反向预取接口
Chunk entropy:减少峰值显存
模型处理长序列张量时(如大语言模型的token序列),完整张量会一次性占用大量内存,VeRL中在训练阶段提供了参数 actor_rollout_ref.actor.entropy_from_logits_with_chunking=True,在前向传播过程中,将张量按 [chunk_size, voc] 形状分块处理,而非直接处理完整序列长度的张量,从而降低显存峰值。
2.4 推理任务性能优化
V1与Chunked Prefill:跟进vLLM最新技术方案,端到端性能提升15%
V1是 vLLM对推理架构的一次整体更新,主要解决 V0 在高并发、长序列场景和资源效率上的局限性,在长序列场景下有大幅性能优化;Chunked Prefill 为 V1 对长序列场景的一种优化手段,将长短不一的 prompts 拆分为长短一致的 chunks 进行 prefill,这些 chunks 间的气泡再插入其他已经完成 prefill 的 prompts 的 decode处理,一方面降低峰值显存,避免长序列场景下过长的prompt造成oom,另一方面大幅提升并行计算的效率。
Qwen2.5-32B 在128卡、2K -> 20K场景下,开启 V1 和 Chunked Prefill 后端到端实测性能提升15%+
使能方式:
开启 vLLM V1 ,在 verl 的runtime_env.yaml文件中添加环境变量设置 VLLM_USE_V1=1;开启 chunked_prefill,需要在verl训练启动脚本中设置参数:actor_rollout_ref.rollout.enable_chunked_prefill=True
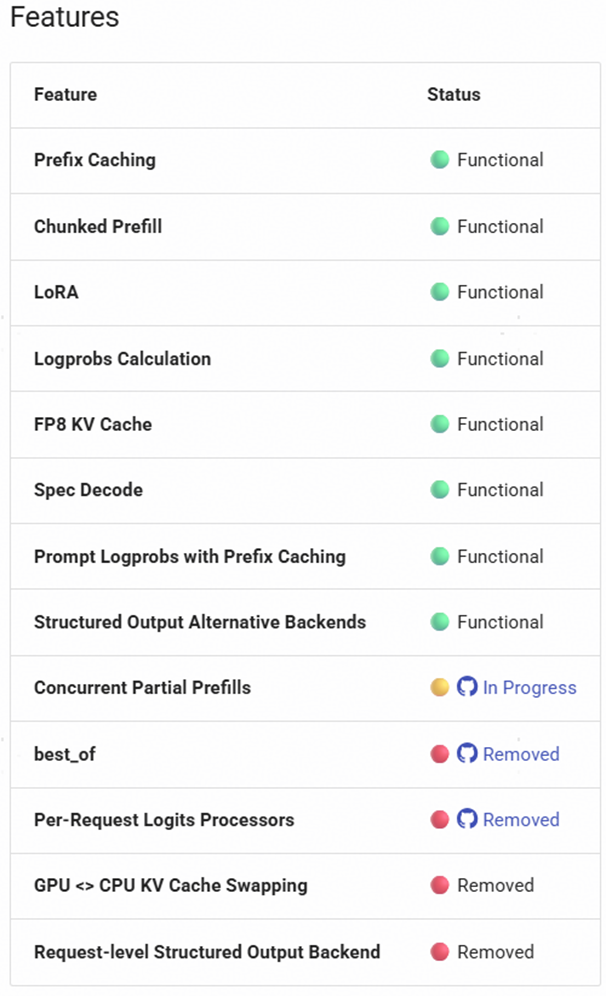
V1 的支持度如下,根据实际需求决定是否开启:

vLLM V1 的详细实现与功能:https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
Chunked Prefill 的技术实现细节:https://zhuanlan.zhihu.com/p/710165390
mc2与切分优化:增大切分结合通算掩盖,性能再提升5%
mc2融合算子使能
在训练过程中,使用融合算子替换多个单算子,能减少算子下发和通信时延,提升训练效率。在vLLM的RowParallelLinear前向函数中,原本会分别执行allreduce和matmul操作,该功能通过使用torch_npu.npu_mm_all_reduce_base实现了allreduce与matmul的融合内核操作mc2,将2个算子合成一个融合算子,实现训练性能优化。
mc2使能方法:
1. 在 runtime_env.yaml 添加环境变量 VLLM_ASCEND_ENABLE_MATMUL_ALLREDUCE=1
2. 部分 verl 版本中 vllm-ascend 与 vllm 的导入顺序存在问题,会导致 vllm-ascend 对 vllm patch 无法生效,包括上述的mc2优化,如果使用的verl版本较低,发现mc2优化无法生效,需要额外在 verl/workers/fsdp_workers.py 中添加如下导入代码:
# # # In verl/workers/fsdp_workers.py
import datetime
import json
import logging
import os
import warnings
from dataclasses import asdict
from typing import Any, Optional
import numpy as np
import psutil
import torch
# ------------------Add------------------------#
import vllm
import vllm_ascend.patch.worker
# ---------------------------------------------#
import torch.distributed
import torch.distributed as dist
该问题由于需要导入vllm-ascend,暂时难以合入 verl 原仓代码,当前只能通过上述手段进行使能。
mc2 使能情况确认:右侧红色部分可以看出mc2融合算子使能成功:
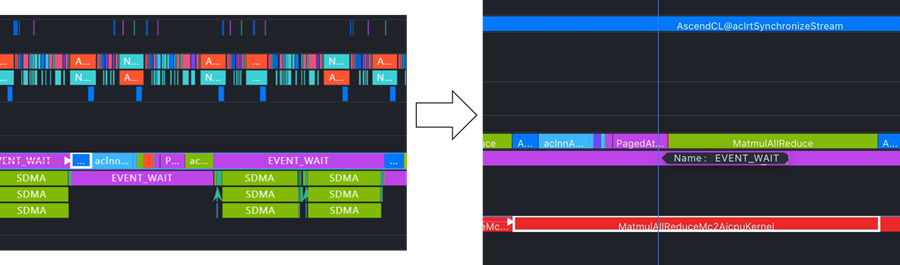
切分优化
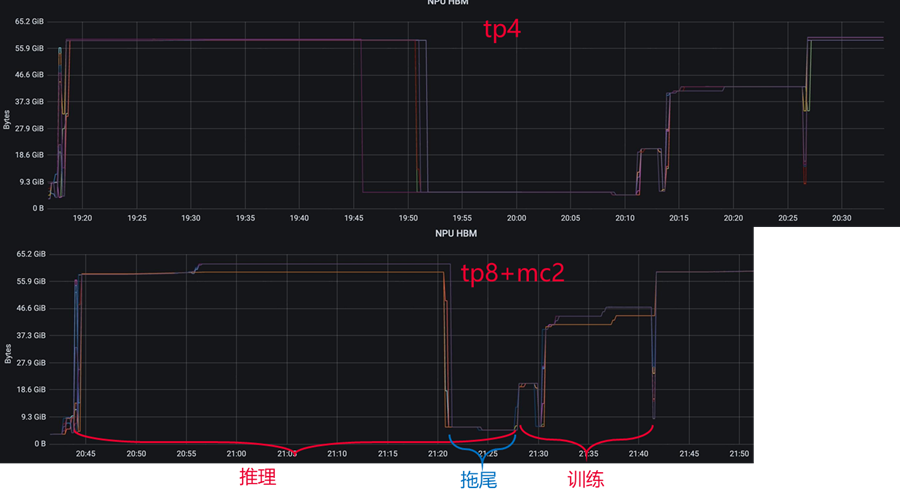
mc2融合算子的使用需要结合TP切分调优。我们分析,TP=4场景下,多数时间设备资源是处于拖尾空泡,mc2通算掩盖收益不明显,需要做更大的TP切分TP=8,TP=8带来的通信开销结合mc2能达到通算掩盖,从而减少拖尾,我们调优发现:1)不开启mc2,TP=4 -> TP=8,性能略微下降;2)开启mc2,TP=4 -> TP=8,性能提升约5%。
Graph mode图模式优化
NPU上图模式主要对下发进行优化,可以分别使用【taskqueue level2】和【taskqueue level 1 + 图模式】两种方案择优使用,taskqueue level2和图模式互斥不可共用。在【vllm0.11.0 + vllm-ascend 0.11.0-dev + pta2.7.1 + CANN8.3】配套下,实测两套方案带来的下发优化性能基本相当。
使能方式:verl 中,通过设定参数 actor_rollout_ref.rollout.enforce_eager=False 来开启静态图模式,注意这里 eager mode 为动态图模式,因此置为 False 为开启静态图。
注:在最新的Verl代码(20251023)中该参数默认值为False,如期望关闭图模式需要手动加入该参数并置为True
三、结语
在强化学习后训练中,短推长场景下最大的瓶颈还是显存bound,针对显存进行优化是一大方向,另外性能低的另一个重要原因是负载不均,观察显存可以发现推理过程中大多数卡都推完的情况下,只在等少数卡完成推理,造成了大量的拖尾时间,后续对强化学习的优化手段也主要从这两个方向出发。
目前主要的性能优化方向集中在训推异步上,开源方案有one step off、full async等,核心思想是让训推并行进行,这类方案通常会导致精度无法对齐,如何并行的同时保证训练效果是当前异步方案攻关的重点。
了解和使用更多昇腾强化学习技术和实践,欢迎通过以下方式参与:
昇腾后训练强化学习最佳实践:
https://mp.weixin.qq.com/s/TnilRFlpGQkfGQFBDX-wYw
https://www.hiascend.com/zh/developer/techArticles/20251107-1
昇腾后训练强化学习Docker镜像:
https://www.hiascend.com/developer/ascendhub/detail/2c7122f323f94a19ba7fca6b8dccf11e
昇腾开源微信小助手:ascendosc
verl开源社区讨论区:https://github.com/volcengine/verl/discussions
[参考]
[1]DAPO论文:https://arxiv.org/abs/2503.14476