



NPU卡虚拟化硬切分参考实践
发表于: 2025/12/12
非商用声明
该文档提供的内容为参考实践,仅供用户参考使用,用户可参考实践文档构建自己的软件,按需进行安全、可靠性加固,但不建议直接将相关Demo或镜像文件集成到商用产品中。
1 方案介绍
1.1 背景
为了提升昇腾设备的算力利用率,节省部署的资源成本,在很多业务场景下需要一张卡部署多个参数量较小的模型。但是简单的混合部署存在算力资源抢占风险,资源隔离性差,增加了运维难度,无法保证运行环境平稳和安全。因此昇腾提供虚拟化切分的能力,将NPU虚拟化为vNPU,分配给多个业务使用。从而在保证资源隔离的前提下,实现算力资源的高效利用和调度,保障业务运行的稳定性与安全性。
1.2 方案简介
基于昇腾硬件驱动提供的硬切分能力,将物理机配置的NPU切分成若干份vNPU(虚拟NPU)挂载到容器中使用,满足多个业务按需申请共同使用一个NPU,降低了用户使用NPU算力的成本,同时借助容器进行资源隔离,资源隔离性好,保证运行环境的平稳和安全。
本参考实践将以金融智能化助手一体机场景为例,详细描述该场景下虚拟化硬切分的方案,同时提供详细的操作指导,帮助用户快速将虚拟化硬切分应用到业务应用中。
1.3 关键特性
1、支持硬件:本切分方案支持Atlas推理系列产品:Atlas 300I Duo、Atlas 300I A2、Atlas 800I A2。
2、支持模型:本切分方案已验证支持Qwen2.5、Qwen3等LLM模型,支持Qwen2.5-VL等VLM模型,支持bge-m3等嵌入类模型,具体已验证模型支持情况如表1所示。其它模型支持情况用户可按需自行验证。
3、支持场景:当前版本硬切分特性仅支持推理场景。
表1 已验证支持模型列表
注意:
1、对于Qwen2.5-VL-3B-Instruct 等多模态模型 ,使用MindIE部署时“npuMemSize”不支持设置为-1,因为需要给ViT部分预留空间。建议参考MindIE产品文档计算合适的数值进行配置。
2、对于MinerU 的模型部署 ,使用的 vLLM Ascend 镜像版本不应低于 v0.12.0rc1。
3、MinerU 在使用 vLLM Ascend 进行服务化部署过程中若出现 显存不足(OOM)现象,可通过调整以下参数以降低显存占用:
(1)降低最大并发序列数(max-num-seqs)
(2)减少批处理规模(max-num-batched-tokens)
(3)禁用图优化 (enforce-eager)
(4)调小显存利用上限(gpu-memory-utilization)
( 实测可用配置:
a) Atlas 800I A2(64G)1切2 :需要设置 --max-num-seqs 128 --max-num-batched-tokens 256 --enforce-eager ;
b) Atlas 300I A2、800I A2(32G)1切2 、Atlas 800I A2(64G)1切4 : 需要设置 --gpu-memory-utilization 0.9 --max-num-seqs 32 )
1.4 应用场景
算力切分特性典型的应用场景为各类一体机场景,例如金融智能化助手一体机同时需要部署LLM模型(例如Qwen、Deepseek)和embedding模型(bge-m3)、reranker模型(bge-reranker-v2-m3)以及OCR模型(PP-OCRv5)、语音识别(SenseVoiceSmall )、语音生成(CosyVoice2)等多种模型,既需实现算力高效利用,又要保障资源隔离与运行可靠性。
本参考实践针对典型应用场景提供参考实践,用户可参考使用。
2 使用指导
2.1 软件配置
本参考实践使用的软件配套版本如下:
表1
| 软件/镜像 | 版本 | 说明 |
|---|---|---|
| Ascend HDK | 25.5.0 | NPU驱动固件 |
| CANN | 9.0.0-beta.1 | 昇腾异构计算架构 |
| Ascend-Docker-Runtime | 7.1.RC1 | 用于将vNPU挂载到容器,按需选择安装 |
| MindIE | 2.2.RC2 | 用于部署Qwen等模型 |
| mis-tei | 7.1.RC1 | 用于部署Embedding、Rerank模型 |
| paddle-npu | 3.2 | 用于部署PP-OCRv5模型 |
| Docker | 18.09.0 | 用于部署镜像 |
| OS | openEuler release 22.03 (LTS-SP4) | 物理机操作系统(请使用昇腾官方兼容的OS) |
说明:
HDK 25.5.0 下载链接: 链接 (例如:选择对应芯片型号的“Ascend-hdk-xxx-npu-driver_25.5.0_linux-aarch64.run”驱动文件,申请权限并下载)
paddle-npu安装部署文档:链接
2.2 使用约束
1、同个模型部署时不支持物理NPU+vNPU混合使用。
2、物理NPU虚拟化出vNPU后,不支持再将该物理NPU挂载到容器使用。
3、虚拟化实例模板是用于对整台服务器上所有NPU进行资源切分,不支持不同规格的标卡混插。如Atlas 300I Duo 支持48G和96G内存规格,不支持这两种内存规格的卡混插进行虚拟化。
4、一个推理服务只能绑定一张vNPU。
3 典型场景参考实践
以金融智能化助手一体机这一典型场景为例,通过采用虚拟化硬切分方案,可在单台Atlas 800I A2上部署7个不同模型,从而满足该一体机各类功能应用的模型需求。本章将围绕该场景下的典型实践,从场景介绍、模型需求、部署方案及部署步骤四个部分展开,以说明切分和部署的设计思路和操作方法。该一体机场景具备一定的通用性,也可为其他一体机场景提供参考;用户可根据自身模型需求,对部署方案进行相应调整和验证。
3.1 场景描述
随着金融行业迅速发展,业务系统对智能分析、自动化处理和风险识别的需求呈指数级增长。在银行、证券等核心金融领域,传统的信息处理方式已难以满足高频业务、海量数据的实时决策需求。本一体机方案面向银行、证券、保险等机构,提供智能化助手能力。系统内置 70B 市场分析大模型,可实时解读宏观走势、研判行业风险,并生成结构化研究结论;32B 智能助手模型用于客服咨询、业务办理指引等高频交互场景,实现快速响应与个性化服务。结合高性能向量检索与重排序模型,一体机支持海量业务文档的智能搜索、合规审查与知识问答。集成 OCR、语音识别和语音生成能力,可对贷款资料进行自动识别,提供语音交互实现实时应答,为网点和线上渠道提供端到端的智能处理能力,显著提升金融机构的运营效率与服务质量。
70B大模型需要使用4卡部署,32B模型需要2卡部署,剩下的两卡完成embedding、reranker模型以及语音生成、语音识别、OCR模型共5个模型部署,使用硬切分的方式灵活分配算力资源,实现单卡部署多模型。
3.2 模型需求
针对该场景,使用Atlas 800I A2(64G)整机构建一体机方案,根据模型需求,初步给出模型需求列表如下。
表1 模型需求列表
| 模型类型 | 模型名称 | 用途 |
|---|---|---|
| LLM模型 | DeepSeek-R1-Distill-Llama-70B | 市场分析、建模、报表生成、长文本/大数据输出场景(高算力、批量/异步任务) |
| LLM模型 | Qwen3 32B | 面向智能助手、交互式客服、实时问答(低延迟、在线交互) |
| embedding模型 | bge-m3 | 负责信贷文档检索、客户咨询语义匹配等场景 |
| reranker模型 | bge-reranker-v2-m3 | 负责精准排序,保证返回给 LLM 的知识高质量 |
| 语音识别模型 | SenseVoiceSmall | 语音指令解析;短问答转文字 |
| 语音生成模型 | CosyVoice2 | 语音客服 |
| OCR小模型 | PP-OCRv5 | 信贷/身份相关图像识别(证件、合同、影像表单) |
3.3 部署方案
针对该场景,使用Atlas 800I A2(64G)构建一体机方案,根据模型需求,给出具体的NPU切分方案和模型部署方案如下,作为参考,用户可以根据实际的性能需求,酌情调整模型使用的资源,并进行性能验证。
表1 模型部署方案列表
| 模型名称 | 推理引擎 | NPU编号 | 切分规格 | 部署方案 |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Llama-70B | MindIE | 0,1,2,3 | NA | 使用Atlas800I A2(64G)的0,1,2,3卡部署1个实例 |
| Qwen3 32B | MindIE | 4,5 | NA | 使用Atlas800I A2(64G)的4,5卡部署1个实例 |
| bge-m3 | mis-tei | 6 | 1切2 | 在6卡上使用vir10_3c_32g进行1切2,在其中一个vNPU上部署该模型 |
| bge-reranker-v2-m3 | mis-tei | 6 | 1切2 | 在6卡上使用vir10_3c_32g进行1切2,在其中一个vNPU上部署该模型 |
| SenseVoiceSmall | MindIE | 7 | 1切4 | 在7卡上使用vir05_1c_16g进行1切4,在其中一个vNPU上部署该模型 |
| CosyVoice2 | MindIE | 7 | 1切4 | 在7卡上使用vir05_1c_16g进行1切4,在其中一个vNPU上部署该模型 |
| PP-OCRv5 | paddle-npu | 7 | 1切2 | 在7卡上使用vir10_3c_32g进行1切2,在其中一个vNPU上部署该模型 |
3.4 部署步骤
本节提供模型具体部署步骤以及注意事项。
1. 执行命令 npu-smi info 查询空闲NPU卡(如下图所示0号卡(id=0,chip_id=0)上无任何进程),可进行切分。
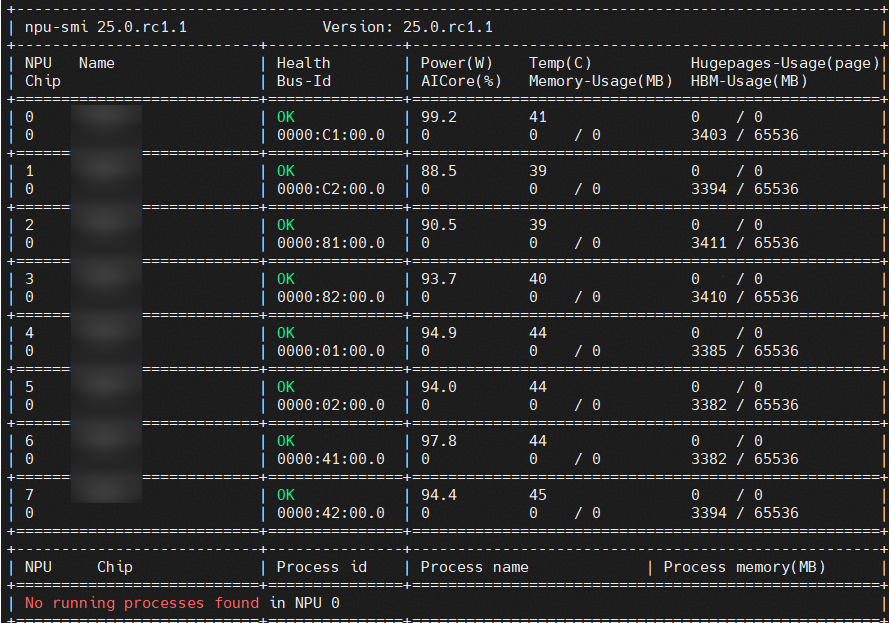
2. 执行命令 npu-smi info -t info-vnpu -i id -c chip_id 查询该NPU上是否有vNPU,若已存在vNPU,可参照本节步骤10的操作按需决定是否删除。
3. 执行命令 npu-smi info -t template-info 查询当前机型支持的切分模版。
4. 根据模型占用显存大小来选择合适的切分模板vnpu_config。例如:本实践中使用的PP-OCRv5模型,首先在单张物理整卡上准备好相关配置文件进行服务化部署,服务启动后使用jmeter等工具进行高并发压测,记录压测过程中出现的最大模型占用显存为23GB。使用切分模板vir10_3c_32g可以分配到32G显存,而vir05_1c_16g分配显存为16G,不满足此处显存要求。故应该选择切分模板vir10_3c_32g进行1切2。
5. 执行命令 npu-smi set -t create-vnpu -i id -c chip_id -f vnpu_config 进行切分。
6. 执行命令 npu-smi info -t info-vnpu -i id -c chip_id 查询该vNPU的信息,获取vNPU_id。
7. 参考附录中【命令参考-使用vNPU】节内容,提供两种vNPU挂载方式:
a) 原生Docker使用vNPU:
docker run -it -d --net=host --shm-size=1g \
--name <container-name> \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
--device=/dev/vdavinci212:/dev/davinci212 \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /home:/home \
<image_name> bash说明:
本方案中MindIE和mis-tei容器均使用该方式挂载vNPU。
按实际情况设置docker run命令参数,使用 --device=/dev/vdavinci212:/dev/davinci212 的方式将vNPU挂载到容器中,212是第6步中查询到的vNPU_id。
b) Ascend Docker Runtime使用vNPU:
一些容器,例如本方案中的paddle-npu容器必须使用Ascend docker-runtime来挂载vNPU。否则会出现设备无法初始化等问题导致容器内找不到vNPU。需要通过Ascend Docker Runtime容器组件,将vNPU挂载到容器。
本方式需要在环境中安装Ascend docker-runtime组件。安装链接:Ascend Docker Runtime-MindCluster7.2.RC1-昇腾社区
Ascend Docker Runtime组件提供有两种挂载方式:
docker run -it -d --net=host \
--shm-size=128g \
--name <container-name> \
-e ASCEND_VISIBLE_DEVICES=100 \
-e ASCEND_RUNTIME_OPTIONS=VIRTUAL \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home:/work \
-w=/work \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/device/paddle-npu:cann800-ubuntu20-npu-$(chip_type)-base-$(uname -m)-gcc84 bash说明:
ASCEND_VISIBLE_DEVICES:切分得到的vNPU_id
或者
docker run -it -d --net=host \
--shm-size=128g \
--name <container-name> \
-e ASCEND_VISIBLE_DEVICES=7 \
-e ASCEND_VNPU_SPECS=vir10_3c_32g \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /home:/work \
-w=/work \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/device/paddle-npu:cann800-ubuntu20-npu-$(chip_type)-base-$(uname -m)-gcc84 bash说明:
ASCEND_VISIBLE_DEVICES:切分用到的物理卡卡号
ASCEND_VNPU_SPECS:切分模板名称
第一种方式需要我们提前创建好vNPU,在docker run命令中绑定容器。
第二种方式不需要提前创建vNPU,在保证该物理卡上的资源满足切分后,在docker run命令中完成vNPU切分并绑定容器。
8. 进入上一步创建的docker容器中,执行命令 npu-smi info 查询vNPU信息,若成功回显类似带有 “vir10_3c_32g ”字样的虚拟卡名称,说明vNPU成功挂载到容器中,后续使用方式跟使用普通NPU一样。
9. 各模型服务化启动方式不再一一列举,可参考1.3节中表1的各官方教程。
10. 确认该vNPU不再使用后,执行命令 npu-smi set -t destroy-vnpu -i id -c chip_id -v vnpu_id 销毁指定的vNPU,避免影响其他人使用。
本部署步骤适用于所有支持的昇腾推理硬件,切分后的各模型性能可以达到实际使用场景下的性能要求。
附录-命令参考
查询所有设备信息
npu-smi info查询单NPU卡规格
npu-smi info -t info-vnpu -i id -c chip_id说明:
id 设备id。通过npu-smi info -l命令查出的NPU ID即为设备id。
chip_id 芯片id。通过npu-smi info -m命令查出的Chip ID即为芯片id。
表1 Atlas 300I A2(64G)、Atlas 800I A2 (64G)规格
| AICORE | Memory GB | AICPU | VPC | VENC | VDEC | JPEGD | JPEGE | PNGD |
|---|---|---|---|---|---|---|---|---|
| 20/20 | 64/64 | 7/7 | 9/9 | 0/0 | 2/2 | 24/24 | 4/4 | NA/NA |
表2 Atlas 300I A2(32G)、Atlas 800I A2 (32G)规格
| AICORE | Memory GB | AICPU | VPC | VENC | VDEC | JPEGD | JPEGE | PNGD |
|---|---|---|---|---|---|---|---|---|
| 20/20 | 32/32 | 7/7 | 9/9 | 0/0 | 2/2 | 24/24 | 4/4 | NA/NA |
表3 Atlas 300I Duo(96G)单芯片规格
| AICORE | Memory GB | AICPU | VPC | VENC | VDEC | JPEGD | JPEGE | PNGD |
|---|---|---|---|---|---|---|---|---|
| 8/8 | 43/43 | 7/7 | 12/12 | 3/3 | 12/12 | 16/16 | 8/8 | NA/NA |
说明:
Atlas 300I Duo(96G)为单卡双芯片设计,上述43GB显存为单芯片的数据。总卡显存为双芯片显存之和
查询切分模板
npu-smi info -t template-info表1 Atlas 300I A2(64G)、Atlas 800I A2 (64G)切分模板
| Name | AICORE | Memory GB | AICPU | VPC PNGD | VENC VDEC | JPEGD JPEGE |
|---|---|---|---|---|---|---|
| vir10_3c_32g | 10 | 32 | 3 | 4 0 | 0 1 | 12 2 |
| vir05_1c_16g | 5 | 16 | 1 | 2 0 | 0 0 | 6 1 |
表2 Atlas 300I A2(32G)、Atlas 800I A2 (32G)切分模板
| Name | AICORE | Memory GB | AICPU | VPC PNGD | VENC VDEC | JPEGD JPEGE |
|---|---|---|---|---|---|---|
| vir10_3c_16g | 10 | 16 | 3 | 4 0 | 0 1 | 12 2 |
| vir10_4c_16g_m | 10 | 16 | 4 | 9 0 | 0 2 | 24 4 |
| vir10_3c_16g_nm | 10 | 16 | 3 | 0 0 | 0 0 | 0 0 |
| vir05_1c_8g | 5 | 8 | 1 | 2 0 | 0 0 | 6 1 |
表3 Atlas 300I Duo(96G)切分模板
| Name | AICORE | Memory GB | AICPU | VPC PNGD | VENC VDEC | JPEGD JPEGE |
|---|---|---|---|---|---|---|
| vir01 | 1 | 6 | 1 | 1 0 | 0 1 | 2 1 |
| vir02 | 2 | 12 | 2 | 3 0 | 1 3 | 4 2 |
| vir02_1c | 2 | 12 | 1 | 3 0 | 0 3 | 4 2 |
| vir04 | 4 | 24 | 4 | 6 0 | 2 6 | 8 4 |
| vir04_3c | 4 | 24 | 3 | 6 0 | 1 6 | 8 4 |
| vir04_3c_ndvpp | 4 | 24 | 3 | 0 0 | 0 0 | 0 0 |
| vir04_4c_dvpp | 4 | 24 | 4 | 12 0 | 3 12 | 16 8 |
说明:
vir后面的数字表示AI Core数量。c前面的数字表示AI CPU数量。Memory/GB的数字表示显存资源分配大小;
创建vNPU
npu-smi set -t create-vnpu -i id -c chip_id -f vnpu_config说明:
id 设备id。通过npu-smi info -l命令查出的NPU ID即为设备id。
chip_id 芯片id。通过npu-smi info -m命令查出的Chip ID即为芯片id。
vnpu_config 虚拟化实例模板名称,可参见 附录【命令参考-查询切分模板】。
删除vNPU
npu-smi set -t destroy-vnpu -i id -c chip_id -v vnpu_id使用vNPU
1、原生Docker使用vNPU
#vnpu绑定mindie容器
docker run -it -u root --name=mindie-vnpu212 --net=host --ipc=host \
--device=/dev/vdavinci212:/dev/davinci212 \
--device=/dev/davinci_manager \
--device=/dev/devmm_svm \
--device=/dev/hisi_hdc \
-v /usr/local/Ascend:/usr/local/Ascend \
-v /usr/local/sbin/:/usr/local/sbin/ \
-v /var/log/npu:/var/log/npu \
swr.cn-south-1.myhuaweicloud.com/ascendhub/mindie:2.2.RC1-800I-A2-py311-openeuler24.03-lts说明:
使用 --device=/dev/vdavinci212:/dev/davinci212 的方式将vNPU挂载到容器中,212是创建vnpu后查询到的vNPU_id
2、Ascend Docker Runtime使用vNPU
Ascend Docker Runtime提供两种将vNPU绑定docker容器的方式:
a) 启动容器时,挂载vNPU_ID为100的虚拟卡
docker run -it \
-e ASCEND_VISIBLE_DEVICES=100 \
-e ASCEND_RUNTIME_OPTIONS=VIRTUAL \
image-name:tag /bin/bash说明:
ASCEND_VISIBLE_DEVICES:切分得到的vNPU_id
b) 启动容器时,从物理芯片ID为0的芯片上,切分出5个AI Core作为虚拟设备并挂载至容器中。
docker run -it --rm \
-e ASCEND_VISIBLE_DEVICES=0 \
-e ASCEND_VNPU_SPECS=vir05_1c_8g \
image-name:tag /bin/bash说明:
ASCEND_VISIBLE_DEVICES:切分用到的物理卡卡号
ASCEND_VNPU_SPECS:切分模板名称
切分实例组合
图1 Atlas 800I A2 (32G)、Atlas 800I A2 (64G)切分实例组合图

图2 Atlas 300I A2(32G)、Atlas 800I A2(32G)切分实例组合图

图3 Atlas 300I Duo(96G)单芯片切分实例组合图
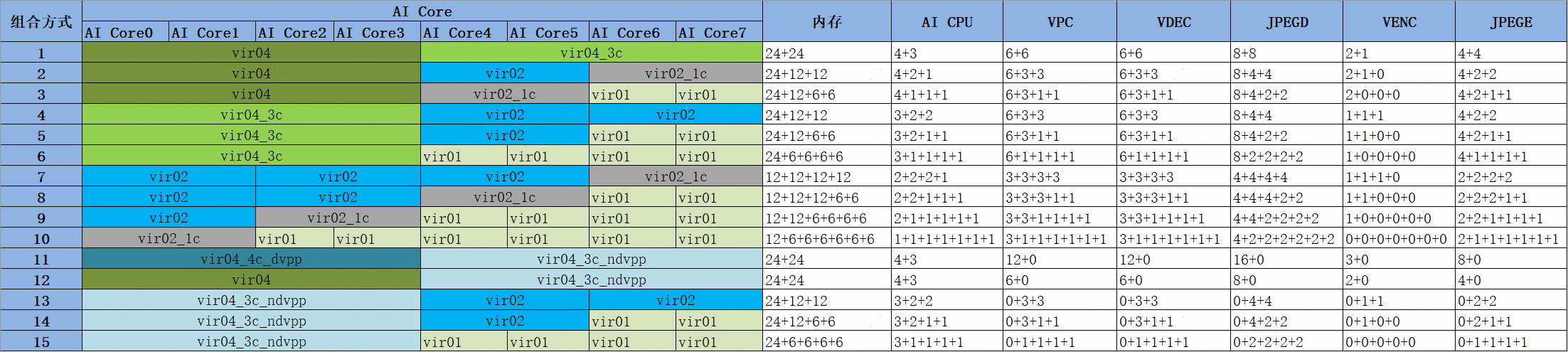
参考文档:创建vNPU-虚拟化实例
vNPU配置恢复使能状态
- 查询当前环境中vNPU的配置恢复使能状态。保证设备重启后,vNPU配置依然生效。
npu-smi info -t vnpu-cfg-recover说明:
查询当前环境中vNPU的配置恢复使能状态。
- 修改vNPU的配置恢复使能状态,可以切分后再修改使能状态。
npu-smi set -t vnpu-cfg-recover -d mode说明:
mode表示vNPU的配置恢复使能状态,“1”表示开启状态,“0”表示关闭状态,默认为开启状态。