



基于Triton Inference Server的昇腾小模型服务化部署参考实践
发表于: 2025/12/19
非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
1 概述
针对LLM、VLM等大模型,已有基于昇腾后端的推理服务化软件支持,例如MindIE和vLLM Ascend。然而,对于CV、语音处理等小模型的服务化部署场景,尽管存在OM模型推理、Torch_npu推理、TorchAir推理等多种推理方式,但目前仍缺乏较为完整的服务化部署样例,无法有效支持动态批处理、多实例部署等关键功能。
开源的Triton Inference Server为小模型的服务化部署提供了成熟的解决方案。该框架在设计上将服务化功能与后端推理逻辑解耦,具有良好的可扩展性,便于集成不同的推理后端。基于这一架构特点,可通过其python_backend编写Python脚本来灵活接入NPU推理能力。例如,OM模型推理工具ais_bench支持Python调用,并具备模型加载、动态批处理等功能,能够方便地在Triton Inference Server中实现高效、可扩展的NPU推理服务。
使用说明:
该参考实践主要面向有小模型做服务化推理需求的场景,可基于该参考实践进行适配。小模型推理的主要方式是OM模型推理、Torch_npu推理、TorchAir推理等,本文结合这几种推理方式进行服务化部署给出了参考实践,覆盖大多数小模型推理场景,使用者也可以根据自身的模型调用方式进行小幅修改适配。
2 推理服务化部署指南
2.1 方案概述
昇腾小模型服务化部署架构如图1所示,其核心是Triton Inference Server与昇腾小模型推理的高效协同。
在昇腾侧,CANN作为面向AI的异构计算架构,向上支持多种AI框架,不仅提供Torch_npu在线推理和TorchAir图编译能力,还提供ATC工具用于模型转换,能够生成经过深度优化(包括算子调度、数据重排和内存优化等)的离线OM模型,从而显著提升推理性能。
在服务化层面,Triton Inference Server凭借其完善的功能、高可靠性和良好的软件生态,为模型提供了强大的服务管理功能。
本方案通过有效整合二者优势,实现了在昇腾设备上高效、稳定的小模型服务化部署。
图1 小模型服务化部署方案架构设计图

主要操作执行步骤包括三点:
1. 环境准备:在物理机上安装昇腾基础驱动与固件,并拉取Triton Inference Server官方镜像。随后,基于该镜像构建包含昇腾CANN软件包的自定义容器环境,以启用NPU后端支持。
2. 模型准备:以OM模型推理为例,需利用昇腾提供的模型转换工具(如ATC),将训练好的模型转换为在昇腾硬件上高性能运行的离线OM模型。
3. 服务配置与启动:为模型编写配置文件(config.pbtxt),定义名称、后端、动态批处理、多实例等关键参数,并准备对应的推理脚本。最后启动Triton服务加载模型,即可提供推理服务。
2.2 拉取Triton Inference Server镜像
Triton Inference Server是一款功能全面的开源推理服务化软件,具备多框架模型支持、并发执行与动态批处理能力,并提供了基于Python的自定义后端开发与模型组合等功能。
Triton Inference Server内置了可配置的模型调度与批处理算法。在推理过程中,每个模型独立的调度器会首先根据预设策略(如动态批处理)将多个请求组合成批,再将批处理后的请求分发给对应的模型后端。后端执行推理计算并生成结果,最终将输出返回。
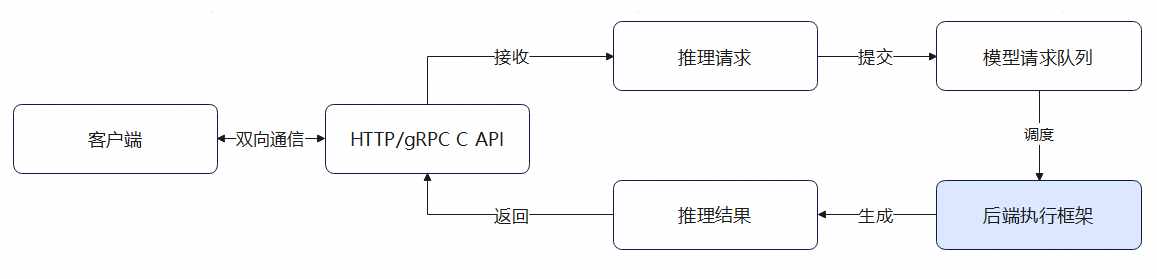
图2是客户端请求的一个流程,客户端发送请求后,经后端框架执行计算后返回,而对服务化框架而言,只负责请求发送、管理和结果返回,并不感知后端执行设备,故修改执行后端为NPU是可行的,图中标蓝部分即为适配修改的部分。
图2 客户端请求流程
要使用Triton Inference Server服务化框架,需拉取Triton Inference Server镜像,该镜像由Triton Inference Server官方提供。
2.3 安装昇腾软件
由于开源Triton Inference Server镜像中仅支持CPU和GPU后端,故要使能NPU进行服务化部署,首先需要在物理机上安装昇腾固件及驱动,由于需要通过镜像部署,故需安装docker并基于Triton Inference Server镜像构建容器,再在容器中安装昇腾软件包,即CANN包。
小模型的推理方式主要有OM模型推理、Torch_npu和TorchAir等,三种推理方式的区别如下:
· OM模型推理指的是通过ais_bench工具来推理OM模型文件,其中OM模型文件指的是通过ATC工具将开源框架模型转换得到的昇腾离线模型文件,ais_bench推理工具是用来针对指定的推理模型运行推理程序的工具。
· Torch_npu使能昇腾NPU可以支持PyTorch框架,为PyTorch框架的使用者提供昇腾设备上的适配方案。
· TorchAir是Torch_npu的图模式能力扩展库,提供了昇腾设备亲和的torch.compile图模式后端,实现了PyTorch网络在昇腾NPU上的图模式推理加速以及性能优化。
三种推理方案在软件环境配置上存在差异,具体依赖组件如下表所示:
表1 三种推理方式的软件依赖对比
推理方式 | 昇腾软件 | Python依赖 |
|---|---|---|
OM模型推理 | 昇腾驱动、CANN | aclruntime、ais_bench |
Torch_npu | 昇腾驱动、CANN | torch、torch_npu |
TorchAir | 昇腾驱动、CANN | torch、torch_npu |
2.4 Triton Inference Server服务化仓库配置
Triton Inference Server支持多种推理后端,包括专用后端(如ONNX、TensorFlow)和灵活的Python后端。Python后端已预编译并集成在官方镜像中,用户可通过编写脚本实现自定义推理逻辑。
基于昇腾设备上部署可通过Python后端来实现,本章将介绍如何配置Python后端模型仓库,实现昇腾设备上Triton Inference Server的适配。
Triton Inference Server的模型仓库是一个目录结构化的模型管理系统,它定义了模型在服务中的存放路径(包含多个模型)、模型配置(输入/输出、batch、并发等)和版本控制(多个模型版本)。
模型仓库的整体配置如下,下面将分别介绍配置文件config.pbtxt和模型推理文件model.py:
model_repository
└── model_name
├── 1
└── model.py
└── config.pbtxt2.4.1 配置文件
每个模型目录都有一个config.pbtxt文件,来配置模型的参数,如模型名称、执行后端、输入输出、实例数量、执行设备、批处理参数等,具体的参数含义如下表所示:
表2 config.pbtxt配置参数说明
参数 | 子参数 | 含义 |
|---|---|---|
name | - | 指定模型的名称,需与模型目录的名称一致 |
backend | - | 指定模型执行的后端,此处填python即可,表示通过python脚本的方式来实现模型的推理 |
max_batch_size | - | 动态批处理可处理的最大批处理数量,需根据模型的能力来设置。设置为0代表不支持动态批处理 |
dynamic_batching | preferred_batch_size | 动态批处理的参数,表示组Batch优先考虑的组Batch大小 |
max_queue_delay_microsecond | 动态批处理的参数,表示组Batch时的最大等待时延(us) | |
input/output | name | 输入/输出的名称 |
data_type | 输入/输出的数据类型 | |
dims | 输入/输出的维度大小 | |
instance_group | count | 配置模型的实例数量 |
kind | 配置模型的执行设备,填KIND_CPU即可 |
1. 指定模型的执行设备
Triton Inference Server原生仅支持CPU/GPU,即config.pbtxt里的kind参数仅能写KIND_CPU/KIND_GPU,由于选CPU时不会感知智算设备,故可选择KIND_CPU,同时在自定义模型初始化时指定运行的NPU设备id。
2. 动态批处理
Triton Inference Server支持动态批处理,动态批处理指的是将一个或多个推理请求组合成单个批次,以此最大限度地提高模型吞吐、减小模型等待时延。实现服务端动态批处理仅需在模型配置文件中添加对应字段即可,如下所示:
dynamic_batching {
preferred_batch_size: [4,8, 2]
max_queue_delay_microseconds: 1000
}3. 多实例配置
Triton Inference Server支持生成单模型的多个副本,允许并行处理,以提高资源利用率、提高模型吞吐。
服务化部署时,可根据实际情况选择最佳的部署方案,通常有单卡单实例、单卡多实例、多卡多实例等,其部署方式大致相同,仅配置参数有所差异,模型推理逻辑不变,Triton Inference Server会根据指定的实例数量进行部署,在多个请求到来时进行请求分发。
· 单卡单实例
Triton Inference Server支持指定模型部署的实例数量,可以自动根据请求顺序去分发给不同实例去计算,此块功能无需修改。基于昇腾硬件,仅需在配置文件中指定实例数量为1,设备类型为KIND_CPU,同时在模型初始化时将其部署在昇腾设备上即可,该场景下需要一张昇腾卡,config.pbtxt配置文件如下所示:
instance_group [
{
count: 1
kind: KIND_CPU
}
]将模型初始化到昇腾硬件上,如下是模型推理文件model.py的示例:
from ais_bench.infer.interface import InferSession
class TritonPythonModel:
def initialize(self, args):
device = 0
# 加载模型
# InferSession的初始化表示在device id为0的npu芯片上加载模型model.om
self.session = InferSession(device_id=device, model_path="/path/to/model.om")· 单卡多实例
单卡多实例即在单卡单实例的基础上,部署多个同一模型的副本,可降低请求的等待时延,提高资源的利用率。该方案仅需一张昇腾卡即可部署,在单卡单实例的基础上修改实例数量即可,config.pbtxt配置文件如下所示:
instance_group [
{
count: 2
kind: KIND_CPU
}
]· 多卡多实例
为了提高资源利用率,也可以通过多卡多实例部署的方式。多卡多实例场景下,需要将实例初始化在不同卡上,由于模型在单个实例上只会初始化一次,可以通过自定义模型初始化函数,自行根据实例id来指定实例应该在哪个设备上执行。要实现多卡多实例部署,需修改配置文件config.pbtxt中的实例数量,并在模型配置文件model.py里修改初始化逻辑,以指定在哪张卡上进行初始化。由于是多卡部署,故该场景至少需要两张昇腾卡。config.pbtxt配置文件如下所示:
instance_group [
{
count: 2
kind: KIND_CPU
}
]将模型初始化到不同的昇腾硬件上,如下是模型推理文件model.py的示例:
from ais_bench.infer.interface import InferSession
class TritonPythonModel:
def initialize(self, args):
device = args["model_instance_name"][-1]
# 根据实例id将不同实例初始化到不同设备上
device = int(device) % 2
# 加载模型
# InferSession的初始化表示在device id为0和1的npu芯片上加载模型model.om
self.session = InferSession(device_id=device, model_path="/path/to/model.om")4. 动态Batch和多实例组合配置
动态批处理与多实例配置是优化推理服务性能的关键。选择何种策略,需基于请求并发量、时延要求及硬件资源进行综合判断。
在单卡场景下,若追求高吞吐且请求并发充足,应启用动态批处理,其最佳批次大小需通过性能实测确定。若请求稀疏或对时延敏感,算力在Batch=1时已无显著冗余,则采用单卡多实例是更优选择。此方式通过并行处理避免组批等待,能有效降低时延并提升资源利用率,但其并行度受实例数量及实例间资源竞争的限制。
当单卡性能无法满足极高的吞吐和时延要求时,则需升级至双卡多实例部署。该方案将实例负载分摊至不同NPU,从根本上避免了资源竞争,从而能同时实现高吞吐与低时延的目标。
2.4.2 模型推理文件
模型推理文件定义了模型是如何执行的,本节以OM模型推理为例,介绍模型推理文件的结构及各个模块的功能。如下表是推理脚本各个模块的功能说明:
表3 推理脚本模块功能说明
模块 | 功能 | 修改方法 |
|---|---|---|
initialize | 获取输入输出配置,如数据类型 | - |
模型初始化 | 根据实例id做映射,将不同实例放到指定卡上进行初始化,也可以自定义初始化方式,将模型加载到显存上 | |
execute | 对推理请求进行批处理 | 若请求数量在模型支持的Batch大小内,则将请求打包后进行推理,推理后再将请求分发,可自定义模型的推理方式 |
对请求逐一处理 | 遍历每个请求,逐一进行处理,最后统一将处理结果返回 | |
finalize | 资源释放 | - |
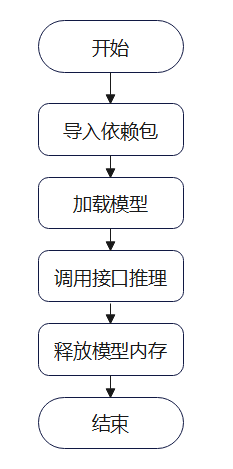
每个模型目录下会有多个模型版本,每个模型版本下会有一个推理后端脚本model.py,用于定义模型的推理逻辑。模型推理文件中,主要包含三个部分,模型初始化、模型推理以及模型资源释放。其中,OM模型可以运用ais_bench工具来进行推理,ais_bench支持多Device推理、支持动态Batch参数、多线程推理等。使用ais_bench工具,通常是通过命令行进行调用,每次模型均需要重复初始化和释放,不适合模型的服务化部署,但通过拆分ais_bench工具的处理逻辑,可以将其分为模型初始化、模型推理、获取模型性能数据、模型释放几个部分,流程如下图所示:
图3 ais_bench工具推理流程图
编写Triton Inference Server模型推理文件时,可将这几个部分拆分后分别放在推理文件中的三个部分,如下所示:
1. 模型初始化:导入依赖包和加载模型
2. 模型推理:调动推理接口进行推理
3. 模型资源释放:释放模型占用内存以及其他占用资源
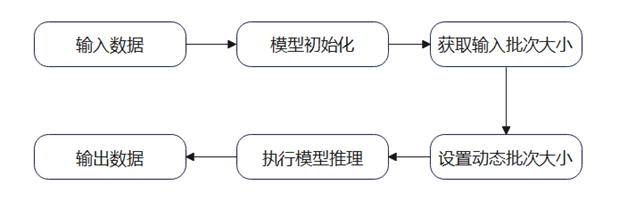
在模型推理过程中,为了支持Triton Inference Server的动态组Batch功能,模型本身也要有动态Batch的能力。以ais_bench工具为例,其也支持动态Batch推理,通过分析ais_bench工具的源码,可在推理前通过set_dynamic_batchsize来指定推理的Batch大小。故要支持小模型的服务化部署和动态批处理,需要在推理时根据输入数据的维度大小指定batch的大小,如下所示:
# 导入库
import numpy as np
from ais_bench.infer.interface import InferSession
# 模型初始化
device = 0
session = InferSession(device_id=device, model_path="/path/to/model.om")
inputs = [np.random.rand(1, 3, 224, 224).astype(np.float32)]
mode = "dymbatch"
# 获取Batch大小
set_dynamic = inputs[0].shape[0]
# 设置Batch大小
session.set_dynamic_batchsize(set_dynamic)
# 模型计算
outputs = session.infer(feeds=inputs, mode=mode)
# 释放模型占用的内存
session.free_resource()图4 ais_bench使用动态Batch的推理流程图
3 服务化部署参考示例
本章选取了视觉类模型与 OCR 模型作为典型场景,主要有以下四个参考实践:视觉类小模型(OM)、OCR小模型(OM)、视觉类小模型(Torch_npu)以及视觉类小模型(TorchAir),同时参考示例覆盖了多种推理方式(OM、Torch_npu、TorchAir),也覆盖Atlas 800I A2、Atlas 300I A2 标卡、Atlas 300I Duo标卡三种推理硬件,针对不同推理硬件的部署差异在本文中均会提及。
本章以服务化推理部署为核心,提供了从配置文件到推理调用的完整示例,旨在帮助读者快速掌握在不同推理框架(OM、Torch_npu、TorchAir)及硬件平台(Atlas 800I A2、Atlas 300I A2、Atlas 300I Duo)上的模型部署方法。
内容覆盖配置文件设计、多实例部署、HTTP/GRPC 调用方式,以及动态Batch与非动态Batch推理的实现参考。
3.1 最佳实践部署流程
本节讲述了如何在昇腾设备上部署Triton Inference Server服务的一个具体的操作流程。
前置条件:在执行以下步骤前,需在物理服务器上安装昇腾固件和驱动,并部署docker服务。
步骤 1 拉取镜像
Triton Inference Server镜像获取链接:GPU-optimized AI, Machine Learning, & HPC Software | NVIDIA NGC | NVIDIA NGC
注意选取Python版本3.11及以下的镜像。当前最新支持的是24.10,具体镜像对应的Python版本可参考:docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/rel-24-10.html
根据不同架构,执行不同的镜像拉取命令:
# aarch64:
docker pull --platform linux/arm64/v8 nvcr.io/nvidia/tritonserver:24.10-py3
# amd64:
docker pull --platform linux/amd64 nvcr.io/nvidia/tritonserver:24.10-py3步骤 2 构建容器
执行以下命令进行容器的构建,注意更改端口和容器名称,以免端口被占用导致冲突,如35528改为12345,需修改的端口为35528、35521、35523、35524,不需要修改的端口为22、8000、8001、8002(22为容器ssh服务端口,可不选,其余为tritonserver服务默认端口):
docker run -itd --privileged --name=triton_server_24.10 --shm-size=50g \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /etc/hccn.conf:/etc/hccn.conf \
-p 35528:22 \
-p 35521:8000 \
-p 35523:8001 \
-p 35524:8002 \
nvcr.io/nvidia/tritonserver:24.10-py3 bash步骤 3 容器环境设置
需先进入容器:
docker exec -it triton_server_24.10 bash设置驱动所需环境变量:
echo 'LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/common:/usr/local/Ascend/driver/lib64/driver:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc配置网络代理:
export http_proxy='http://xxx.xxx.xxx.xxx:xxxx'
export https_proxy='http://xxx.xxx.xxx.xxx:xxxx'配置pip源:
mkdir -p ~/.pip && \
echo "[global]" > ~/.pip/pip.conf && \
echo "trusted-host=mirrors.aliyun.com" >> ~/.pip/pip.conf && \
echo "index-url=http://mirrors.aliyun.com/pypi/simple" >> ~/.pip/pip.conf步骤 4 安装CANN组件
安装CANN包:先安装toolkit包、再安装kernels包,toolkit包不区分硬件形态,kernels包要根据不同的硬件形态来安装不同的软件包,如下所示,其中Atlas 300I Duo设备选择第一个kernels包,Atlas 800I A2和Atlas 300I A2设备选择第二个kernels包:
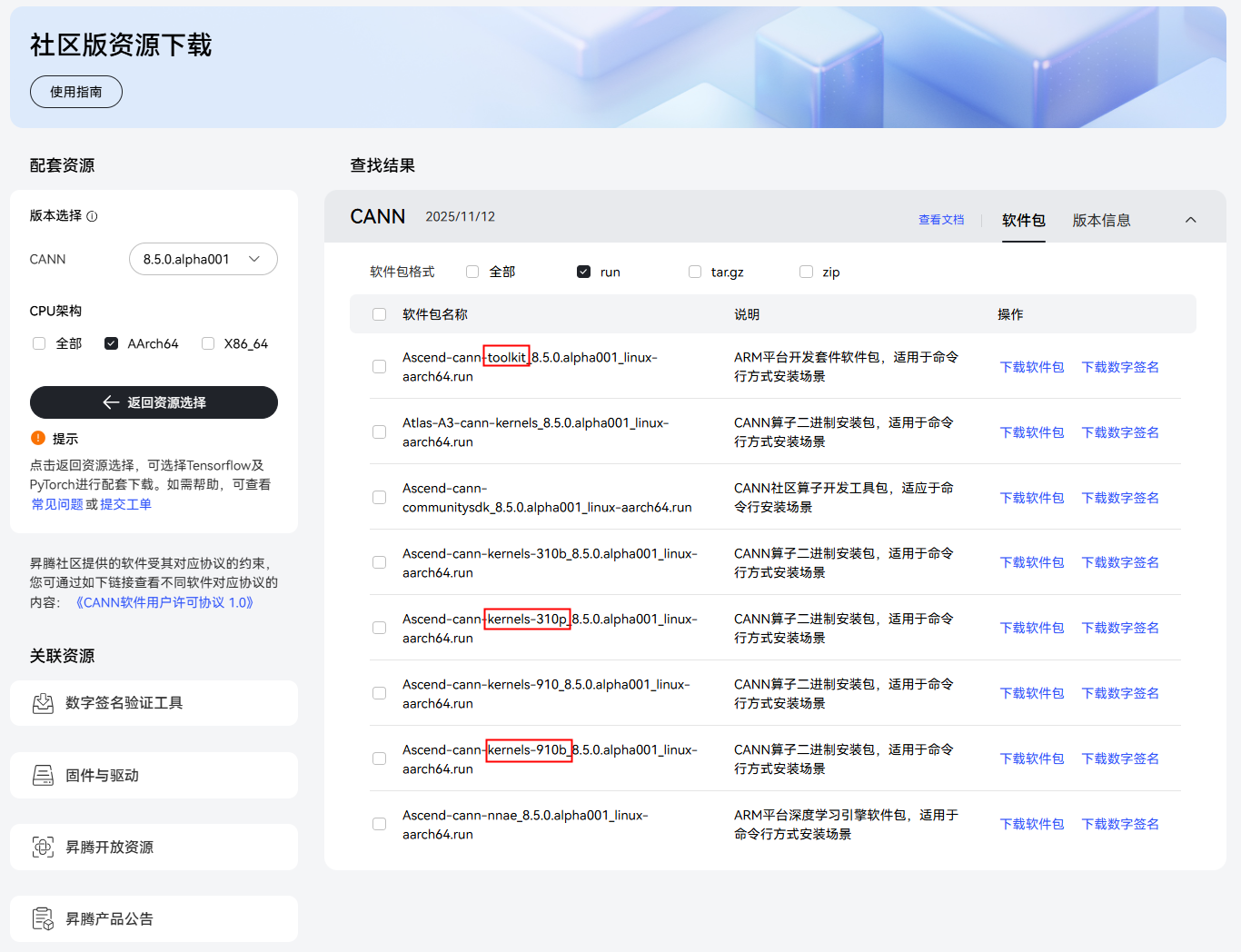
如上的安装包下载链接可参考:社区版资源下载-资源下载中心-昇腾社区
下载好软件包后,按顺序执行以下命令进行toolkit包和kernels包的安装:
chmod u+x *.run
echo y | bash Ascend-cann-toolkit*.run --quiet --install
echo 'source /usr/local/Ascend/ascend-toolkit/set_env.sh' >> ~/.bashrc
source ~/.bashrc
echo y | bash *cann-kernels*.run --quiet --install步骤 5 创建模型仓库
模型仓库是模型推理的入口,model_repository目录结构如下,可在任意路径下放置:
model_repository
└── model_name
├── 1
└── model.py
└── config.pbtxt具体的模型仓库参考示例可根据参考示例章节中对应场景下的说明及示例进行配置。
步骤 6 启动Triton Inference Server服务
准备好环境以及模型仓库后,即可启动Triton Inference Server服务,可采用相对路径或绝对路径启动服务,执行命令如下:
tritonserver --model-repository ./model_repository步骤 7 客户端调用
说明:Triton Inference Server支持HTTP/REST和GRPC协议,若需要使用HTTPS协议进行通信,则需要在Triton Inference Server前面再加一层反向代理来实现。
本节讲述了如何通过HTTP/REST、GPRC协议来实现Triton Inference Server客户端和服务端的交互。
1. HTTP调用示例(Python调用)
通过HTTP进行调用,需安装对应组件:
pip install tritonclient[http]==2.41.0以下给出了基于HTTP的Python调用示例:
import sys
import numpy as np
import tritonclient.http as httpclient
if __name__ == "__main__":
bs = 1
input_numpy = np.random.random((bs, 3, 224, 224)).astype(np.float32)
model_name = "resnet50"
image = ""
url = "localhost:8000"
verbose = False
try:
triton_client = httpclient.InferenceServerClient(
url=url, verbose=verbose
)
except Exception as e:
print("channel creation failed: " + str(e))
sys.exit(1)
inputs = []
outputs = []
input_name = "INPUT"
output_name = "OUTPUT"
inputs.append(httpclient.InferInput(input_name, input_numpy.shape, "FP32"))
outputs.append(httpclient.InferRequestedOutput(output_name))
inputs[0].set_data_from_numpy(input_numpy)
results = triton_client.infer(
model_name=model_name, inputs=inputs, outputs=outputs
)
output0_data = results.as_numpy(output_name)
print(output0_data.shape)2. GRPC调用示例(Python调用)
通过GRPC进行调用,需安装对应组件:
pip install tritonclient[grpc]==2.41.0以下给出了基于GRPC的Python调用示例:
import sys
import numpy as np
import tritonclient.grpc as tritongrpcclient
if __name__ == "__main__":
bs = 1
input_numpy = np.random.random((bs, 3, 224, 224)).astype(np.float32)
model_name = "resnet50"
image = ""
url = "localhost:8001"
verbose = False
try:
triton_client = tritongrpcclient.InferenceServerClient(
url=url, verbose=verbose
)
except Exception as e:
print("channel creation failed: " + str(e))
sys.exit(1)
inputs = []
outputs = []
input_name = "INPUT"
output_name = "OUTPUT"
inputs.append(tritongrpcclient.InferInput(input_name, input_numpy.shape, "FP32"))
outputs.append(tritongrpcclient.InferRequestedOutput(output_name))
inputs[0].set_data_from_numpy(input_numpy)
results = triton_client.infer(
model_name=model_name, inputs=inputs, outputs=outputs
)
output0_data = results.as_numpy(output_name)
print(output0_data.shape)步骤 8 性能测试
Triton Inference Server提供了性能测试工具perf_analyzer,使用方式如下:
perf_analyzer -m [模型名称] -b [批次大小] -t [线程数]以下是使用示例:
perf_analyzer -m resnet50 -b 1 -t 13.2 参考示例
本章针对以下四种场景给出对应的参考示例代码,即模型仓库的代码,以及给出了相关的环境依赖。
3.2.1 视觉类小模型(OM)
通过OM模型来进行推理,不仅需要准备OM模型文件,也要安装ais_bench推理工具,同时配置模型仓库既可以进行服务化部署。
1. 安装ais_bench工具
下载aclruntime和ais_bench推理程序的whl包:ais-bench_workload/tool/ais_bench/README.md · Ascend/tools - Gitee.com。
执行如下命令,进行安装:
# 安装aclruntime
pip3 install ./aclruntime-{version}-{python_version}-linux_{arch}.whl
# 安装ais_bench推理程序
pip3 install ./ais_bench-{version}-py3-none-any.whl2. 生成OM模型
本节的参考示例以resnet50模型为例,以下是生成OM模型的步骤:
获取resnet50模型原始权重:
wget https://download.pytorch.org/models/resnet50-0676ba61.pth安装依赖:
pip install torch==2.1.0 torchvision==0.12.0 onnx编写pth2onnx.py文件:
import sys
import torch
import torch.onnx
import torchvision.models as models
def convert(pthfile):
model = models.resnet50(pretrained=False)
resnet50 = torch.load(pthfile, map_location='cpu')
model.load_state_dict(resnet50)
print(model)
input_names = ["actual_input_1"]
output_names = ["output1"]
dummy_input = torch.randn(16, 3, 224, 224)
torch.onnx.export(
model,
dummy_input,
"resnet50_official.onnx",
input_names=input_names,
output_names=output_names,
opset_version=11)
if __name__ == "__main__":
pth_path = sys.argv[1]
convert(pth_path)导出onnx文件:
python3 pth2onnx.py ./resnet50-0676ba61.pth将onnx文件转换为OM文件:
·安装依赖:
pip install decorator scipy attr attrs psutil· 执行以下命令生成OM文件,执行前需设置环境变量chip_name:
atc \
--model=resnet50_official.onnx \
--framework=5 \
--output=resnet50 \
--input_format=NCHW \
--input_shape="actual_input_1:-1,3,224,224" \
--enable_small_channel=1 \
--log=error \
--soc_version=Ascend${chip_name} \
--dynamic_batch_size "1,2,4,8"
# Ascend${chip_name}请根据实际查询结果填写,执行npu-smi info即可查看chip_name3. 配置模型仓库
以resnet50模型为例,给出了双卡双实例的配置示例:
· 构建模型仓库文件夹:
按如下目录结构构建模型仓库:
model_repository
└── resnet50
├── 1
└── model.py
└── config.pbtxt· config.pbtxt配置文件:
name: "resnet50"
backend: "python"
max_batch_size: 8
dynamic_batching {
preferred_batch_size: [ 4, 8, 2 ]
max_queue_delay_microseconds: 1000
}
input {
name: "INPUT"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
output {
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1000 ]
}
instance_group [
{
count: 2
kind: KIND_CPU
}
]· model.py推理文件
按如下内容构建model.py,注意需修改/path/to/resnet50.om为步骤2生成的OM文件路径:
import numpy as np
import json
import triton_python_backend_utils as pb_utils
# 导入依赖包
from ais_bench.infer.interface import InferSession
class TritonPythonModel:
def initialize(self, args):
# 获取示例id,如两个实例,实例id为0或1
instance_id = args["model_instance_name"][-1]
# 根据实例id初始化模型,此处实例0初始化在0卡上,实例1初始化在1卡上
device = int(instance_id) % 2
model_config = json.loads(args["model_config"])
# 获取输出配置、输出的数据类型
output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT")
self.output_dtype = pb_utils.triton_string_to_numpy(
output_config["data_type"]
)
# 加载模型: InferSession初始化
self.session = InferSession(device_id=device, model_path="/path/to/resnet50.om")
def execute(self, requests):
output_dtype = self.output_dtype
responses = []
output = []
# 获取所有请求的batch_size列表
batch_sizes = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
batch_size = input_tensor.as_numpy().shape[0]
batch_sizes.append(batch_size)
total_batch_size = sum(batch_sizes)
# 合并所有请求的输入
input_numpys = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
input_numpy = input_tensor.as_numpy()
input_numpys.append(input_numpy)
# 按batch维度合并所有输入
input_numpy = np.vstack(input_numpys)
print("total_batch_size", total_batch_size)
# requests为调度器打包好的请求,组Batch情况下为组Batch的请求的数量,total_batch_size为8时根据请求情况可能为1-8
# om模型支持的Batch大小则进行请求合并后计算
if total_batch_size in [ 4, 8, 2 ]:
# 获取输入Batch大小并设置动态Batch的大小
set_dynamic = input_numpy.shape[0]
self.session.set_dynamic_batchsize(set_dynamic)
# 模型推理
output = self.session.infer(feeds=[input_numpy], mode="dymbatch")
# om模型不支持的Batch则分别以单个Batch计算
else:
for idx in range(total_batch_size):
input_numpy_idx = input_numpy[idx:idx+1]
set_dynamic = input_numpy_idx.shape[0]
self.session.set_dynamic_batchsize(set_dynamic)
result = self.session.infer(feeds=[input_numpy_idx], mode="dymbatch")
output.append(result[0])
output = [np.vstack(output)]
print("out_tensor_shape", output[0].shape)
# 按照原始batch_size分割输出并返回
start_idx = 0
for i, batch_size in enumerate(batch_sizes):
end_idx = start_idx + batch_size
out_data = output[0][start_idx:end_idx]
out_tensor = pb_utils.Tensor("OUTPUT", out_data.astype(output_dtype))
inference_response = pb_utils.InferenceResponse(
output_tensors=[out_tensor]
)
responses.append(inference_response)
start_idx = end_idx
return responses
def finalize(self):
# 释放模型占用的内存
self.session.free_resource()4. 启动服务化
执行以下命令启动Triton Inference Server服务:
tritonserver --model-repository ./model_repository5. 性能测试
先安装依赖:
pip install tritonclient[http]==2.41.0另起终端,并执行以下命令进行性能测试:
perf_analyzer -m resnet50 -b 1 -t 13.2.2 OCR小模型(OM)
以OCR模型为例,展示了非动态Batch以及单卡单实例下在800I A2/300I A2上的部署示例。
1. 安装依赖
可参照PaddleX网站进行安装:PaddleX/docs/practical_tutorials/high_performance_npu_tutorial.md at release/3.2 · PaddlePaddle/PaddleX · GitHub
步骤如下:
· 安装PaddleX
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
pip install -e ".[base]"
cd ../· 安装依赖
apt-get update --allow-unauthenticated && apt-get install -y libgl1· 安装高性能推理插件
执行以下命令进行安装:
paddlex --install hpi-npu若遇到网络问题,可执行以下命令设置环境变量并进行安装:
PIP_TRUSTED_HOST="paddle-model-ecology.bj.bcebos.com" paddlex --install hpi-npu2. 获取OM文件
通过以下链接可获取转换好后的OM模型文件,本示例以PP-OCRv4_mobile_rec模型为例:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/infer_om/models/PP-OCRv4_mobile_rec/PP-OCRv4_mobile_rec_infer_om_910B.tar --no-check-certificate解压:
tar -xvf PP-OCRv4_mobile_rec_infer_om_910B.tar获取推理示例文件:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_rec_001.png --no-check-certificate3. 配置模型仓库
以PP-OCRv4_mobile_rec模型为例,给出了单卡单实例的配置示例:
· 构建模型仓库文件夹:
按如下目录结构构建模型仓库:
model_repository
└── ocr_npu
├── 1
└── model.py
└── config.pbtxt· config.pbtxt配置文件:
name: "ocr_npu"
backend: "python"
max_batch_size: 0
input [
{
name: "INPUT_IMAGE"
data_type: TYPE_STRING
dims: [1] # Triton Python backend 可以传字符串表示文件路径
}
]
output [
{
name: "OUTPUT_JSON"
data_type: TYPE_STRING
dims: [1]
}
]
instance_group [
{
kind: KIND_CPU
count: 1
}
]· model.py推理文件
按如下内容构建model.py,注意需修改/path/to/PP-OCRv4_mobile_rec_infer_om_910B为步骤2解压后的文件夹路径:
import os
import json
import triton_python_backend_utils as pb_utils
import numpy as np
from paddlex import create_model
class TritonPythonModel:
def ocr_res_merge(self, ocr_res):
res = []
if ocr_res:
rec_text = ocr_res.get('rec_text', [])
rec_score = ocr_res.get('rec_score', [])
res.append([
[rec_text, str(rec_score)]
])
return [res]
def initialize(self, args):
model_dir = "/path/to/PP-OCRv4_mobile_rec_infer_om_910B"
hpi_config = {
"auto_config": False,
"backend": "om",
}
device_id = 0
self.model = create_model(
model_name="PP-OCRv4_mobile_rec",
model_dir=model_dir,
device=f"npu:{device_id}",
use_hpip=True,
hpi_config=hpi_config,
input_shape=[3, 48, 320]
)
def execute(self, requests):
responses = []
for request in requests:
input_image = pb_utils.get_input_tensor_by_name(request, "INPUT_IMAGE").as_numpy()[0].decode("utf-8")
result = list(self.model.predict(input_image))
result[0].print(json_format=False)
result_str = result[0].json.get('res', {})
result_str = self.ocr_res_merge(result_str)
result_str = json.dumps(result_str, ensure_ascii=False)
output_tensor = pb_utils.Tensor(
"OUTPUT_JSON",
np.array([result_str], dtype=np.object_) # 维度[1]的字符串数组
)
response = pb_utils.InferenceResponse(output_tensors=[output_tensor])
responses.append(response)
return responses
def finalize(self):
del self.model
self.model = None4. 启动服务化
执行以下命令启动Triton Inference Server服务:
tritonserver --model-repository ./model_repository5. GRPC调用示例
该OCR模型有多个返回输出,和图像模型有所差异,故提供了以下示例,说明客户端如何通过GRPC的方式,获取服务端返回的多个输出。
按如下内容在任意位置下构建client.py,注意需修改/path/to/general_ocr_rec_001.png为步骤2下载的图片路径:
import sys
import tritonclient.grpc as tritongrpcclient
import numpy as np
import json
if __name__ == "__main__":
model_name = "ocr_npu"
image_path = "/path/to/general_ocr_rec_001.png"
url = "localhost:8001"
verbose = False
triton_client = tritongrpcclient.InferenceServerClient(
url=url, verbose=verbose
)
inputs = []
outputs = []
input_name = "INPUT_IMAGE"
output_name = "OUTPUT_JSON"
inputs.append(tritongrpcclient.InferInput(input_name, [1], "BYTES"))
inputs[0].set_data_from_numpy(np.array([image_path.encode('utf-8')]))
outputs.append(tritongrpcclient.InferRequestedOutput(output_name))
results = triton_client.infer(
model_name=model_name,
inputs=inputs,
outputs=outputs
)
output_data = results.as_numpy(output_name)[0].decode('utf-8')
parsed = json.loads(output_data)
for res in parsed:
print("Text:", res[0][0][0], "Score:", res[0][0][1])先安装依赖:
pip install tritonclient[grpc]==2.41.0 protobuf测试客户端调用:
python3 client.py3.2.3 视觉类小模型(Torch_npu)
本节的参考示例以resnet50模型为例:
1. 安装依赖
pip install torch==2.1.0 torch_npu==2.1.0.post12 torchvision==0.16.0 pyyaml decorator scipy attr attrs psutil2. 配置模型仓库
以resnet50模型为例,给出了双卡双实例的配置示例:
· 构建模型仓库文件夹:
按如下目录结构构建模型仓库:
model_repository
└── resnet50TorchNpu
├── 1
└── model.py
└── config.pbtxt· config.pbtxt配置文件:
name: "resnet50TorchNpu"
backend: "python"
max_batch_size: 8
dynamic_batching {
preferred_batch_size: [ 4, 8, 2 ]
max_queue_delay_microseconds: 1000
}
input {
name: "INPUT"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
output {
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1000 ]
}
instance_group [
{
count: 2
kind: KIND_CPU
}
]· model.py推理文件
按如下内容构建model.py:
import numpy as np
import json
import triton_python_backend_utils as pb_utils
import torch
import torch_npu
from torchvision.models import resnet50
class TritonPythonModel:
def initialize(self, args):
# 获取示例id,如两个实例,实例id为0或1
instance_id = args["model_instance_name"][-1]
# 根据实例id初始化模型,此处实例0初始化在0卡上,实例1初始化在1卡上
device_id = int(instance_id) % 2
model_config = json.loads(args["model_config"])
# 获取输出配置、输出的数据类型
output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT")
self.output_dtype = pb_utils.triton_string_to_numpy(
output_config["data_type"]
)
# 加载模型
device = torch.device(f"npu:{device_id}")
torch.npu.set_device(device)
model = resnet50(pretrained=False)
model.to(device)
model.eval()
self.model = model
self.device = device
def execute(self, requests):
output_dtype = self.output_dtype
responses = []
output = []
# 获取所有请求的batch_size列表
batch_sizes = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
batch_size = input_tensor.as_numpy().shape[0]
batch_sizes.append(batch_size)
# 合并所有请求的输入
input_numpys = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
input_numpy = input_tensor.as_numpy()
input_numpys.append(input_numpy)
# 按batch维度合并所有输入
input_numpy = np.vstack(input_numpys)
input_tensor = torch.from_numpy(input_numpy).to(self.device)
output_tensor = self.model(input_tensor)
output = output_tensor.detach().cpu().numpy()
print("out_tensor_shape", output.shape)
# 按照原始batch_size分割输出并返回
start_idx = 0
for _, batch_size in enumerate(batch_sizes):
end_idx = start_idx + batch_size
out_data = output[start_idx:end_idx]
out_tensor = pb_utils.Tensor("OUTPUT", out_data.astype(output_dtype))
inference_response = pb_utils.InferenceResponse(
output_tensors=[out_tensor]
)
responses.append(inference_response)
start_idx = end_idx
return responses
def finalize(self):
del self.model
self.model = None3. 启动服务化
执行以下命令启动Triton Inference Server服务:
tritonserver --model-repository ./model_repository4. 性能测试
先安装依赖:
pip install tritonclient[http]==2.41.0另起终端,并执行以下命令进行性能测试:
perf_analyzer -m resnet50TorchNpu -b 1 -t 13.2.4 视觉类小模型(TorchAir)
本节的参考示例以resnet50模型为例:
1. 安装依赖
pip install torch==2.1.0 torch_npu==2.1.0.post12 torchvision==0.16.0 pyyaml decorator scipy attr attrs psutil2. 配置模型仓库
以resnet50模型为例,给出了双卡双实例的配置示例:
· 构建模型仓库文件夹:
按如下目录结构构建模型仓库:
model_repository
└── resnet50TorchAir
├── 1
└── model.py
└── config.pbtxt· config.pbtxt配置文件:
name: "resnet50TorchAir"
backend: "python"
max_batch_size: 8
dynamic_batching {
preferred_batch_size: [ 4, 8, 2 ]
max_queue_delay_microseconds: 1000
}
input {
name: "INPUT"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
output {
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1000 ]
}
instance_group [
{
count: 2
kind: KIND_CPU
}
]· model.py推理文件
import numpy as np
import json
import triton_python_backend_utils as pb_utils
import torch
import torch_npu
import torchair as tng
from torchvision.models import resnet50
class TritonPythonModel:
def initialize(self, args):
# 获取示例id,如两个实例,实例id为0或1
instance_id = args["model_instance_name"][-1]
# 根据实例id初始化模型,此处实例0初始化在0卡上,实例1初始化在1卡上
device_id = int(instance_id) % 2
model_config = json.loads(args["model_config"])
# 获取输出配置、输出的数据类型
output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT")
self.output_dtype = pb_utils.triton_string_to_numpy(
output_config["data_type"]
)
# 加载模型
device = torch.device(f"npu:{device_id}")
torch.npu.set_device(device)
model = resnet50(pretrained=False)
model.to(device)
model.eval()
# 配置图模式config
config = tng.CompilerConfig()
# # 从TorchAir框架获取npu提供的 默认backend
npu_backend = tng.get_npu_backend(compiler_config=config)
# 使用TorchAir的backend去调用compile接口编译模型
model = torch.compile(model, backend=npu_backend)
self.model = model
self.device = device
def execute(self, requests):
output_dtype = self.output_dtype
responses = []
output = []
# 获取所有请求的batch_size列表
batch_sizes = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
batch_size = input_tensor.as_numpy().shape[0]
batch_sizes.append(batch_size)
# 合并所有请求的输入
input_numpys = []
for request in requests:
input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT")
input_numpy = input_tensor.as_numpy()
input_numpys.append(input_numpy)
# 按batch维度合并所有输入
input_numpy = np.vstack(input_numpys)
input_tensor = torch.from_numpy(input_numpy).to(self.device)
output_tensor = self.model(input_tensor)
output = output_tensor.detach().cpu().numpy()
print("out_tensor_shape", output.shape)
# 按照原始batch_size分割输出并返回
start_idx = 0
for _, batch_size in enumerate(batch_sizes):
end_idx = start_idx + batch_size
out_data = output[start_idx:end_idx]
out_tensor = pb_utils.Tensor("OUTPUT", out_data.astype(output_dtype))
inference_response = pb_utils.InferenceResponse(
output_tensors=[out_tensor]
)
responses.append(inference_response)
start_idx = end_idx
return responses
def finalize(self):
del self.model
self.model = None3. 启动服务化
先安装依赖:
pip3 install protobuf==3.20执行以下命令启动Triton Inference Server服务:
tritonserver --model-repository ./model_repository4. 性能测试
先安装依赖:
pip install tritonclient[http]==2.41.0另起终端,并执行以下命令进行性能测试:
perf_analyzer -m resnet50TorchAir -b 1 -t 1